Introduction to Databases in Python
BeginnerSkill Level
4 h
97.3K learners
El lenguaje de consulta estructurado (SQL) es el más utilizado para ejecutar diversas tareas de análisis de datos. También se utiliza para mantener una base de datos relacional, por ejemplo: añadir tablas, eliminar valores y optimizar la base de datos. Una base de datos relacional simple consta de varias tablas interconectadas, y cada tabla consta de filas y columnas.
Por término medio, una empresa tecnológica genera millones de puntos de datos cada día. Se necesita una solución de almacenamiento sólida y eficaz que permita utilizar los datos para mejorar el sistema actual o crear un nuevo producto. Una base de datos relacional como MySQL, PostgreSQL y SQLite resuelve estos problemas proporcionando una sólida gestión de bases de datos, seguridad y alto rendimiento.
Funciones básicas de SQL
SQL es una habilidad muy demandada que te ayudará a conseguir cualquier trabajo en el sector tecnológico. Empresas como Meta, Google y Netflix siempre están buscando profesionales de datos que puedan extraer información de bases de datos SQL y proponer soluciones innovadoras. Puedes aprender los conceptos básicos de SQL siguiendo el tutorial Introducción a SQL en DataCamp.
SQL puede ayudarnos a descubrir el rendimiento de la empresa, comprender los comportamientos de los clientes y controlar las métricas de éxito de las campañas de marketing. La mayoría de los analistas de datos pueden realizar la mayoría de las tareas de inteligencia empresarial ejecutando consultas SQL, así que ¿por qué necesitamos herramientas como PoweBI, Python y R? Las consultas SQL permiten saber qué ha ocurrido en el pasado, pero no predecir proyecciones futuras. Estas herramientas nos ayudan a comprender mejor el rendimiento actual y el crecimiento potencial.
Python y R son lenguajes polivalentes que permiten a los profesionales ejecutar análisis estadísticos avanzados, construir modelos de aprendizaje automático, crear API de datos y, en última instancia, ayudar a las empresas a pensar más allá de los KPI. En este tutorial, aprenderemos a conectar bases de datos SQL, rellenar bases de datos y ejecutar consultas SQL utilizando Python y R.
Nota: Si usted es nuevo en SQL, entonces tome la pista de habilidades SQL para entender los fundamentos de la escritura de consultas SQL.
El tutorial de Python cubrirá los aspectos básicos de la conexión con varias bases de datos (MySQL y SQLite), la creación de tablas, la adición de registros, la ejecución de consultas y el aprendizaje de la función de Pandas read_sql.
Podemos conectar la base de datos utilizando SQLAlchemy, pero en este tutorial, vamos a utilizar el paquete incorporado de Python SQLite3 para ejecutar consultas en la base de datos. SQLAlchemy ofrece soporte para todo tipo de bases de datos mediante una API unificada. Si estás interesado en aprender más sobre SQLAlchemy y cómo funciona con otras bases de datos, consulta el curso Introducción a las bases de datos en Python.
MySQL es el motor de bases de datos más popular del mundo, y es ampliamente utilizado por empresas como Youtube, Paypal, LinkedIn y GitHub. Aquí aprenderemos a conectar la base de datos. El resto de los pasos para utilizar MySQL son similares a los del paquete SQLite3.
Primero, instala el paquete mysql usando '!pip install mysql' y luego crea un motor de base de datos local proporcionando tu nombre de usuario, contraseña y nombre de la base de datos.
import mysql.connector as sql
conn = sql.connect(
host="localhost",
user="abid",
password="12345",
database="datacamp_python"
)
Del mismo modo, podemos crear o cargar una base de datos SQLite utilizando la función sqlite3.connect. SQLite es una biblioteca que implementa un motor de base de datos autónomo, sin configuración y sin servidor. Es compatible con DataLab, por lo que lo utilizaremos en nuestro proyecto para evitar errores de host local.
import sqlite3
import pandas as pd
conn= sqlite3.connect("datacamp_python.db")
En esta parte, aprenderemos a cargar el conjunto de datos COVID-19's impact on airport traffic, bajo licencia CC BY-NC-SA 4.0, en nuestra base de datos SQLite. También aprenderemos a crear tablas desde cero.

