Curso
Machine Learning for Finance in Python
4 h
32K
Las preguntas básicas están relacionadas con la terminología, los algoritmos y las metodologías. Los entrevistadores hacen estas preguntas para evaluar los conocimientos técnicos del candidato.
El aprendizaje semisupervisado es una combinación de aprendizaje supervisado y no supervisado. El algoritmo se entrena con una combinación de datos etiquetados y sin etiquetar. Por lo general, se utiliza cuando se dispone de un conjunto de datos etiquetados muy pequeño y un conjunto de datos sin etiquetar muy grande.
En términos sencillos, el algoritmo no supervisado se utiliza para crear clústeres y, mediante el uso de datos etiquetados existentes, etiquetar el resto de los datos sin etiquetar. Un algoritmo semisupervisado asume la hipótesis de continuidad, la hipótesis de agrupamiento y la hipótesis de variedad.
Por lo general, se utiliza para ahorrar el coste de adquirir datos etiquetados. Por ejemplo, la clasificación de secuencias proteicas, el reconocimiento automático del habla y los coches autónomos.
Además del conjunto de datos, necesitas un caso de uso empresarial o requisitos de aplicación. Puedes aplicar el aprendizaje supervisado y no supervisado a los mismos datos.
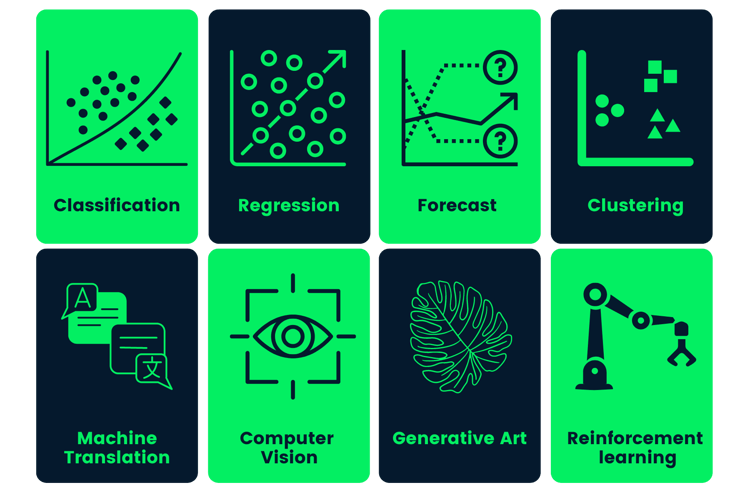
En general:
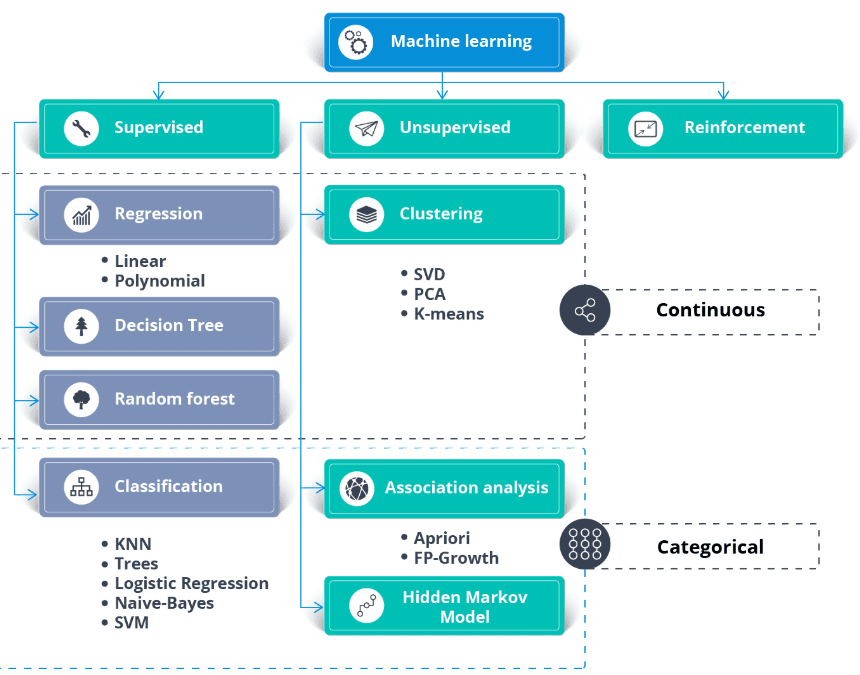
Imagen de thecleverprogrammer
Aprende los fundamentos del machine learning con nuestro curso.
