Curso
Ingesta de datos eficiente con pandas
4 h
60.5K
Cuando se trata de un conjunto de datos, como uno con 10.000 filas y 50 columnas, obtener rápidamente una visión general de estos conjuntos de datos puede ser todo un reto. Aquí es donde pandas Profiling resulta útil. Agiliza el proceso generando un informe exhaustivo de su conjunto de datos, lo que minimiza el tiempo de exploración de estos grandes conjuntos de datos.
En este artículo, usted aprenderá cómo empezar con lo que antes se conocía como pandas Profiling. El nombre del paquete pandas-profiling se ha cambiado recientemente a ydata-profiling. En este tutorial, aprenderá a generar un informe de perfil a partir del conjunto de datos, qué contiene el informe de perfil, cómo leer este informe de perfil y, por último, cómo guardar este informe para su uso posterior.
Pandas Profiling se utiliza para generar un informe completo y exhaustivo para el conjunto de datos, con muchas características y personalizaciones en el informe generado. Este informe incluye diversos datos, como estadísticas del conjunto de datos, distribución de valores, valores que faltan, uso de memoria, etc., que resultan muy útiles para explorar y analizar los datos de forma eficaz.
Pandas Profiling también ayuda mucho en el Análisis Exploratorio de Datos (EDA). EDA se utiliza para comprender la estructura subyacente de los datos, detectar patrones y generar perspectivas en un formato visual.
Para EDA, tenemos que escribir muchas líneas de código, lo que a veces puede ser complejo y llevar mucho tiempo, pero se puede automatizar utilizando Pandas Profiling con sólo unas pocas líneas de código.
Si necesita un repaso sobre EDA, lea Python Exploratory Data Analysis.
He aquí un ejemplo de informe de perfil:
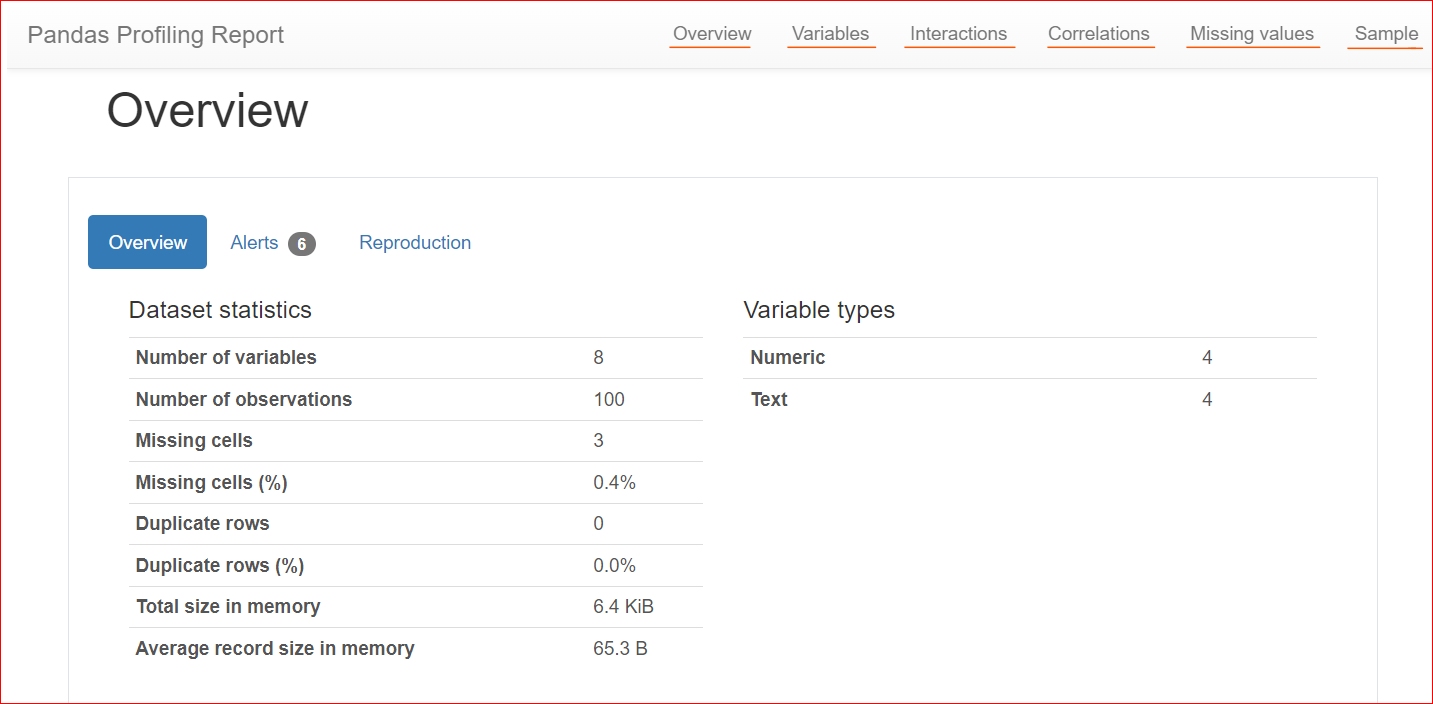
Imagen del autor
Pandas profiling es ampliamente utilizado en EDA debido a su facilidad de uso, eficiencia de tiempo e informes HTML interactivos. Sin embargo, existen algunos inconvenientes potenciales en el uso de pandas profiling con grandes conjuntos de datos.
