Los modelos de machine learning son cada vez más complejos, potentes y capaces de hacer predicciones precisas. Sin embargo, a medida que estos modelos se convierten en "cajas negras", resulta aún más difícil comprender cómo llegaron a esas predicciones. Esto ha hecho que se preste cada vez más atención a la interpretabilidad y explicabilidad del machine learning.
Por ejemplo, solicitaste un préstamo en un banco pero te lo denegaron. Quieres saber el motivo del rechazo, pero el agente del servicio de atención al cliente te responde que un algoritmo desestimó la solicitud, y que no pueden determinar el motivo. Esto es frustrante, ¿verdad? Mereces una explicación de la decisión que te afecta. Por eso las empresas intentan que sus modelos de machine learning sean más transparentes y comprensibles.
Una de las herramientas más prometedoras para este proceso son los valores SHAP, que miden cuánto contribuye cada característica (como los ingresos, la edad, la puntuación crediticia, etc.) a la predicción del modelo. Los valores SHAP pueden ayudarte a ver qué características son las más importantes para el modelo y cómo afectan al resultado.
En este tutorial, aprenderemos sobre los valores SHAP y su papel en la interpretación de modelos de machine learning. También utilizaremos el paquete `Shap` de Python para crear y analizar distintos gráficos para interpretar los modelos.
¿Qué son los Valores SHAP?
Los valores SHAP (SHapley Additive exPlanations) son una forma de explicar la salida de cualquier modelo de machine learning. Utiliza un enfoque de teoría de juegos que mide la contribución de cada jugador al resultado final. En el machine learning, a cada característica se le asigna un valor de importancia que representa su contribución al resultado del modelo.
Los valores SHAP muestran cómo afecta cada rasgo a cada predicción final, la importancia de cada rasgo en comparación con los demás y la dependencia del modelo de la interacción entre rasgos.
Valores SHAP en machine learning
Los valores SHAP son una forma habitual de obtener una explicación coherente y objetiva de cómo influye cada característica en la predicción del modelo.
Los valores SHAP se basan en la teoría de juegos y asignan un valor de importancia a cada característica de un modelo. Los rasgos con valores SHAP positivos tienen un impacto positivo en la predicción, mientras que los que tienen valores negativos tienen un impacto negativo. La magnitud es una medida de la fuerza del efecto.
Los valores SHAP son independientes del modelo, lo que significa que pueden utilizarse para interpretar cualquier modelo de machine learning, incluyendo:
- Regresión lineal
- Árboles de decisión
- Bosques aleatorios
- Modelos de refuerzo de gradiente
- Redes neuronales
Las propiedades de los valores SHAP
Los valores SHAP tienen varias propiedades útiles que los hacen eficaces para interpretar los modelos:
Aditividad
Los valores SHAP son aditivos, lo que significa que la contribución de cada característica a la predicción final puede calcularse independientemente y luego sumarse. Esta propiedad permite calcular eficazmente los valores SHAP, incluso para conjuntos de datos de alta dimensión.
Precisión local
Los valores SHAP suman la diferencia entre la salida esperada del modelo y la salida real para una entrada determinada. Esto significa que los valores SHAP proporcionan una interpretación precisa y local de la predicción del modelo para una entrada determinada.
Ausencia
Los valores SHAP son cero para las características ausentes o irrelevantes para una predicción. Esto hace que los valores SHAP sean robustos frente a los datos que faltan y garantiza que los rasgos irrelevantes no distorsionen la interpretación.
Coherencia
Los valores SHAP no cambian cuando cambia el modelo, a menos que cambie la contribución de una característica. Esto significa que los valores SHAP proporcionan una interpretación coherente del comportamiento del modelo, incluso cuando cambian la arquitectura o los parámetros del modelo.
En general, los valores SHAP proporcionan una forma coherente y objetiva de conocer cómo hace predicciones un modelo de machine learning y qué características tienen mayor influencia.
Cómo implementar valores SHAP en Python
En esta sección, calcularemos los valores SHAP y visualizaremos la importancia de los rasgos, la dependencia de los rasgos, la fuerza y el gráfico de decisión. Puedes encontrar el código fuente, el conjunto de datos y las visualizaciones en DataCamp Workspace.
