
Curso
Introducción al Deep Learning en Python
4 h
263.5K
La detección de objetos es una técnica utilizada en visión por ordenador para la identificación y localización de objetos dentro de una imagen o un vídeo.
La localización de imágenes es el proceso de identificar la ubicación correcta de uno o varios objetos mediante cajas delimitadoras, que corresponden a formas rectangulares alrededor de los objetos.
Este proceso se confunde a veces con la clasificación de imágenes o el reconocimiento de imágenes, cuyo objetivo es predecir la clase de una imagen o de un objeto dentro de una imagen en una de las categorías o clases.
La siguiente ilustración corresponde a la representación visual de la explicación anterior. El objeto detectado en la imagen es "Persona".

Imagen del autor
En este blog conceptual, primero comprenderás las ventajas de la detección de objetos, antes de presentar YOLO, el algoritmo de detección de objetos más avanzado.
En la segunda parte, nos centraremos más en el algoritmo YOLO y en cómo funciona. Después, proporcionaremos algunas aplicaciones de la vida real utilizando YOLO.
La última sección explicará cómo ha evolucionado YOLO de 2015 a 2020, antes de concluir con los próximos pasos.
You Only Look Once (YOLO) es un algoritmo de detección de objetos en tiempo real de última generación introducido en 2015 por Joseph Redmon, Santosh Divvala, Ross Girshick y Ali Farhadi en su famoso trabajo de investigación "You Only Look Once: Detección de Objetos Unificada y en Tiempo Real".
Los autores enmarcan el problema de la detección de objetos como un problema de regresión en lugar de una tarea de clasificación, separando espacialmente las cajas delimitadoras y asociando probabilidades a cada una de las imágenes detectadas mediante una única red neuronal convolucional (CNN).
Realizando el curso Procesamiento de imágenes con Keras en Python, serás capaz de construir redes neuronales profundas basadas en Keras para tareas de clasificación de imágenes.
Si te interesa más Pytorch, Aprendizaje profundo con Pytorch te enseñará las redes neuronales convolucionales y cómo utilizarlas para construir modelos mucho más potentes.
Algunas de las razones por las que YOLO está a la cabeza de la competencia incluyen su:
YOLO es extremadamente rápido porque no se ocupa de canalizaciones complejas. Puede procesar imágenes a 45 fotogramas por segundo (FPS). Además, YOLO alcanza más del doble de precisión media (mAP) que otros sistemas en tiempo real, lo que lo convierte en un gran candidato para el procesamiento en tiempo real.
En el gráfico siguiente, observamos que YOLO supera con creces a los demás detectores de objetos, con 91 FPS.
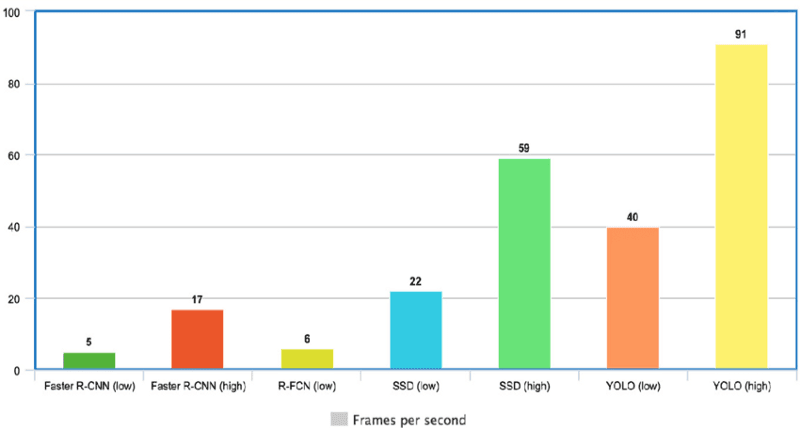
Velocidad de YOLO comparada con otros detectores de objetos de última generación(fuente)
YOLO supera con creces en precisión a otros modelos de última generación, con muy pocos errores de fondo.
Esto es especialmente cierto para las nuevas versiones de YOLO, de las que se hablará más adelante en el artículo. Con esos avances, YOLO ha ido un poco más allá al proporcionar una mejor generalización para nuevos dominios, lo que lo hace estupendo para aplicaciones que dependen de una detección de objetos rápida y robusta.
Por ejemplo, el artículo Detección automática del melanoma con redes neuronales convolucionales profundas de Yolo muestra que la primera versión YOLOv1 tiene la precisión media más baja para la detección automática de la enfermedad del melanoma, en comparación con YOLOv2 y YOLOv3.
Hacer que YOLO fuera de código abierto llevó a la comunidad a mejorar constantemente el modelo. Ésta es una de las razones por las que YOLO ha hecho tantas mejoras en tan poco tiempo.
La arquitectura de YOLO es similar a la de GoogleNet. Como se ilustra a continuación, tiene en total 24 capas convolucionales, cuatro capas de agrupamiento máximo y dos capas totalmente conectadas.