Para instalar pandas Profiling, puede utilizar pip o conda, dependiendo de sus preferencias y entorno.
Usando Pip:
Abra un símbolo del sistema o un terminal y ejecute el siguiente comando:
pip install ydata-profilingUso de Conda:
Abra Anaconda PowerShell Prompt y ejecute el siguiente comando:
conda install -c conda-forge ydata-profilingUna vez completada con éxito la instalación, importe ydata-profiling utilizando la siguiente sentencia.
from ydata_profiling import ProfileReportEsto importará la clase ProfileReport de la biblioteca ydata_profiling. Puede utilizar esta clase para generar informes de perfil para sus DataFrames.
Para generar un informe de perfil, siga los pasos que se indican a continuación:
ydata_profiling.ProfileReport() y pase el DataFrame.Aquí está el código directo siguiendo los pasos descritos anteriormente. En primer lugar, importamos las bibliotecas necesarias y, a continuación, leemos el archivo CSV mediante la función read_csv(). En este caso, utilizaremos el archivo CSV de las 100 reseñas de libros más vendidos. A continuación, utilizamos la clase ProfileReport y le pasamos nuestro DataFrame.
Además, estamos estableciendo un nuevo título, "Trending Books". Por defecto, el título es otro, pero si quieres personalizarlo, utiliza la variable title dentro de la clase. Por último, para generar y mostrar el informe, puede utilizar profile o profile.to_notebook_iframe().
El informe se generará en la secuencia siguiente: En primer lugar, se resumirá todo el conjunto de datos. A continuación, se generará la estructura del informe. Por último, mostrará el informe, que podrá guardar como archivo HTML y utilizar para análisis posteriores.

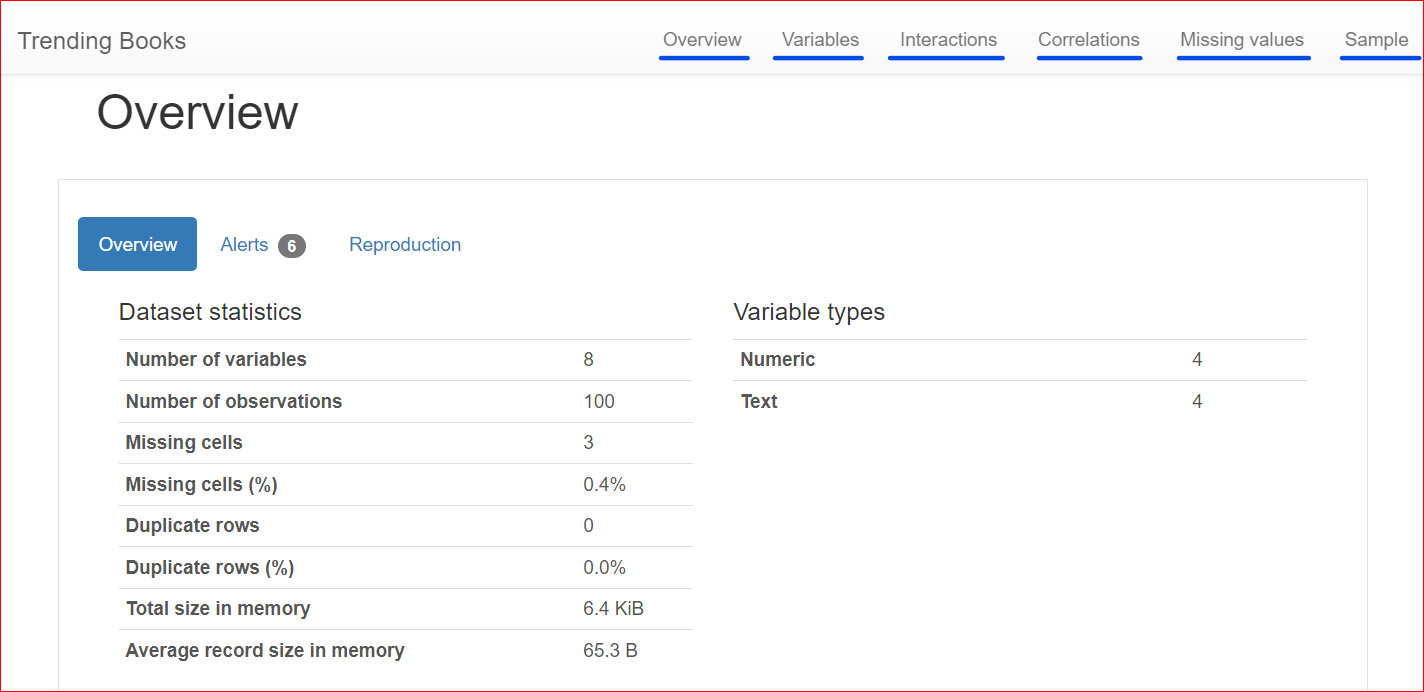
A continuación se muestra el informe generado, que incluye diferentes secciones como Resumen, Variables, Interacciones, Correlaciones, Valores perdidos y Muestra.
Si es nuevo en EDA y, más concretamente, en la creación de perfiles de datos, lea Exploratory Data Analysis of Craft Beers: Perfiles de datos.
El informe se genera en muchas secciones, exploremos todas las secciones una por una.
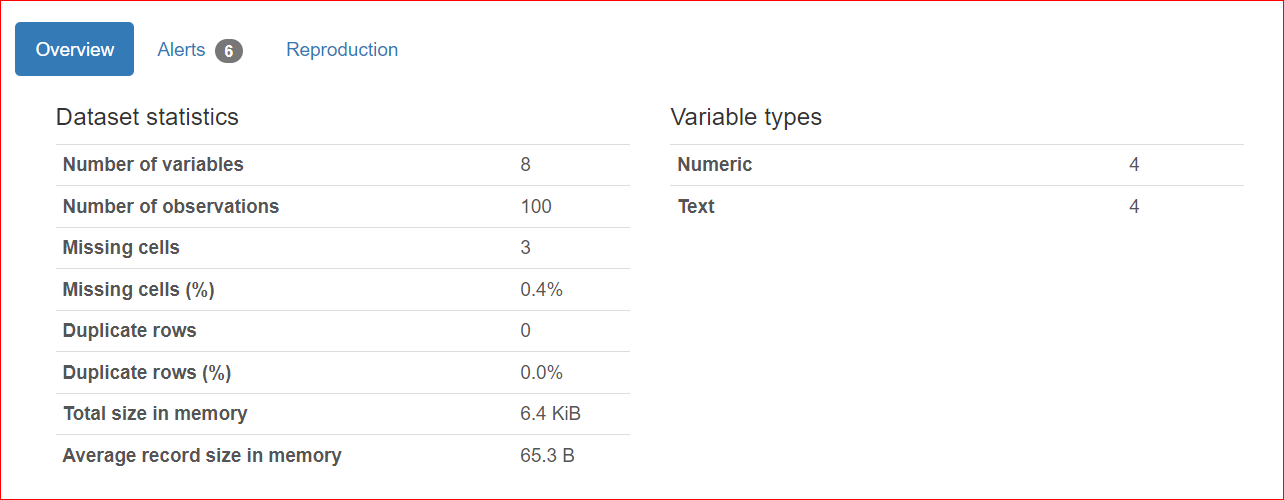
Esta sección consta de 3 pestañas: Visión general, alertas y reproducción.
