GPT-3, la tercera generación de Generative Pre-trained Transformer. es un modelo de aprendizaje profundo de red neuronal de última generación creado por OpenAI. Al utilizar grandes cantidades de datos de Internet, GPT-3 puede producir textos diversos y sólidos generados por máquina con una entrada mínima. GPT-3 tiene una amplia gama de aplicaciones y no se limita al resumen de textos, la traducción, el desarrollo de chatbot y la generación de contenidos.
A pesar de su robustez, el rendimiento de GPT-3 puede mejorarse aún más ajustándolo a un caso de uso específico.
Pero, ¿qué entendemos por afinar?
Es el proceso de entrenamiento del GPT-3 preentrenado en un conjunto de datos de casos de uso personalizados. Esto permite que el modelo se adapte mejor a los matices de ese caso de uso o dominio específico, lo que conduce a resultados más precisos.
Los prerrequisitos para realizar con éxito el ajuste fino son (1) una comprensión básica de la programación en Python y (2) y una familiaridad con el aprendizaje automático y el procesamiento del lenguaje natural.
Nuestra Clasificación en el aprendizaje automático: Una introducción artículo le ayuda a aprender acerca de la clasificación en el aprendizaje automático, mirando a lo que es, cómo se utiliza, y algunos ejemplos de algoritmos de clasificación.
Utilizaremos el paquete openai Python proporcionado por OpenAI para que sea más cómodo utilizar su API y acceder a las capacidades de GPT-3.
Este artículo recorrerá el proceso de ajuste del modelo GPT-3 utilizando Python sobre los propios datos del usuario, cubriendo todos los pasos, desde la obtención de las credenciales de la API hasta la preparación de los datos, el entrenamiento del modelo y su validación.
¿Qué modelos de GPT pueden ajustarse?
Entre los modelos de GPT que se pueden afinar figuran Ada, Babbage, Curie y Davinci. Estos modelos pertenecen a la familia GPT-3. Además, es importante señalar que el ajuste fino no está disponible actualmente para los modelos GPT-3.5-turbo más recientes ni para otros GPT-4.
Lea nuestra guía para principiantes sobre GPT-3 para obtener más información sobre el modelo.
¿Cuáles son los casos más adecuados para ajustar la GPT?
La clasificación y la generación condicional son los dos tipos de problemas que pueden beneficiarse del ajuste fino de un modelo lingüístico como GPT-3. Analicemos brevemente cada una de ellas.
Clasificación
Para los problemas de clasificación, a cada entrada de la consulta se le asigna una de las clases predefinidas, y algunos de los casos se ilustran a continuación:
- Garantizar la veracidad de las declaraciones: Si una empresa quiere verificar que los anuncios de su sitio web mencionan el producto y la empresa correctos, un clasificador puede ajustarse para filtrar los anuncios incorrectos, asegurándose de que el modelo no está inventando cosas.
- Análisis del sentimiento: Se trata de clasificar el texto en función del sentimiento, como positivo, negativo o neutro.
- Categorización del triaje del correo electrónico: Para clasificar los correos electrónicos entrantes en una de las muchas categorías predefinidas, esas categorías se pueden convertir en números, que funcionan bien para hasta ~500 categorías.
Generación condicional
Los problemas de esta categoría consisten en generar contenidos a partir de una entrada dada. Las aplicaciones incluyen parafrasear, resumir, extraer entidades, redactar descripciones de productos, asistentes virtuales (chatbots), etc. Algunos ejemplos son:
- Creación de anuncios atractivos a partir de artículos de Wikipedia. En este caso de uso generativo, asegúrese de que las muestras proporcionadas son de alta calidad, ya que el modelo ajustado intentará imitar el estilo (y los errores) de los ejemplos.
- Extracción de entidades. Esta tarea se asemeja a un problema de transformación lingüística. Mejore el rendimiento ordenando las entidades extraídas alfabéticamente o en el mismo orden en que aparecen en el texto original.