El K Nearest Neighbor (KNN) es un clasificador de aprendizaje supervisado. Utiliza la proximidad para clasificar etiquetas o predecir la agrupación de puntos de datos individuales. Podemos utilizarlo para regresión y clasificación. El algoritmo KNN es no paramétrico, lo que significa que no establece ninguna hipótesis subyacente sobre la distribución de los datos.
En el clasificador KNN:
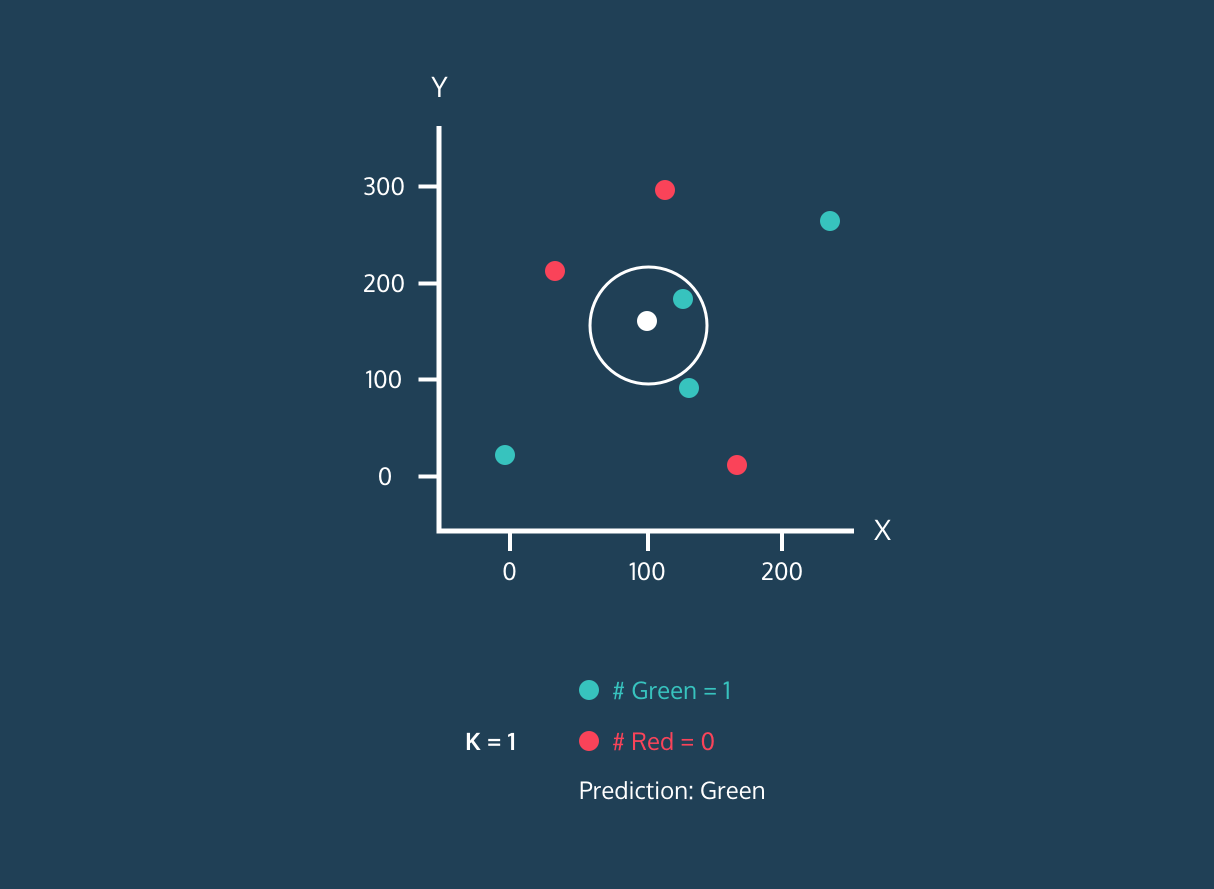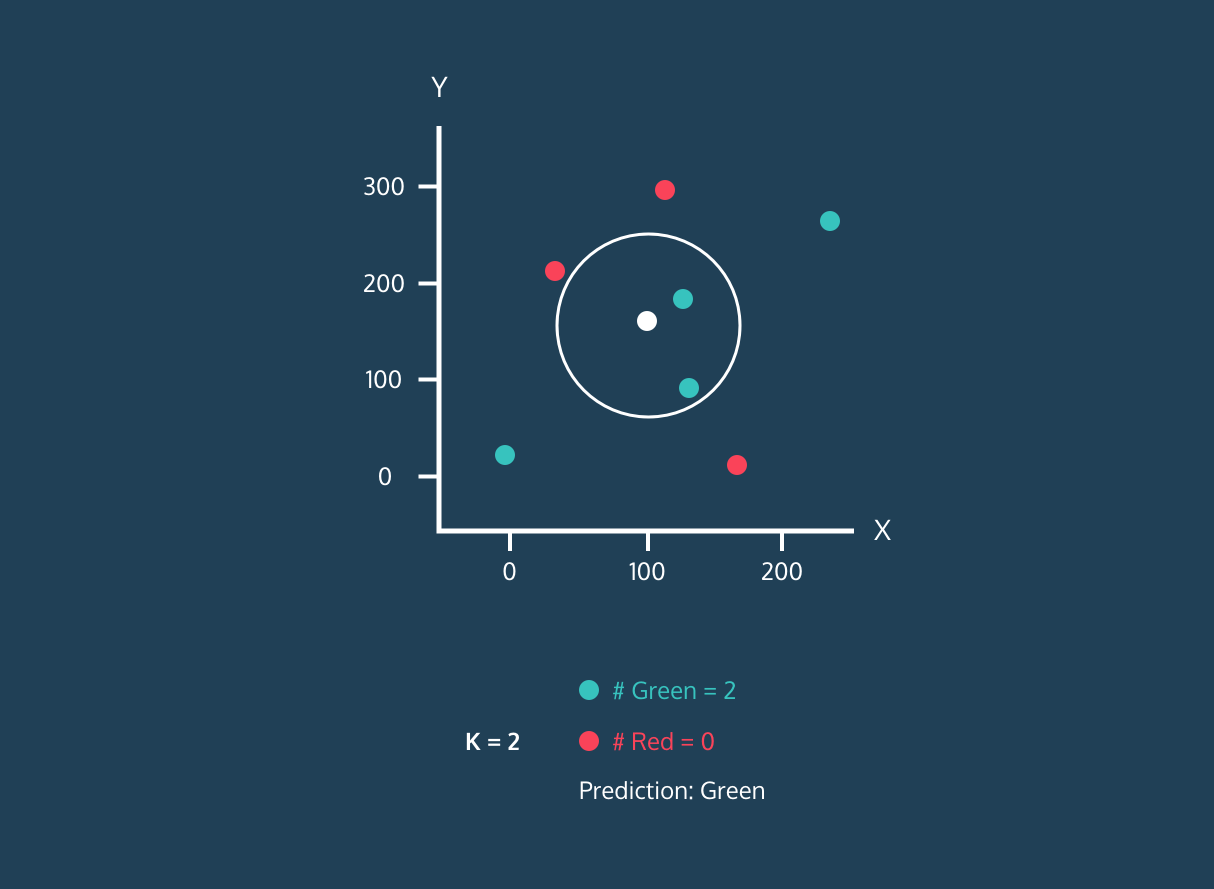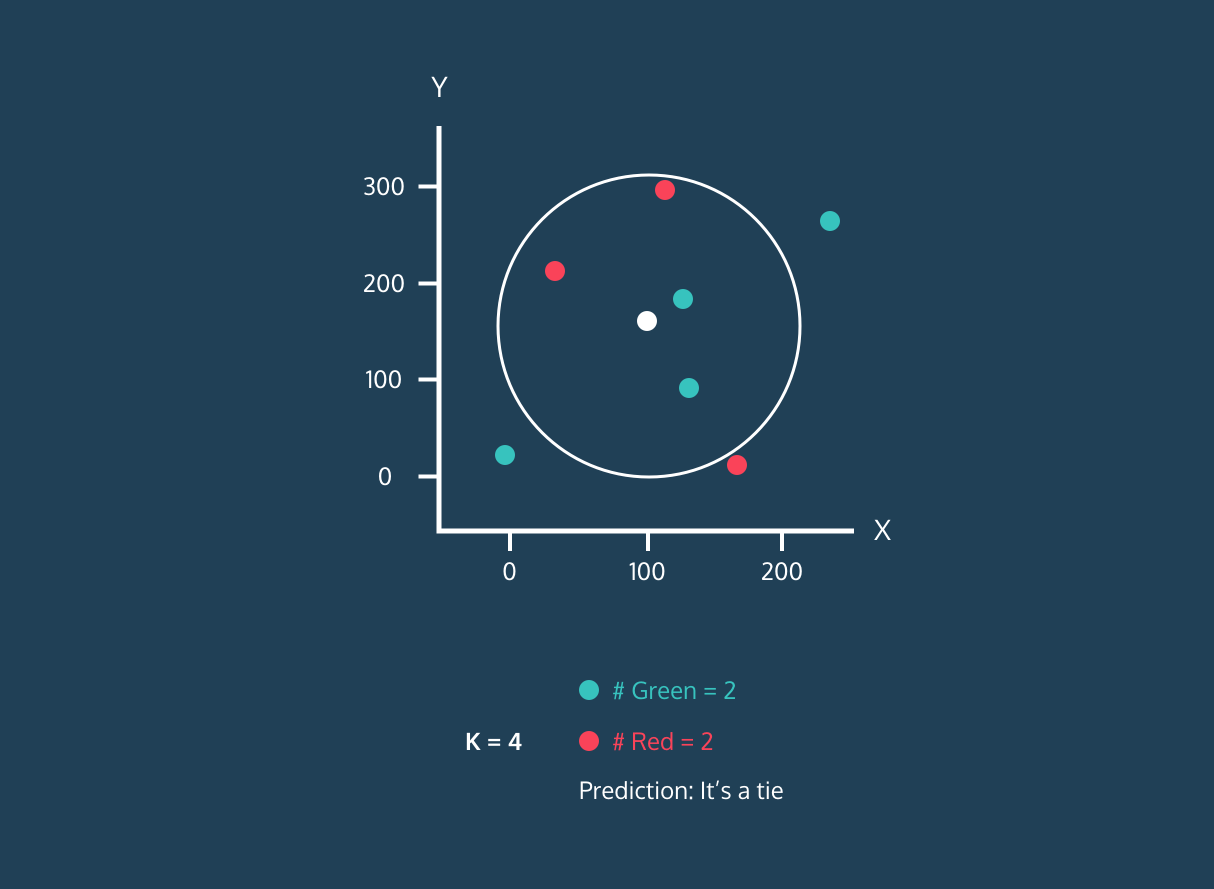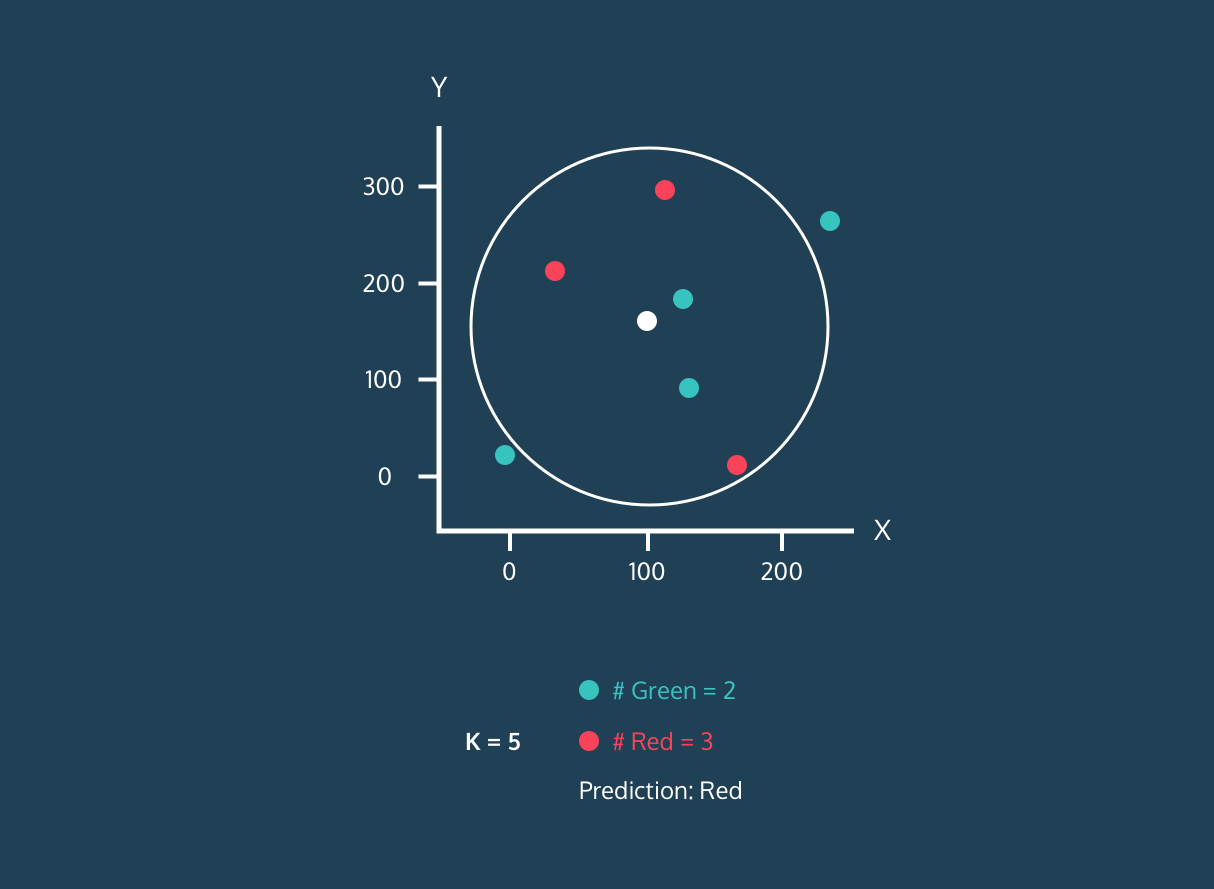
Imagen de la historia de desarrollo de Codesigner.
Aprende todo sobre los modelos de clasificación y regresión del aprendizaje supervisado con un curso breve.
La importancia de las características se refiere a las técnicas que asignan una puntuación a las características de entrada en función de su utilidad para predecir una variable objetivo. Desempeña un papel fundamental a la hora de comprender la estructura subyacente de los datos, el comportamiento del modelo y hacer que este sea más interpretable.
Existen varios métodos para determinar la importancia de las características:
Comprender la importancia de las características es fundamental para optimizar los modelos, reducir el sobreajuste mediante la eliminación de características no informativas y mejorar la interpretabilidad de los modelos, especialmente en ámbitos en los que es fundamental comprender el proceso de decisión del modelo.
El sobreajuste se produce cuando un modelo funciona bien con los datos de entrenamiento, pero no logra generalizarse a datos desconocidos porque ha memorizado los datos de entrenamiento en lugar de aprender los patrones subyacentes. Se puede evitar:
