Certification available
Course
Supervised Learning with scikit-learn
4 hr
101.8K
Practice loading a Python Pickled file with this hands-on exercise.
Are you tired of rerunning your Python code every time you need to access a previously created data frame, variable, or machine learning model?
Object serialization may be the solution you’re looking for.
It is the process of storing a data structure in memory so that you can load or transmit it when required without losing its current state.
Here is a simple diagram explaining how serialization works:
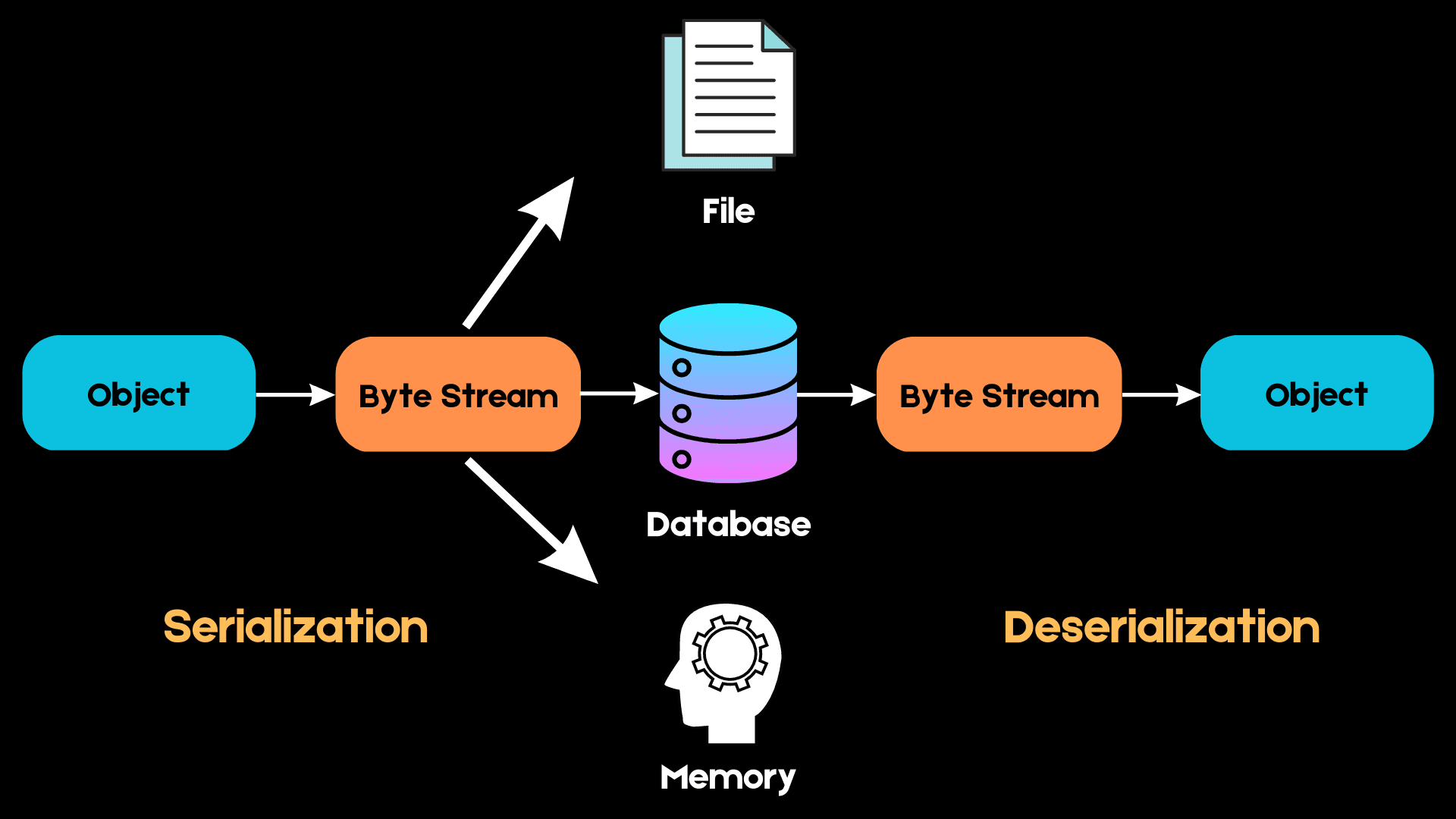
Image by author
In Python, we work with high-level data structures such as lists, tuples, and sets. However, when we want to store these objects in memory, they need to be converted into a sequence of bytes that the computer can understand. This process is called serialization.
The next time we want to access the same data structure, this sequence of bytes must be converted back into the high-level object in a process known as deserialization.
We can use formats such as JSON, XML, HDF5, and Pickle for serialization. In this tutorial, we will learn about the Python Pickle library for serialization. We will cover its uses and understand when you should choose Pickle over other serialization formats.
Finally, we will learn how to use Pickle Python library to serialize lists, dictionaries, Pandas data frames, machine learning models, and more.
Learn the skills you need at your own pace—from non-coding essentials to data science and machine learning.
Learn more about Python and Machine Learning
Course
Course
Course
Mark Graus
10 min
Adel Nehme
5 min
Joleen Bothma
9 min
Amina Edmunds
7 min
Satyam Tripathi
9 min
Natassha Selvaraj
9 min





