🧭 Summary (Вступ)
Markdown — це проста й потужна мова розмітки, що дозволяє красиво документувати код, створювати пояснення, таблиці, формули та навіть елементи дизайну без необхідності знати HTML. У середовищі Jupyter Notebook Markdown використовується для створення текстових блоків між комірками коду, що робить аналітичні звіти, дослідження даних і навчальні матеріали читабельними й професійними.
Markdown допомагає структурувати роботу, пояснювати алгоритми, вставляти зображення, посилання, формули LaTeX і навіть форматовані повідомлення (alert boxes).
!pip install kagglehubimport pandas as pd
# Завантажуємо датасет Titanic напряму з URL
url = 'https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv'
df = pd.read_csv(url)
# 1. Подивимось на перші 5 рядків
print("=== Перші 5 рядків датасету ===")
print(df.head())
print("\n")
# 2. Розмір датасету (рядки, колонки)
print(f"=== Розмір датасету ===")
print(f"Кількість рядків: {df.shape[0]}")
print(f"Кількість колонок: {df.shape[1]}")
print("\n")
# 3. Назви всіх колонок
print("=== Назви колонок ===")
print(df.columns.tolist())
print("\n")
# 4. Базова інформація про датасет
print("=== Інформація про датасет ===")
print(df.info())
print("\n")
# 5. Статистика по числових колонках
print("=== Статистика ===")
print(df.describe())
print("\n")
# 6. Скільки людей вижило?
print("=== Виживання пасажирів ===")
print(f"Вижило: {df['Survived'].sum()} людей")
print(f"Загинуло: {len(df) - df['Survived'].sum()} людей")
print("\n")
# 7. Середній вік пасажирів
print("=== Вік пасажирів ===")
print(f"Середній вік: {df['Age'].mean():.1f} років")
print("\n")
# 8. Кількість чоловіків і жінок
print("=== Розподіл за статтю ===")
print(df['Sex'].value_counts())
print("\n")
# 9. Виживання по класах
print("=== Виживання по класах ===")
survival_by_class = df.groupby('Pclass')['Survived'].mean() * 100
print(survival_by_class)
print("\n")
# 10. Збереження обробленого датасету
# df.to_csv('titanic_processed.csv', index=False)
# print("Датасет збережено у файл titanic_processed.csv")📊 Квартилі та перцентилі: що вони розповідають про дані краще за середнє
Проблема середнього значення (mean): Середнє та стандартне відхилення можуть вводити в оману, особливо коли дані скошені (skewed) або містять викиди. Кілька дуже великих значень (наприклад, дорогі квитки першого класу на «Титаніку») сильно підвищують середнє, хоча більшість людей платили значно менше.
🚢 Приклад «Титаніка»
- Середня ціна квитка: $32.20
- Медіана (50-й перцентиль): $14.45
- 25% пасажирів заплатили менше $7.91
- 75% пасажирів — менше $31.00
👉 «Типовий» пасажир платив близько
🔍 Чому стандартного відхилення недостатньо
Стандартне відхилення показує наскільки широко розкидані дані, але:
- не показує напрям перекосу (вліво чи вправо),
- сильно чутливе до викидів,
- не відповідає на питання типу: «Який поріг для топ-10%?».
📌 Перцентилі та квартилі — що це?
-
Перцентиль — значення, нижче якого знаходиться певний % спостережень.
-
Квартилі ділять дані на 4 рівні частини:
- Q1 (25%) — нижня межа «типових» значень
- Q2 (50%) — медіана
- Q3 (75%) — верхня межа «типових» значень
-
IQR = Q3 − Q1 — розкид середніх 50% даних (стійкий до викидів).
🧮 Обчислення
- Якщо позиція перцентиля — ціле число, беремо відповідне значення.
- Якщо дробове — використовуємо лінійну інтерполяцію між сусідніми значеннями.
📈 Візуалізації
- Box plot — показує медіану, квартилі та викиди.
- Гістограма з перцентилями — реальну форму розподілу.
- Порівняння за класами — виявляє нерівність (1-й клас ≫ 3-й).
- Крива перцентилів віку — кумулятивний розподіл.
🧠 Основні висновки з даних «Титаніка»
-
Розподіл цін сильно скошений вправо.
-
Медіана краща за середнє для опису «типового» пасажира.
-
Існує велика нерівність між класами:
- Медіана 1-го класу ≈ у 7.5 раза вища, ніж 3-го.
-
Пасажири були відносно молодими: медіанний вік ≈ 28 років.