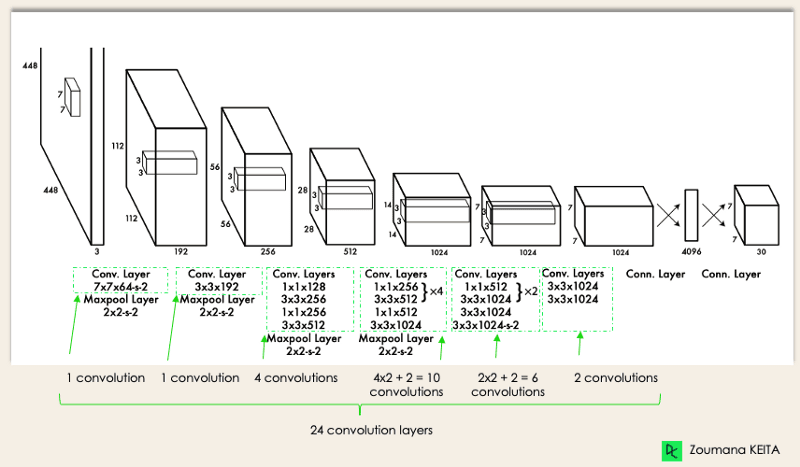
Arquitectura YOLO del documento original (Modificado por el autor)
La arquitectura funciona como sigue:
Al completar el curso de Aprendizaje Profundo en Python, estarás preparado para utilizar Keras para entrenar y probar redes complejas de múltiples salidas y profundizar en el aprendizaje profundo.
Ahora que entiendes la arquitectura, vamos a tener una visión general de alto nivel de cómo el algoritmo YOLO realiza la detección de objetos utilizando un caso de uso sencillo.
"Imagina que creas una aplicación YOLO que detecta jugadores y balones de fútbol a partir de una imagen dada.
Pero, ¿cómo puedes explicar este proceso a alguien, especialmente a las personas no iniciadas?
→ Ese es el objetivo de esta sección. Entenderás todo el proceso de cómo YOLO realiza la detección de objetos; cómo obtener la imagen (B) a partir de la imagen (A)"
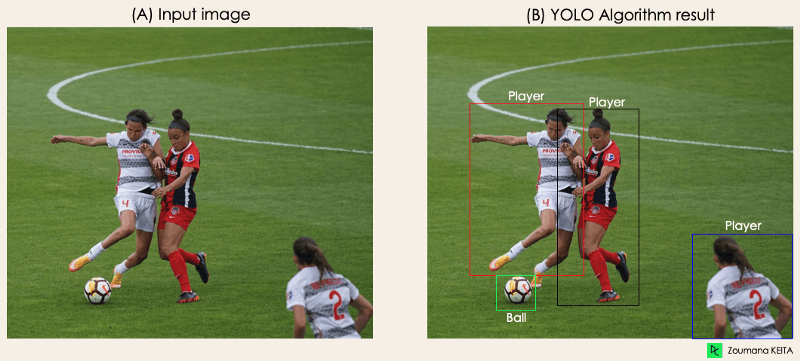 Imagen del autor
Imagen del autor
El algoritmo funciona basándose en los cuatro enfoques siguientes:
Echemos un vistazo más de cerca a cada uno de ellos.
Este primer paso comienza dividiendo la imagen original (A) en celdas de cuadrícula NxN de igual forma, donde N en nuestro caso es 4, mostradas en la imagen de la derecha. Cada celda de la cuadrícula es responsable de localizar y predecir la clase del objeto que abarca, junto con el valor de probabilidad/confianza.

Imagen del autor
El siguiente paso es determinar las cajas delimitadoras, que corresponden a rectángulos que resaltan todos los objetos de la imagen. Podemos tener tantas cajas delimitadoras como objetos haya en una imagen determinada.
YOLO determina los atributos de estos recuadros delimitadores utilizando un único módulo de regresión con el siguiente formato, donde Y es la representación vectorial final de cada recuadro delimitador.
Y = [pc, bx, by, bh, bw, c1, c2]
Esto es especialmente importante durante la fase de entrenamiento del modelo.
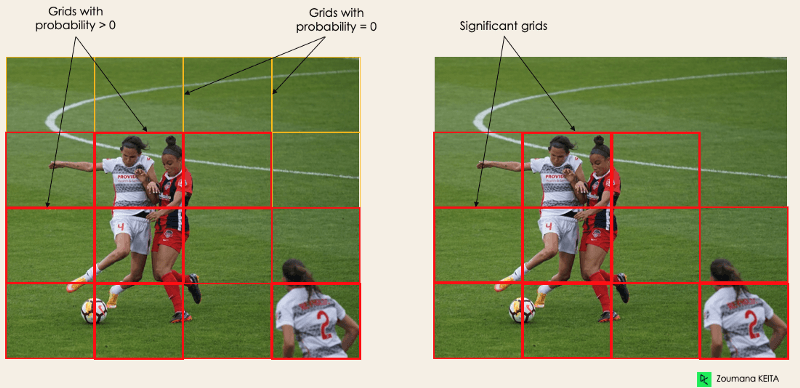
Imagen del autor
Para entenderlo, prestemos más atención al jugador de la parte inferior derecha.
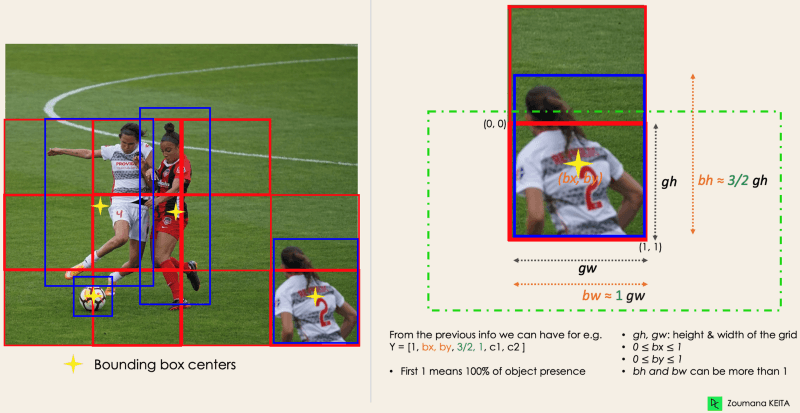 del autor
del autor
La mayoría de las veces, un solo objeto de una imagen puede tener varias cajas cuadriculadas candidatas a la predicción, aunque no todas sean relevantes. El objetivo del IOU (un valor entre 0 y 1) es descartar esas casillas de la cuadrícula para conservar sólo las que sean relevantes. Ésta es la lógica que hay detrás:
A continuación se muestra una ilustración de la aplicación del proceso de selección de cuadrícula al objeto inferior izquierdo. Podemos observar que el objeto tenía originalmente dos cuadrículas candidatas, pero al final sólo se seleccionó la "Cuadrícula 2".
