¿Qué es PandasAI?
PandasAI es una biblioteca de Python que utiliza modelos generativos de IA para potenciar las capacidades de Pandas. Se creó para complementar la biblioteca pandas, una herramienta muy utilizada para el análisis y la manipulación de datos.
Los usuarios pueden resumir los datos de los marcos de datos de pandas utilizando un lenguaje natural. Además, puedes utilizarlo para trazar visualizaciones complejas, manipular marcos de datos y generar perspectivas empresariales.
Imagen de Pandas-AI
PandasAI es fácil de usar para principiantes; incluso una persona con poca formación técnica puede utilizarla para realizar tareas complejas de análisis de datos. Su función es ayudar a analizar los datos más rápidamente y a obtener conclusiones significativas.
Primeros pasos con PandasAI
En esta sección, aprenderemos a instalar y configurar PandasAI para el análisis de datos.
En primer lugar, instalaremos PandasAI mediante pip.
pip install pandasaiInstalación opcional: también podemos instalar la dependencia de Google PaLM utilizando el siguiente código.
pip install pandasai[google]En segundo lugar, necesitamos obtener una clave de la API de OpenAI y almacenarla como variable de entorno siguiendo el tutorial Utilizar GPT-3.5 y GPT-4 mediante la API de OpenAI en Python.
Por último, debemos importar las funciones esenciales, establecer la clave OpenAI en la envoltura de la API LLM e instanciar un objeto PandasAI. Utilizaremos este objeto para ejecutar avisos en uno o varios marcos de datos de pandas.
import os
from pandasai import PandasAI
from pandasai.llm.openai import OpenAI
openai_api_key = os.environ["OPENAI_API_KEY"]
llm = OpenAI(api_token=openai_api_key)
pandas_ai = PandasAI(llm)Además de OpenAI GPT-3.5, puedes utilizar LLM API wrapper para Google PALM (Bison) o incluso modelos de código abierto disponibles en HuggingFace, como Starcoder y Falcon.
from pandasai.llm.starcoder import Starcoder
from pandasai.llm.falcon import Falcon
from pandasai.llm.google_palm import GooglePalm
# GooglePalm
llm = GooglePalm(api_token="YOUR_Google_API_KEY")
# Starcoder
llm = Starcoder(api_token="YOUR_HF_API_KEY")
# Falcon
llm = Falcon(api_token="YOUR_HF_API_KEY")También puedes configurar un archivo .env y evitar configurar api_token. Para ello, tienes que añadir claves API al archivo .env utilizando la siguiente plantilla:
HUGGINGFACE_API_KEY=
OPENAI_API_KEY=
Usos básicos de PandasAI
En este caso de uso básico, cargaremos los datos de películas de Netflix utilizando la biblioteca pandas. El conjunto de datos consta de más de 8500 películas y programas de TV disponibles en Netflix.
import pandas as pd
df = pd.read_csv("netflix_dataset.csv", index_col=0)
df.head(3)
Sigue nuestro tutorial sobre pandas en Python para aprender todo lo que puedes hacer con la biblioteca pandas de Python.
Pasando un marco de datos y un prompt, podemos hacer que PandasAI genere análisis y manipule el conjunto de datos. En nuestro caso, pediremos a PandasAI que muestre los registros de las cinco películas de mayor duración.
pandas_ai.run(df, prompt='What are 5 longest duration movies?')Como vemos, la película de mayor duración es Black Mirror, con 312 minutos.
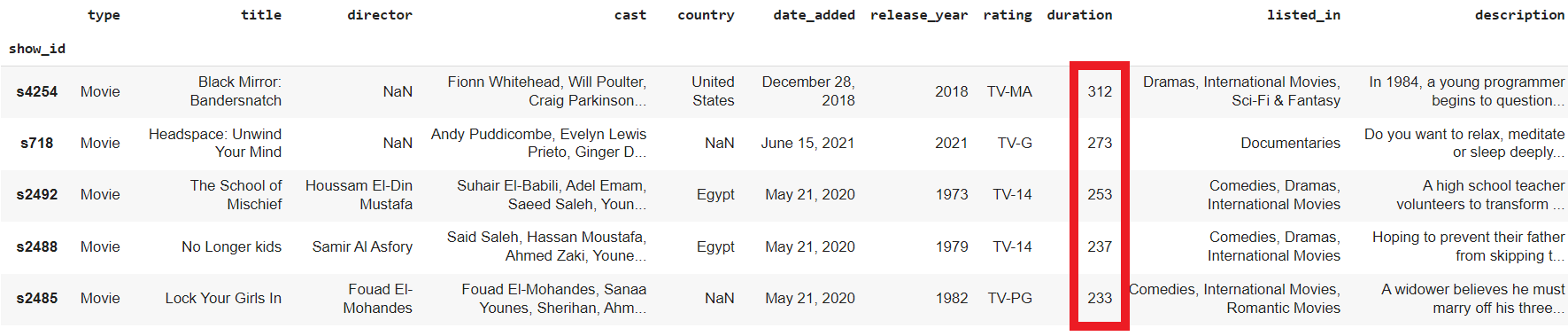
Pidámosle que sólo muestre los nombres de las cinco películas de mayor duración.
pandas_ai.run(df, prompt='List the names of the 5 longest duration movies.')['Black Mirror: Bandersnatch', 'Headspace: Unwind Your Mind', 'The School of Mischief', 'No Longer kids', 'Lock Your Girls In']Nota: si quieres reforzar aún más tu privacidad, puedes instanciar PandasAI con enforce_privacy = True, que no enviará las cabeceras del conjunto de datos (sino sólo los nombres de las columnas) al LLM.