✅ Коли використовувати квартилі та перцентилі
- Скошені дані (доходи, ціни, витрати)
- Дані з викидами
- Рейтинги та пороги (top-10%, top-5%)
- Порівняння груп
- Встановлення «нормального діапазону» (Q1–Q3)
🎯 Головна ідея
- Стандартне відхилення показує наскільки дані розкидані
- Перцентилі показують де саме знаходиться більшість значень
- Разом вони дають повну картину розподілу
👉 Коли хтось каже «середнє», завжди запитуй: «Це mean чи median? І яка форма розподілу?»
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Завантажити датасет Titanic
df = pd.read_csv('titanic.csv')
print("="*60)
print("КВАРТИЛІ І ПЕРЦЕНТИЛІ - АНАЛІЗ ТИТАНІКА")
print("="*60)
# ============================================
# ЧАСТИНА 1: АНАЛІЗ ВАРТОСТІ КВИТКІВ
# ============================================
# Видалити пропущені значення
fares = df['Fare'].dropna()
print("\n=== КВАРТИЛІ ВАРТОСТІ КВИТКІВ ===")
q1_fare = fares.quantile(0.25) # Перший квартиль (25-й перцентиль)
q2_fare = fares.quantile(0.50) # Другий квартиль (медіана, 50-й перцентиль)
q3_fare = fares.quantile(0.75) # Третій квартиль (75-й перцентиль)
print(f"Q1 (25-й перцентиль): ${q1_fare:.2f}")
print(f"Q2 (50-й перцентиль / Медіана): ${q2_fare:.2f}")
print(f"Q3 (75-й перцентиль): ${q3_fare:.2f}")
print(f"IQR (міжквартильний розмах, Q3 - Q1): ${q3_fare - q1_fare:.2f}")
print(f"\nІнтерпретація:")
print(f"• 25% пасажирів заплатили менше ніж ${q1_fare:.2f}")
print(f"• 50% пасажирів заплатили менше ніж ${q2_fare:.2f} (медіана)")
print(f"• 75% пасажирів заплатили менше ніж ${q3_fare:.2f}")
print(f"• Середні 50% заплатили від ${q1_fare:.2f} до ${q3_fare:.2f}")
# Порівняння середнього та медіани
mean_fare = fares.mean()
print(f"\nСереднє значення вартості: ${mean_fare:.2f}")
print(f"Медіана вартості: ${q2_fare:.2f}")
print(f"Різниця: ${mean_fare - q2_fare:.2f} (Середнє на {((mean_fare/q2_fare - 1)*100):.1f}% вище!)")
print("→ Розподіл з правосторонньою асиметрією (кілька дорогих квитків підвищують середнє)")
# ============================================
# ЧАСТИНА 2: АНАЛІЗ ПЕРЦЕНТИЛІВ
# ============================================
print("\n=== КЛЮЧОВІ ПЕРЦЕНТИЛІ (Вартість) ===")
percentiles = [10, 25, 50, 75, 90, 95, 99]
for p in percentiles:
value = fares.quantile(p/100)
print(f"{p}-й перцентиль: ${value:.2f} (Топ {100-p}% заплатили більше)")
# ============================================
# ЧАСТИНА 3: АНАЛІЗ ВІКУ
# ============================================
ages = df['Age'].dropna()
print("\n=== КВАРТИЛІ ВІКУ ===")
q1_age = ages.quantile(0.25) # Перший квартиль віку
q2_age = ages.quantile(0.50) # Медіана віку
q3_age = ages.quantile(0.75) # Третій квартиль віку
print(f"Q1 (25-й перцентиль): {q1_age:.1f} років")
print(f"Q2 (50-й перцентиль): {q2_age:.1f} років")
print(f"Q3 (75-й перцентиль): {q3_age:.1f} років")
print(f"IQR (міжквартильний розмах): {q3_age - q1_age:.1f} років")
print(f"\nІнтерпретація:")
print(f"• 25% пасажирів були молодші за {q1_age:.1f}")
print(f"• 50% були молодші за {q2_age:.1f} (медіанний вік)")