Configuración
Instala SHAP utilizando PyPI o conda-forge:
pip install shapo
conda install -c conda-forge shapCarga el Churn de Clientes de Telecomunicaciones. El conjunto de datos parece limpio, y la columna objetivo es "Churn".
import shap
import pandas as pd
import numpy as np
shap.initjs()
customer = pd.read_csv("data/customer_churn.csv")
customer.head()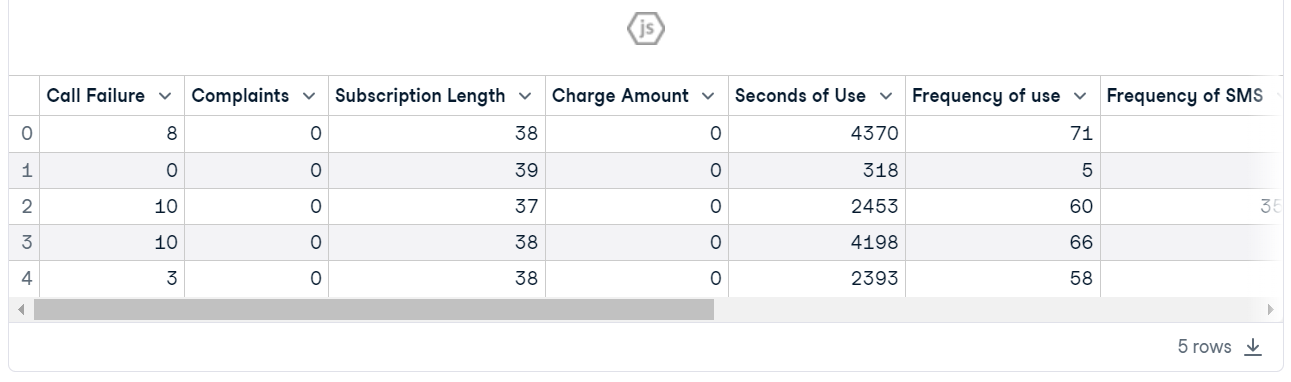
Entrenamiento y evaluación del modelo
- Crea X e y utilizando una columna objetivo y divide el conjunto de datos en entrenamiento y prueba.
- Entrena el clasificador Random Forest en el conjunto de entrenamiento.
- Haz predicciones utilizando un conjunto de pruebas.
- Muestra el informe de clasificación.
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
X = customer.drop("Churn", axis=1) # Independent variables
y = customer.Churn # Dependent variable
# Split into train and test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# Train a machine learning model
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# Make prediction on the testing data
y_pred = clf.predict(X_test)
# Classification Report
print(classification_report(y_pred, y_test))El modelo ha mostrado un mejor rendimiento para la etiqueta "0" que para la "1", debido a un conjunto de datos desequilibrado. En general, un 94 % de precisión es un resultado aceptable.
precision recall f1-score support
0 0.97 0.96 0.97 815
1 0.79 0.82 0.80 130
accuracy 0.94 945
macro avg 0.88 0.89 0.88 945
weighted avg 0.94 0.94 0.94 945Consulta nuestra guía Clasificación en el machine learning para aprender sobre la clasificación en el machine learning con ejemplos en Python.
Configurar SHAP Explainer
Ahora viene la parte explicativa del modelo.
Primero crearemos un objeto explicativo proporcionando un modelo de clasificación de bosque aleatorio, y luego calcularemos el valor SHAP utilizando un conjunto de pruebas.
explainer = shap.Explainer(clf)
shap_values = explainer.shap_values(X_test)Gráfico resumen
Visualiza el summary_plot utilizando los valores SHAP y el conjunto de pruebas.
shap.summary_plot(shap_values, X_test)El gráfico resumen muestra la importancia de cada característica en el modelo. Los resultados muestran que “Status”, “Complaints” y “Frequency of use” desempeñan papeles importantes en la determinación de los resultados.