- Chatbot de atención al cliente. Un chatbot suele incluir contexto relevante sobre la conversación (detalles del pedido), un resumen de la conversación hasta el momento y los mensajes más recientes.
- Descripción del producto basada en sus propiedades técnicas. Convertir los datos de entrada en un lenguaje natural para lograr un rendimiento superior en este contexto.
Cómo ajustar GPT-3 paso a paso
Es obligatorio crear una cuenta de desarrollador de OpenAI para acceder a la clave API, y los pasos se indican a continuación:
En primer lugar, crea una cuenta desde el sitio web oficial de OpenAI.
A continuación, seleccione el icono de perfil de usuario en la esquina superior derecha y haga clic en "Ver claves API" para acceder a la página de creación de una nueva clave API o de utilización de una ya existente.
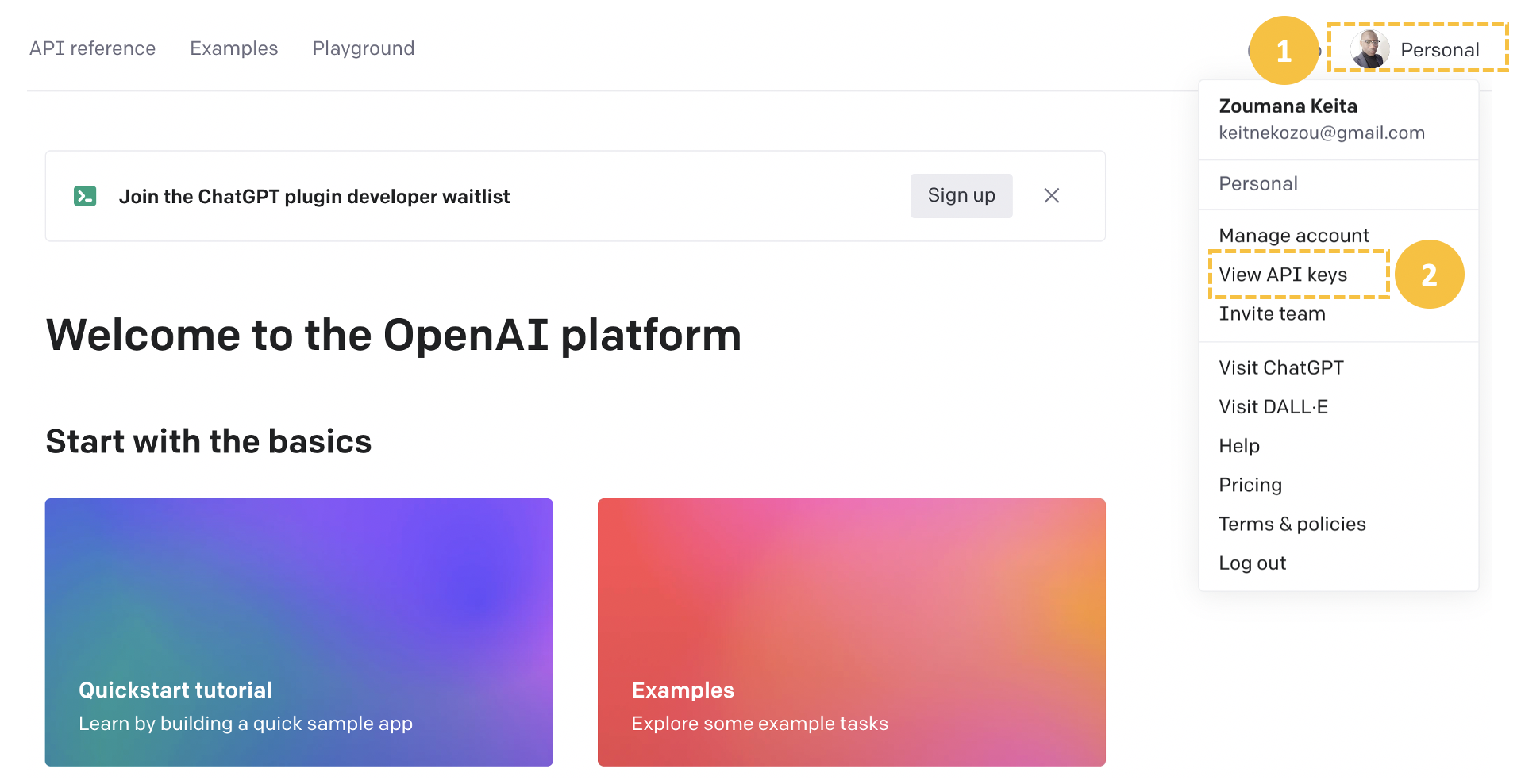
Cree una nueva clave secreta desde la pestaña "Crear nueva clave secreta" proporcionando un nombre significativo (GPT3_fine_tuning_key en este caso) y, a continuación, la clave API se generará automáticamente.