print(f"• 75% були молодші за {q3_age:.1f}")
# ============================================
# ЧАСТИНА 4: КВАРТИЛІ ЗА КЛАСАМИ
# ============================================
print("\n=== КВАРТИЛІ ВАРТОСТІ ЗА КЛАСОМ ПАСАЖИРА ===")
for pclass in [1, 2, 3]:
# Отримати вартість квитків для кожного класу
class_fares = df[df['Pclass'] == pclass]['Fare'].dropna()
q1 = class_fares.quantile(0.25)
q2 = class_fares.quantile(0.50)
q3 = class_fares.quantile(0.75)
print(f"\nКлас {pclass}:")
print(f" Q1: ${q1:.2f}")
print(f" Q2 (Медіана): ${q2:.2f}")
print(f" Q3: ${q3:.2f}")
print(f" IQR: ${q3-q1:.2f}")
# ============================================
# ЧАСТИНА 5: ВИЖИВАННЯ ЗА ВІКОВИМИ КВАРТИЛЯМИ
# ============================================
print("\n=== РІВЕНЬ ВИЖИВАННЯ ЗА ВІКОВИМИ КВАРТИЛЯМИ ===")
# Створити групи вікових квартилів
# pd.qcut розділяє дані на рівні групи за квартилями
df['Age_Quartile'] = pd.qcut(df['Age'].dropna(),
q=4, # 4 квартилі
labels=['Q1 (Наймолодші)', 'Q2', 'Q3', 'Q4 (Найстарші)'])
# Розрахувати рівень виживання для кожного квартиля
survival_by_age_quartile = df.groupby('Age_Quartile', observed=True)['Survived'].agg(['mean', 'count'])
survival_by_age_quartile.columns = ['Рівень_Виживання', 'Кількість']
print(survival_by_age_quartile)
print("\nВисновок: Чи впливає віковий квартиль на виживання?")Квартилі (Quartiles):
- Q1 - перший квартиль (25% даних нижче цього значення)
- Q2 - другий квартиль (медіана, 50% даних)
- Q3 - третій квартиль (75% даних нижче цього значення)
IQR (Interquartile Range) - міжквартильний розмах:
- Різниця між Q3 та Q1
- Показує розкид середніх 50% даних
- Використовується для виявлення викидів
Перцентилі (Percentiles):
- Значення, нижче якого знаходиться певний відсоток даних
- Наприклад, 90-й перцентиль - 90% даних нижче цього значення
Що показує цей код:
- Аналіз вартості квитків - як розподілялися ціни на Титаніку
- Порівняння середнього і медіани - виявлення асиметрії
- Вікові групи - розподіл віку пасажирів
- Різниця між класами - як відрізнялися ціни в 1-му, 2-му і 3-му класах
- Вік і виживання - чи впливав вік на шанси вижити
# Встановити стиль графіків
plt.style.use('seaborn-v0_8-darkgrid')
# Створити сітку з 4 графіків (2 рядки × 2 стовпці)
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# Загальний заголовок для всіх графіків
fig.suptitle('Аналіз квартилів і перцентилів - Датасет Титаніка',
fontsize=16, fontweight='bold')
# ============================================
# ГРАФІК 1: Box Plot - Розподіл вартості квитків
# ============================================
ax1 = axes[0, 0] # Верхній лівий графік
# Створити діаграму "коробка з вусами" (box plot)
bp = ax1.boxplot([fares], # Дані про вартість квитків
vert=False, # Горизонтальна орієнтація
widths=0.5, # Ширина коробки
patch_artist=True, # Дозволити кольорове заповнення
boxprops=dict(facecolor='lightblue', alpha=0.7), # Колір коробки
medianprops=dict(color='red', linewidth=2), # Червона лінія медіани
whiskerprops=dict(linewidth=1.5), # Товщина "вусів"