El conjunto de datos de tráfico del aeropuerto consiste en un porcentaje del volumen de tráfico durante el periodo de referencia comprendido entre el 1 de febrero de 2020 y el 15 de marzo de 2020. Cargaremos un archivo CSV utilizando la función de Pandas read_csv y luego utilizaremos la función to_sql para transferir el marco de datos a nuestra tabla SQLite. La función to_sql requiere un nombre de tabla (String) y la conexión al motor SQLite.
data = pd.read_csv("data/covid_impact_on_airport_traffic.csv")
data.to_sql(
'airport', # Name of the sql table
conn, # sqlite.Connection or sqlalchemy.engine.Engine
if_exists='replace'
)
Ahora comprobaremos si lo hemos conseguido ejecutando una rápida consulta SQL. Antes de ejecutar una consulta, necesitamos crear un cursor que nos ayudará a ejecutar consultas, como se muestra en el bloque de código siguiente. Puede tener varios cursores en la misma base de datos dentro de una misma conexión.
En nuestro caso, la consulta SQL devuelve tres columnas y cinco filas de la tabla de aeropuertos. Para mostrar la primera fila, utilizaremos cursor.fetchone().
cursor = conn.cursor()
cursor.execute("""SELECT Date, AirportName, PercentOfBaseline
FROM airport
LIMIT 5""")
cursor.fetchone()
>>> ('2020-04-03', 'Kingsford Smith', 64)
Para visualizar el resto de registros, utilizaremos cursor.fetchall(). El conjunto de datos del aeropuerto se carga correctamente en la base de datos con unas pocas líneas de código.
cursor.fetchall()
>>> [('2020-04-13', 'Kingsford Smith', 29),
('2020-07-10', 'Kingsford Smith', 54),
('2020-09-02', 'Kingsford Smith', 18),
('2020-10-31', 'Kingsford Smith', 22)]
Ahora vamos a aprender a crear una tabla desde cero y a rellenarla añadiendo valores de ejemplo. Crearemos una tabla studentinfo con id (entero, clave primaria, autoincremento), nombre (texto) y asunto (texto).
Nota: La sintaxis de SQLite es un poco diferente. Se recomienda consultar la hoja de trucos de SQLite para comprender las consultas SQL mencionadas en este tutorial.
cursor.execute("""
CREATE TABLE studentinfo
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
subject TEXT
)
""")
Comprobemos cuántas tablas hemos añadido a la base de datos ejecutando una sencilla consulta SQLite.
cursor.execute("""
SELECT name
FROM sqlite_master
WHERE type='table'
""")
cursor.fetchall()
>>> [('airport',), ('studentinfo',)]
En esta sección, añadiremos valores a la tabla studentinfo y ejecutaremos consultas SQL sencillas. Utilizando INSERT INTO, podemos añadir una única fila a la tabla studentinfo.
Para insertar valores, necesitamos proporcionar una consulta y argumentos de valor a la función execute. La función rellena las entradas "? " con los valores que hemos proporcionado.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
value = ("Marry", "Math")
cursor.execute(query,value)
Repita la consulta anterior añadiendo varios registros.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
values = [("Abid", "Stat"),
("Carry", "Math"),
("Ali","Data Science"),
("Nisha","Data Science"),
("Matthew","Math"),
("Henry","Data Science")]
cursor.executemany(query,values)
Es hora de verificar el registro. Para ello, ejecutaremos una sencilla consulta SQL que nos devolverá las filas cuyo asunto sea Data Science.