La pestaña Resumen incluye estadísticas del conjunto de datos, como el número de variables (o el número de columnas diferentes), el número de celdas con valores perdidos, las filas duplicadas y el tamaño del conjunto de datos en memoria.
En nuestro conjunto de datos, hay un total de 8 variables o columnas. Entre las variables, cuatro son numéricas (rango, precio del libro, valoración y año de publicación), mientras que las cuatro restantes son textuales (título del libro, autor, género y URL). No hay filas duplicadas, como muestra el recuento de 0 duplicados. Además, en la columna "calificación" faltan tres valores.
La pestaña Alertas contiene alertas relacionadas con correlaciones con otras variables, valores que faltan, valores únicos, ceros, etc.
En nuestro caso, las columnas URL y Rank tienen valores únicos, y en la columna rating faltan tres valores.
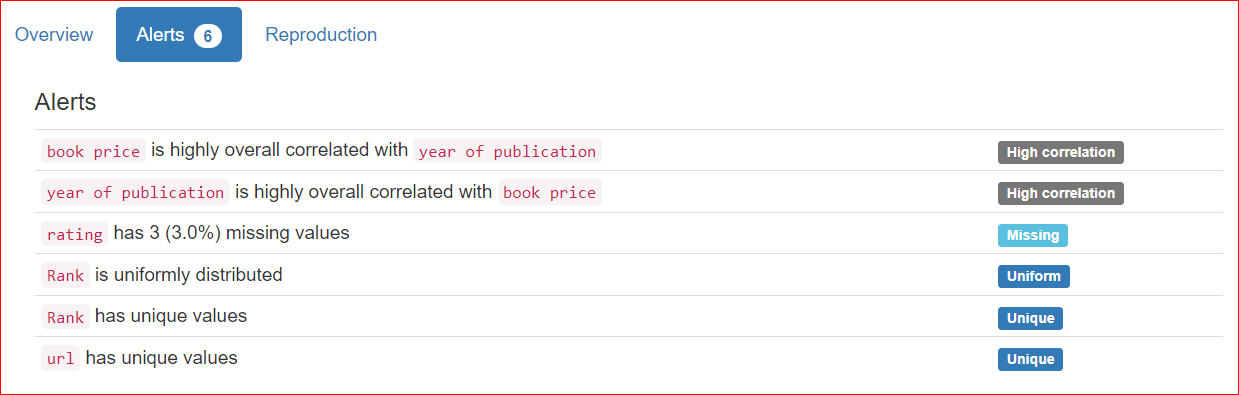
La pestaña Reproducción muestra cuándo comenzó y cuándo terminó el análisis. Muestra la duración del análisis, incluida la versión de software que está utilizando (en mi caso, es ydata-profiling v4.6.1).
La sección Variables incluye todas las columnas de su conjunto de datos. Puede hacer clic en la flecha de alternancia y seleccionar cualquier columna.
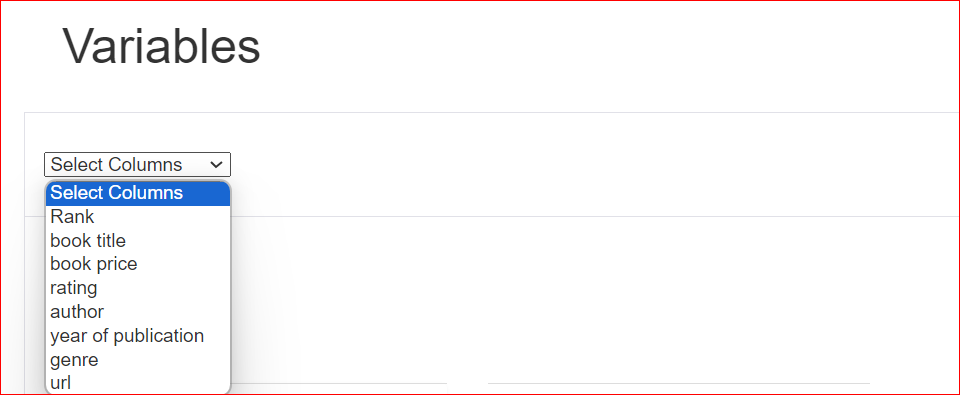
Suponiendo que haya seleccionado la columna calificación, el informe muestra que esta columna contiene 10 valores únicos que se distribuyen en 100 filas. Además, tres casillas carecen de valor. El valor mínimo es 4,1, mientras que el máximo es 5. También se muestra la media de todas las valoraciones.