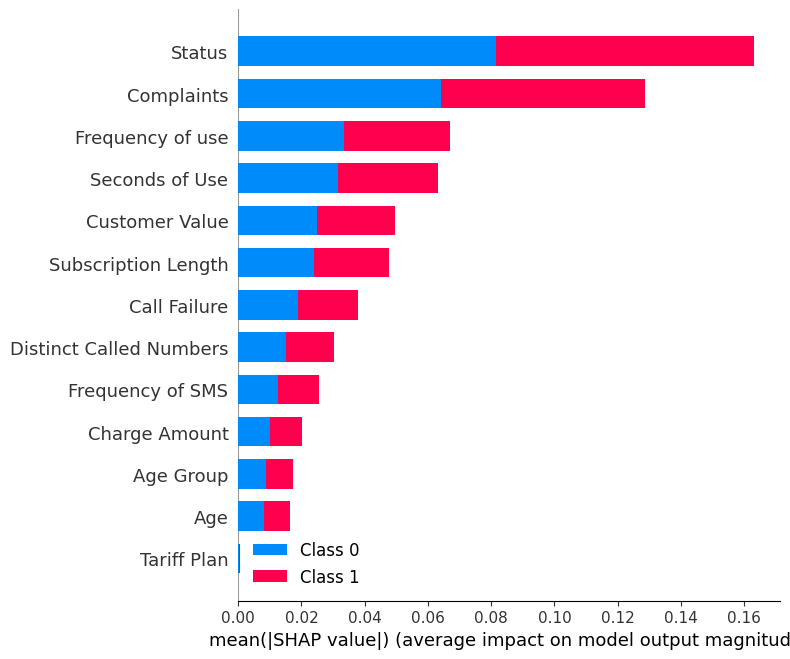
Muestra la dirección summary_plot de la etiqueta "0".
shap.summary_plot(shap_values[0], X_test)- El eje Y indica los nombres de las características por orden de importancia, de arriba abajo.
- El eje X representa el valor SHAP, que indica el grado de cambio en las probabilidades logarítmicas.
- El color de cada punto del gráfico representa el valor de la característica correspondiente, con el rojo indicando valores altos y el azul valores bajos.
- Cada punto representa una fila de datos del conjunto de datos original.
Si observas la característica “Complaints ', verás que en su mayoría es alta con un valor SHAP negativo. Significa que un mayor número de reclamaciones tiende a afectar negativamente al resultado.
Nota: para la etiqueta "1" la visualización se invertirá.
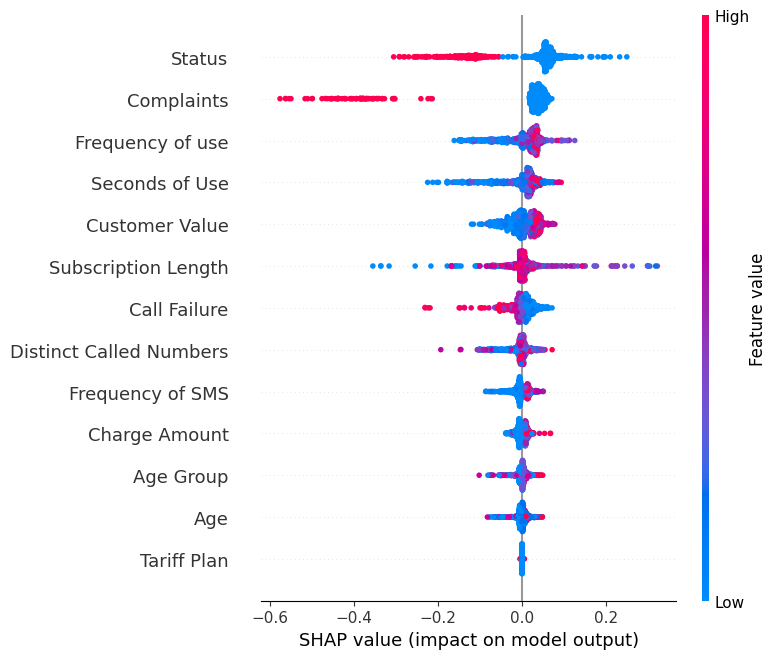
Gráfico de dependencia
Visualiza el `dependence_plot` entre la característica “Subscription Length” y “Age”.
shap.dependence_plot("Subscription Length", shap_values[0], X_test,interaction_index="Age")Un gráfico de dependencia es un tipo de gráfico de dispersión que muestra cómo se ven afectadas las predicciones de un modelo por una característica específica (Subscription Length). Por término medio, la duración de las suscripciones tiene un efecto mayoritariamente positivo en el modelo.