Una matriz de confusión es una tabla que se utiliza para evaluar el rendimiento de un modelo de clasificación. Muestra el recuento de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos. Es útil para calcular métricas como la exactitud, la precisión, la recuperación y la puntuación F1.
Modelos paramétricos: Estos hacen suposiciones sobre la distribución subyacente de los datos y tienen un número fijo de parámetros (por ejemplo, regresión lineal).
Modelos no paramétricos: No hacen suposiciones sobre la distribución de los datos y pueden adaptarse a la complejidad a medida que se añaden más datos (por ejemplo, K-Nearest Neighbors).
La compensación entre sesgo y varianza se refiere al equilibrio entre la capacidad de un modelo para captar patrones complejos (bajo sesgo) y su sensibilidad a las fluctuaciones en los datos de entrenamiento (baja varianza). Un buen modelo logra un equilibrio al minimizar tanto el sesgo como la varianza para evitar el subajuste y el sobreajuste.
La sesión de entrevista técnica se centra más en evaluar tus conocimientos sobre los procesos y tu capacidad para manejar la incertidumbre. El responsable de contratación te hará preguntas sobre machine learning relacionadas con el procesamiento de datos, el entrenamiento y la validación de modelos, y algoritmos avanzados.
Sí. La mayoría de los algoritmos utilizan la distancia euclídea entre puntos de datos, y si el valor de la característica varía mucho, los resultados serán bastante diferentes. En la mayoría de los casos, los valores atípicos hacen que los modelos de machine learning funcionen peor en el conjunto de datos de prueba.