Nota importante: en la esquina inferior derecha hay un botón que permite obtener más detalles. Al hacer clic en este botón se accede a más información sobre la columna de calificación, como la mediana, la desviación típica, el coeficiente de variación y otras características asociadas a la columna.
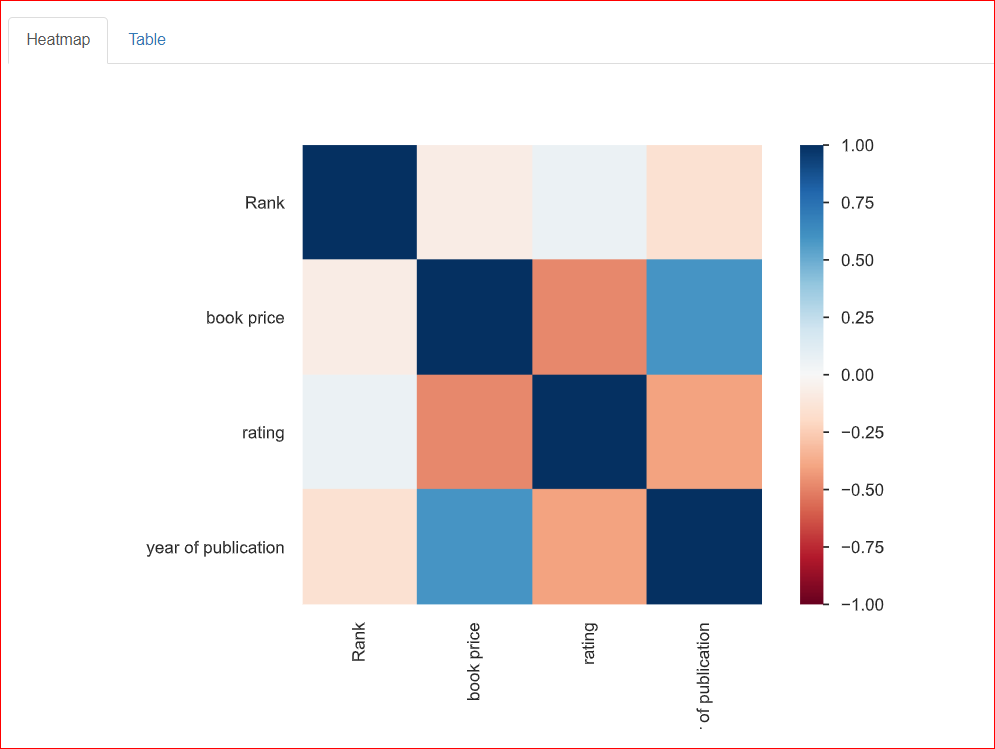
Ayuda en el estudio de la relación entre dos variables, lo que se conoce como correlación. El siguiente mapa de calor muestra las relaciones entre todas las variables. Rank está 100% relacionado con Rank, y por eso está representado por el cuadrado azul oscuro de la parte superior izquierda.
El año de publicación está moderadamente relacionado con el precio del libro (en torno a 0,75), que se representa con el color azul claro porque no están totalmente relacionados. Por ejemplo, el precio del libro es de 20,93 y el año de publicación es 2023, por lo que estos números guardan cierta relación entre sí.
