Curso
Aprendizaje supervisado en R: Clasificación
4 h
100.4K
Hoy en día, muchos sectores trabajan con conjuntos de datos muy grandes de distintos tipos. Procesar manualmente toda esa información puede llevar mucho tiempo e incluso puede no añadir valor a largo plazo. Se están aplicando muchas estrategias, desde la simple automatización a las técnicas de machine learning, para obtener un mayor rendimiento de la inversión. Este blog conceptual tratará uno de los conceptos más importantes: la clasificación en machine learning.
Empezaremos definiendo qué es la clasificación en machine learning antes de aclarar los dos tipos de aprendices de machine learning y la diferencia entre clasificación y regresión. A continuación, abordaremos algunos casos del mundo real en los que se puede utilizar la clasificación. Después, presentaremos los distintos tipos de clasificación y profundizaremos en algunos ejemplos de algoritmos de clasificación. Por último, realizaremos prácticas sobre la implementación de algunos algoritmos.
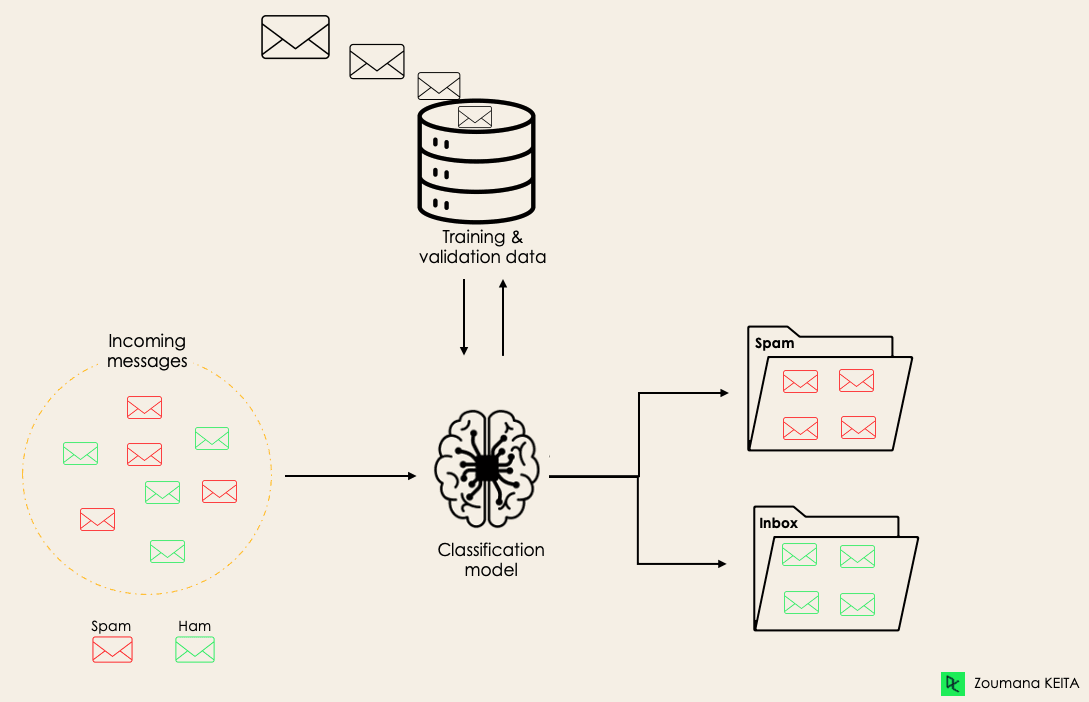
La clasificación es un método de machine learning supervisado en el que el modelo intenta prever la etiqueta correcta de unos datos de entrada dados. En la clasificación, el modelo se entrena completamente con los datos de entrenamiento y, luego, se evalúa con los datos de prueba antes de utilizarse para realizar previsiones con nuevos datos no vistos.
Por ejemplo, un algoritmo puede aprender a prever si un determinado correo electrónico es spam o no, como se muestra a continuación.