También utilizamos el escalado de características para reducir el tiempo de convergencia. El descenso por gradiente tardará más en alcanzar los mínimos locales cuando las características no estén normalizadas.
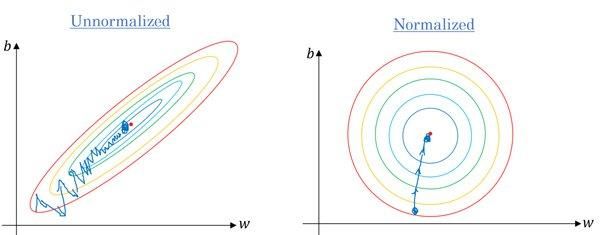
Gradiente sin y con escalado | Quora
Las habilidades en ingeniería de características tienen una gran demanda. Puedes aprender todo sobre el tema realizando un curso de DataCamp, como Ingeniería de características para el machine learning en Python.
El sesgo bajo se produce cuando el modelo predice valores cercanos al valor real. Está imitando el conjunto de datos de entrenamiento. El modelo no tiene generalización, lo que significa que si se prueba con datos desconocidos, dará malos resultados.
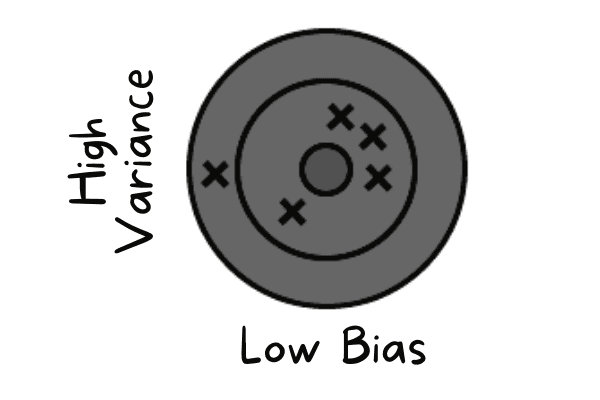
Bajo sesgo y alta varianza | Autor
Para solucionar estos problemas, utilizaremos algoritmos de bagging, ya que dividen un conjunto de datos en subconjuntos mediante muestreo aleatorio. A continuación, generamos conjuntos de modelos utilizando estas muestras con un único algoritmo. Después, combinamos la predicción del modelo utilizando la clasificación por votación o el promedio.
Para una alta varianza, podemos utilizar técnicas de regularización. Se penalizaron los coeficientes de los modelos más altos para reducir la complejidad del modelo. Además, podemos seleccionar las características más importantes del gráfico de importancia de las características y entrenar el modelo.
La deriva del modelo se produce cuando el rendimiento de un modelo se degrada con el tiempo debido a que los datos del mundo real cambian en comparación con los datos de entrenamiento. Hay dos tipos principales:
La validación cruzada se utiliza para evaluar el rendimiento del modelo de forma sólida y evitar el sobreajuste. Por lo general, las técnicas de validación cruzada seleccionan muestras aleatoriamente de los datos y las dividen en conjuntos de datos de entrenamiento y prueba. El número de divisiones se basa en el valor K.
Por ejemplo, si K = 5, habrá cuatro pliegues para el tren y uno para la prueba. Se repetirá cinco veces para medir el modelo realizado en pliegues separados.
No podemos hacerlo con un conjunto de datos de series temporales porque no tiene sentido utilizar el valor del futuro para pronosticar el valor del pasado. Existe una dependencia temporal entre las observaciones, y solo podemos dividir los datos en una dirección, de modo que los valores del conjunto de datos de prueba se encuentren después del conjunto de entrenamiento.
El diagrama muestra que la división en k partes de los datos de series temporales es unidireccional. Los puntos azules son el conjunto de entrenamiento, el punto rojo es el conjunto de prueba y los blancos son datos sin usar. Como podemos observar en cada iteración, avanzamos con el conjunto de entrenamiento, mientras que el conjunto de prueba permanece delante del conjunto de entrenamiento, sin ser seleccionado aleatoriamente.
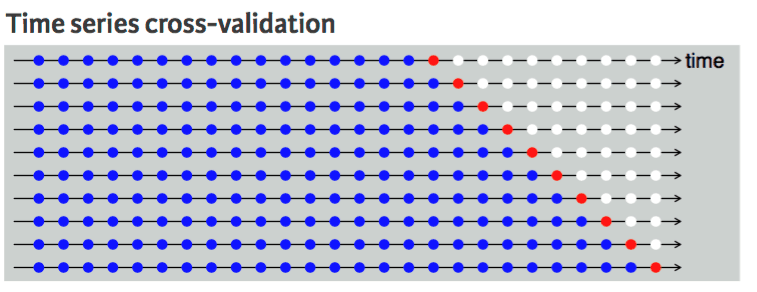
Validación cruzada de series temporales | Guía de programación R de UC Business Analytics
Aprende sobre la manipulación, el análisis, la visualización y el modelado de datos de series temporales con el curso Series temporales con Python.
La mayoría de los puestos de trabajo relacionados con el machine learning que se ofrecen en LinkedIn, Glassdoor e Indeed son específicos para cada función. Por lo tanto, durante la entrevista, se centrarán en preguntas específicas sobre el puesto. Para el puesto de ingeniero de visión artificial, el responsable de contratación se centrará en cuestiones relacionadas con el procesamiento de imágenes.
Imagina una imagen de 250 x 250 y una primera capa oculta totalmente conectada con 1000 unidades ocultas. Para esta imagen, las características de entrada son 250 X 250 X 3 = 187 500, y la matriz de pesos en la primera capa oculta será una matriz dimensional de 187 500 X 1000. Estas cifras son enormes para el almacenamiento y el cálculo, y para combatir este problema, utilizamos operaciones de convolución.
Aprende procesamiento de imágenes con un breve curso de Procesamiento de imágenes en Python.
Si no dispones de datos suficientes para entrenar una red neuronal convolucional, puedes utilizar el aprendizaje por transferencia para entrenar tu modelo y obtener resultados de vanguardia. Necesitas un modelo preentrenado que haya sido entrenado con un conjunto de datos general pero más amplio. Después, lo ajustarás con datos más recientes entrenando las últimas capas de los modelos.
El aprendizaje por transferencia permite a los científicos de datos entrenar modelos con datos más pequeños utilizando menos recursos, computación y almacenamiento. Puedes encontrar fácilmente modelos preentrenados de código abierto para diversos casos de uso, y la mayoría de ellos tienen una licencia comercial, lo que significa que puedes utilizarlos para crear tu aplicación.