Incluso podemos pedir a PandasAI que realice tareas complejas como agrupar, ordenar y combinar.
pandas_ai.run(df, prompt='What is the average duration of tv shows based on country? Make sure the output is sorted.')country
Denmark, Singapore, Canada, United States 10.0
United States, Mexico, Colombia 7.0
Canada, United States, France 5.5
United Kingdom, Ireland 5.0
Canada, United Kingdom 5.0
...
Spain, Cuba 1.0
Germany, France, Russia 1.0Nota: algunas indicaciones técnicas pueden no funcionar, especialmente cuando le pides que agrupe columnas.
Usos avanzados de PandasAI
Un caso de uso avanzado de PandasAI es la generación de visualizaciones de datos complejas y análisis empresariales utilizando múltiples marcos de datos.
En el primer ejemplo, podríamos escribir un indicador para generar un gráfico de barras que muestre el número de títulos por año, clasificados por tipo.
pandas_ai.run(df, prompt='Plot the bar chart of type of media for each year release, using different colors.')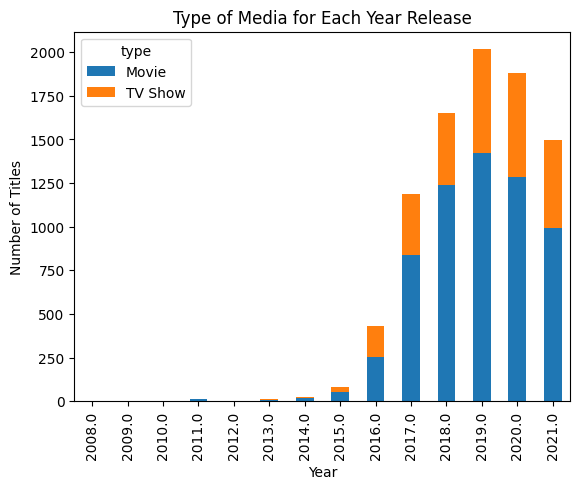
Nota: puedes guardar cualquier gráfico generado por PandasAI estableciendo el parámetro save_charts en True. Por ejemplo, PandasAI(llm, save_charts=True). Los gráficos se guardarán en ./pandasai/exports/charts directory.
En un segundo ejemplo, crearemos tres marcos de datos y utilizaremos los tres marcos de datos para generar análisis con PandasAI.
PandasAI unirá primero df1 con df2 basándose en "store" y df2 con df3 en "location". A continuación, procesará el conjunto de datos combinados y obtendrá un resultado en unos segundos. Un científico de datos habría tardado al menos 10 minutos en comprender los datos e idear una solución.
# DataFrame 1
df1 = pd.DataFrame({
'sales': [100, 200, 300],
'store': ['Walmart', 'Target', 'Walmart']
})
# DataFrame 2
df2 = pd.DataFrame({
'revenue': [400, 500, 600],
'store': ['Walmart', 'Target', 'Walmart'],
'location': ['North', 'South', 'West']})
# DataFrame 3
df3 = pd.DataFrame({
'profit': [700, 800, 900],
'location': ['North', 'South', 'West'],
'employees': [20, 25, 30]})
pandas_ai.run([df1,df2,df3], prompt='How many employees work at Walmart?')50También puedes realizar tareas complejas de análisis de datos siguiendo un curso de Manipulación de datos con pandas.
Interfaz de línea de comandos (CLI) de PandasAI
La interfaz de línea de comandos de PandasAI es una herramienta experimental, y puedes instalarla clonando el repositorio y desplazándote al proyecto directamente.
!git clone https://github.com/gventuri/pandas-ai.git
%cd pandas-aiDespués, utilizaremos poetry para crear y activar un entorno virtual.
!poetry shellNota: si poetry no está instalada en tu sistema, puedes instalarla utilizando curl -sSL https://install.python-poetry.org | python3 -
Utiliza el código siguiente para instalar las dependencias dentro del entorno activado.
!poetry installPor último, abre un terminal y utiliza la herramienta CLI de PandasAI. Debes proporcionar un conjunto de datos, un nombre de modelo y un indicador. Si no se proporciona ningún token, pai recuperará el token del archivo .env.
!pai -d "netflix_dataset.csv" -m "openai" -p "What are 5 longest duration movies?"- -d, --dataset: La ruta del archivo del conjunto de datos.
- -t, --token: Tu token de la API de HuggingFace u OpenAI.
- -m, --model: El modelo LLM a utilizar. Las opciones son:
openai,open-assistant,starcoder, falcon,azure-openai, ogoogle-palm. - -p, --prompt: El prompt para que PandasAI se ejecute.
Lee la documentación de PandasAI para conocer más funciones y características que pueden simplificar tu flujo de trabajo.
Conclusión
PandasAI tiene el potencial de revolucionar el análisis de datos aprovechando modelos de lenguaje de gran tamaño para generar perspectivas a partir de conjuntos de datos.
Mientras que los científicos de datos suelen dedicar mucho tiempo a limpiar, explorar y visualizar los datos, PandasAI automatiza muchas de estas tareas repetitivas.
Sin embargo, como todas las herramientas de IA, PandasAI sigue teniendo limitaciones y no puede sustituir completamente a los humanos. Los resultados analizados suelen requerir una verificación humana para garantizar la precisión e identificar cualquier caso límite.
En este post, aprendimos a instalar, configurar y utilizar PandasAI para el análisis de datos. Utilizamos PandasAI para realizar tareas de análisis de datos, generar visualizaciones de datos y aprovechar múltiples marcos de datos para obtener información empresarial. Si quieres mejorar tus indicaciones para obtener mejores resultados, considera la posibilidad de completar un curso de Introducción a ChatGPT o consultar la Hoja de trucos de ChatGPT para la ciencia de datos.