 Antes de sumergirnos en el concepto de clasificación, comprenderemos la diferencia entre los dos tipos de aprendices de la clasificación: los aprendices vagos y los ansiosos. A continuación aclararemos la diferencia entre clasificación y regresión.
Antes de sumergirnos en el concepto de clasificación, comprenderemos la diferencia entre los dos tipos de aprendices de la clasificación: los aprendices vagos y los ansiosos. A continuación aclararemos la diferencia entre clasificación y regresión.
En la clasificación del machine learning hay dos tipos de aprendices: los vagos y los ansiosos.
Los aprendices ansiosos son algoritmos de machine learning que primero crean un modelo a partir del conjunto de datos de entrenamiento y, luego, hacen previsiones con conjuntos de datos futuros. Dedican más tiempo al proceso de entrenamiento porque están ansiosos por tener una mejor generalización durante el entrenamiento a partir del aprendizaje de los pesos, pero requieren menos tiempo para hacer previsiones.
La mayoría de los algoritmos de machine learning son aprendices ansiosos. A continuación te damos algunos ejemplos:
En cambio, los aprendices vagos o basados en instancias no crean ningún modelo inmediatamente a partir de los datos de entrenamiento, y de ahí viene lo de vagos. Se limitan a memorizar los datos de entrenamiento y, cada vez que es necesario hacer una previsión, buscan al vecino más próximo en todos los datos de entrenamiento, lo que los hace muy lentos durante la previsión. Algunos ejemplos de este tipo son:
Sin embargo, algunos algoritmos, como BallTrees y KDTrees, pueden utilizarse para mejorar la latencia de la previsión.
Hay cuatro categorías principales de algoritmos de machine learning: aprendizaje supervisado, no supervisado, semisupervisado y por refuerzo.
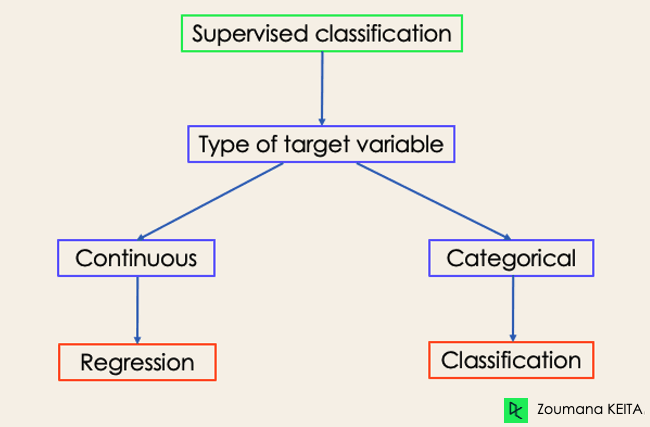
Aunque tanto la clasificación como la regresión pertenecen a la categoría de aprendizaje supervisado, no son lo mismo.
Si te interesa saber más sobre clasificación, los cursos Aprendizaje supervisado con scikit-learn y Aprendizaje supervisado en R pueden serte útiles. Te permiten comprender mejor cómo aborda las tareas cada algoritmo y las funciones de Python y R necesarias para implementarlos.
En cuanto a la regresión, Introducción a la regresión en R e Introducción a la regresión con statsmodels en Python te ayudarán a explorar distintos tipos de modelos de regresión, así como su implementación en R y Python.
 Ejemplos de clasificación de machine learning en la vida real
Ejemplos de clasificación de machine learning en la vida real La clasificación de machine learning supervisado tiene distintas aplicaciones en varios dominios de nuestra vida cotidiana. Aquí tienes algunos ejemplos.
Entrenar un modelo de machine learning con datos históricos de pacientes puede ayudar a los especialistas sanitarios a analizar con precisión sus diagnósticos:
La educación es uno de los dominios que más datos textuales, de vídeo y de audio maneja. Esta información no estructurada puede analizarse con ayuda de las tecnologías del lenguaje natural para realizar distintas tareas, como:
El transporte es el componente clave del desarrollo económico de muchos países. Por ello, los sectores utilizan modelos de machine learning y aprendizaje profundo:
La agricultura es uno de los pilares de la supervivencia humana. Introducir la sostenibilidad puede ayudar a mejorar la productividad de los agricultores a otro nivel sin dañar el medioambiente:
Hay cuatro tareas principales de clasificación en machine learning: clasificaciones binarias, multiclase, multietiqueta y desequilibradas.