cursor.execute("""
SELECT *
FROM studentinfo
WHERE subject LIKE 'Data Science'
""")
cursor.fetchall()
>>> [(4, 'Ali', 'Data Science'),
(5, 'Nisha', 'Data Science'),
(7, 'Henry', 'Data Science')]
El comando DISTINCT subject se utiliza para mostrar valores únicos presentes en columnas de asunto. En nuestro caso, son Matemáticas, Estadística y Ciencia de Datos.
cursor.execute("SELECT DISTINCT subject from studentinfo")
cursor.fetchall()
>>> [('Math',), ('Stat',), ('Data Science',)]
Para guardar todos los cambios, utilizaremos la función commit(). Sin un commit, los datos se perderán tras el reinicio de la máquina.
conn.commit()
En esta parte aprenderemos a extraer los datos de la base de datos SQLite y convertirlos en un marco de datos Pandas con una sola línea de código. read_sql proporciona algo más que ejecutar consultas SQL. Podemos utilizarlo para establecer columnas de índice, analizar la fecha y la hora, añadir valores y filtrar nombres de columnas. Aprenda más sobre la importación de datos en Python realizando un breve curso DataCamp.
read_sql requiere dos argumentos: una consulta SQL y la conexión al motor SQLite. La salida contiene las cinco primeras filas de la tabla de aeropuertos en las que PercentOfBaseline es mayor que 20.
data_sql_1 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
""",
conn)
print(data_sql_1.head())
Date City PercentOfBaseline
0 2020-12-02 Sydney 27
1 2020-12-02 Santiago 48
2 2020-12-02 Calgary 99
3 2020-12-02 Leduc County 100
4 2020-12-02 Richmond 86
Realizar análisis de datos en bases de datos relacionales es ahora más fácil gracias a la integración de Pandas. También podemos utilizar estos datos para prever los valores y realizar complejos análisis estadísticos.
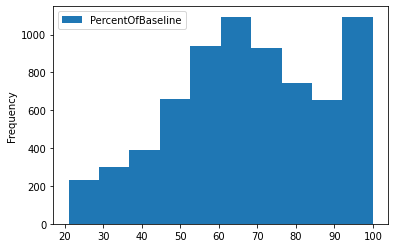
La función plot se utiliza para visualizar el histograma de la columna PercentOfBaseline.
data_sql_1.plot(y="PercentOfBaseline",kind="hist");
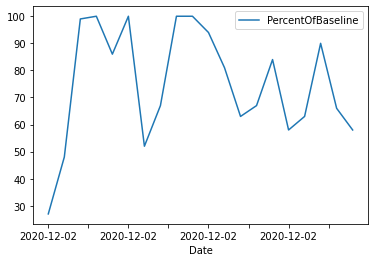
Del mismo modo, podemos limitar los valores a los 20 primeros y mostrar un gráfico lineal de series temporales.
data_sql_2 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
LIMIT 20
""",
conn)
data_sql_2.plot(x="Date",y="PercentOfBaseline",kind="line");
Por último, cerraremos la conexión para liberar recursos. La mayoría de los paquetes lo hacen automáticamente, pero es preferible cerrar las conexiones después de finalizar los cambios.
conn.close()
Vamos a replicar todas las tareas del tutorial de Python utilizando R. El tutorial incluye la creación de conexiones, la escritura de tablas, la adición de filas, la ejecución de consultas y el análisis de datos con dplyr.
El paquete DBI se utiliza para conectar con las bases de datos más populares, como MariaDB, Postgres, Duckdb y SQLite. Por ejemplo, instale el paquete RMySQL y cree una base de datos proporcionando un nombre de usuario, una contraseña, un nombre de base de datos y una dirección de host.
install.packages("RMySQL")
library(RMySQL)
conn = dbConnect(
MySQL(),
user = 'abid',
password = '1234',
dbname = 'datacamp_R',
host = 'localhost'
)
En este tutorial, vamos a crear una base de datos SQLite proporcionando un nombre y la función SQLite.
