
Course
Machine Learning for Business
2 hr
43.7K
Neural networks or artificial neural networks are fundamental tools in machine learning, powering many state-of-the-art algorithms and applications across various domains, including computer vision, natural language processing, robotics, and more.
A neural network consists of interconnected nodes, called neurons, organized into layers. Each neuron receives input signals, performs a computation on them using an activation function, and produces an output signal that may be passed to other neurons in the network. An activation function determines the output of a neuron given its input. These functions introduce nonlinearity into the network, enabling it to learn complex patterns in data.
The network is typically organized into layers, starting with the input layer, where data is introduced. Followed by hidden layers where computations are performed and finally, the output layer where predictions or decisions are made.
Neurons in adjacent layers are connected by weighted connections, which transmit signals from one layer to the next. The strength of these connections, represented by weights, determines how much influence one neuron's output has on another neuron's input. During the training process, the network learns to adjust its weights based on examples provided in a training dataset. Additionally, each neuron typically has an associated bias, which allows the neuron to adjust its output threshold.
Neural networks are trained using techniques called feedforward propagation and backpropagation. During feedforward propagation, input data is passed through the network layer by layer, with each layer performing a computation based on the inputs it receives and passing the result to the next layer.
Backpropagation is an algorithm used to train neural networks by iteratively adjusting the network's weights and biases in order to minimize the loss function. A loss function (also known as a cost function or objective function) is a measure of how well the model's predictions match the true target values in the training data. The loss function quantifies the difference between the predicted output of the model and the actual output, providing a signal that guides the optimization process during training.
The goal of training a neural network is to minimize this loss function by adjusting the weights and biases. The adjustments are guided by an optimization algorithm, such as gradient descent. We will revisit some of these topics in more detail later on in this tutorial.
Biological neuron vs. artificial neural network (Source: ResearchGate)
The ANN depicted on the right of the image is a simple neural network called ‘perceptron’. It consists of a single layer, which is the input layer, with multiple neurons with their own weights; there are no hidden layers. The perceptron algorithm learns the weights for the input signals in order to draw a linear decision boundary.
However, to solve more complicated, non-linear problems related to image processing, computer vision, and natural language processing tasks, we work with deep neural networks.
Check out Datacamp’s Introduction to Deep Neural Networks tutorial to learn more about deep neural networks and how to construct one from scratch utilizing TensorFlow and Keras in Python. If you would prefer to use R language instead, Datacamp’s Building Neural Network (NN) Models in R has you covered.
There are several types of ANN, each designed for specific tasks and architectural requirements. Let's briefly discuss some of the most common types before diving deeper into MLPs next.
These are the simplest form of ANNs, where information flows in one direction, from input to output. There are no cycles or loops in the network architecture. Multilayer perceptrons (MLP) are a type of feedforward neural network.
In RNNs, connections between nodes form directed cycles, allowing information to persist over time. This makes them suitable for tasks involving sequential data, such as time series prediction, natural language processing, and speech recognition.
CNNs are designed to effectively process grid-like data, such as images. They consist of layers of convolutional filters that learn hierarchical representations of features within the input data. CNNs are widely used in tasks like image classification, object detection, and image segmentation.
These are specialized types of recurrent neural networks designed to address the vanishing gradient problem in traditional RNN. LSTMs and GRUs incorporate gated mechanisms to better capture long-range dependencies in sequential data, making them particularly effective for tasks like speech recognition, machine translation, and sentiment analysis.
It is designed for unsupervised learning and consists of an encoder network that compresses the input data into a lower-dimensional latent space, and a decoder network that reconstructs the original input from the latent representation. Autoencoders are often used for dimensionality reduction, data denoising, and generative modeling.
GANs consist of two neural networks, a generator and a discriminator, trained simultaneously in a competitive setting. The generator learns to generate synthetic data samples that are indistinguishable from real data, while the discriminator learns to distinguish between real and fake samples. GANs have been widely used for generating realistic images, videos, and other types of data.