En una tarea de clasificación binaria, el objetivo es clasificar los datos de entrada en dos categorías mutuamente excluyentes. En tal situación, los datos de entrenamiento se etiquetan con formato binario: verdadero y falso; positivo y negativo; O y 1; spam y no spam, etc., según el problema que se aborde. Por ejemplo, podríamos querer detectar si una imagen dada es un camión o un barco.
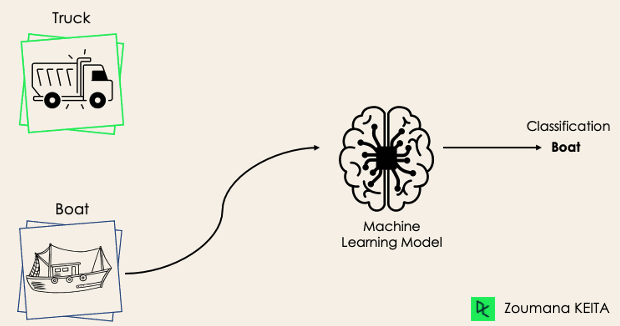
Los algoritmos de regresión logística y máquinas de vectores de soporte están diseñados nativamente para clasificaciones binarias. Sin embargo, para la clasificación binaria también pueden utilizarse otros algoritmos, como K vecinos más próximos y árboles de decisión.
La clasificación multiclase, por otra parte, tiene al menos dos etiquetas de clase mutuamente excluyentes, donde el objetivo es prever a qué clase pertenece un ejemplo de entrada dado. En el caso siguiente, el modelo clasificó correctamente la imagen como avión.
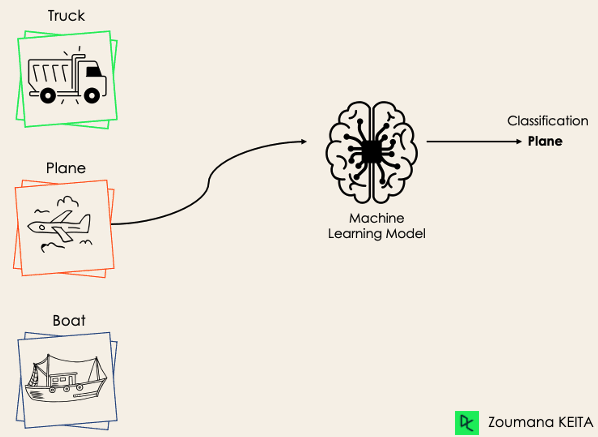
La mayoría de los algoritmos de clasificación binaria también pueden utilizarse para la clasificación multiclase. Estos algoritmos incluyen, entre otros:
Pero, ¡espera! ¿No decías que SVM y regresión logística no admiten la clasificación multiclase por defecto?
→ Correcto. Sin embargo, podemos aplicar enfoques de transformación binaria, como uno contra uno y uno contra todos, para adaptar los algoritmos nativos de clasificación binaria a las tareas de clasificación multiclase.
Uno contra uno: esta estrategia entrena tantos clasificadores como pares de etiquetas haya. Si tenemos una clasificación de 3 clases, tendremos tres pares de etiquetas y, por tanto, tres clasificadores, como se muestra a continuación.