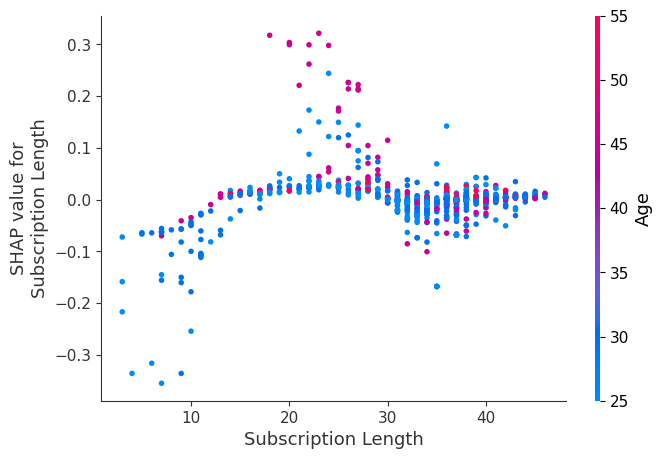
Diagrama de fuerzas
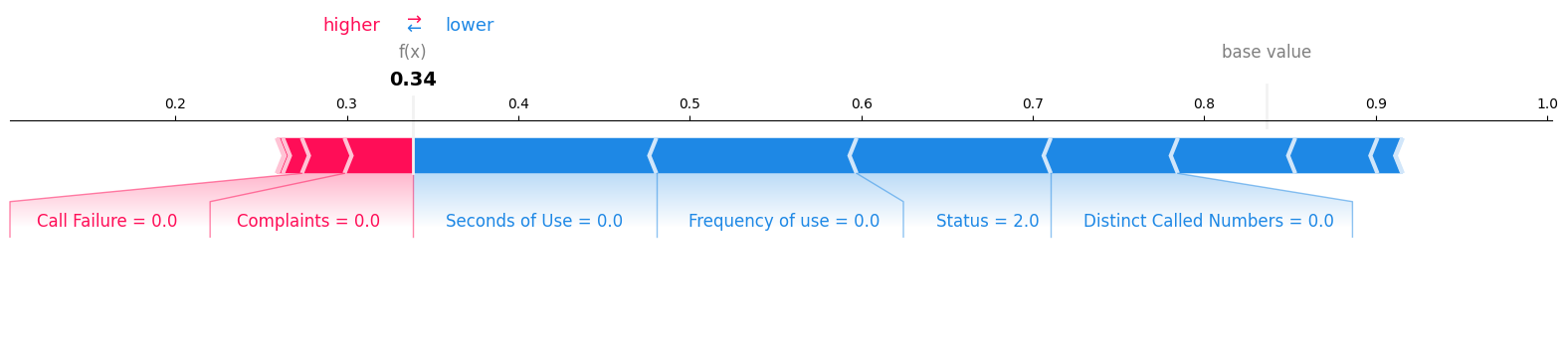
Examinaremos la primera muestra del conjunto de pruebas para determinar qué características contribuyeron al resultado "0". Para ello, utilizaremos un diagrama de fuerzas y proporcionaremos el valor esperado, el valor SHAP y la muestra de ensayo.
shap.plots.force(explainer.expected_value[0], shap_values[0][0,:], X_test.iloc[0, :], matplotlib = True)Podemos ver claramente que las cero reclamaciones y los cero fallos en las llamadas han contribuido negativamente a la pérdida de clientes.
Veamos las muestras de rotación de clientes con etiqueta "1".
shap.plots.force(explainer.expected_value[1], shap_values[1][6, :], X_test.iloc[6, :],matplotlib = True)Puedes ver todas las características con el valor y la magnitud que han contribuido a la pérdida de clientes. Parece que incluso una queja no resuelta puede costarle cara a una empresa de telecomunicaciones.