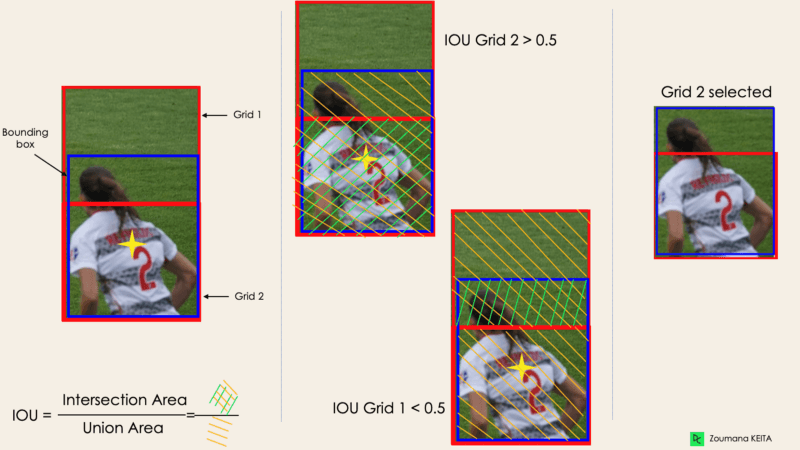
Imagen del autor
Establecer un umbral para el IOU no siempre es suficiente, porque un objeto puede tener varias casillas con IOU por encima del umbral, y dejar todas esas casillas podría incluir ruido. Aquí es donde podemos utilizar el NMS para conservar sólo las casillas con mayor puntuación de probabilidad de detección.
La detección de objetos YOLO tiene distintas aplicaciones en nuestra vida cotidiana. En esta sección trataremos algunos de ellos en los siguientes ámbitos: sanidad, agricultura, vigilancia de la seguridad y coches autónomos.
La detección de objetos se ha introducido en muchos sectores prácticos, como la sanidad y la agricultura. Vamos a entender cada una de ellas con ejemplos concretos.
Concretamente en cirugía, puede ser un reto localizar órganos en tiempo real, debido a la diversidad biológica de un paciente a otro. Reconocimiento de riñones en TC utilizó YOLOv3 para facilitar la localización de riñones en 2D y 3D a partir de tomografías computerizadas (TC).
El curso Análisis de Imágenes Biomédicas en Python puede ayudarte a aprender los fundamentos de la exploración, manipulación y medición de datos de imágenes biomédicas utilizando Python.
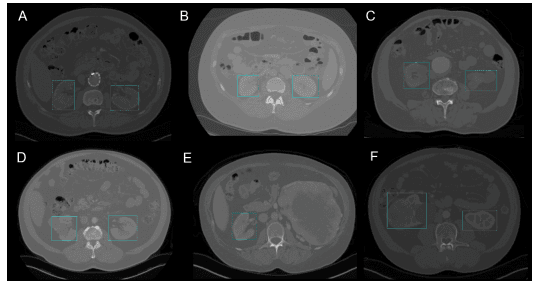
Detección del riñón en 2D mediante YOLOv3(Imagen de Reconocimiento del riñón en TC mediante YOLOv3)
La inteligencia artificial y la robótica están desempeñando un papel fundamental en la agricultura moderna. Los robots recolectores son robots basados en la visión que se introdujeron para sustituir la recolección manual de frutas y verduras. Uno de los mejores modelos en este campo utiliza YOLO. En Detección de tomates basada en el marco YOLOv3 modificado, los autores describen cómo utilizaron YOLO para identificar los tipos de frutas y verduras para una cosecha eficiente.

Imagen de la detección de tomates basada en el marco YOLOv3 modificado(fuente)
Aunque la detección de objetos se utiliza sobre todo en la vigilancia de seguridad, no es la única aplicación. YOLOv3 se ha utilizado durante la pandemia de covid19 para estimar las violaciones de la distancia social entre las personas.
Puedes ampliar tu lectura sobre este tema en Un marco de supervisión de la distancia social basado en el aprendizaje profundo para COVID-19.
La detección de objetos en tiempo real forma parte del ADN de los sistemas de vehículos autónomos. Esta integración es vital para los vehículos autónomos, porque necesitan identificar correctamente los carriles correctos y todos los objetos y peatones circundantes para aumentar la seguridad vial. El aspecto en tiempo real de YOLO lo convierte en un candidato mejor que los enfoques simples de segmentación de imágenes.
Desde el primer lanzamiento de YOLO en 2015, ha evolucionado mucho con diferentes versiones. En esta sección, comprenderemos las diferencias entre cada una de estas versiones.