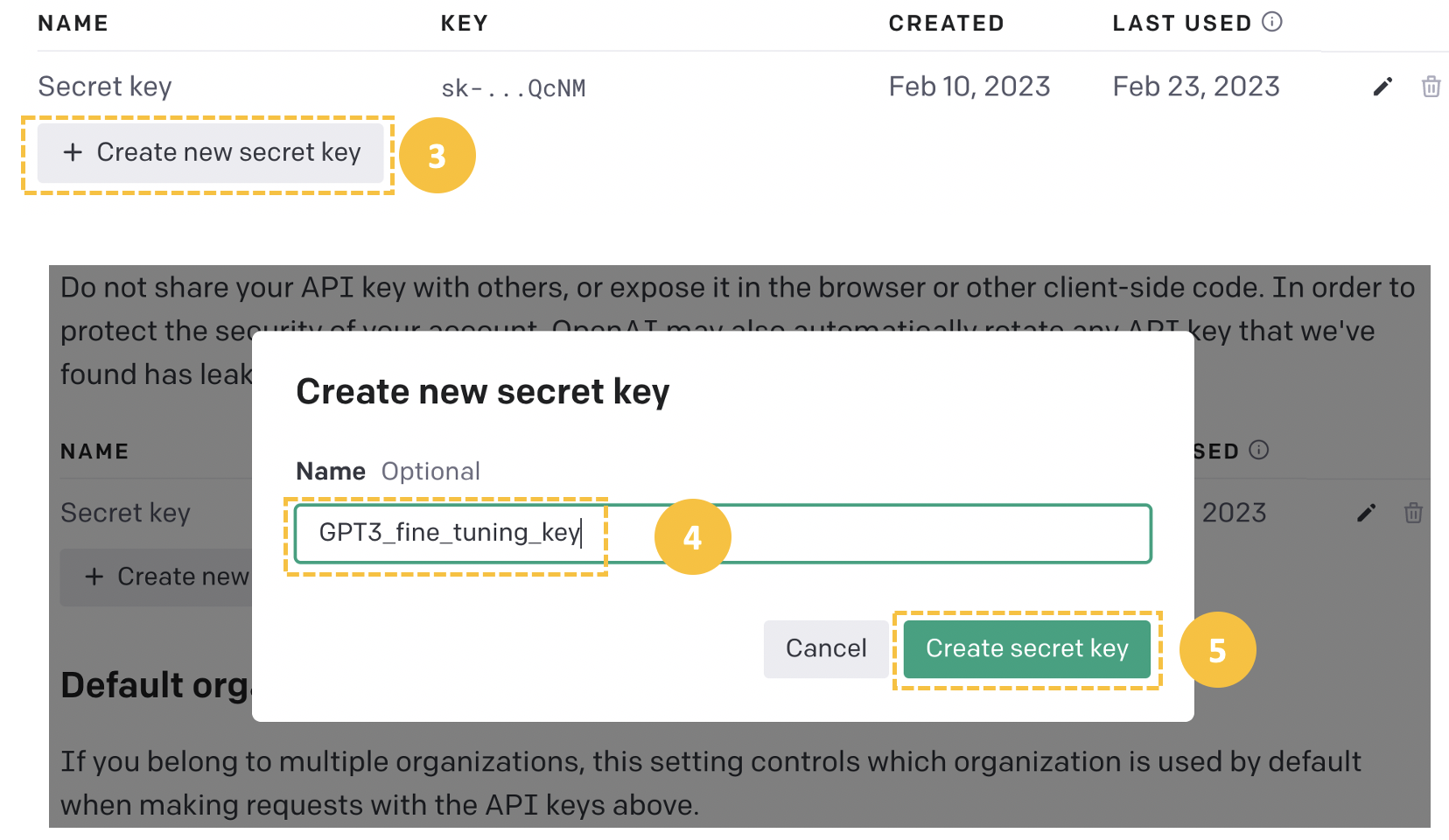
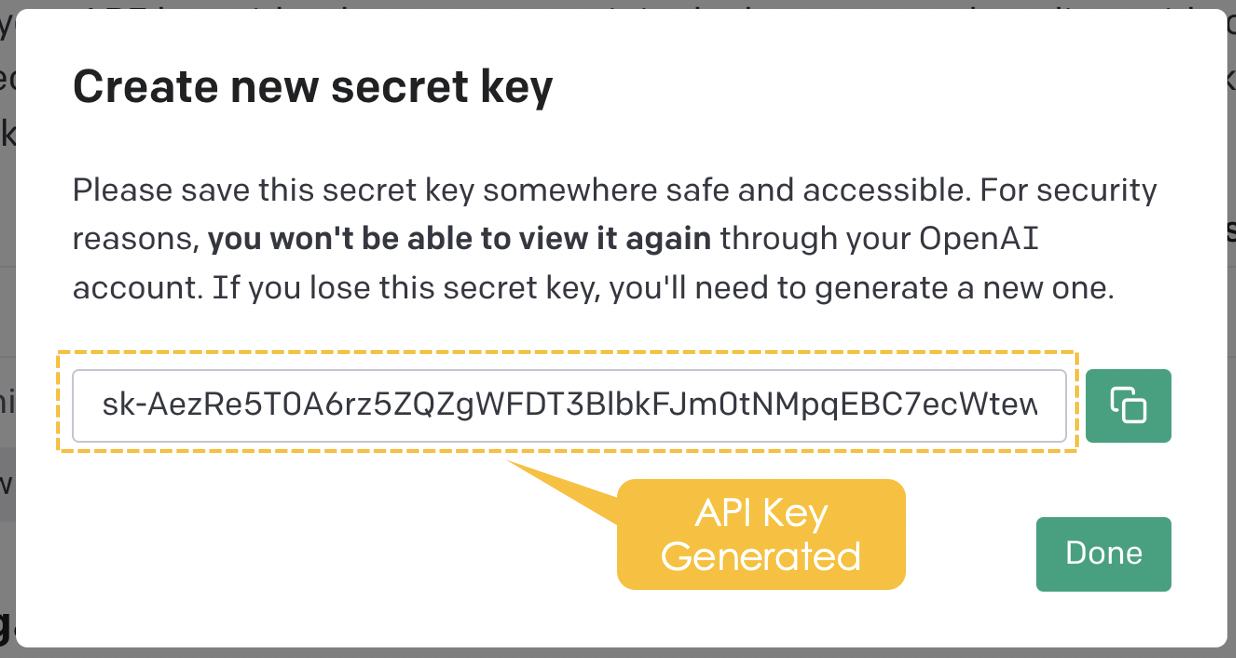
Si te quedas atascado o tienes dificultades, asegúrate de consultar el libro de trabajo DataLab con todo el código.