A multilayer perceptron is a type of feedforward neural network consisting of fully connected neurons with a nonlinear kind of activation function. It is widely used to distinguish data that is not linearly separable.
MLPs have been widely used in various fields, including image recognition, natural language processing, and speech recognition, among others. Their flexibility in architecture and ability to approximate any function under certain conditions make them a fundamental building block in deep learning and neural network research. Let's take a deeper dive into some of its key concepts.
The input layer consists of nodes or neurons that receive the initial input data. Each neuron represents a feature or dimension of the input data. The number of neurons in the input layer is determined by the dimensionality of the input data.
Between the input and output layers, there can be one or more layers of neurons. Each neuron in a hidden layer receives inputs from all neurons in the previous layer (either the input layer or another hidden layer) and produces an output that is passed to the next layer. The number of hidden layers and the number of neurons in each hidden layer are hyperparameters that need to be determined during the model design phase.
This layer consists of neurons that produce the final output of the network. The number of neurons in the output layer depends on the nature of the task. In binary classification, there may be either one or two neurons depending on the activation function and representing the probability of belonging to one class; while in multi-class classification tasks, there can be multiple neurons in the output layer.
Neurons in adjacent layers are fully connected to each other. Each connection has an associated weight, which determines the strength of the connection. These weights are learned during the training process.
In addition to the input and hidden neurons, each layer (except the input layer) usually includes a bias neuron that provides a constant input to the neurons in the next layer. Bias neurons have their own weight associated with each connection, which is also learned during training.
The bias neuron effectively shifts the activation function of the neurons in the subsequent layer, allowing the network to learn an offset or bias in the decision boundary. By adjusting the weights connected to the bias neuron, the MLP can learn to control the threshold for activation and better fit the training data.