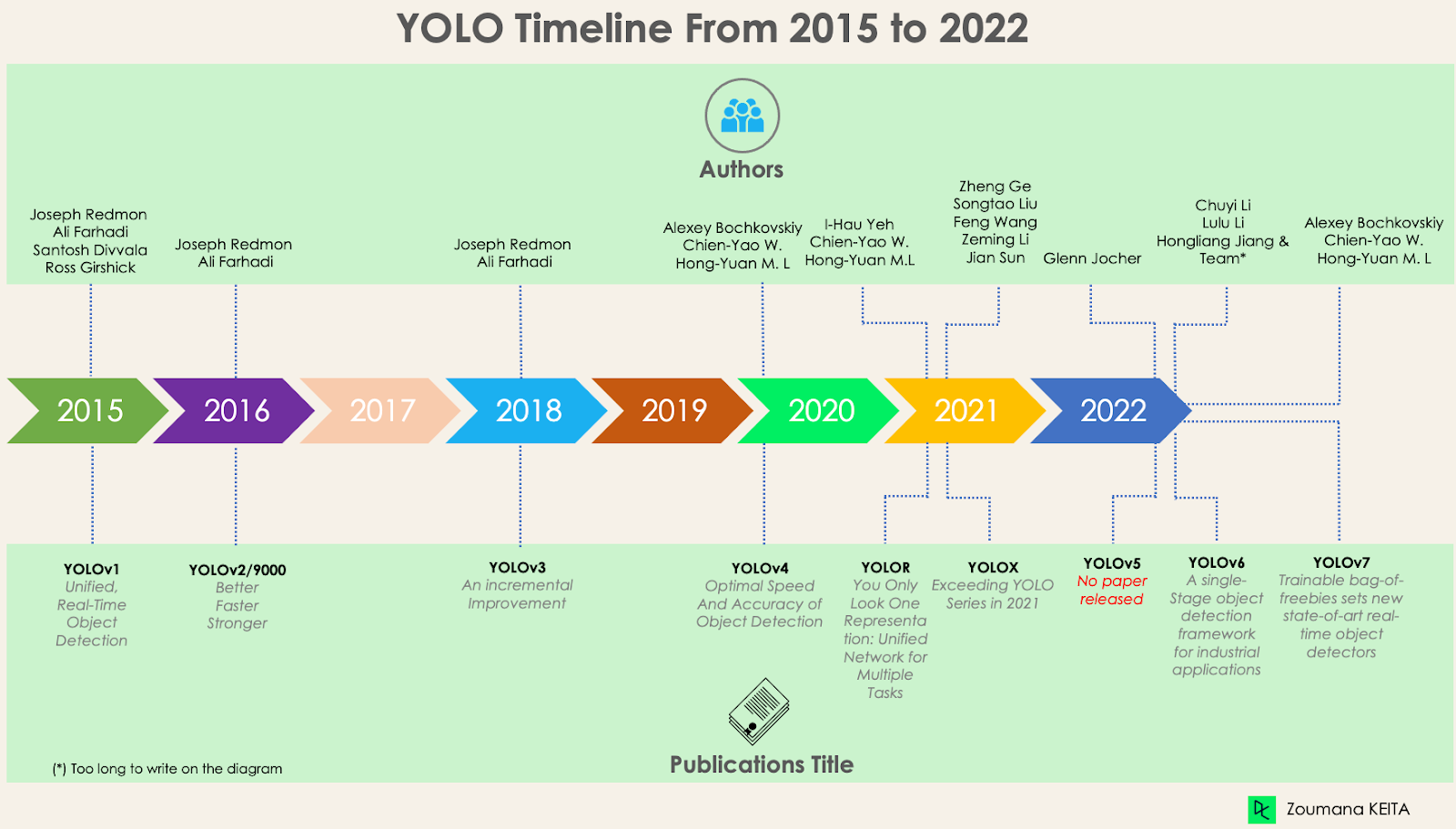
Esta primera versión de YOLO supuso un cambio en la detección de objetos, por su capacidad para reconocerlos de forma rápida y eficaz.
Sin embargo, como muchas otras soluciones, la primera versión de YOLO tiene sus propias limitaciones:
YOLOv2 se creó en 2016 con la idea de hacer el modelo YOLO mejor, más rápido y más fuerte.
La mejora incluye, entre otras cosas, el uso de Darknet-19 como nueva arquitectura, la normalización por lotes, una mayor resolución de las entradas, capas de convolución con anclas, agrupación dimensional y (5) características de grano fino.
Añadir una capa de normalización por lotes mejoró el rendimiento en un 2% mAP. Esta normalización por lotes incluía un efecto de regularización, que evitaba el sobreajuste.
YOLOv2 utiliza directamente una entrada de mayor resolución 448×448 en lugar de 224×224, lo que hace que el modelo ajuste su filtro para rendir mejor en imágenes de mayor resolución. Este enfoque aumentó la precisión en un 4% mAP, tras ser entrenado durante 10 épocas en los datos de ImageNet.
En lugar de predecir la coordenada exacta de las cajas delimitadoras de los objetos como hace YOLOv1, YOLOv2 simplifica el problema sustituyendo las capas totalmente conectadas por cajas de anclaje. Este enfoque disminuyó ligeramente la precisión, pero mejoró la recuperación del modelo en un 7%, lo que da más margen de mejora.
Las cajas de anclaje mencionadas anteriormente son encontradas automáticamente por YOLOv2 utilizando la agrupación dimensional de k-means con k=5, en lugar de realizar una selección manual. Este novedoso enfoque proporcionó un buen equilibrio entre el recuerdo y la precisión del modelo.
Para comprender mejor la agrupación dimensional de k-means, echa un vistazo a nuestros tutoriales Agrupación de K-Means en Python con scikit-learn y Agrupación de K-Means en R. Se sumergen en el concepto de agrupación de k-means utilizando Python y R.
Las predicciones de YOLOv2 generan mapas de características de 13x13, lo que por supuesto es suficiente para la detección de objetos grandes. Pero para detectar objetos mucho más finos, se puede modificar la arquitectura convirtiendo el mapa de características de 26 × 26 × 512 en un mapa de características de 13 × 13 × 2048, concatenado con las características originales. Este enfoque mejoró el rendimiento del modelo en un 1%.
