Course
Pandas Joins for Spreadsheet Users
4 hr
3.5K
Trying to strengthen your data skills? Our AI assistant explores your goals and interests to recommend the perfect content. Start building skills that matter to you and your career.
Before reading a CSV file into a pandas dataframe, you should have some insight into what the data contains. Thus, it’s recommended you skim the file before attempting to load it into memory: this will give you more insight into what columns are required and which ones can be discarded.
Let’s write some code to import a file using read_csv(). Then we can talk about what’s going on and how we can customize the output we receive while reading the data into memory.
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
All that has gone on in the code above is we have:
read_csv to read the data into memory as a pandas dataframe.But there’s a lot more to the read_csv() function.
The default behavior of pandas is to add an initial index to the dataframe returned from the CSV file it has loaded into memory. However, you can explicitly specify what column to make as the index to the read_csv function by setting the index_col parameter.
Note the value you assign to index_col may be given as either a string name, column index or a sequence of string names or column indexes. Assigning the parameter a sequence will result in a multiIndex (a grouping of data by multiple levels).
Let’s read in the data again and set the id column as the index.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austing.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
What if you only want to read specific columns into memory because not all of them are important? This is a common scenario that occurs in the real world. Using the read_csv function, you can select only the columns you need after loading the file, but this means you must know what columns you need prior to loading in the data if you wish to perform this operation from within the read_csv function.
If you do know the columns you need, you’re in luck; you can save time and memory by passing a list-like object to the usecols parameter of the read_csv function.
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
We have barely scratched the surface of different ways to customize the output of the read_csv function, but going into more depth would certainly be an information overload.
We recommend you bookmark the importing data in Python cheat sheet and check out Introduction to importing data in Python to learn more. If that’s a little too easy, there is also the intermediate importing data in Python interactive course.
Once you know how to read a CSV file from local storage into memory, reading data from other sources is a breeze. It’s ultimately the same process, except that you’re no longer passing a file path.
Let’s say there’s data you want from a specific webpage; how would you read it into memory?
We will use the Iris dataset from the UCI repository as an example:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
Voila!
You may have noticed we assigned a list of strings to the names parameter in the read_csv function. This is just so we can rename the column headers while reading the data into memory.
The most common object in the pandas library is, by far, the dataframe object. It’s a 2-dimensional labeled data structure consisting of rows and columns that may be of different data types (i.e., float, numeric, categorical, etc.).
Conceptually, you can think of a pandas dataframe like a spreadsheet, SQL table, or a dictionary of series objects – whichever you’re more familiar with. The cool thing about the pandas dataframe is that it comes with many methods that make it easy for you to become acquainted with your data as quickly as possible.
You have already seen one of those methods: iris_data.head(), which shows the first n (the default is 5) rows. The “opposite” method of head() is tail(), which shows the last n (5 by default) rows of the dataframe object. For example:
iris_data.tail()
You can quickly discover the column names by using the columns attribute on your dataframe object:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Another important method you can use on your dataframe object is info(). This method prints out a concise summary of the dataframe, including information about the index, data types, columns, non-null values, and memory usage.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() generates descriptive statistics, including those that summarize the central tendency, dispersion, and shape of the dataset’s distribution. If your data has missing values, don’t worry; they are not included in the descriptive statistics.
Let’s call the describe method on the Iris dataset:
# Get descriptive statistics
iris_data.describe()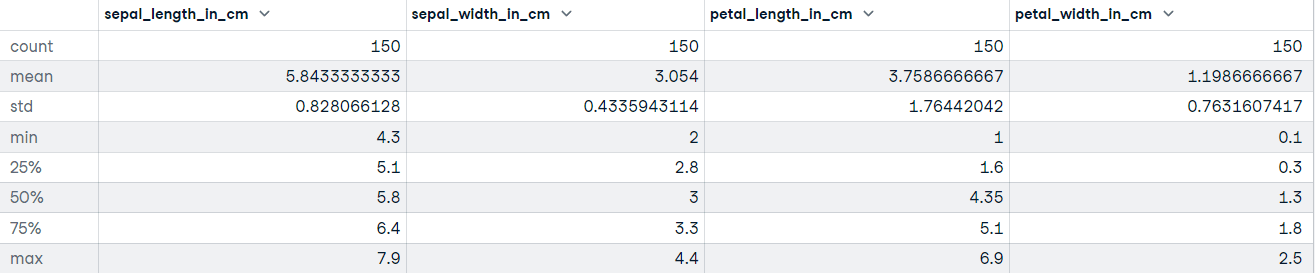
Another method available to pandas dataframe objects is to_csv(). When you have cleaned and preprocessed your data, the next step may be to export the dataframe to a file – this is pretty straightforward:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Executing this code will create a CSV in the current working directory called cleaned_iris_data.csv.
But what if you want to use a different delimiter to mark the beginning and end of a unit of data or you wanted to specify how your missing values should be represented? Maybe you don’t want the headers to be exported to the file.
Well, you can adjust the parameters of the to_csv() method to suit your requirements for the data you want to export.
Let’s take a look at a few examples of how you can adjust the output of to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Let’s recap what we covered in this tutorial; you learned how to:
read_csv() function from the pandas library.read_csv() function to return.pandas.read_csv()to_csv() method.In this tutorial, we focused solely on importing and exporting data from the perspective of a CSV file; you now have a good sense of how useful pandas is when importing and exporting CSV files. CSV is one of the most common data storage formats, but it’s not the only one. There are various other file formats used in data science, such as parquet, JSON, and excel.
Plenty of useful, high-quality datasets are hosted on the web, which you can access through APIs, for example. If you want to understand how to handle loading data into Python in more detail, DataCamp's Introduction to Importing Data in Python course will teach you all the best practices.
There are also tutorials on how to import JSON and HTML data into pandas and a beginner-friendly ultimate guide to pandas tutorial. Be sure to check those out to dive deeper into the pandas framework.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.
Learn more about Python and pandas
Course
Course
Course
Amberle McKee
Adel Nehme
Amberle McKee
Adel Nehme
Bex Tuychiev
Adel Nehme