Note: It is important to note that in the context of MLPs, bias can refer to two related but distinct concepts: bias as a general term in machine learning and the bias neuron (defined above). In general machine learning, bias refers to the error introduced by approximating a real-world problem with a simplified model. Bias measures how well the model can capture the underlying patterns in the data. A high bias indicates that the model is too simplistic and may underfit the data, while a low bias suggests that the model is capturing the underlying patterns well.
Typically, each neuron in the hidden layers and the output layer applies an activation function to its weighted sum of inputs. Common activation functions include sigmoid, tanh, ReLU (Rectified Linear Unit), and softmax. These functions introduce nonlinearity into the network, allowing it to learn complex patterns in the data.
MLPs are trained using the backpropagation algorithm, which computes gradients of a loss function with respect to the model's parameters and updates the parameters iteratively to minimize the loss.
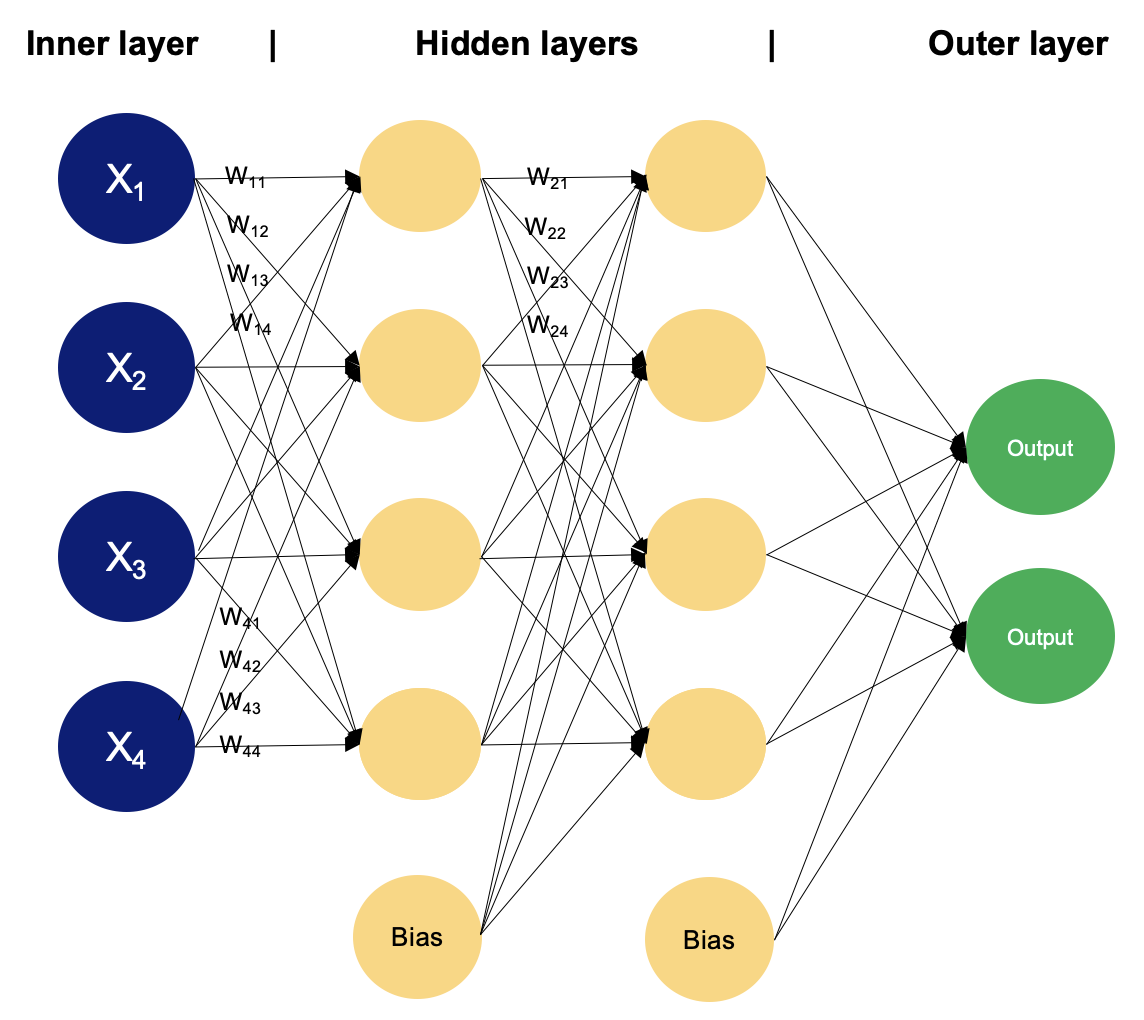
Example of an MLP with two hidden layers. Image by Author
In a multilayer perceptron, neurons process information in a step-by-step manner, performing computations that involve weighted sums and nonlinear transformations. Let's walk layer by layer to see the magic that goes within.
w. The weights determine how much influence the input from one neuron has on the output of another.b. The bias provides an additional input to the neuron, allowing it to adjust its output threshold. Like weights, biases are learned during training.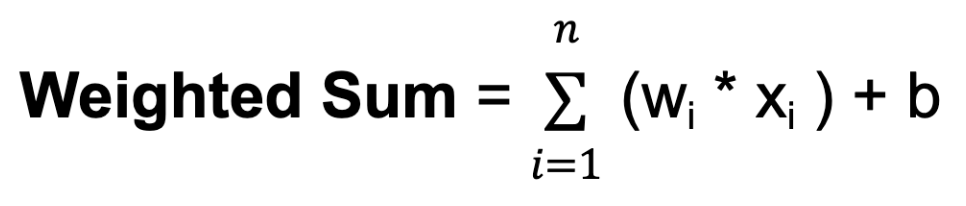
Where n is the total number of input connections, wi is the weight for the i-th input, and xi is the i-th input value.
f. The activation function introduces nonlinearity into the network, allowing it to learn and represent complex relationships in the data. The activation function determines the output range of the neuron and its behavior in response to different input values. The choice of activation function depends on the nature of the task and the desired properties of the network.During the training process, the network learns to adjust the weights associated with each neuron's inputs to minimize the discrepancy between the predicted outputs and the true target values in the training data. By adjusting the weights and learning the appropriate activation functions, the network learns to approximate complex patterns and relationships in the data, enabling it to make accurate predictions on new, unseen samples.
This adjustment is guided by an optimization algorithm, such as stochastic gradient descent (SGD), which computes the gradients of a loss function with respect to the weights and updates the weights iteratively.
Let’s take a closer look at how SGD works.
θₜ₊₁ = θₜ − η ∇J(θₜ)Where:
θₜ represents the model parameters (e.g., weights and biases) at iteration t
∇J(θₜ) is the gradient of the loss function J with respect to the parameters at iteration t
η (eta) is the learning rate, which controls the step size during optimization
n. This parameter controls the size of the steps taken towards the minimum. If the learning rate is too small, convergence may be slow; if it is too large, the algorithm may oscillate or diverge.Stochastic gradient descent updates the model parameters more frequently using smaller subsets of data, making it computationally efficient, especially for large datasets. The randomness introduced by SGD can have a regularization effect, preventing the model from overfitting to the training data. It is also well-suited for online learning scenarios where new data becomes available incrementally, as it can update the model quickly with each new data point or mini-batch.
However, SGD can also have some challenges, such as increased noise due to the stochastic nature of the gradient estimation and the need to tune hyperparameters like the learning rate. Various extensions and adaptations of SGD, such as mini-batch stochastic gradient descent, momentum, and adaptive learning rate methods like AdaGrad, RMSProp, and Adam, have been developed to address these challenges and improve convergence and performance.
You have seen the working of the multilayer perceptron layers and learned about stochastic gradient descent; to put it all together, there is one last topic to dive into: backpropagation.
Backpropagation is short for “backward propagation of errors.” In the context of backpropagation, SGD involves updating the network's parameters iteratively based on the gradients computed during each batch of training data. Instead of computing the gradients using the entire training dataset (which can be computationally expensive for large datasets), SGD computes the gradients using small random subsets of the data called mini-batches. Here’s an overview of how backpropagation algorithm works:
Preparing data for training an MLP involves cleaning, preprocessing, scaling, splitting, formatting, and maybe even augmenting the data. Based on the activation functions used and the scale of the input features, the data might need to be standardized or normalized. Experimenting with different preprocessing techniques and evaluating their impact on model performance is often necessary to determine the most suitable approach for a particular dataset and task.
To learn more about feature scaling, check out Datacamp’s Feature Engineering for Machine Learning in Python course.
Implementing a MLP involves several steps, from data preprocessing to model training and evaluation. Selecting the number of layers and neurons for a MLP involves balancing model complexity, training time, and generalization performance. There is no one-size-fits-all answer, as the optimal architecture depends on factors such as the complexity of the task, the amount of available data, and computational resources. However, here are some general guidelines to consider when implementing MLP:
Multilayer perceptrons represent a fundamental and versatile class of artificial neural networks that have significantly contributed to the advancement of machine learning and artificial intelligence. Through their interconnected layers of neurons and nonlinear activation functions, MLPs are capable of learning complex patterns and relationships in data, making them well-suited for a wide range of tasks. The history of MLPs reflects a journey of exploration, discovery, and innovation, from the early perceptron models to the modern deep learning architectures that power many state-of-the-art systems today.
In this article, you’ve learned the basics of artificial neural networks, focused on multilayer perceptrons, learned about stochastic gradient descent and backpropagation. If you are interested in getting hands-on experience and using deep learning techniques to solve real-world challenges, such as predicting housing prices, building neural networks to model images and text - we highly recommend following Datacamp’s Keras toolbox track.
Working with Keras, you’ll learn about neural networks, deep learning model workflows, and how to optimize your models. Datacamp also has a Keras cheat sheet that can come in handy!
Start Your Machine Learning Journey Today!
Course
Course
Course
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Bharath K
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Karlijn Willems