Se ha realizado una mejora incremental en el YOLOv2 para crear el YOLOv3.
El cambio incluye principalmente una nueva arquitectura de red: Darknet-53. Se trata de una red neuronal 106, con redes de muestreo ascendente y bloques residuales. Es mucho mayor, más rápido y más preciso que Darknet-19, que es la columna vertebral de YOLOv2. Esta nueva arquitectura ha sido beneficiosa a muchos niveles:
YOLOv3 utiliza un modelo de regresión logística para predecir la puntuación de objetualidad de cada cuadro delimitador.
En lugar de utilizar softmax como se hacía en YOLOv2, se han introducido clasificadores logísticos independientes para predecir con precisión la clase de los cuadros delimitadores. Esto es útil incluso ante dominios más complejos con etiquetas superpuestas (por ejemplo, Persona → Jugador de fútbol). Utilizar un softmax limitaría cada casilla a tener una sola clase, lo que no siempre es cierto.
YOLOv3 realiza tres predicciones a diferentes escalas para cada ubicación dentro de la imagen de entrada para ayudar con el remuestreo de las capas anteriores. Esta estrategia permite obtener información semántica de grano fino y más significativa para obtener una imagen de salida de mejor calidad.
Esta versión de YOLO tiene una Velocidad y Precisión de Detección de Objetos óptimas en comparación con todas las versiones anteriores y con otros detectores de objetos de última generación.
La imagen de abajo muestra que el YOLOv4 supera al YOLOv3 y al FPS en velocidad en un 10% y un 12% respectivamente.
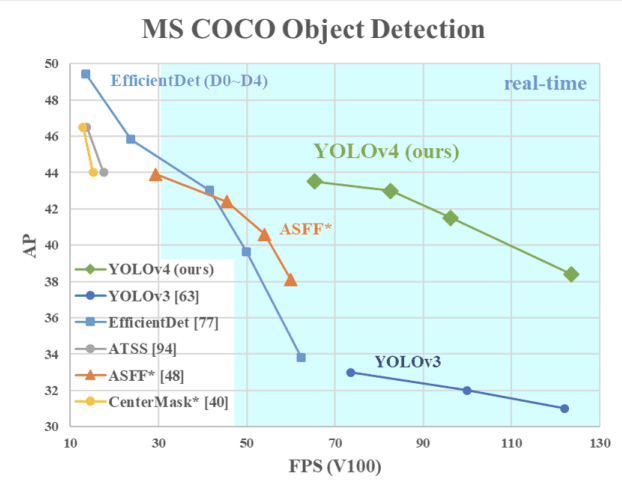
Velocidad de YOLOv4 comparada con YOLOv3 y otros detectores de objetos de última generación(fuente)
YOLOv4 está diseñado específicamente para sistemas de producción y optimizado para cálculos paralelos.
La columna vertebral de la arquitectura de YOLOv4 es CSPDarknet53, una red que contiene 29 capas de convolución con filtros de 3 × 3 y aproximadamente 27,6 millones de parámetros.
Esta arquitectura, comparada con YOLOv3, añade la siguiente información para una mejor detección de objetos:
Como Red Unificada para Tareas Múltiples, YOLOR se basa en la red unificada, que es una combinación de enfoques de conocimiento explícito e implícito.
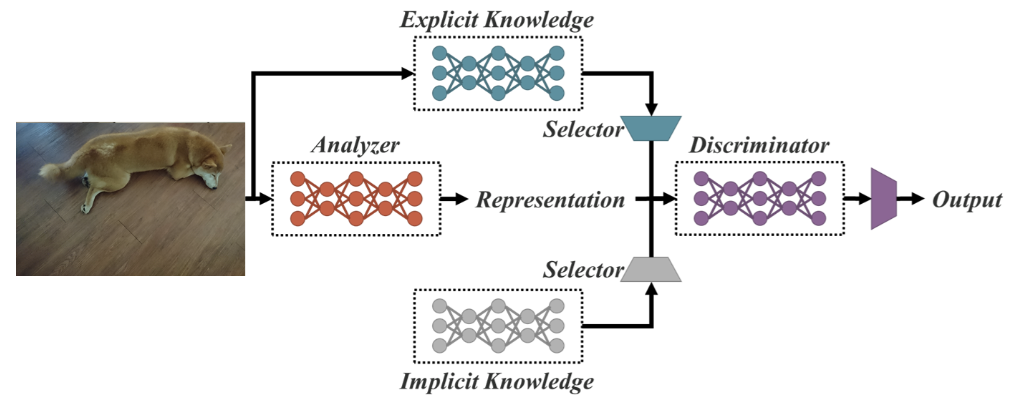
Arquitectura de red unificada (fuente)
El conocimiento explícito es el aprendizaje normal o consciente. En cambio, el aprendizaje implícito es el que se realiza inconscientemente (a partir de la experiencia).
Combinando estas dos técnicas, YOLOR es capaz de crear una arquitectura más robusta basada en tres procesos: (1) alineación de rasgos, (2) alineación de predicciones para la detección de objetos, y (3) representación canónica para el aprendizaje multitarea
Este enfoque introduce una representación implícita en el mapa de características de cada red piramidal de características (FPN), lo que mejora la precisión en un 0,5% aproximadamente.
Las predicciones del modelo se refinan añadiendo una representación implícita a las capas de salida de la red.
Realizar un entrenamiento multitarea requiere la ejecución de la optimización conjunta sobre la función de pérdida compartida entre todas las tareas. Este proceso puede disminuir el rendimiento global del modelo, y este problema puede mitigarse con la integración de la representación canónica durante el entrenamiento del modelo.
En el gráfico siguiente, podemos observarque YOLOR consiguió en los datos de MS COCO una velocidad de inferencia puntera en comparación con otros modelos.
