Curso
Python intermedio
4 h
1.4M
La amplia contribución de los investigadores en PNL, abreviatura de Procesamiento del Lenguaje Natural, durante las últimas décadas ha ido generando resultados innovadores en distintos dominios. A continuación te mostramos algunos ejemplos del Procesamiento del Lenguaje Natural en la práctica:
Este blog conceptual pretende cubrir los Transformadores, uno de los modelos más potentes jamás creados en el Procesamiento del Lenguaje Natural. Tras explicar sus ventajas en comparación con las redes neuronales recurrentes, desarrollaremos su comprensión de los Transformadores. A continuación, te guiaremos por algunos casos reales utilizando transformadores Huggingface.
También puedes aprender más sobre Cómo crear aplicaciones PNL con Hugging Face con nuestro code-along.
Antes de sumergirnos en el concepto básico de los transformadores, entendamos brevemente qué son los modelos recurrentes y sus limitaciones.
Las redes recurrentes emplean la arquitectura codificador-decodificador, y las utilizamos principalmente cuando se trata de tareas en las que tanto la entrada como las salidas son secuencias en algún orden definido. Algunas de las mayores aplicaciones de las redes recurrentes son la traducción automática y el modelado de datos de series temporales.
Consideremos la traducción al inglés de la siguiente frase en francés. La entrada transmitida al codificador es la frase original en francés, y la salida traducida la genera el descodificador.
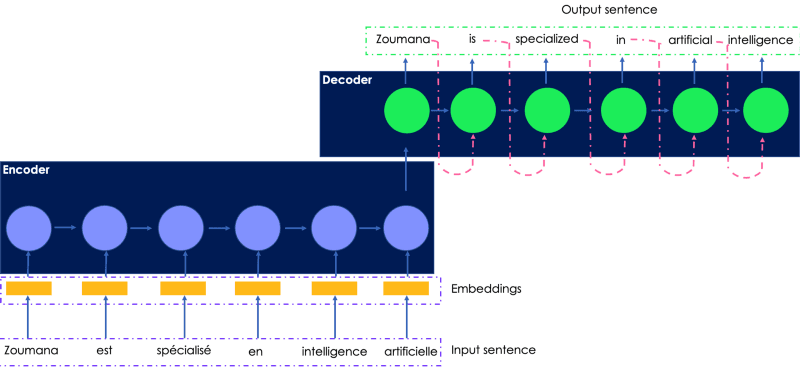
Una ilustración sencilla de la red recurrente para la traducción de idiomas
¿No sería estupendo disponer de un modelo que combinara las ventajas de las redes recurrentes y posibilitara el cálculo paralelo?
Aquí es donde los transformadores resultan útiles.
Transformers es la nueva arquitectura de red neuronal, sencilla pero potente, introducida por Google Brain en 2017 con su famoso trabajo de investigación "La atención es todo lo que necesitas". Se basa en el mecanismo de la atención en lugar del cómputo secuencial que podríamos observar en las redes recurrentes.
Al igual que las redes recurrentes, las transformantes también tienen dos bloques principales: codificador y decodificador, cada uno con un mecanismo de autoatención. La primera versión de los transformadores tenía una arquitectura de codificador-decodificador RNN y LSTM, que más tarde se han transformado en redes de autoatención y feed-forward.
La sección siguiente ofrece una visión general de los principales componentes de cada bloque de transformadores.
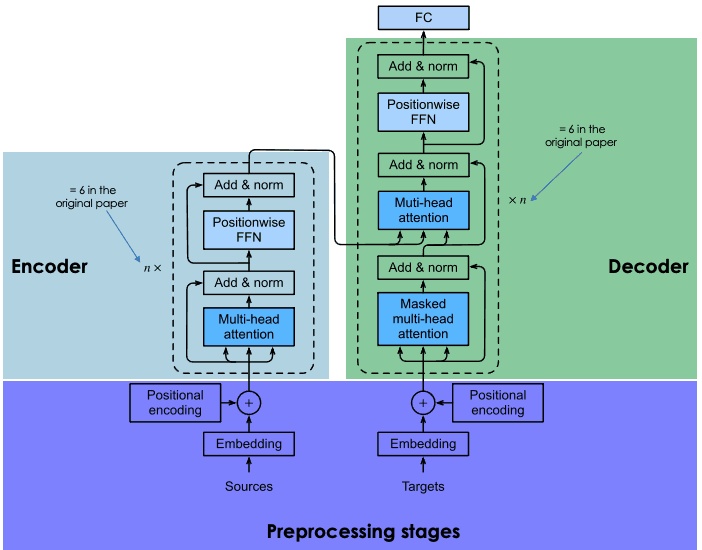
Arquitectura general de los transformadores (adaptado por el Autor)
Esta sección contiene dos pasos principales: (1) la generación de las incrustaciones de la frase de entrada, y (2) el cálculo del vector posicional de cada palabra en la frase de entrada. Todos los cálculos se realizan de la misma manera tanto para la frase origen (antes del bloque codificador) como para la frase destino (antes del bloque decodificador).