Conjunto de datos
En este caso de uso, pondremos a punto el modelo GPT-3 para un escenario de respuesta a preguntas, consistente en un patrón estructurado de pregunta-respuesta diseñado para ayudar al modelo a comprender la tarea que debe realizar. Se mantiene un formato coherente para cada par de preguntas y respuestas en todos los datos de entrenamiento y prueba.
Una instancia del conjunto de datos de preguntas-respuestas tiene el siguiente formato:
{
"prompt": "my prompt ->",
"completion": "the answer of the prompt. \n"
}- "prompt" es el texto de entrada leído y procesado por el modelo. El separador principal es el signo de flecha (->) para delimitar la pregunta de la respuesta esperada.
- "finalización" es la respuesta esperada a la pregunta. El signo de barra invertida "\n" se utiliza como secuencia de parada para indicar el final de la respuesta.
Una vez comprendido el formato del conjunto de datos, podemos generar tanto el conjunto de datos de entrenamiento como el de validación, como se muestra a continuación. Estas preguntas y respuestas se han generado utilizando ChatGPT.
Nuestra ChatGPT Cheat Sheet for Data Science proporciona a los usuarios acceso a más de 60 preguntas para tareas de Ciencia de Datos.
training_data = [
{
"prompt": "What is the capital of France?->",
"completion": """ The capital of France is Paris.\n"""
},
{
"prompt": "What is the primary function of the heart?->",
"completion": """ The primary function of the heart is to pump blood throughout the body.\n"""
},
{
"prompt": "What is photosynthesis?->",
"completion": """ Photosynthesis is the process by which green plants and some other organisms convert sunlight into chemical energy stored in the form of glucose.\n"""
},
{
"prompt": "Who wrote the play 'Romeo and Juliet'?->",
"completion": """ William Shakespeare wrote the play 'Romeo and Juliet'.\n"""
},
{
"prompt": "Which element has the atomic number 1?->",
"completion": """ Hydrogen has the atomic number 1.\n"""
},
{
"prompt": "What is the largest planet in our solar system?->",
"completion": """ Jupiter is the largest planet in our solar system.\n"""
},
{
"prompt": "What is the freezing point of water in Celsius?->",
"completion": """ The freezing point of water in Celsius is 0 degrees.\n"""
},
{
"prompt": "What is the square root of 144?->",
"completion": """ The square root of 144 is 12.\n"""
},
{
"prompt": "Who is the author of 'To Kill a Mockingbird'?->",
"completion": """ The author of 'To Kill a Mockingbird' is Harper Lee.\n"""
},
{
"prompt": "What is the smallest unit of life?->",
"completion": """ The smallest unit of life is the cell.\n"""
}
]
validation_data = [
{
"prompt": "Which gas do plants use for photosynthesis?->",
"completion": """ Plants use carbon dioxide for photosynthesis.\n"""
},
{
"prompt": "What are the three primary colors of light?->",
"completion": """ The three primary colors of light are red, green, and blue.\n"""
},
{
"prompt": "Who discovered penicillin?->",
"completion": """ Sir Alexander Fleming discovered penicillin.\n"""
},
{
"prompt": "What is the chemical formula for water?->",
"completion": """ The chemical formula for water is H2O.\n"""
},
{
"prompt": "What is the largest country by land area?->",
"completion": """ Russia is the largest country by land area.\n"""
},
{
"prompt": "What is the speed of light in a vacuum?->",
"completion": """ The speed of light in a vacuum is approximately 299,792 kilometers per second.\n"""
},
{
"prompt": "What is the currency of Japan?->",
"completion": """ The currency of Japan is the Japanese Yen.\n"""
},
{
"prompt": "What is the smallest bone in the human body?->",
"completion": """ The stapes, located in the middle ear, is the smallest bone in the human body.\n"""
}
]Configurar
Antes de sumergirnos en el proceso de implementación, necesitamos preparar el entorno de trabajo instalando las librerías necesarias, especialmente la librería OpenAI Python, como se muestra a continuación:
pip install --upgrade openaiAhora podemos importar la biblioteca.
