1. Winter is Coming. Let's load the dataset ASAP!
If you haven't heard of Game of Thrones, then you must be really good at hiding. Game of Thrones is the hugely popular television series by HBO based on the (also) hugely popular book series A Song of Ice and Fire by George R.R. Martin. In this notebook, we will analyze the co-occurrence network of the characters in the Game of Thrones books. Here, two characters are considered to co-occur if their names appear in the vicinity of 15 words from one another in the books.
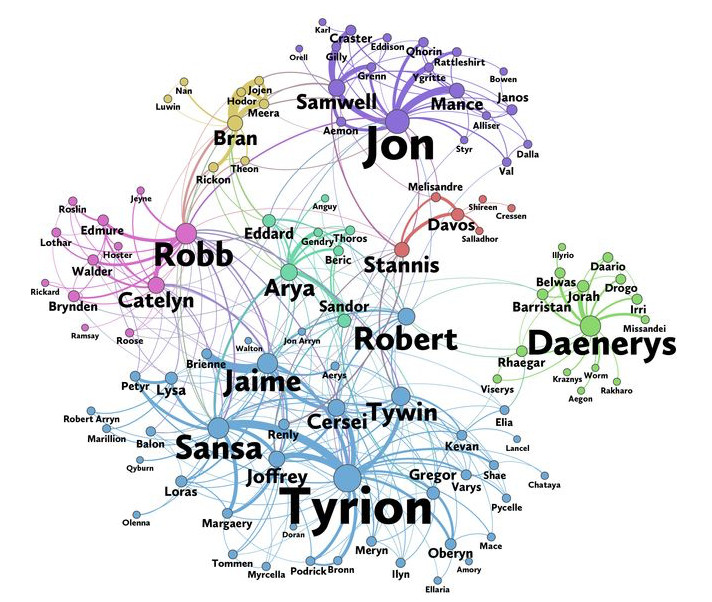
This dataset constitutes a network and is given as a text file describing the edges between characters, with some attributes attached to each edge. Let's start by loading in the data for the first book A Game of Thrones and inspect it.
# Importing modules
import pandas as pd
# Reading in datasets/book1.csv
book1 = pd.read_csv("datasets/book1.csv")
# Printing out the head of the dataset
print(book1.head())2. Time for some Network of Thrones
The resulting DataFrame book1 has 5 columns: Source, Target, Type, weight, and book. Source and target are the two nodes that are linked by an edge. A network can have directed or undirected edges and in this network all the edges are undirected. The weight attribute of every edge tells us the number of interactions that the characters have had over the book, and the book column tells us the book number.
Once we have the data loaded as a pandas DataFrame, it's time to create a network. We will use networkx, a network analysis library, and create a graph object for the first book.
# Importing modules
import networkx as nx
# Creating an empty graph object
G_book1 = nx.Graph()
3. Populate the network with the DataFrame
Currently, the graph object G_book1 is empty. Let's now populate it with the edges from book1. And while we're at it, let's load in the rest of the books too!
# Iterating through the DataFrame to add edges
for _, edge in book1.iterrows():
G_book1.add_edge(edge['Source'], edge['Target'], weight=edge['weight'])
# Creating a list of networks for all the books
books = [G_book1]
book_fnames = ['datasets/book2.csv', 'datasets/book3.csv', 'datasets/book4.csv', 'datasets/book5.csv']
for book_fname in book_fnames:
book = pd.read_csv(book_fname)
G_book = nx.Graph()
for _, edge in book.iterrows():
G_book.add_edge(edge['Source'], edge['Target'], weight=edge['weight'])
books.append(G_book)4. The most important character in Game of Thrones
Is it Jon Snow, Tyrion, Daenerys, or someone else? Let's see! Network science offers us many different metrics to measure the importance of a node in a network. Note that there is no "correct" way of calculating the most important node in a network, every metric has a different meaning.
First, let's measure the importance of a node in a network by looking at the number of neighbors it has, that is, the number of nodes it is connected to. For example, an influential account on Twitter, where the follower-followee relationship forms the network, is an account which has a high number of followers. This measure of importance is called degree centrality.