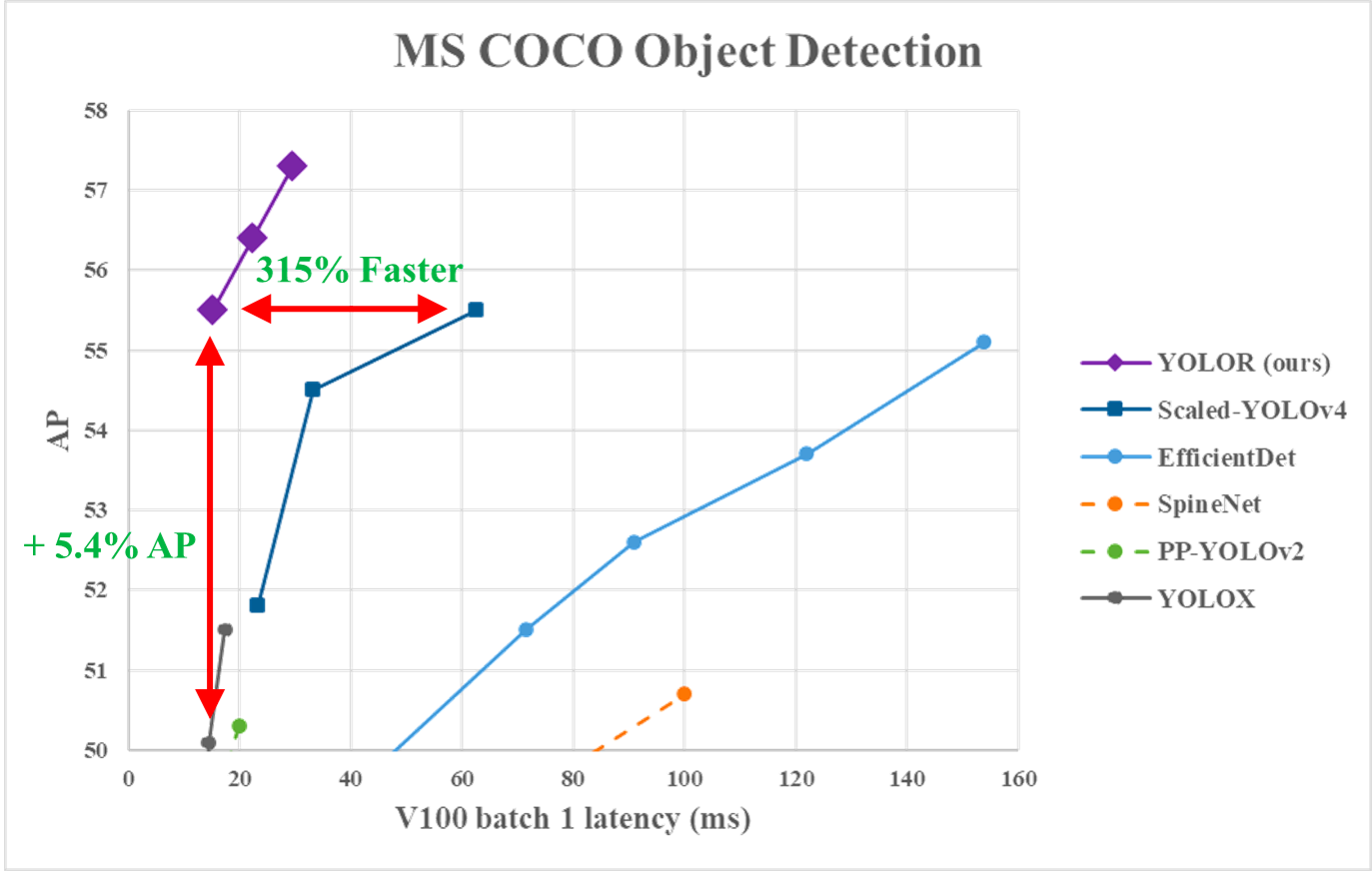
Rendimiento de YOLOR frente a YOLOv4 y otros modelos (fuente)
Utiliza una línea de base que es una versión modificada de YOLOv3, con Darknet-53 como columna vertebral.
Publicado en el documento Superar la serie YOLO en 2021, YOLOX pone sobre la mesa las siguientes cuatro características clave para crear un modelo mejor en comparación con las versiones anteriores.
Se demuestra que la cabeza acoplada utilizada en las versiones anteriores de YOLO reduce el rendimiento de los modelos. En cambio, YOLOX utiliza un método desacoplado, que permite separar las tareas de clasificación y localización, aumentando así el rendimiento del modelo.
La integración de Mosaic y MixUp en el enfoque de aumento de datos aumentó considerablemente el rendimiento de YOLOX.
Los algoritmos basados en anclas realizan la agrupación bajo el capó, lo que aumenta el tiempo de inferencia. La eliminación del mecanismo de anclaje en YOLOX redujo el número de predicciones por imagen, y mejoró significativamente el tiempo de inferencia.
En lugar de utilizar el enfoque de intersección de unión (IoU), el autor introdujo SimOTA, una estrategia de asignación de etiquetas más robusta que consigue resultados de vanguardia, no sólo reduciendo el tiempo de entrenamiento, sino también evitando problemas de hiperparámetros adicionales. Además, mejoró la mAP de detección en un 3%.
YOLOv5, en comparación con otras versiones, no tiene ningún artículo de investigación publicado, y es la primera versión de YOLO que se implementa en Pytorch, en lugar de Darknet.