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ['OPENAI_API_KEY'],
)Preparar el conjunto de datos
Tratar con el formato de lista, como se muestra arriba, puede ser conveniente para conjuntos de datos pequeños. Sin embargo, guardar los datos en formato JSONL (JSON Lines) tiene varias ventajas. Las ventajas incluyen escalabilidad, interoperabilidad, simplicidad y también compatibilidad con la API OpenAI, que requiere datos en formato JSONL al crear trabajos de ajuste.
El siguiente código aprovecha la función de ayuda prepare_data para crear los datos de entrenamiento y validación en formato JSONL:
import json
training_file_name = "training_data.jsonl"
validation_file_name = "validation_data.jsonl"
def prepare_data(dictionary_data, final_file_name):
with open(final_file_name, 'w') as outfile:
for entry in dictionary_data:
json.dump(entry, outfile)
outfile.write('\n')
prepare_data(training_data, "training_data.jsonl")
prepare_data(validation_data, "validation_data.jsonl")Por último, subimos los dos conjuntos de datos a la cuenta de desarrollador de OpenAI de la siguiente manera:
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")La ejecución correcta del código anterior muestra debajo el identificador único de los datos de entrenamiento y validación.

En este nivel tenemos toda la información para proceder a la puesta a punto.
Crear un trabajo de ajuste
Este proceso de puesta a punto está muy inspirado en el openai-cookbook que realiza la puesta a punto en Microsoft Azure.
Para realizar el ajuste fino utilizaremos los dos pasos siguientes: (1) definir los hiperparámetros, y (2) activar el ajuste fino.
Pondremos a punto el modelo davinci y lo ejecutaremos durante 15 épocas utilizando un tamaño de lote de 3 y un multiplicador de la tasa de aprendizaje de 0,3 utilizando los conjuntos de datos de entrenamiento y validación.
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="davinci-002",
hyperparameters={
"n_epochs": 15,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")El código anterior genera la siguiente información para el jobID (`ftjob-WsCjQMEmSvRMFCbhdTqxZzOf`), la respuesta de formación y el estado de la formación (pendiente).

Este estado pendiente no proporciona ninguna información relevante. Sin embargo, podemos tener más información sobre el proceso de formación ejecutando el siguiente código:
import signal
import datetime
def signal_handler(sig, frame):
status = client.fine_tuning.jobs.retrieve(job_id).status
print(f"Stream interrupted. Job is still {status}.")
return
print(f"Streaming events for the fine-tuning job: {job_id}")
signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id)
try:
for event in events:
print(
f'{datetime.datetime.fromtimestamp(event.created_at)} {event.message}'
)
except Exception:
print("Stream interrupted (client disconnected).")A continuación se generan todas las épocas, junto con el estado del ajuste fino, que se realiza con éxito.
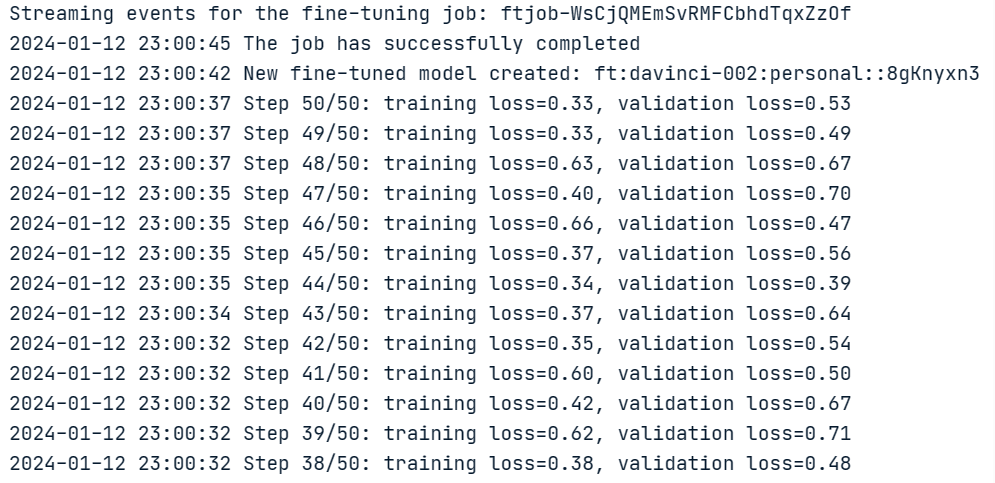
Comprobar el estado del trabajo de ajuste
Verifiquemos que nuestra operación ha tenido éxito y, además, podemos examinar todas las operaciones de ajuste fino utilizando una operación de lista.