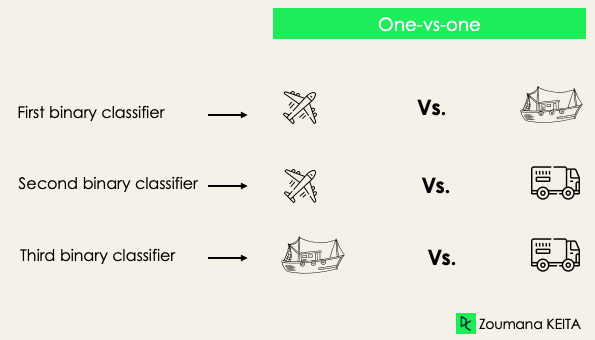
En general, para N etiquetas, tendremos N × (N - 1)/2 clasificadores. Cada clasificador se entrena con un único conjunto de datos binarios, y la clase final se prevé por la mayoría de los votos entre todos los clasificadores. El enfoque uno contra uno funciona mejor para SVM y otros algoritmos basados en kernel.
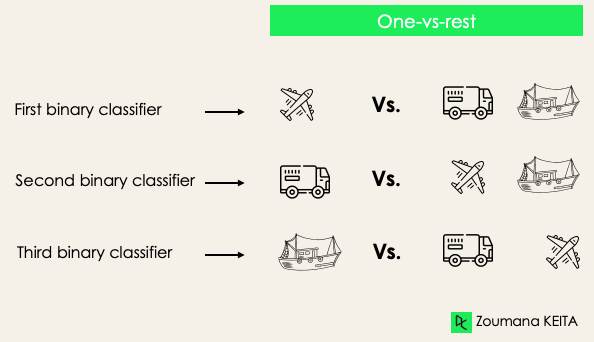
Uno contra el resto: en esta fase, empezamos considerando cada etiqueta como una etiqueta independiente y consideramos el resto combinado como una sola etiqueta. Con 3 clases, tendremos tres clasificadores.
En general, para N etiquetas, tendremos N clasificadores binarios.
En las tareas de clasificación multietiqueta, intentamos prever 0 o más clases para cada ejemplo de entrada. En este caso, no hay exclusión mutua porque el ejemplo de entrada puede tener más de una etiqueta.
Este caso puede observarse en distintos dominios, como el autoetiquetado en el procesamiento de lenguaje natural, donde un texto dado puede contener varios temas. De forma similar a la visión artificial, una imagen puede contener varios objetos, como se ilustra a continuación: el modelo previó que la imagen contendría: un avión, un barco, un camión y un perro.
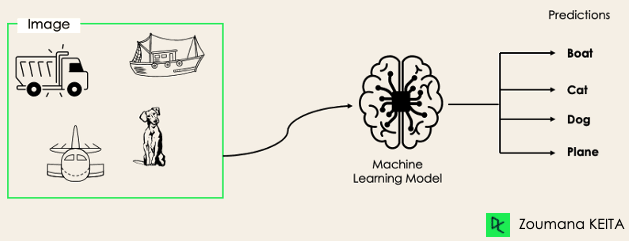
No es posible utilizar modelos de clasificación multiclase o binaria para realizar una clasificación multietiqueta. Sin embargo, la mayoría de los algoritmos utilizados para esas tareas de clasificación estándar tienen sus versiones especializadas para la clasificación multietiqueta. Podemos citar:
En la clasificación desequilibrada, el número de ejemplos se distribuye de forma desigual en cada clase, lo que significa que podemos tener más de una clase que de las demás en los datos de entrenamiento. Consideremos el siguiente caso de clasificación de 3 clases en el que los datos de entrenamiento contienen: 60 % de camiones, 25 % de aviones y 15 % de barcos.
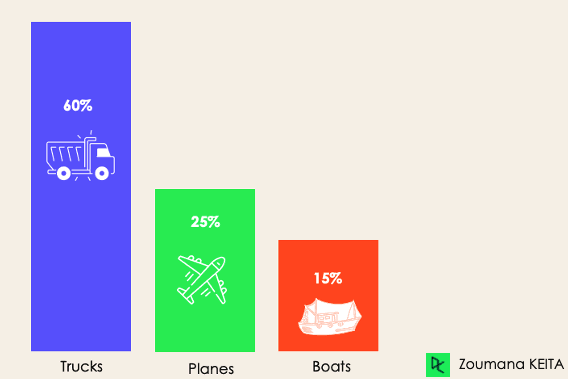
El problema de la clasificación desequilibrada podría darse en el siguiente supuesto:
El uso de modelos predictivos convencionales como árboles de decisión, regresión logística, etc., podría no ser eficaz cuando se trata de un conjunto de datos desequilibrado, porque podrían estar sesgados hacia la previsión de la clase con mayor número de observaciones y considerar ruido las clases que tienen menor número de observaciones.