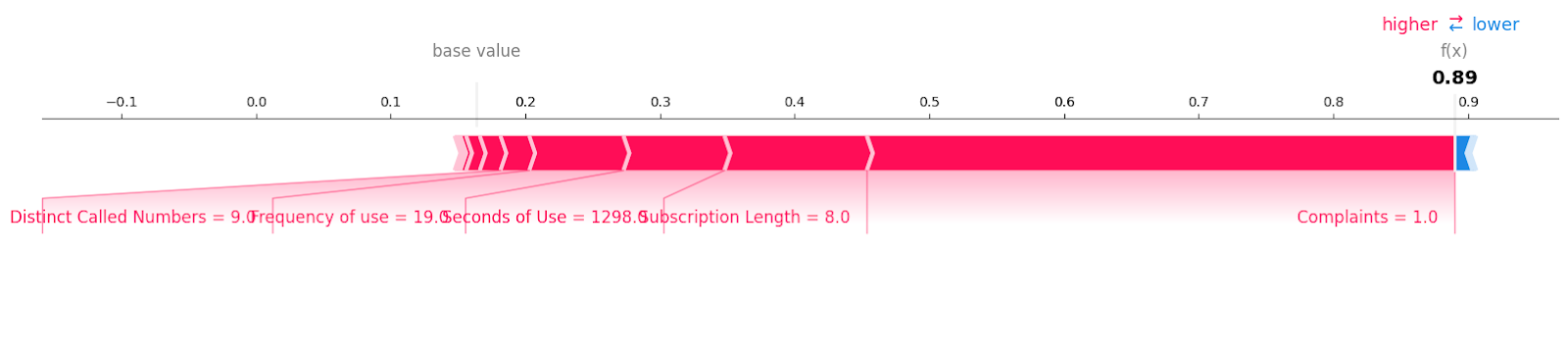
Gráfico de decisión
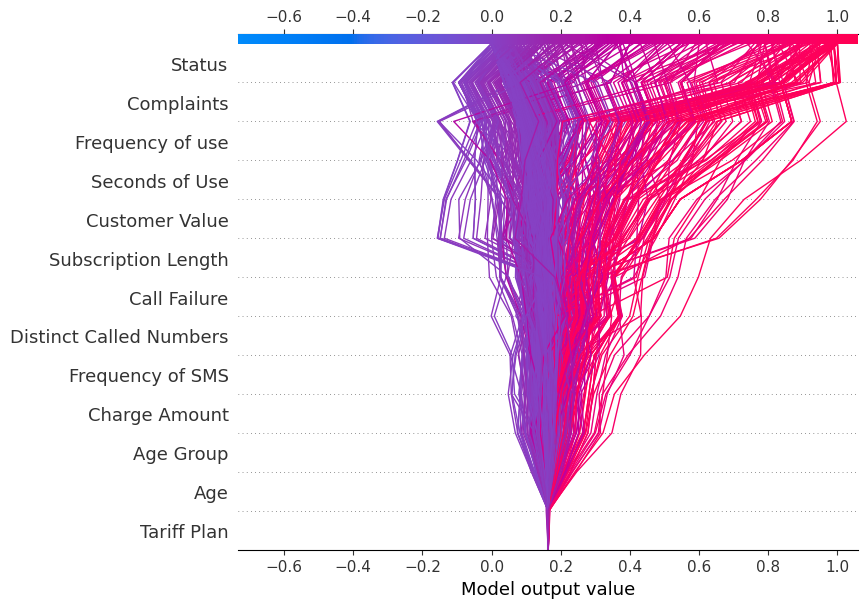
Ahora mostraremos decision_plot. Representa visualmente las decisiones del modelo mediante la asignación de los valores SHAP acumulados para cada predicción.