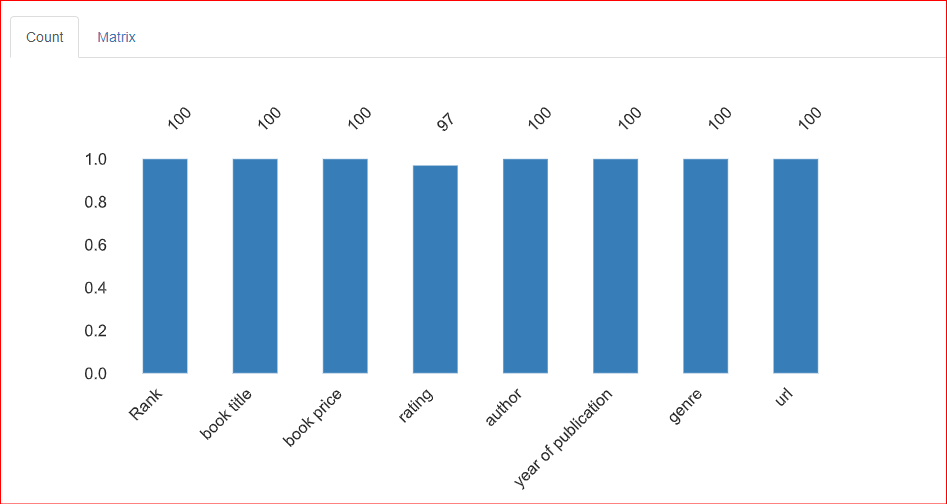
Esta sección proporciona información sobre los valores que faltan en el conjunto de datos. La pestaña Recuento de esta sección indica que faltan 3 valores en la columna de calificación.
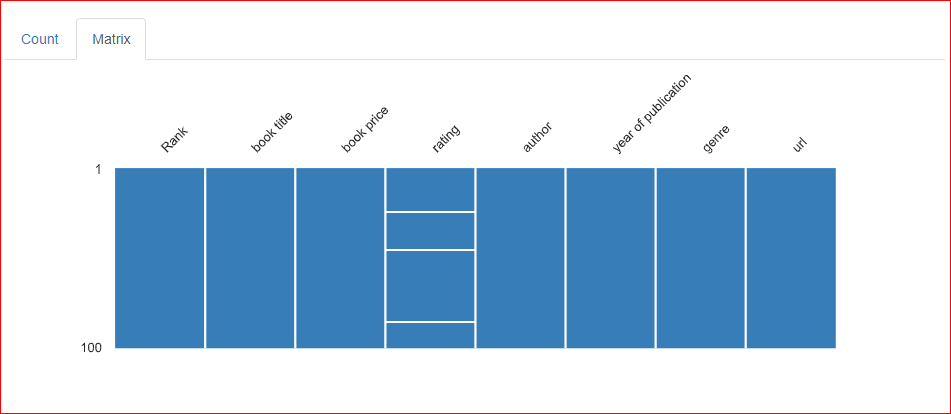
En la pestaña Matriz de la sección de valores que faltan, hay tres líneas horizontales en la columna Calificación, lo que indica que faltan tres valores en la columna.
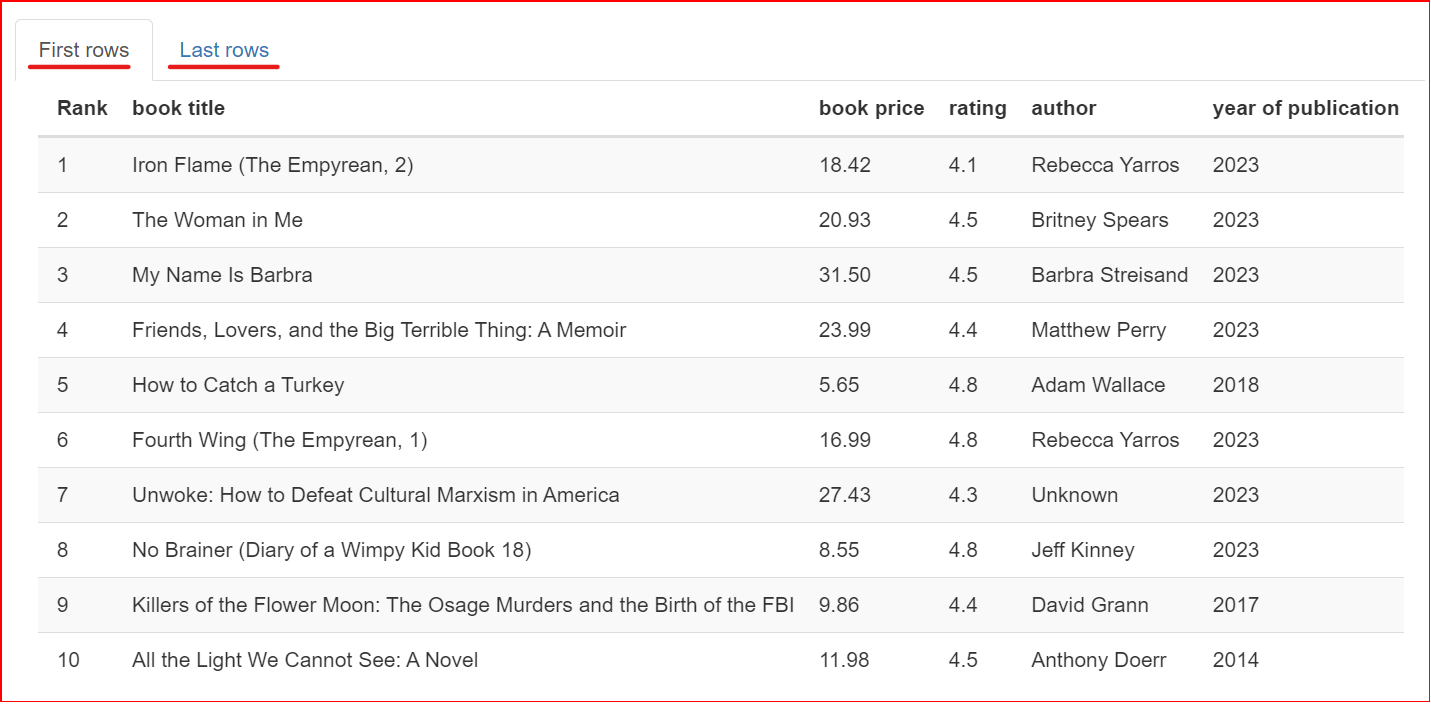
Esta sección contiene una muestra del conjunto de datos. Muestra las 10 primeras y las 10 últimas filas del conjunto de datos.
Se genera su informe de perfil, y es posible que desee guardarlo para su uso posterior, como extraer datos útiles del informe de perfil o integrarlo con otras aplicaciones. Puede guardar el informe en formato HTML y JSON. El método to_file() guardará el informe fuera de Jupyter Notebook.
Aquí está el código completo para el perfilado de Pandas:
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