¿Significa eso que esos problemas quedan excluidos?
¡Por supuesto que no! Podemos utilizar varios enfoques para abordar el problema del desequilibrio en un conjunto de datos. Los enfoques más utilizados son las técnicas de muestreo o el aprovechamiento de la potencia de los algoritmos sensibles al coste.
El objetivo de estas técnicas es equilibrar la distribución del original mediante:
Estos algoritmos tienen en cuenta el coste de una clasificación errónea. Su objetivo es minimizar el coste total generado por los modelos.
Ahora que tenemos una idea de los distintos tipos de modelos de clasificación, es crucial elegir las métricas de evaluación adecuadas para esos modelos. En esta sección, trataremos las métricas más utilizadas: exactitud, precisión, recuerdo, puntuación F1 y área bajo la curva ROC (Receiver Operating Characteristic) y AUC (Area Under the Curve).



Ahora tenemos todas las herramientas para proceder a la implementación de algunos algoritmos. En esta sección se tratarán cuatro algoritmos y su implementación en el conjunto de datos de préstamos para ilustrar algunos de los conceptos tratados anteriormente, sobre todo para los conjuntos de datos desequilibrados con una tarea de clasificación binaria. Nos centraremos solo en cuatro algoritmos para simplificar.
El objetivo no es tener el mejor modelo posible, sino ilustrar cómo entrenar cada uno de los algoritmos siguientes. El código fuente está disponible en DataCamp Workspace, donde puedes ejecutarlo todo con un solo clic.
import pandas as pd
loan_data = pd.read_csv("loan_data.csv")
loan_data.head()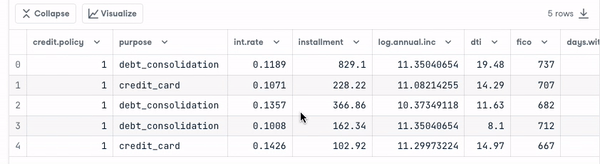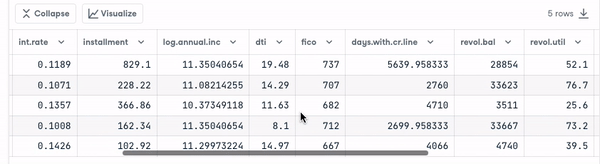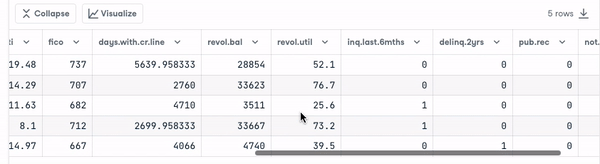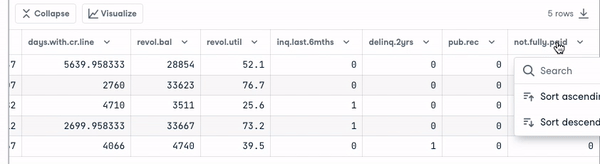
import matplotlib.pyplot as plt
# Helper function for data distribution
# Visualize the proportion of borrowers
def show_loan_distrib(data):
count = ""
if isinstance(data, pd.DataFrame):
count = data["not.fully.paid"].value_counts()
else:
count = data.value_counts()
count.plot(kind = 'pie', explode = [0, 0.1],
figsize = (6, 6), autopct = '%1.1f%%', shadow = True)
plt.ylabel("Loan: Fully Paid Vs. Not Fully Paid")
plt.legend(["Fully Paid", "Not Fully Paid"])
plt.show()
# Visualize the proportion of borrowers
show_loan_distrib(loan_data)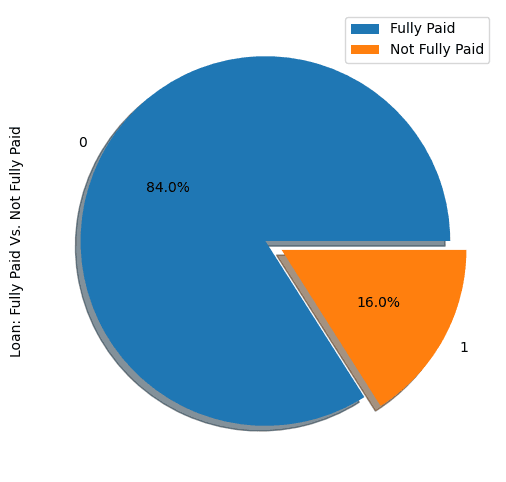
En el gráfico anterior, observamos que el 84 % de los prestatarios devolvieron sus préstamos, y solo el 16 % no los devolvieron, lo que hace que el conjunto de datos esté realmente desequilibrado.