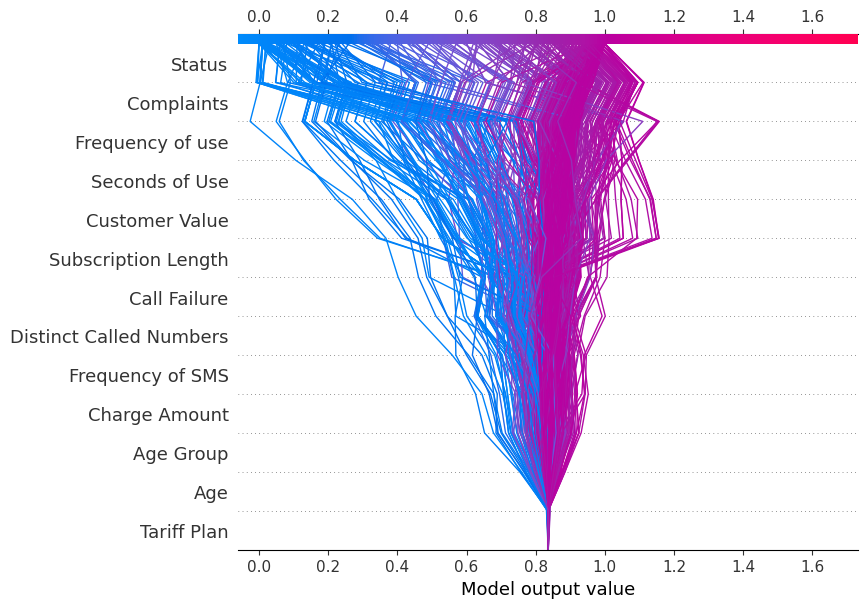
shap.decision_plot(explainer.expected_value[1], shap_values[1], X_test.columns)Cada línea trazada en el gráfico de decisión muestra la intensidad con que los rasgos individuales contribuyeron a la predicción de un único modelo, explicando así qué valores de rasgo impulsaron la predicción.
Nota: el gráfico de decisión de la etiqueta objetivo "1" está inclinado hacia "1".
Mostrar el gráfico de decisión para la etiqueta objetivo "0"
shap.decision_plot(explainer.expected_value[0], shap_values[0], X_test.columns)Ahora el gráfico de decisión se inclina hacia "0".
Aplicación de los valores SHAP
Aparte de la interpretabilidad y explicabilidad del machine learning, el valor SHAP puede utilizarse para:
- Depuración de modelos. Examinando los valores SHAP, podemos identificar cualquier sesgo o valor atípico en los datos que pueda estar haciendo que el modelo cometa errores.
- Importancia de las características. Identificar y eliminar los elementos de bajo impacto puede crear un modelo más optimizado.
- Explicaciones de anclaje. Podemos utilizar los valores SHAP para explicar predicciones individuales destacando las características esenciales que causaron esa predicción. Puede ayudar a los usuarios a comprender y confiar en las decisiones de un modelo.
- Resúmenes de modelos. Puede proporcionar un resumen global de un modelo en forma de gráfico resumen de valores SHAP. Ofrece una visión general de las características más importantes de todo el conjunto de datos.
- Detección de sesgos. El análisis de valores SHAP ayuda a identificar si ciertas características afectan desproporcionadamente a grupos concretos. Permite detectar y reducir la discriminación en el modelo.
- Auditoría de equidad. Puede utilizarse para evaluar la imparcialidad y las implicaciones éticas de un modelo.
- Aprobación reglamentaria. Los valores SHAP pueden ayudar a obtener la aprobación normativa explicando las decisiones del modelo.
Conclusión
Hemos explorado los valores SHAP y cómo podemos utilizarlos para proporcionar interpretabilidad a los modelos de machine learning. Aunque disponer de un modelo preciso es esencial, las empresas deben ir más allá de la precisión y centrarse en la interpretabilidad y la transparencia para ganarse la confianza de los usuarios y los reguladores.
Ser capaz de explicar por qué un modelo hizo una predicción concreta ayuda a depurar posibles sesgos, identificar problemas con los datos y justificar las decisiones del modelo.
Si eres nuevo en el machine learning y quieres prepararte para el trabajo, considera la posibilidad de cursar el programa de carrera Científico de machine learning con Python. Este programa te ayudará a dominar los conocimientos de Python necesarios para convertirte en un científico de machine learning y conseguir un empleo.