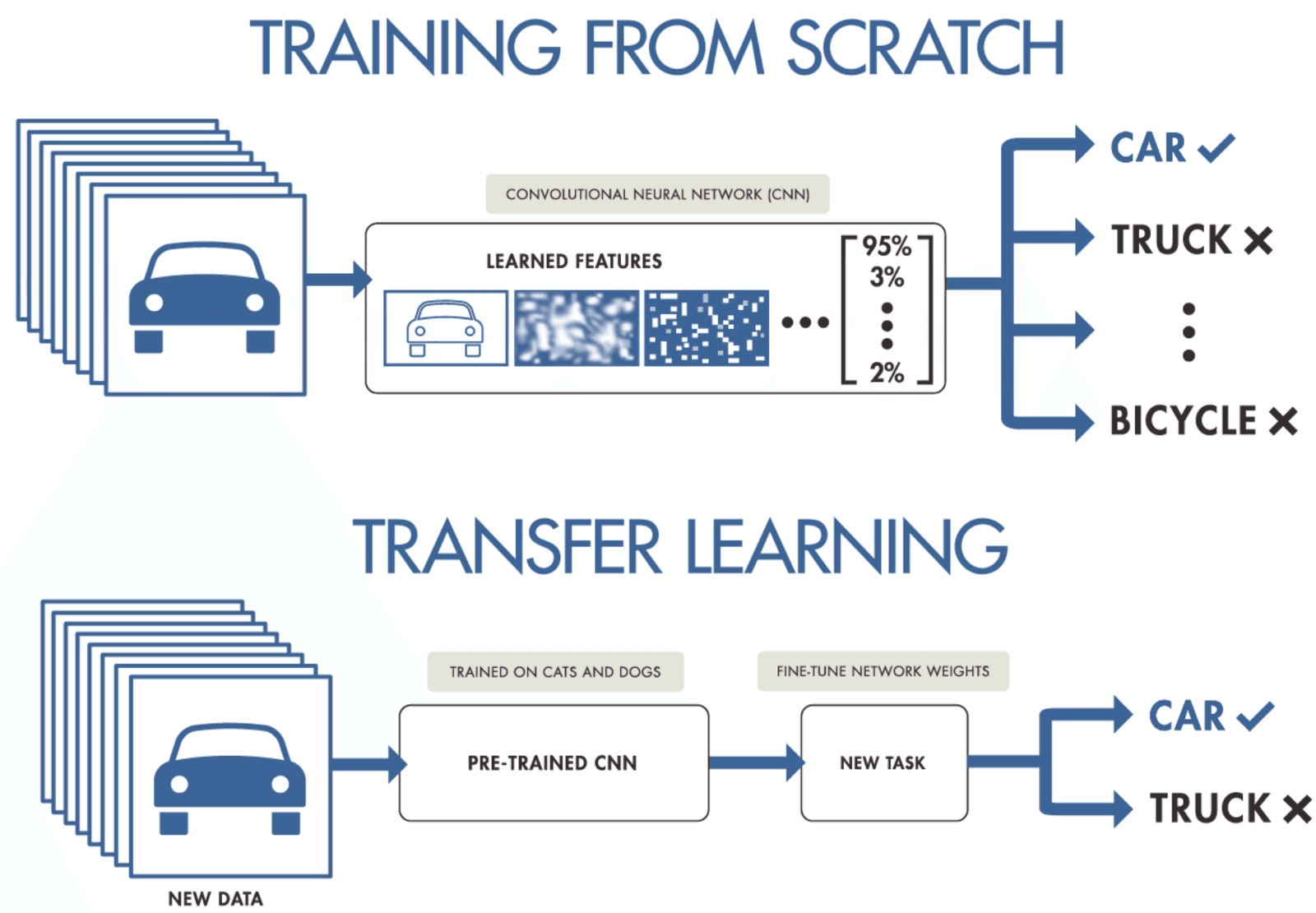
Aprendizaje por transferencia por purnasai gudikandula
YOLO es un algoritmo de detección de objetos basado en redes neuronales convolucionales, y puede proporcionar resultados en tiempo real. El algoritmo YOLO requiere una sola pasada hacia adelante a través de la CNN para reconocer el objeto. Predice tanto las probabilidades de las distintas clases como los recuadros delimitadores.
El modelo se entrenó para detectar diversos objetos, y las empresas están utilizando el aprendizaje por transferencia para ajustarlo a nuevos datos para aplicaciones modernas, como la conducción autónoma, la preservación de la vida silvestre y la seguridad.
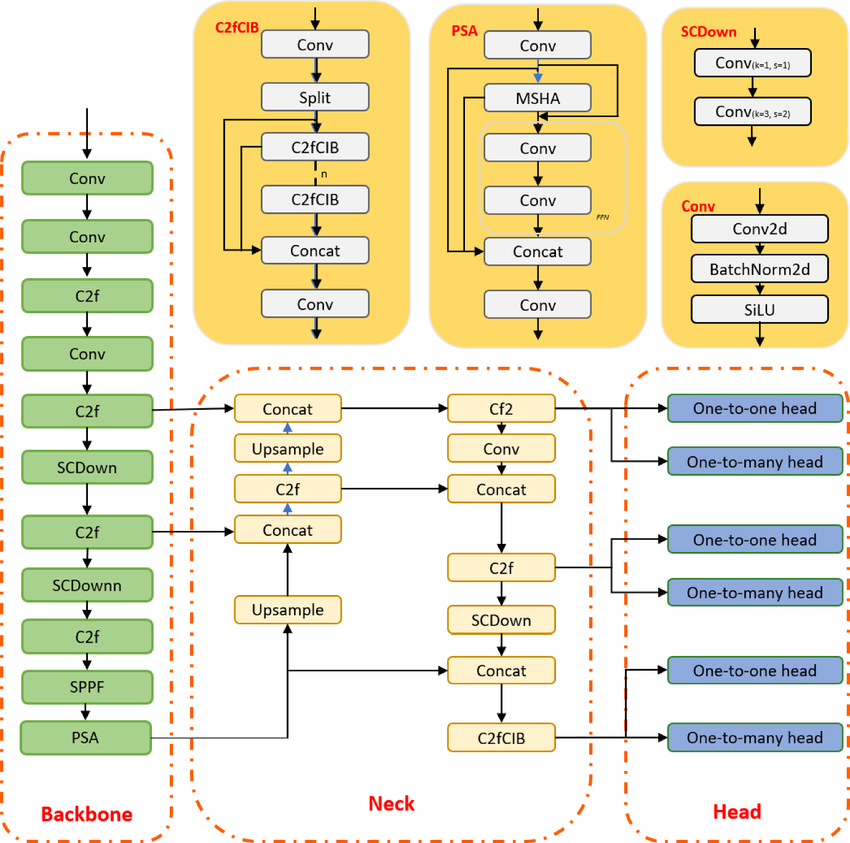
Arquitectura del modelo YOLOv10 | ResearchGate
El procesamiento del lenguaje natural (PLN) es uno de los pilares de las aplicaciones modernas de inteligencia artificial. Prepárate para preguntas que tienden un puente entre la teoría lingüística y la aplicación práctica, y que ponen a prueba tu capacidad para procesar, analizar y extraer significado de datos de texto no estructurados utilizando tanto técnicas clásicas como enfoques modernos de aprendizaje profundo.
El análisis sintáctico, también conocido como análisis sintáctico o parsing, es un análisis de texto que nos revela el significado lógico que hay detrás de una oración o parte de una oración. Se centra en la relación entre las palabras y la estructura gramatical de las oraciones. También se puede decir que es el proceso de análisis del lenguaje natural mediante el uso de reglas gramaticales.