Using this measure, let's extract the top ten important characters from the first book (book[0]) and the fifth book (book[4]).
# Calculating the degree centrality of book 1
deg_cen_book1 = nx.degree_centrality(books[0])
# Calculating the degree centrality of book 5
deg_cen_book5 = nx.degree_centrality(books[4])
# Sorting the dictionaries according to their degree centrality and storing the top 10
sorted_deg_cen_book1 = sorted(deg_cen_book1.items(), key=lambda x:x[1], reverse=True)[0:10]
# Sorting the dictionaries according to their degree centrality and storing the top 10
sorted_deg_cen_book5 = sorted(deg_cen_book5.items(), key=lambda x:x[1], reverse=True)[0:10]
# Printing out the top 10 of book1 and book5
print(sorted_deg_cen_book1)
print(sorted_deg_cen_book5) 5. The evolution of character importance
According to degree centrality, the most important character in the first book is Eddard Stark but he is not even in the top 10 of the fifth book. The importance of characters changes over the course of five books because, you know, stuff happens… ;)
Let's look at the evolution of degree centrality of a couple of characters like Eddard Stark, Jon Snow, and Tyrion, which showed up in the top 10 of degree centrality in the first book.
%matplotlib inline
# Creating a list of degree centrality of all the books
evol = [nx.degree_centrality(book) for book in books]
degree_evol_df = pd.DataFrame.from_records(evol)
degree_evol_df[['Eddard-Stark', 'Tyrion-Lannister', 'Jon-Snow']].plot()6. What's up with Stannis Baratheon?
We can see that the importance of Eddard Stark dies off as the book series progresses. With Jon Snow, there is a drop in the fourth book but a sudden rise in the fifth book.
Now let's look at various other measures like betweenness centrality and PageRank to find important characters in our Game of Thrones character co-occurrence network and see if we can uncover some more interesting facts about this network. Let's plot the evolution of betweenness centrality of this network over the five books. We will take the evolution of the top four characters of every book and plot it.
# Creating a list of betweenness centrality of all the books just like we did for degree centrality
evol = [nx.betweenness_centrality(book, weight='weight') for book in books]
# Making a DataFrame from the list
betweenness_evol_df = pd.DataFrame.from_records(evol).fillna(0)
# Finding the top 4 characters in every book
set_of_char = set()
for i in range(5):
set_of_char |= set(list(betweenness_evol_df.T[i].sort_values(ascending=False)[0:4].index))
list_of_char = list(set_of_char)
# Plotting the evolution of the top characters
betweenness_evol_df[list_of_char].plot(figsize=(13, 7))7. What does Google PageRank tell us about GoT?
We see a peculiar rise in the importance of Stannis Baratheon over the books. In the fifth book, he is significantly more important than other characters in the network, even though he is the third most important character according to degree centrality.
PageRank was the initial way Google ranked web pages. It evaluates the inlinks and outlinks of webpages in the world wide web, which is, essentially, a directed network. Let's look at the importance of characters in the Game of Thrones network according to PageRank.
# Creating a list of pagerank of all the characters in all the books
evol = [nx.nx.pagerank(book, weight='weight') for book in books]
# Making a DataFrame from the list
pagerank_evol_df = pd.DataFrame.from_records(evol).fillna(0)
# Finding the top 4 characters in every book
set_of_char = set()
for i in range(5):
set_of_char |= set(list(pagerank_evol_df.T[i].sort_values(ascending=False)[0:4].index))
list_of_char = list(set_of_char)
# Plotting the top characters
pagerank_evol_df[list_of_char].plot(figsize=(13, 7))8. Correlation between different measures
Stannis, Jon Snow, and Daenerys are the most important characters in the fifth book according to PageRank. Eddard Stark follows a similar curve but for degree centrality and betweenness centrality: He is important in the first book but dies into oblivion over the book series.
We have seen three different measures to calculate the importance of a node in a network, and all of them tells us something about the characters and their importance in the co-occurrence network. We see some names pop up in all three measures so maybe there is a strong correlation between them?
Let's look at the correlation between PageRank, betweenness centrality and degree centrality for the fifth book using Pearson correlation.