import time
status = client.fine_tuning.jobs.retrieve(job_id).status
if status not in ["succeeded", "failed"]:
print(f"Job not in terminal status: {status}. Waiting.")
while status not in ["succeeded", "failed"]:
time.sleep(2)
status = client.fine_tuning.jobs.retrieve(job_id).status
print(f"Status: {status}")
else:
print(f"Finetune job {job_id} finished with status: {status}")
print("Checking other finetune jobs in the subscription.")
result = client.fine_tuning.jobs.list()
print(f"Found {len(result.data)} finetune jobs.")A continuación se muestra el resultado de la ejecución:

Hay un total de 2 trabajos de ajuste fino.
Validación del modelo
Por último, el modelo ajustado puede recuperarse a partir del atributo "fine_tuned_model". La siguiente sentencia print muestra que el nombre del modo final es: `ft:davinci-002:personal::8gKnyxn3`
# Retrieve the finetuned model
fine_tuned_model = result.data[0].fine_tuned_model
print(fine_tuned_model)
![]()
Con este modelo, podemos ejecutar consultas para validar sus resultados proporcionando un prompt, el nombre del modelo, y creando una consulta con la función openai.Completion.create(). El resultado se recupera del diccionario de respuestas de la siguiente manera:
new_prompt = "Which part is the smallest bone in the entire human body?"
answer = client.completions.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer.choices[0].text)
new_prompt = "Which type of gas is utilized by plants during the process of photosynthesis?"
answer = client.completions.create(
model=fine_tuned_model,
prompt=new_prompt
)
print(answer.choices[0].text)Aunque las preguntas no están escritas exactamente igual que en el conjunto de datos de validación, el modelo consiguió asignarlas a las respuestas correctas. A continuación figuran las respuestas a las solicitudes anteriores.

Con muy pocas muestras de entrenamiento, conseguimos tener un modelo afinado decente. Se pueden obtener mejores resultados con un tamaño de entrenamiento mayor.
Conclusión
En este artículo hemos explorado el potencial de GPT-3 y analizado el proceso de ajuste del modelo para mejorar su rendimiento en casos de uso específicos. Hemos esbozado los requisitos previos para perfeccionar con éxito GPT-3, incluidos unos conocimientos básicos de programación en Python y familiaridad con el aprendizaje automático y el procesamiento del lenguaje natural.
Además, hemos introducido el paquete openai Python, utilizado para simplificar el proceso de acceso a las capacidades de GPT-3 a través de la API de OpenAI. El artículo ha cubierto todos los pasos necesarios para poner a punto el modelo GPT-3 utilizando Python y conjuntos de datos personalizados, desde la obtención de las credenciales de la API hasta la preparación de los datos, el entrenamiento del modelo y su validación.
Al destacar las ventajas del ajuste fino y ofrecer una guía completa del proceso, este artículo pretende ayudar a los científicos de datos, desarrolladores y otras partes interesadas con las herramientas y conocimientos necesarios para crear modelos GPT-3 más precisos y eficientes adaptados a sus necesidades y requisitos específicos.
Tenemos un artículo que trata de ¿Qué es GPT-4 y por qué es importante? y también Una introducción al uso de transformadores y el tutorial Cara de abrazo. Asegúrese de leerlos para llevar sus conocimientos al siguiente nivel.