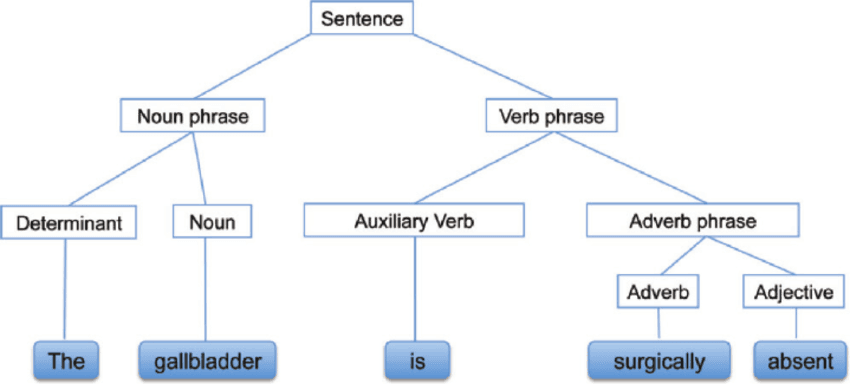
Análisis sintáctico | researchgate
La derivación y la lematización son técnicas de normalización que se utilizan para minimizar la variación estructural de las palabras en una oración.
La derivación elimina los afijos añadidos a la palabra y la deja en su forma básica. Por ejemplo, cambiar a Chang.
Es ampliamente utilizado por los motores de búsqueda para optimizar el almacenamiento. En lugar de almacenar todas las formas de las palabras, solo almacena las raíces.
La lematización convierte la palabra en su forma lema. El resultado es la raíz de la palabra en lugar del tallo. Tras la lematización, obtenemos la palabra válida que significa algo. Por ejemplo, Cambiar para cambiar.

Derivación frente a Lematización | Autor
La optimización de transformadores grandes requiere abordar tanto el ancho de banda de la memoria como los cuellos de botella informáticos:
Aprende los conceptos básicos del PLN completando el programa «Procesamiento del lenguaje natural en Python ».
Dado que los LLM dominan el panorama actual de la IA, los entrevistadores dan prioridad a los candidatos que saben cómo implementarlos de forma eficaz. Esta sección se centra en algunos de los mayores retos prácticos de ingeniería de 2026.
La ventana de contexto de un LLM es la cantidad máxima de texto (medida en tokens) que el modelo puede considerar a la vez al generar una respuesta, y limita directamente la cantidad de «memoria de trabajo» que el modelo tiene efectivamente.
A pesar de que las ventanas de contexto grandes son cada vez más comunes, el rendimiento y el coste no escalan de forma lineal: las indicaciones largas aumentan la latencia y pueden seguir provocando problemas de fiabilidad cuando la información relevante está oculta en medio del contexto.
En las entrevistas, respondía explicando estrategias prácticas para tareas de documentos largos:
Las alucinaciones se producen cuando un LLM genera información plausible pero objetivamente incorrecta. En 2026, la mitigación requiere un enfoque multifacético:
Esta es una clásica cuestión de «compensación». La decisión depende de la actualidad de los datos y la especificidad del dominio:
La cuestión se trata con más detalle en nuestro blog sobre RAG frente a ajuste fino.
El aprendizaje por refuerzo (RL) aborda problemas en los que un agente aprende interactuando con un entorno en lugar de a partir de conjuntos de datos estáticos. Prepárate para hablar sobre cómo funciona RL y explicar conceptos básicos como las políticas.
El aprendizaje por refuerzo utiliza el método de prueba y error para alcanzar objetivos. Es un algoritmo orientado a objetivos y aprende del entorno dando los pasos correctos para maximizar la recompensa acumulada.
En el aprendizaje por refuerzo típico:
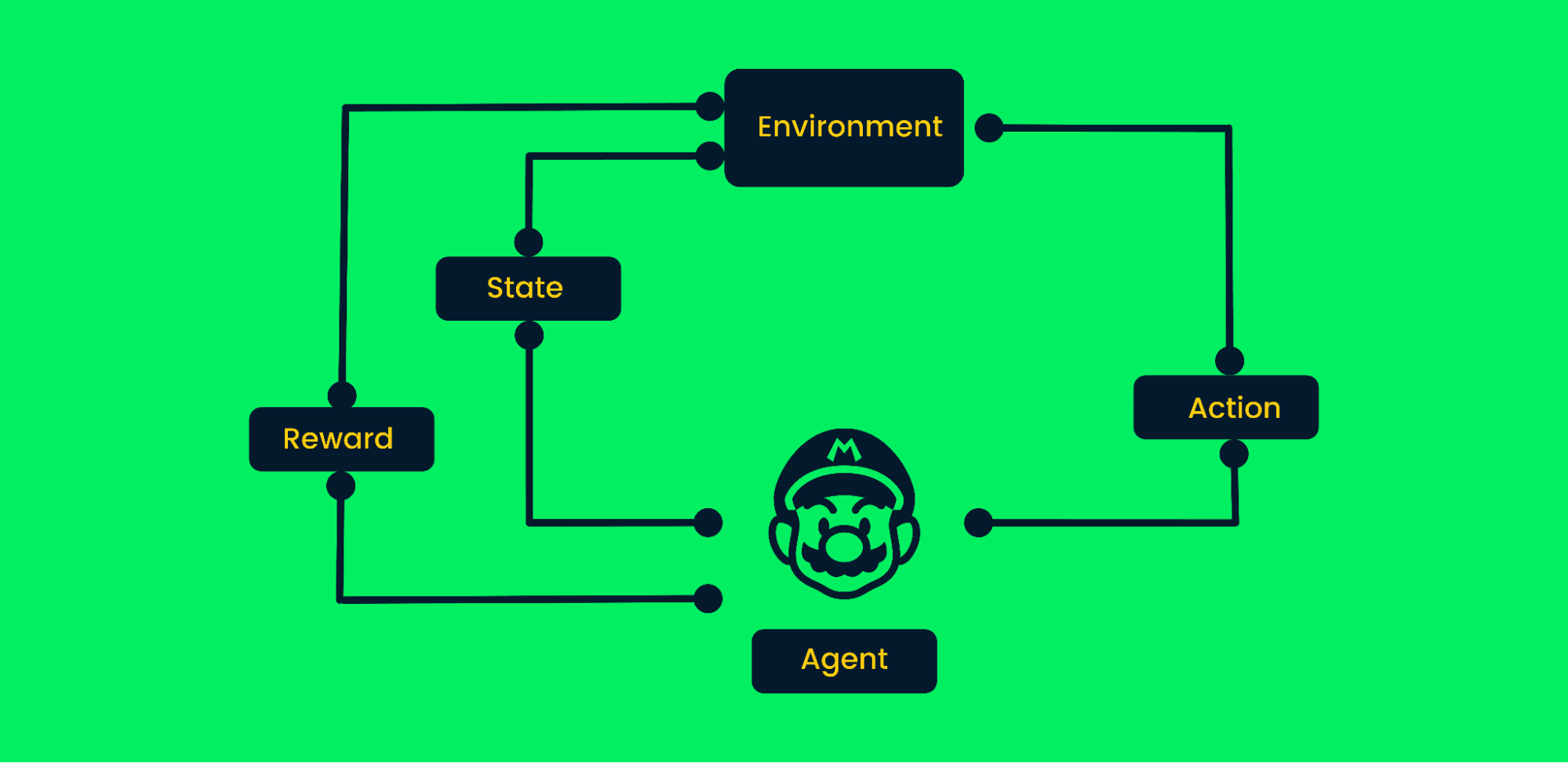
Marco de aprendizaje por refuerzo | Autor
Los algoritmos de aprendizaje sobre políticas evalúan y mejoran la misma política para actuar y actualizarla. En otras palabras, la política que se utiliza para actualizar y la política que se utiliza para tomar medidas son las mismas.