Publicado por Glenn Jocher en junio de 2020, YOLOv5, de forma similar a YOLOv4, utiliza CSPDarknet53 como columna vertebral de su arquitectura. El lanzamiento incluye cinco tamaños de modelo diferentes: YOLOv5s (el más pequeño), YOLOv5m, YOLOv5l y YOLOv5x (el más grande).
Una de las principales mejoras de la arquitectura de YOLOv5 es la integración de la capa Focus, representada por una sola capa, que se crea sustituyendo las tres primeras capas de YOLOv3. Esta integración redujo el número de capas y el número de parámetros, y también aumentó la velocidad de avance y retroceso sin que ello repercutiera mucho en el mAP.
La siguiente ilustración compara el tiempo de entrenamiento entre YOLOv4 y YOLOv5s.
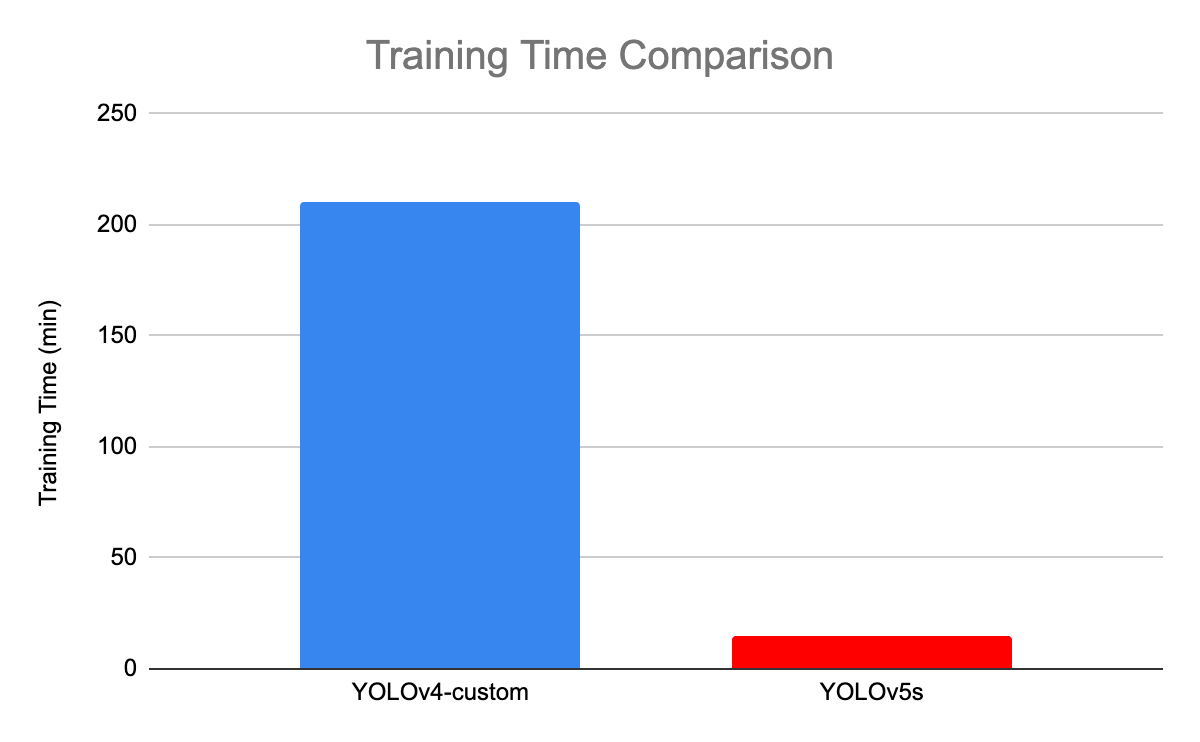
Comparación del tiempo de entrenamiento entre YOLOv4 y YOLOv5(fuente)
Dedicado a aplicaciones industriales con un diseño eficiente y un alto rendimiento, el framework YOLOv6 (MT-YOLOv6) fue lanzado por Meituan, una empresa china de comercio electrónico.
Escrita en Pytorch, esta nueva versión no formaba parte del YOLO oficial, pero aun así recibió el nombre de YOLOv6 porque su columna vertebral se inspiraba en la arquitectura YOLO original de una etapa.
YOLOv6 introdujo tres mejoras significativas con respecto al anterior YOLOv5: un diseño de columna vertebral y cuello que se adapta al hardware, una cabeza desacoplada eficiente y una estrategia de entrenamiento más eficaz.
YOLOv6 proporciona resultados sobresalientes en comparación con las versiones anteriores de YOLO en cuanto a precisión y velocidad en el conjunto de datos COCO, como se ilustra a continuación.