Antes de seguir adelante, tenemos que comprobar el tipo de las variables para poder codificar las que deban codificarse.
Observamos que todas las columnas son variables continuas, excepto el atributo purpose, que debe codificarse.

# Check column types
print(loan_data.dtypes)
encoded_loan_data = pd.get_dummies(loan_data, prefix="purpose",
drop_first=True)
print(encoded_loan_data.dtypes)X = encoded_loan_data.drop('not.fully.paid', axis = 1)
y = encoded_loan_data['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,
stratify = y, random_state=2022)Exploraremos aquí dos estrategias de muestreo: el submuestreo aleatorio y el sobremuestreo SMOTE.
Submuestrearemos la clase mayoritaria, que corresponde a "fully paid" (clase 0).
X_train_cp = X_train.copy()
X_train_cp['not.fully.paid'] = y_train
y_0 = X_train_cp[X_train_cp['not.fully.paid'] == 0]
y_1 = X_train_cp[X_train_cp['not.fully.paid'] == 1]
y_0_undersample = y_0.sample(y_1.shape[0])
loan_data_undersample = pd.concat([y_0_undersample, y_1], axis = 0)
# Visualize the proportion of borrowers
show_loan_distrib(loan_data_undersample)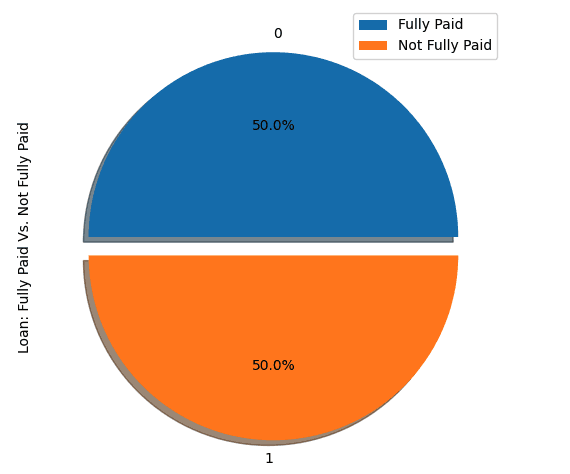
Realiza un sobremuestreo en la clase minoritaria
smote = SMOTE(sampling_strategy='minority')
X_train_SMOTE, y_train_SMOTE = smote.fit_resample(X_train,y_train)
# Visualize the proportion of borrowers
show_loan_distrib(y_train_SMOTE)Tras aplicar las estrategias de muestreo, observamos que el conjunto de datos se distribuye por igual entre los distintos tipos de prestatarios.
En esta sección aplicaremos estos dos algoritmos de clasificación al conjunto de datos muestreado con smote SMOTE. El mismo enfoque de entrenamiento puede aplicarse también a los datos submuestreados.
Se trata de un algoritmo explicable. Clasifica un punto de datos modelando su probabilidad de pertenecer a una clase determinada mediante la función sigmoide.