Antes de generar las incrustaciones de los datos de entrada, empezamos realizando la tokenización, y luego creamos la incrustación de cada palabra individual sin prestar atención a su relación en la frase.
La tarea de tokenización descarta cualquier noción de relación que existiera en la frase de entrada. La codificación posicional intenta crear la naturaleza cíclica original generando un vector de contexto para cada palabra.
Al final del paso anterior, obtenemos para cada palabra dos vectores: (1) la incrustación y (2) su vector de contexto. Estos vectores se suman para crear un vector único para cada palabra, que luego se transmite al codificador.
Como ya se ha dicho, perdimos toda noción de relación. El objetivo de la capa de atención es captar las relaciones contextuales existentes entre las distintas palabras de la frase de entrada. Este paso acaba generando un vector de atención para cada palabra.
En esta fase, se aplica una red neuronal feed-forward a cada vector de atención para transformarlos en un formato esperado por la siguiente capa de atención multicabezal del descodificador.
El bloque decodificador consta de tres capas principales: atención multicabezal enmascarada, atención multicabezal y una red feed-forward en función de la posición. Ya entendemos las dos últimas capas, que son las mismas en el codificador.
El descodificador entra en la ecuación durante el entrenamiento de la red, y recibe dos entradas principales: (1) los vectores de atención de la frase de entrada que queremos traducir y (2) las frases de destino traducidas al inglés.
Durante la generación de la siguiente palabra inglesa, la red puede utilizar todas las palabras de la palabra francesa. Sin embargo, cuando se trata de una palabra determinada de la secuencia de destino (traducción al inglés), la red sólo tiene que acceder a las palabras anteriores, ya que poner a disposición las siguientes hará que la red "haga trampas" y no se esfuerce por aprender correctamente. Aquí es donde la capa de atención multicabezal enmascarada tiene todas sus ventajas. Enmascara esas palabras siguientes transformándolas en ceros para que no puedan ser utilizadas por la red de atención.
El resultado de la capa de atención multicabeza enmascarada pasa por el resto de capas para predecir la siguiente palabra generando una puntuación de probabilidad.
Esta arquitectura tuvo éxito por las siguientes razones:
Entrenar redes neuronales profundas como los transformadores desde cero no es una tarea fácil, y puede presentar los siguientes retos:
Utilizar el aprendizaje por transferencia puede tener muchas ventajas, como reducir el tiempo de entrenamiento, acelerar el proceso de entrenamiento de nuevos modelos y disminuir el plazo de entrega del proyecto.
Imagina construir un modelo desde cero para traducir la lengua mandinga al wolof, que son lenguas de bajos recursos. Recopilar datos relacionados con esas lenguas es costoso. En lugar de pasar por todos estos retos, se pueden reutilizar redes neuronales profundas preentrenadas como punto de partida para entrenar el nuevo modelo.
Dichos modelos se han entrenado con un enorme corpus de datos, puesto a disposición por otra persona (persona moral, organización, etc.), y se ha evaluado que funcionan muy bien en tareas de traducción de idiomas como el francés al inglés.
Si eres nuevo en PNL, este curso de Introducción al Procesamiento del Lenguaje Natural en Python puede proporcionarte las habilidades fundamentales para realizar y resolver problemas del mundo real.
Pero, ¿qué entiendes por reutilización de redes neuronales profundas?
La reutilización del modelo implica elegir el modelo preentrenado que sea similar a tu caso de uso, refinar los datos del par entrada-salida de tu tarea objetivo y volver a entrenar la cabeza del modelo preentrenado utilizando tus datos.