profile = ProfileReport(df, title="Trending Books")
profile.to_notebook_iframe()
profile.to_file("books_data.html")Para generar el informe, simplemente pasamos el archivo CSV y nada más. No incluimos ningún elemento adicional; en las acciones sólo se utilizan valores por defecto.
Sin embargo, puede haber secciones que desee omitir o incluir información adicional. Aquí es donde entran en juego los usos avanzados de Pandas Profiling. Puede controlar varios aspectos del informe cambiando la configuración por defecto.
Si quieres saber más sobre herramientas de análisis y visualización de datos, lee 21 herramientas esenciales de Python.
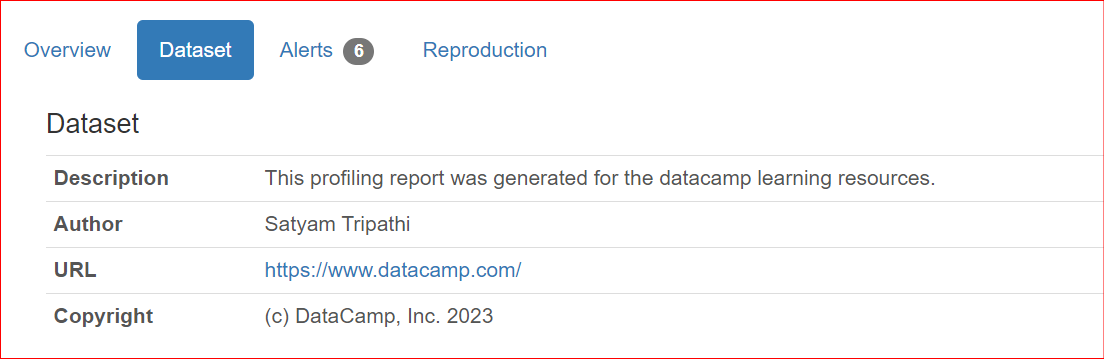
Cuando se comparten informes con compañeros de trabajo o se publican en línea, puede ser importante incluir metadatos del conjunto de datos, como el autor, el titular de los derechos de autor o las descripciones. ydata-profiling permite complementar un informe con esa información.