Política de objetivos == Política de comportamiento
Los algoritmos basados en políticas son Sarsa, Monte Carlo para políticas, iteración de valores e iteración de políticas.
Los algoritmos de aprendizaje fuera de política son completamente diferentes, ya que la política actualizada es diferente de la política de comportamiento. Por ejemplo, en el aprendizaje Q, el agente aprende de una política óptima con la ayuda de una política codiciosa y actúa utilizando otras políticas.
Política objetivo != Política de comportamiento
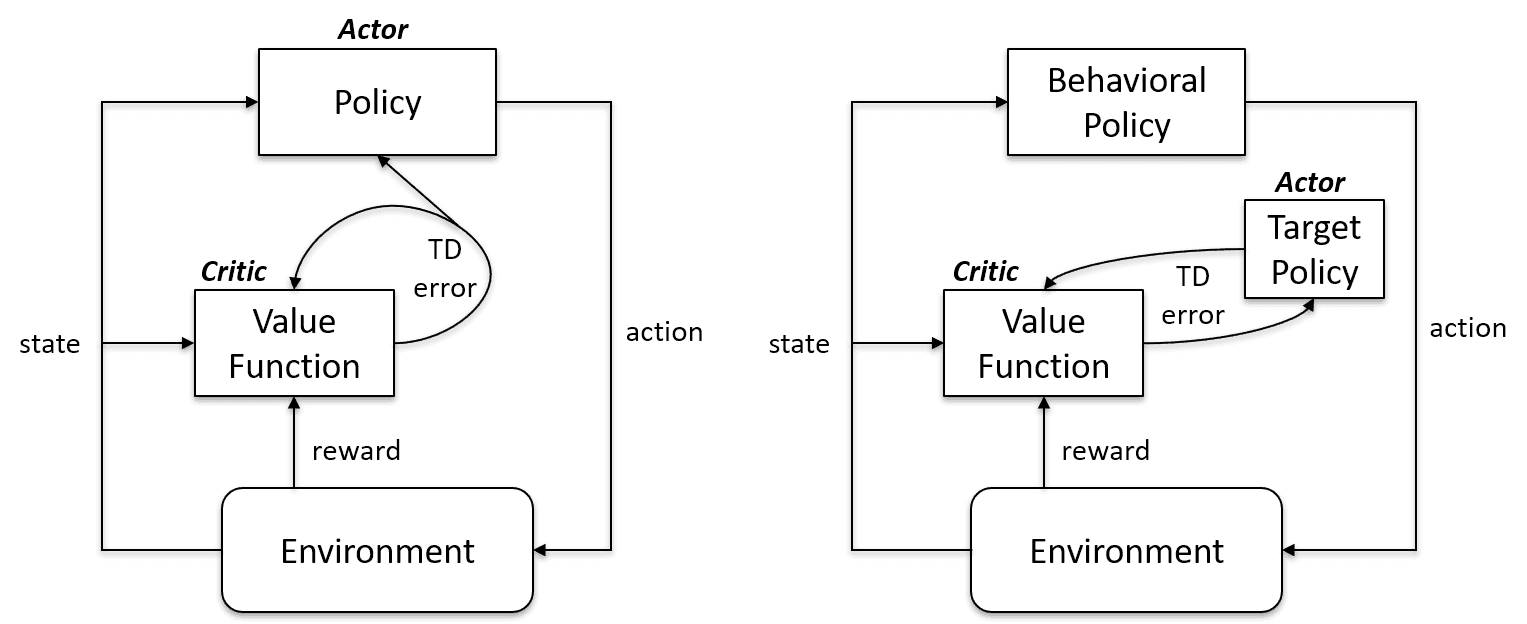
En política frente a Caso fuera de política | Stack Exchange sobre inteligencia artificial
El aprendizaje simple Q es genial. Resuelve el problema a pequeña escala, pero a gran escala fracasa.
Imagina que el entorno tiene 1000 estados y 1000 acciones por estado. Necesitaremos una tabla Q con millones de celdas. Para jugar al ajedrez y al Go se necesitará una tabla aún más grande. Aquí es donde el aprendizaje profundo Q viene al rescate.
Utiliza una red neuronal para aproximar la función del valor Q. La receta de las redes neuronales establece como entrada y salida el valor Q de todas las acciones posibles.
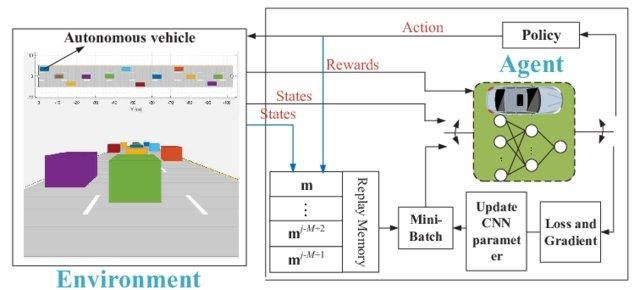
Red Q profunda para la conducción autónoma | ResearchGate
A continuación, te presentamos algunas preguntas que te podrían hacer en una entrevista de trabajo en algunas de las principales empresas tecnológicas:
Las características operativas del receptor (ROC) muestran la relación entre sensibilidad y especificidad.
La curva se grafica utilizando la tasa de falsos positivos (FP/(TN + FP)) y la tasa de verdaderos positivos (TP/(TP + FN)).
El área bajo la curva (AUC) muestra el rendimiento del modelo. Si el área bajo la curva ROC es 0,5, entonces nuestro modelo es completamente aleatorio. El modelo con un AUC cercano a 1 es el mejor modelo.
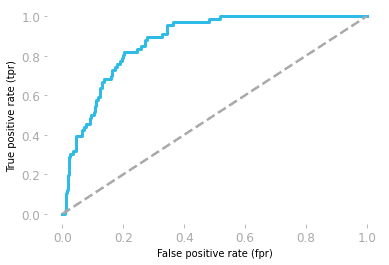
Curva ROC por Hadrien Jean
A diferencia de la clasificación (donde una respuesta es correcta o incorrecta), la GenAI a menudo requiere una evaluación humana o marcos de «LLM como juez»:
Para la reducción de dimensionalidad, podemos utilizar métodos de selección o extracción de características.
La selección de características es un proceso que consiste en seleccionar las características óptimas y descartar las irrelevantes. Utilizamos métodos de filtro, envoltura e incrustación para analizar la importancia de las características y eliminar las menos importantes con el fin de mejorar el rendimiento del modelo.