library(RSQLite)
library(DBI)
library(tidyverse)
conn = dbConnect(SQLite(), dbname = 'datacamp_R.db')
Al importar la biblioteca tidyverse, tendremos acceso a los conjuntos de datos dplyr, ggplot y defaults.
dbWriteTable toma data.frame y lo añade a la tabla SQL. Toma tres argumentos: conexión a SQLite, nombre de la tabla y marco de datos. Con dbReadTable, podemos ver toda la tabla. Para ver las 6 filas superiores, hemos utilizado head.
dbWriteTable(conn, "cars", mtcars)
head(dbReadTable(conn, "cars"))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
dbExecute nos permite ejecutar cualquier consulta SQLite, así que lo usaremos para crear una tabla llamada idcard.
Para mostrar los nombres de las tablas de la base de datos, utilizaremos dbListTables.
dbExecute(conn, 'CREATE TABLE idcard (id int, name text)')
dbListTables(conn)
>>> 'cars''idcard'
Añadamos una única fila a la tabla idcard y utilicemos dbGetQuery para mostrar los resultados.
Nota: dbGetQuery ejecuta una consulta y devuelve los registros mientras que dbExecute ejecuta una consulta SQL pero no devuelve ningún registro.
dbExecute(conn, "INSERT INTO idcard (id,name)\
VALUES(1,'love')")
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
Ahora añadiremos dos filas más y mostraremos los resultados utilizando dbReadTable.
dbExecute(conn,"INSERT INTO idcard (id,name)\
VALUES(2,'Kill'),(3,'Game')
")
dbReadTable(conn,'idcard')
id name
1 love
2 Kill
3 Game
dbCreateTable nos permite crear una mesa sin complicaciones. Requiere tres argumentos: conexión, nombre de la tabla y un vector de caracteres o un data.frame. El vector de caracteres consta de nombres (nombres de columna) y valores (tipos). En nuestro caso, vamos a proporcionar un data.frame de población por defecto para crear la estructura inicial.
dbCreateTable(conn,'population',population)
dbReadTable(conn,'population')
country year population
A continuación, vamos a utilizar dbAppendTable para añadir valores en la tabla de población.
dbAppendTable(conn,'population',head(population))
dbReadTable(conn,'population')
country year population
Afghanistan 1995 17586073
Afghanistan 1996 18415307
Afghanistan 1997 19021226
Afghanistan 1998 19496836
Afghanistan 1999 19987071
Afghanistan 2000 20595360
Utilizaremos dbGetQuery para realizar todas nuestras tareas de análisis de datos. Intentemos ejecutar una consulta sencilla y luego aprendamos más sobre otras funciones.
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
2 Kill
3 Game
También puede ejecutar una consulta SQL compleja para filtrar la potencia y mostrar filas y columnas limitadas.
dbGetQuery(conn, "SELECT mpg,hp,gear\
FROM cars\
WHERE hp > 50\
LIMIT 5")
mpg hp gear
21.0 110 4
21.0 110 4
22.8 93 4
21.4 110 3
18.7 175 3
Para eliminar tablas, utilice dbRemoveTable. Como podemos ver ahora, hemos eliminado con éxito la tabla idcard.
dbRemoveTable(conn,'idcard')
dbListTables(conn)
>>> 'cars''population'
Para comprender mejor las tablas, utilizaremos dbListFields, que mostrará los nombres de las columnas de una tabla determinada.
dbListFields(conn, "cars")
>>> 'mpg''cyl''disp''hp''drat''wt''qsec''vs''am''gear''carb'
En esta sección, usaremos dplyr para leer tablas y luego ejecutar consultas usando filter, select y collect. Si no quieres aprender sintaxis SQL y quieres realizar todas las tareas usando R puro, entonces este método es para ti. Hemos sacado la tabla de coches, la hemos filtrado por marchas y mpg, y luego hemos seleccionado tres columnas como se muestra a continuación.
cars_results <-
tbl(conn, "cars") %>%
filter(gear %in% c(4, 3),
mpg >= 14,
mpg <= 21) %>%
select(mpg, hp, gear) %>%
collect()
cars_results
mpg hp gear
21.0 110 4
21.0 110 4
18.7 175 3
18.1 105 3
14.3 245 3
... ... ...