Las propiedades actualmente admitidas son descripción, creador, autor, url, año_de_copyright y titular_de_copyright. Por defecto, los conjuntos de datos se presentan en la sección Visión general del informe.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
dataset={
"description": "This profiling report was generated for the datacamp learning resources.",
"author": "Satyam Tripathi",
"copyright_holder": "DataCamp, Inc.",
"copyright_year": 2023,
"url": "<https://www.datacamp.com/>",
},
)
report.to_notebook_iframe()Este es el código de salida:
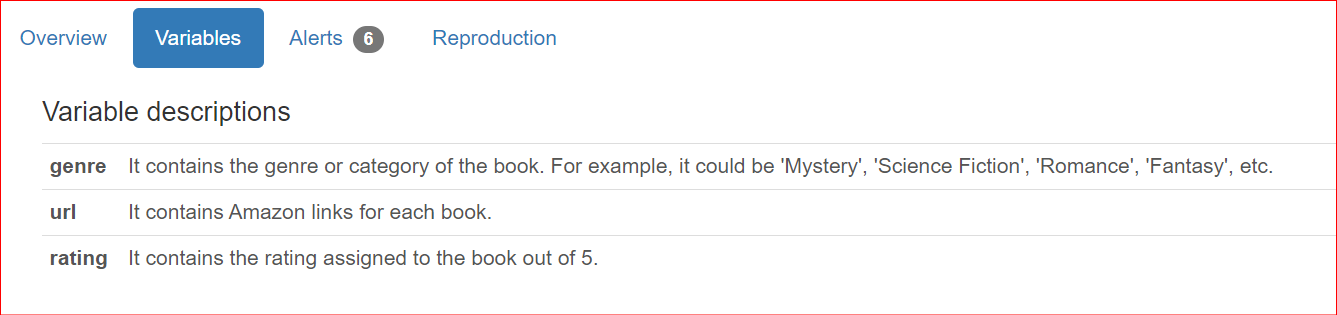
Además de ofrecer detalles de los conjuntos de datos, los usuarios a menudo desean incluir descripciones específicas de las columnas cuando comparten informes con los miembros del equipo y las partes interesadas. Por defecto, estas descripciones se presentan en la sección Visión general del informe.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(
df,
title="Trending Books",
variables={
"descriptions": {
"genre": "It contains the genre or category of the book. For example, it could be 'Mystery', 'Science Fiction', 'Romance', 'Fantasy', etc.",
"url": "It contains Amazon links for each book.",
"rating": "It contains the rating assigned to the book out of 5.",
}
},
)
report.to_notebook_iframe()Este es el código de salida:
Por defecto, ydata-profiling resume exhaustivamente el conjunto de datos de entrada para proporcionar la mayor cantidad de información para el análisis de datos. Para conjuntos de datos pequeños, estos cálculos pueden realizarse rápidamente. Sin embargo, para conjuntos de datos más grandes, puede resultar demasiado difícil de manejar.
ydata-profiling incluye un archivo de configuración mínimo en el que los cálculos más costosos se desactivan por defecto. Esta configuración excluye secciones que consumen mucho tiempo, como correlaciones, interacciones, etc.
from ydata_profiling import ProfileReport
import pandas as pd
df = pd.read_csv("trending-books.csv")
report = ProfileReport(df, minimal=True)
report.to_notebook_iframe()ydata-profiling también ofrece varias alternativas para superar el reto de manejar grandes conjuntos de datos. Explórelos aquí.
En el artículo, usted aprendió acerca de la biblioteca única,ydata-profiling,antes conocido como "Pandas Profiling", para crear informes con sólo un par de líneas de código. Ha aprendido a generar el informe de perfil y a explorar todas las secciones y pestañas presentes en el informe de perfil. Y lo que es más importante, has aprendido los usos avanzados de esta biblioteca, que te llevarán un paso por delante en tu viaje por la ciencia de datos.
Pandas es la biblioteca de Python más popular del mundo, utilizada para todo, desde la manipulación de datos hasta el análisis de datos. Para aprender a manipular DataFrames, mientras extrae, filtra y transforma conjuntos de datos del mundo real para su análisis, consulte nuestro curso sobre Manipulación de Datos con pandas.
Explorar Más usos de los pandas
Curso
Curso
Curso
blog
Matt Crabtree
9 min
Tutorial
Karlijn Willems
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz
Tutorial
Moez Ali