capprops=dict(linewidth=1.5)) # Товщина кінцевих ліній
# Розрахувати квартилі
q1, q2, q3 = fares.quantile([0.25, 0.50, 0.75])
# Додати вертикальні лінії для квартилів
ax1.axvline(q1, color='green', linestyle='--', alpha=0.7, label=f'Q1: ${q1:.2f}')
ax1.axvline(q2, color='red', linestyle='--', alpha=0.7, label=f'Q2: ${q2:.2f}')
ax1.axvline(q3, color='orange', linestyle='--', alpha=0.7, label=f'Q3: ${q3:.2f}')
ax1.set_xlabel('Вартість ($)', fontsize=11)
ax1.set_title('Box Plot: Розподіл вартості квитків з квартилями', fontweight='bold')
ax1.legend() # Показати легенду
ax1.grid(True, alpha=0.3) # Додати сітку
# ============================================
# ГРАФІК 2: Гістограма з лініями перцентилів
# ============================================
ax2 = axes[0, 1] # Верхній правий графік
# Побудувати гістограму вартості квитків
ax2.hist(fares, bins=50, # 50 стовпчиків
color='skyblue',
edgecolor='black',
alpha=0.7)
# Перцентилі для відображення
percentiles_to_plot = [25, 50, 75, 90]
colors = ['green', 'red', 'orange', 'purple']
# Додати вертикальні лінії для кожного перцентиля
for p, color in zip(percentiles_to_plot, colors):
value = fares.quantile(p/100)
ax2.axvline(value, color=color, linestyle='--', linewidth=2,
label=f'P{p}: ${value:.2f}')
ax2.set_xlabel('Вартість ($)', fontsize=11)
ax2.set_ylabel('Частота', fontsize=11)
ax2.set_title('Розподіл вартості з ключовими перцентилями', fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)
# ============================================
# ГРАФІК 3: Box Plot за класами пасажирів
# ============================================
ax3 = axes[1, 0] # Нижній лівий графік
# Підготувати дані для кожного класу
class_1_fares = df[df['Pclass'] == 1]['Fare'].dropna() # 1-й клас
class_2_fares = df[df['Pclass'] == 2]['Fare'].dropna() # 2-й клас
class_3_fares = df[df['Pclass'] == 3]['Fare'].dropna() # 3-й клас
# Створити box plot для трьох класів
bp = ax3.boxplot([class_1_fares, class_2_fares, class_3_fares],
labels=['1-й клас', '2-й клас', '3-й клас'],
patch_artist=True,
boxprops=dict(alpha=0.7),
medianprops=dict(color='red', linewidth=2))
# Розфарбувати коробки різними кольорами
colors = ['gold', 'silver', 'brown'] # Золотий, сріблястий, коричневий
for patch, color in zip(bp['boxes'], colors):
patch.set_facecolor(color)
ax3.set_ylabel('Вартість ($)', fontsize=11)
ax3.set_title('Квартилі вартості за класом пасажира', fontweight='bold')
ax3.grid(True, alpha=0.3, axis='y') # Горизонтальна сітка
# ============================================
# ГРАФІК 4: Розподіл перцентилів віку
# ============================================
ax4 = axes[1, 1] # Нижній правий графік
# Розрахувати перцентилі від 0 до 100 з кроком 5
percentiles = np.arange(0, 101, 5)
age_percentiles = [ages.quantile(p/100) for p in percentiles]
# Побудувати криву перцентилів
ax4.plot(percentiles, age_percentiles,
linewidth=2.5,
color='darkblue',
marker='o', # Круглі маркери
markersize=4)
# Заповнити область під кривою
ax4.fill_between(percentiles, age_percentiles, alpha=0.3, color='lightblue')