X = loan_data_undersample.drop('not.fully.paid', axis = 1)
y = loan_data_undersample['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, stratify = y, random_state=2022)
logistic_classifier = LogisticRegression()
logistic_classifier.fit(X_train, y_train)
y_pred = logistic_classifier.predict(X_test)
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))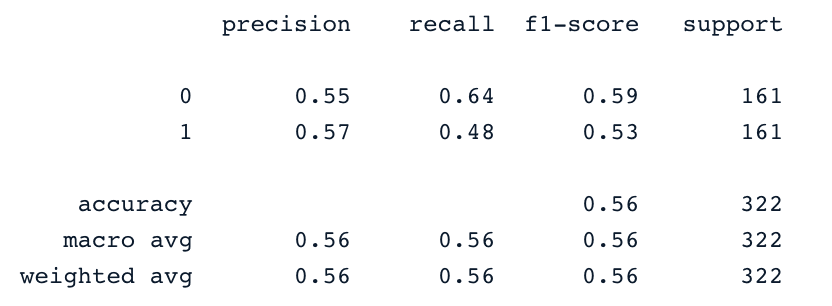
Este algoritmo puede utilizarse tanto para la clasificación como para la regresión. Aprende a trazar el hiperplano (límite de decisión) utilizando el principio de maximización del margen. Este límite de decisión se traza a través de los dos vectores de soporte más cercanos.
SVM proporciona una estrategia de transformación llamada trucos del kernel que se utiliza para proyectar datos separables no lineales en un espacio de dimensión superior para hacerlos linealmente separables.
from sklearn.svm import SVC
svc_classifier = SVC(kernel='linear')
svc_classifier.fit(X_train, y_train)
# Make Prediction & print the result
y_pred = svc_classifier.predict(X_test)
print(classification_report(y_test,y_pred))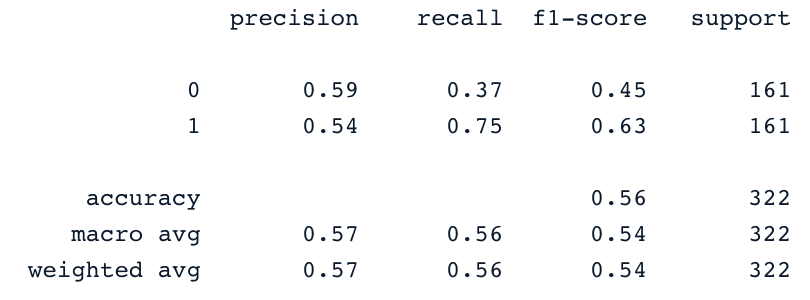
Por supuesto, estos resultados pueden mejorarse con más creación de atributos y ajuste fino. Sin embargo, son mejores que el uso de los datos originales desequilibrados.
Este algoritmo es una extensión de un conocido algoritmo llamado árboles con potenciación del gradiente. Es un gran candidato no solo para combatir el sobreajuste, sino también por su velocidad y rendimiento.
Para abreviar, puedes consultar Machine learning con modelos basados en árboles en Python y Machine learning con modelos basados en árboles en R. En estos cursos aprenderás a utilizar tanto Python como R para implementar modelos basados en árboles.
Este blog conceptual ha cubierto el aspecto principal de las clasificaciones en machine learning y también te ha proporcionado algunos ejemplos de diferentes dominios a los que se aplican. Por último, se ha tratado la implementación de regresión logística y máquina de vectores de soporte tras realizar las estrategias de submuestreo y sobremuestreo SMOTE para generar un conjunto de datos equilibrado para el entrenamiento de los modelos.
Esperamos que te haya ayudado a comprender mejor este tema de la clasificación en machine learning. Puedes ampliar tu aprendizaje siguiendo el programa Científico de machine learning con Python, que abarca el aprendizaje supervisado, no supervisado y profundo. También proporciona una buena introducción al procesamiento del lenguaje natural, el procesamiento de imágenes, Spark y Keras.
Cursos de machine learning
Curso
Curso
Curso
blog
Matt Crabtree
14 min
blog
Natassha Selvaraj
15 min
blog
Moez Ali
8 min
blog
DataCamp Team
11 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
11 min