La introducción de los Transformadores ha conducido al desarrollo de modelos de aprendizaje por transferencia de última generación, como:
Hugging Face es una comunidad de IA y una plataforma de Aprendizaje Automático creada en 2016 por Julien Chaumond, Clément Delangue y Thomas Wolf. Su objetivo es democratizar la PNL proporcionando a los científicos de datos, profesionales de la IA e ingenieros acceso inmediato a más de 20.000 modelos preentrenados basados en la arquitectura de transformadores de última generación. Estos modelos pueden aplicarse a:
Hugging Face Transformers también proporciona casi 2000 conjuntos de datos y API por capas, lo que permite a los programadores interactuar fácilmente con esos modelos utilizando casi 31 bibliotecas. La mayoría son de aprendizaje profundo, como Pytorch, Tensorflow, Jax, ONNX, Fastai, Stable-Baseline 3, etc.
Estos cursos son una gran introducción al uso de Pytorch y Tensorflow para construir respectivamente redes neuronales convolucionales profundas. Otros componentes de los Transformadores de Cara Abrazada son las Tuberías.
El método pipeline() tiene la siguiente estructura:
from transformers import pipeline
# To use a default model & tokenizer for a given task(e.g. question-answering)
pipeline("<task-name>")
# To use an existing model
pipeline("<task-name>", model="<model_name>")
# To use a custom model/tokenizer
pipeline('<task-name>', model='<model name>',tokenizer='<tokenizer_name>')Ahora que conoces mejor los Transformers y la plataforma Cara Abrazada, te guiaremos a través de los siguientes escenarios del mundo real: traducción de idiomas, clasificación de secuencias con clasificación de disparo cero, análisis de sentimientos y respuesta a preguntas.
Este conjunto de datos está disponible en Datacamp El conjunto de datos está enriquecido por Facebook y se creó para predecir la popularidad de un artículo antes de su publicación. El análisis se basará en la columna de descripción. Para ilustrar nuestros ejemplos, utilizaremos sólo tres ejemplos de los datos.
A continuación encontrarás una breve descripción de los datos. Tiene 14 columnas y 1428 filas.
import pandas as pd
# Load the data from the path
data_path = "datacamp_workspace_export_2022-08-08 07_56_40.csv"
news_data = pd.read_csv(data_path, error_bad_lines=False)
# Show data information
news_data.info()
MariamMT es un marco eficaz de Traducción Automática. Utiliza el motor MarianNMT, desarrollado íntegramente en C++ por Microsoft y muchas instituciones académicas, como la Universidad de Edimburgo y la Universidad Adam Mickiewicz de Poznań. El mismo motor está actualmente detrás del servicio Traductor de Microsoft.
El grupo de PNL de la Universidad de Helsinki ha puesto a disposición pública varios modelos de traducción en Transformadores de Caras Abrazadas y todos tienen el siguiente formato Helsinki-NLP/opus-mt-{src}-{tgt}, donde {src} y {tgt} corresponden respectivamente a las lenguas de origen y de destino.
Así, en nuestro caso, la lengua de partida es el inglés (en) y la lengua de llegada es el francés (fr)
MarianMT es uno de esos modelos previamente entrenados con Marian sobre datos paralelos recogidos en Opus.
pip install transformers sentencepiece
from transformers import MarianTokenizer, MarianMTModel# Get the name of the model
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Get the tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Instantiate the model
model = MarianMTModel.from_pretrained(model_name)def format_batch_texts(language_code, batch_texts):
formated_bach = [">>{}<< {}".format(language_code, text) for text in
batch_texts]
return formated_bachdef perform_translation(batch_texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts,
return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts# Check the model translation from the original language (English) to French
translated_texts = perform_translation(english_texts, trans_model, trans_model_tkn)
# Create wrapper to properly format the text
from textwrap import TextWrapper
# Wrap text to 80 characters.
wrapper = TextWrapper(width=80)
for text in translated_texts:
print("Original text: \n", text)
print("Translation : \n", text)
print(print(wrapper.fill(text)))
print("")
La mayoría de las veces, el entrenamiento de un modelo de Aprendizaje Automático requiere que se conozcan de antemano todas las etiquetas/objetivos candidatos, lo que significa que si tus etiquetas de entrenamiento son ciencia, política o educación, no podrás predecir la etiqueta de sanidad a menos que vuelvas a entrenar tu modelo, teniendo en cuenta esa etiqueta y los datos de entrada correspondientes.