# Виділити квартилі горизонтальними лініями
for p in [25, 50, 75]:
value = ages.quantile(p/100)
ax4.axhline(value, color='red', linestyle='--', alpha=0.6)
# Додати текстові мітки
ax4.text(102, value, f'Q{p//25}: {value:.1f}р', fontsize=9, va='center')
ax4.set_xlabel('Перцентиль', fontsize=11)
ax4.set_ylabel('Вік (роки)', fontsize=11)
ax4.set_title('Крива перцентилів віку (від 0-го до 100-го)', fontweight='bold')
ax4.grid(True, alpha=0.3)
# Автоматично відрегулювати відстані між графіками
plt.tight_layout()
# Відобразити всі графіки
plt.show()
print("\n✅ Всі візуалізації успішно створені!")Пояснення графіків:
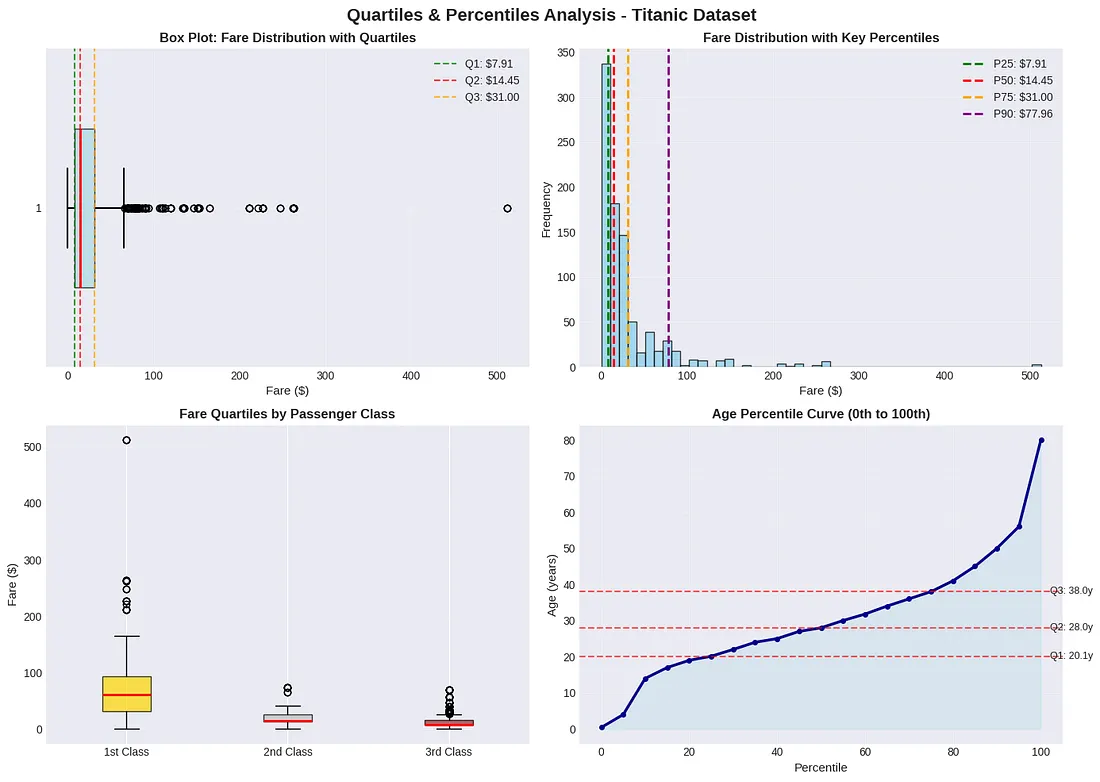
ГРАФІК 1: Box Plot вартості
Що показує:
- Коробка = середні 50% даних (від Q1 до Q3)
- Червона лінія всередині = медіана (Q2)
- "Вуса" = розмах даних (без викидів)
- Точки за межами = викиди (outliers)
Вертикальні лінії:
- 🟢 Зелена (Q1) - 25% пасажирів заплатили менше
- 🔴 Червона (Q2) - медіана (50%)
- 🟠 Помаранчева (Q3) - 75% заплатили менше
ГРАФІК 2: Гістограма з перцентилями
Що показує:
- Стовпчики = кількість пасажирів у кожному ціновому діапазоні
- Вертикальні лінії = ключові перцентилі
Кольорові лінії:
- 🟢 P25 (Q1) - 25-й перцентиль
- 🔴 P50 (Q2) - медіана
- 🟠 P75 (Q3) - 75-й перцентиль
- 🟣 P90 - 90-й перцентиль (лише 10% заплатили більше)
ГРАФІК 3: Box Plot за класами
Що показує:
- Порівняння розподілу цін між класами
- Наскільки відрізнялися ціни в 1-му, 2-му і 3-му класах
Кольори:
- 🥇 Золотий = 1-й клас (найдорожчий)
- 🥈 Сріблястий = 2-й клас
- 🟤 Коричневий = 3-й клас (найдешевший)
Висновки з графіка:
- 1-й клас: найбільший розкид цін, високі викиди
- 3-й клас: щільно згруповані низькі ціни
- Медіана 1-го класу >> медіани 2-го та 3-го
ГРАФІК 4: Крива перцентилів віку
Що показує:
- Як розподілений вік пасажирів від 0-го до 100-го перцентиля
- Кожна точка = певний перцентиль віку
Горизонтальні червоні лінії:
- Q1 (25%) - чверть пасажирів молодші за цей вік
- Q2 (50%) - медіанний вік
- Q3 (75%) - три чверті пасажирів молодші
Форма кривої:
- Крута на початку = багато дітей/молодих
- Пологіша в середині = рівномірний розподіл
- Крута в кінці = мало літніх людей
Ключові висновки з візуалізацій:
- Розподіл вартості сильно асиметричний (багато дешевих, мало дорогих квитків)
- Різниця між класами величезна (1-й клас у десятки разів дорожчий за 3-й)
- Більшість пасажирів - молоді дорослі (медіана віку близько 28-30 років)
- Багато дітей (швидке зростання кривої на початку)
Посилання:
- Quartiles & Percentiles: Understanding Your Data’s Story Beyond Averages, https://medium.com/@umang.gulati19/quartiles-percentiles-understanding-your-datas-story-beyond-averages-5338738fda30
- T-tests Explained: Understand how to Compare Outcomes Between Two Groups, https://medium.com/@sabourinleandre/t-tests-for-beginners-comparing-two-groups-b146b0b51fec
- Difference Between the Two-Tailed vs One-Tailed Test in Hypothesis Testing, https://medium.com/@sabourinleandre/two-tailed-vs-one-tailed-tests-ddba8e8d8ccc