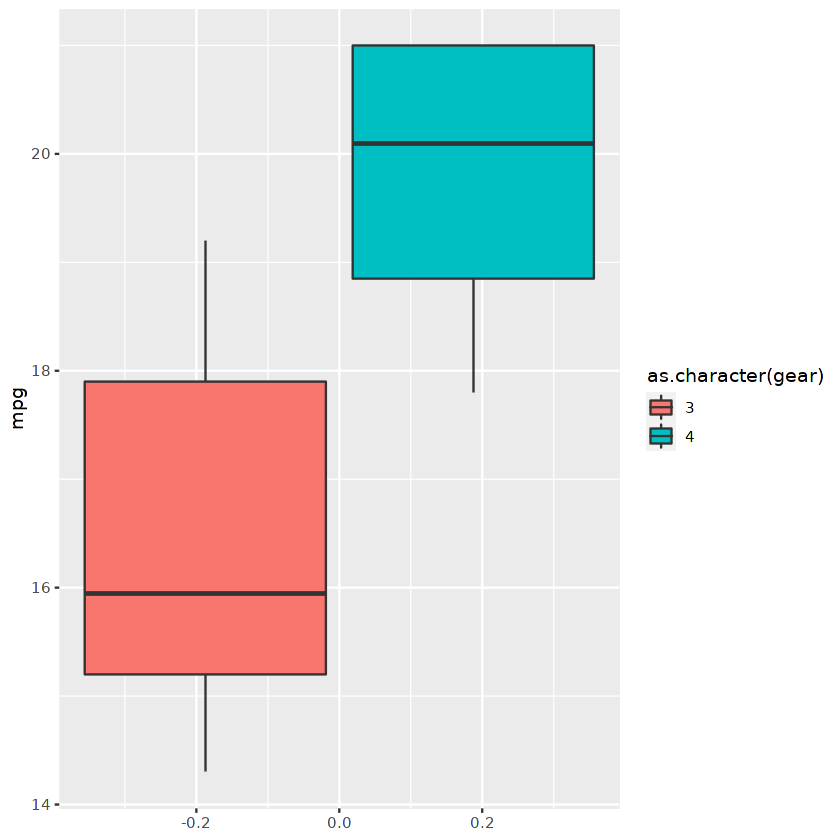
Podemos utilizar el marco de datos filtrado para mostrar un gráfico boxplot utilizando ggplot.
ggplot(cars_results,aes(fill=as.character(gear), y=mpg)) +
geom_boxplot()
O podemos mostrar un gráfico de puntos de faceta dividido por el número de marchas.
ggplot(cars_results,
aes(mpg, ..count.. ) ) +
geom_point(stat = "count", size = 4) +
coord_flip()+
facet_grid( as.character(gear) ~ . )
En este tutorial, hemos aprendido la importancia de ejecutar consultas SQL con Python y R, crear bases de datos, añadir tablas y realizar análisis de datos utilizando consultas SQL. También hemos aprendido cómo Pandas y dplyr nos ayudan a ejecutar consultas con una sola línea de código.
SQL es una habilidad imprescindible para todos los trabajos relacionados con la tecnología. Si está empezando su carrera como analista de datos, le recomendamos que complete el itinerario profesional de Analista de datos con SQL Server en un plazo de dos meses. Esta carrera le enseñará todo sobre consultas SQL, servidores y gestión de recursos.
Puede ejecutar gratuitamente todos los scripts utilizados en este tutorial:
Cursos relacionados de Python y SQL
Curso
Curso
Curso
blog
Javier Canales Luna
10 min
Tutorial
Abid Ali Awan
Tutorial
Joleen Bothma
Tutorial
Sejal Jaiswal
Tutorial
Elena Kosourova
Tutorial
Aditya Sharma