Este potente enfoque permite predecir el objetivo de un texto en unas 15 lenguas sin haber visto ninguna de las etiquetas candidatas. Podemos utilizar este modelo simplemente cargándolo desde el centro.
El objetivo aquí es intentar clasificar la categoría de cada una de las descripciones anteriores, ya sea tecnología, política, seguridad o finanzas.
from transformers import pipelinecandidate_labels = ["tech", "politics", "business", "finance"]my_classifier = pipeline("zero-shot-classification",
model='joeddav/xlm-roberta-large-xnli')#For the first description
prediction = my_classifier(english_texts[0], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)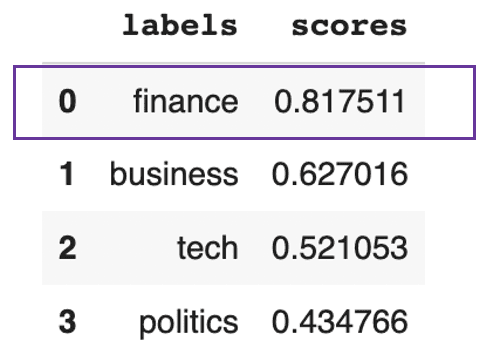
Se prevé que el texto trate principalmente de finanzas
Este resultado anterior muestra que el texto trata globalmente sobre finanzas, con un 81%.
Para la última descripción, obtenemos el resultado siguiente:
#For the last description
prediction = my_classifier(english_texts[-1], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)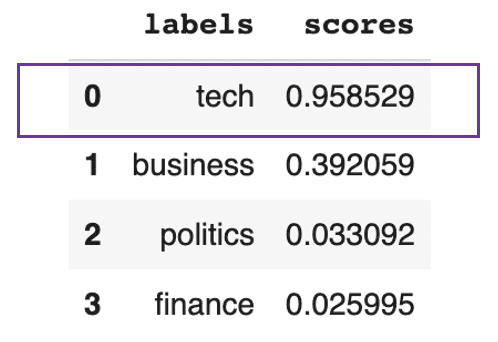
Se prevé que el texto trate principalmente de tecnología
Este resultado anterior muestra que, en general, el texto es técnico en un 95%.
La mayoría de los modelos que realizan la clasificación de sentimientos requieren un entrenamiento adecuado. El módulo hugging Face pipeline facilita la ejecución de predicciones de análisis de sentimiento utilizando un modelo específico disponible en el hub especificando su nombre.
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)# Run the predictions
distil_bert_model(english_texts[1:])
El modelo predijo que el primer texto tenía un sentimiento negativo con un 96% de confianza, y que el segundo tenía un sentimiento positivo con un 52% de confianza.
Si quieres profundizar en las tareas de análisis de sentimientos, este curso de Análisis de Sentimientos en Python te ayudará a adquirir las habilidades necesarias para construir tu propio clasificador de análisis de sentimientos utilizando Python y a comprender los fundamentos de la PLN.
Imagina enfrentarte a un informe mucho más largo que el de Apple. Y lo único que te interesa es la fecha del acontecimiento que se menciona. En lugar de leer todo el informe para encontrar la información clave, podemos utilizar un modelo de pregunta-respuesta de Cara Abrazada que nos dará la respuesta que nos interesa.
Esto puede hacerse proporcionando al modelo el contexto adecuado (el informe de Apple) y la pregunta cuya respuesta nos interesa encontrar.
from transformers import AutoModelForQuestionAnswering, AutoTokenizermodel_checkpoint = "deepset/roberta-base-squad2"
task = 'question-answering'
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)QA_input = {
'question': 'when is Apple hosting an event?',
'context': english_texts[-1]
}model_response = QA_model(QA_input)
pd.DataFrame([model_response])
El modelo respondió que el evento de Apple es el 10 de septiembre con una confianza alta del 97%.
En este artículo, hemos cubierto la evolución de la tecnología del lenguaje natural, desde las redes recurrentes hasta los transformadores, y cómo Hugging Face ha democratizado el uso de la PNL a través de su plataforma.
Si aún tienes dudas sobre el uso de transformadores, creemos que ha llegado el momento de darles una oportunidad y añadir valor a tus casos empresariales.
Cursos para Python
Curso
Curso
Curso
Tutorial
Satyam Tripathi
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