La extracción de características transforma el espacio con múltiples dimensiones en un espacio con menos dimensiones. No se pierde información durante el proceso y se utilizan menos recursos para procesar los datos. Las técnicas de extracción más comunes son el análisis discriminante lineal (LDA), el PCA kernel y el análisis discriminante cuadrático.
En el caso de un clasificador de spam, un modelo de regresión logística devolverá la probabilidad. O bien utilizamos la probabilidad de 0,8999 o la convertimos en clase (spam/no spam) utilizando un umbral.
Por lo general, el umbral de un clasificador es 0,5, pero en algunos casos es necesario ajustarlo para mejorar la precisión. El umbral de 0,5 significa que si la probabilidad es igual o superior a 0,5, se trata de spam, y si es inferior, no lo es.
Para encontrar el umbral, podemos utilizar curvas de precisión-recuerdo y curvas ROC, búsqueda por cuadrícula y cambiar manualmente el valor para obtener un mejor CV.
Conviértete en un ingeniero profesional de machine learning completando el programa de Científico de machine learning con Python.
La regresión lineal se utiliza para comprender la relación entre las características (X) y el objetivo (y). Antes de entrenar el modelo, debemos cumplir con algunos requisitos:
Nota: los residuos en la regresión lineal son la diferencia entre los valores reales y los valores previstos.
Durante las entrevistas de programación, te harán preguntas sobre problemas de machine learning, pero en algunos casos evaluarán tus conocimientos de Python haciéndote preguntas generales sobre programación. Conviértete en un programador experto en Python siguiendo el programa de formación para programadores de Python.
Crear una función bigram es bastante fácil. Debes utilizar dos bucles con la función zip.
zip para crear una combinación de la palabra anterior y la siguiente.Es bastante fácil si desglosas el problema y utilizas funciones zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Resultados:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]La función de activación es una transformación no lineal en las redes neuronales. Pasamos la entrada por la función de activación antes de pasarla a la siguiente capa.
El valor de entrada neto puede ser cualquier valor entre -inf y +inf, y la neurona no sabe cómo limitar los valores, por lo que no puede decidir el patrón de disparo. La función de activación decide si una neurona debe activarse o no para limitar los valores de entrada netos.
Tipos más comunes de funciones de activación:
La respuesta depende completamente de ti. Pero antes de responder, debes considerar qué objetivo empresarial deseas alcanzar para establecer una métrica de rendimiento y cómo vas a obtener los datos.
En un diseño típico de sistema de machine learning, vosotros:
Debes asegurarte de centrarte en el diseño, más que en la teoría o la arquitectura del modelo. Asegúrate de hablar sobre la inferencia del modelo y cómo mejorarla aumentará los ingresos generales.
Además, explica por qué elegiste una metodología en lugar de otra.
Aprende más sobre cómo crear sistemas de recomendación realizando un curso en DataCamp.
Resolver retos de programación y mejorar tus habilidades en Python aumentará tus posibilidades de superar la fase de la entrevista de programación.
Antes de lanzarte a resolver un problema, debes comprender la pregunta. Simplemente tienes que crear una función booleana que devuelva True si, al desplazar las letras de la cadena B, obtienes la cadena A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEl aprendizaje conjunto se utiliza para combinar los conocimientos de múltiples modelos de machine learning con el fin de mejorar la precisión y las métricas de rendimiento.
Métodos de conjunto simples:
Métodos avanzados de conjunto:
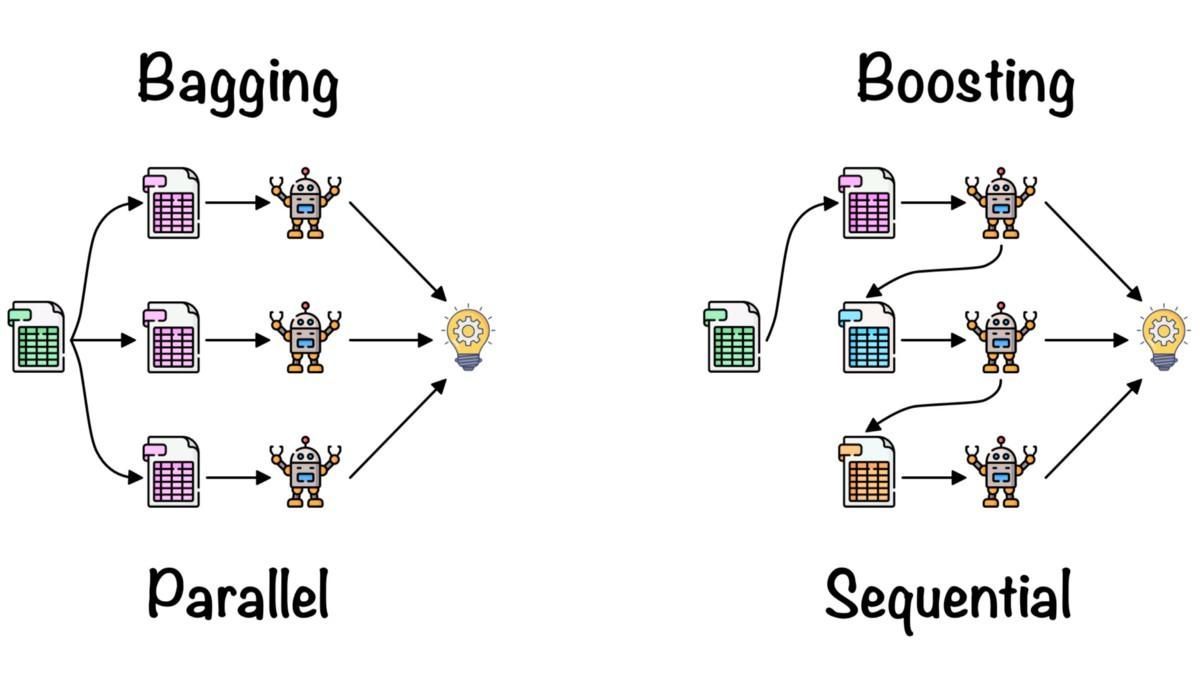
Bagging and Boosting by Fernando López
Aprende más sobre promedios, agrupación, apilamiento y refuerzo completando el curso Métodos de conjunto en Python.
Al concluir nuestra exploración de las preguntas esenciales para una entrevista sobre machine learning, queda claro que para tener éxito en este tipo de entrevistas es necesario combinar conocimientos teóricos, habilidades prácticas y estar al tanto de las últimas tendencias y tecnologías en el campo. Desde comprender conceptos básicos como el aprendizaje semisupervisado y la selección de algoritmos, hasta profundizar en las complejidades de algoritmos específicos como KNN, y lidiar con retos específicos de cada función en el procesamiento del lenguaje natural, la visión artificial o el aprendizaje por refuerzo, el alcance es enorme.
Tanto si eres un principiante que desea iniciarse en este campo como si eres un profesional con experiencia que desea seguir avanzando, el aprendizaje y la práctica continuos son fundamentales. DataCamp ofrece un programa completo de científico de machine learning con Python que proporciona una forma estructurada y profunda de mejorar tus habilidades.
Cursos de machine learning
Curso
Curso
blog
Javier Canales Luna
8 min
blog
Tim Lu
9 min
blog
Abid Ali Awan
15 min
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min