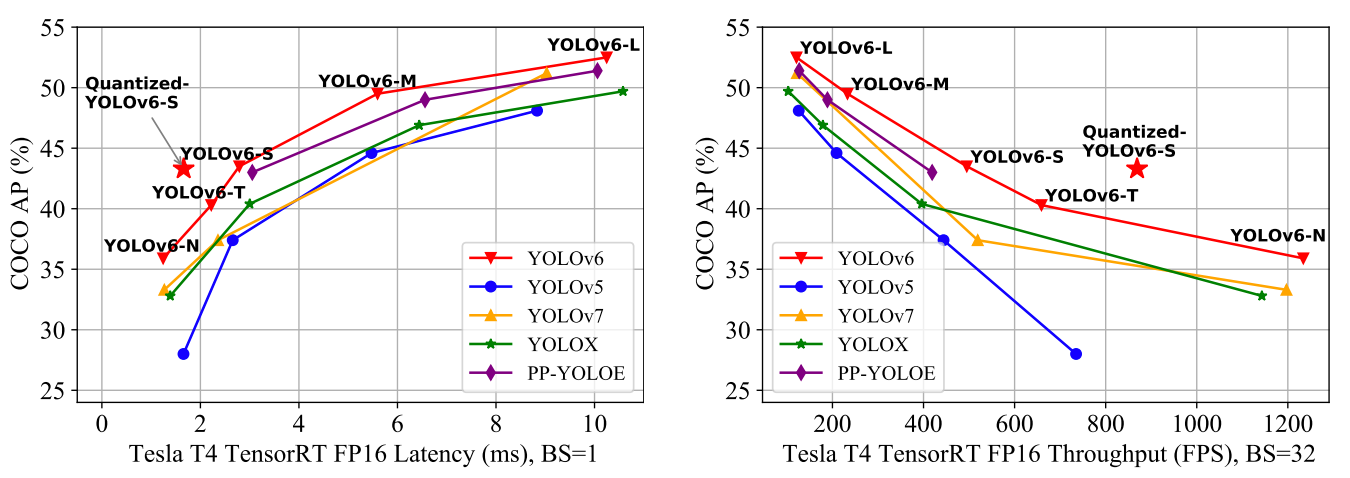
Comparación de detectores de objetos eficientes de última generación. Todos los modelos se han probado con TensorRT 7, excepto el modelo cuantizado, que es con TensorRT 8(fuente)
Todas estas características hacen de YOLOv5, el algoritmo adecuado para las aplicaciones industriales.
YOLOv7 se publicó en julio de 2022 en el artículo La bolsa de objetos libres entrenada establece un nuevo estado de la técnica para los detectores de objetos en tiempo real. Esta versión supone un avance significativo en el campo de la detección de objetos, y supera a todos los modelos anteriores en precisión y velocidad.
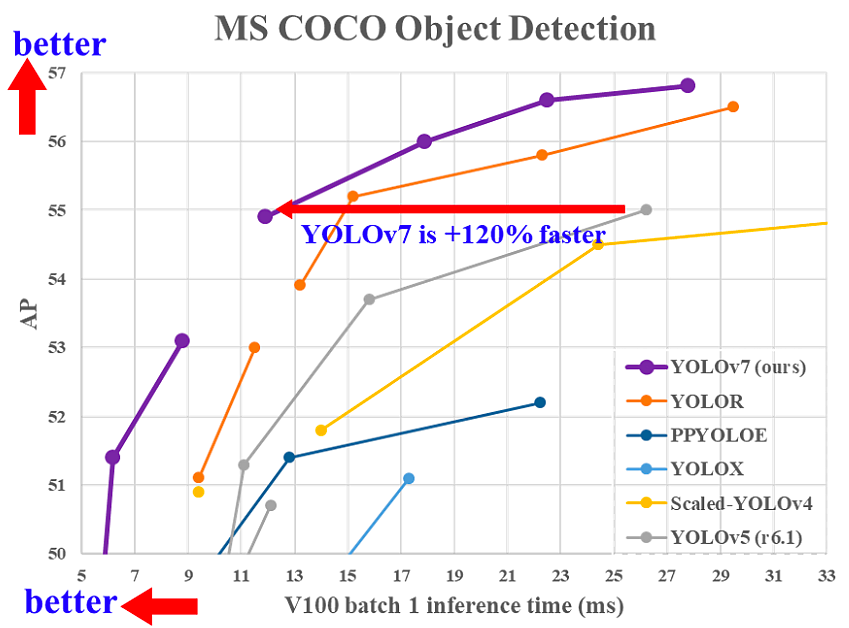
Comparación del tiempo de inferencia de YOLOv7 con otros detectores de objetos en tiempo real(fuente)
YOLOv7 ha introducido un cambio importante en su (1) arquitectura y (2) en el nivel de bolsa de regalos entrenable:
YOLOv7 reformó su arquitectura integrando la Red de Agregación de Capas Eficiente Ampliada (E-ELAN), que permite al modelo aprender características más diversas para un mejor aprendizaje.
Además, YOLOv7 escala su arquitectura concatenando la arquitectura de los modelos de los que deriva, como YOLOv4, YOLOv4 escalado y YOLO-R. Esto permite que el modelo satisfaga las necesidades de diferentes velocidades de inferencia.
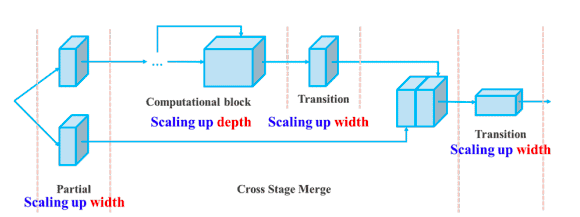
Escala compuesta de profundidad y anchura para el modelo basado en la concatenación(fuente)
El término bag-of-freebies se refiere a mejorar la precisión del modelo sin aumentar el coste de entrenamiento, y ésta es la razón por la que YOLOv7 aumentó no sólo la velocidad de inferencia, sino también la precisión de detección.
En este artículo se han tratado las ventajas de YOLO en comparación con otros algoritmos de detección de objetos de última generación, y su evolución de 2015 a 2020, destacando sus beneficios.
Dado el rápido avance de YOLO, no hay duda de que seguirá siendo el líder en el campo de la detección de objetos durante mucho tiempo.
El siguiente paso de este artículo será la aplicación del algoritmo YOLO a casos del mundo real. Hasta entonces, nuestro curso Introducción al Aprendizaje Profundo en Py thon puede ayudarte a aprender los fundamentos de las redes neuronales y cómo construir modelos de aprendizaje profundo utilizando Keras 2.0 en Python.
Cursos de Aprendizaje Profundo
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Zoumana Keita
14 min
blog
Kurtis Pykes
8 min
blog
Matt Crabtree
14 min
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita



