Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
100.3K
Durante el último año y medio, el campo del procesamiento del lenguaje natural (PLN) ha experimentado una importante transformación debido a la popularización de los grandes modelos del lenguaje (LLM). Las habilidades de lenguaje natural que presentan estos modelos han permitido aplicaciones que parecían imposibles de conseguir hace unos años.
Los LLM están superando los límites de lo que antes se consideraba alcanzable, con capacidades que van desde la traducción de idiomas al análisis de sentimientos y la generación de textos.
Sin embargo, todos sabemos que entrenar esos modelos lleva mucho tiempo y es caro. Por eso, el ajuste preciso de los grandes modelos lingüísticos es importante para adaptar estos algoritmos avanzados a tareas o dominios específicos.
Este proceso mejora el rendimiento del modelo en tareas especializadas y amplía significativamente su aplicabilidad en diversos campos. Esto significa que podemos aprovechar la capacidad de procesamiento del lenguaje natural de los LLM preentrenados y de código abierto y entrenarlos aún más para que realicen nuestras tareas específicas.
Hoy, explora la esencia de los modelos lingüísticos preentrenados y profundiza en el proceso de ajuste preciso.
Así pues, vamos a navegar por los pasos prácticos para afinar con precisión un modelo como el GPT-2 utilizando Hugging Face.
El modelo lingüístico es un tipo de algoritmo de machine learning diseñado para predecir la palabra siguiente de una frase, a partir de sus segmentos anteriores. Se basa en la arquitectura Transformers, que se explica en profundidad en nuestro artículo sobre Cómo funcionan los Transformers.
Los modelos lingüísticos preentrenados, como el GPT (Generative Pre-trained Transformer), se entrenan con grandes cantidades de datos de texto. Esto permite a los LLM comprender los principios fundamentales que rigen el uso de las palabras y su disposición en el lenguaje natural.

Imagen del autor. Entrada y salida del LLM.
Lo más importante es que estos modelos no solo son buenos comprendiendo el lenguaje natural, sino que también son buenos generando texto similar al humano a partir de la información que reciben.
¿Y lo mejor de todo?
Estos modelos ya están abiertos a las masas mediante API. Si quieres aprender a aprovechar las LLM más potentes de OpenAI, puedes aprender a hacerlo siguiendo esta hoja de trucos sobre la API de OpenAI.
El ajuste preciso es el proceso de tomar un modelo preentrenado y seguir entrenándolo en un conjunto de datos específicos del dominio.
La mayoría de los modelos LLM actuales tienen un rendimiento global muy bueno, pero fallan en problemas específicos orientados a tareas concretas. El proceso de ajuste preciso ofrece ventajas considerables, como la reducción de los gastos de cálculo y la posibilidad de aprovechar modelos de vanguardia sin necesidad de construir uno desde cero.
Los transformadores dan acceso a una amplia colección de modelos preentrenados adecuados para diversas tareas. El ajuste preciso de estos modelos es un paso crucial para mejorar la capacidad del modelo de realizar tareas específicas, como el análisis del sentimiento, la respuesta a preguntas o el resumen de documentos, con mayor precisión.
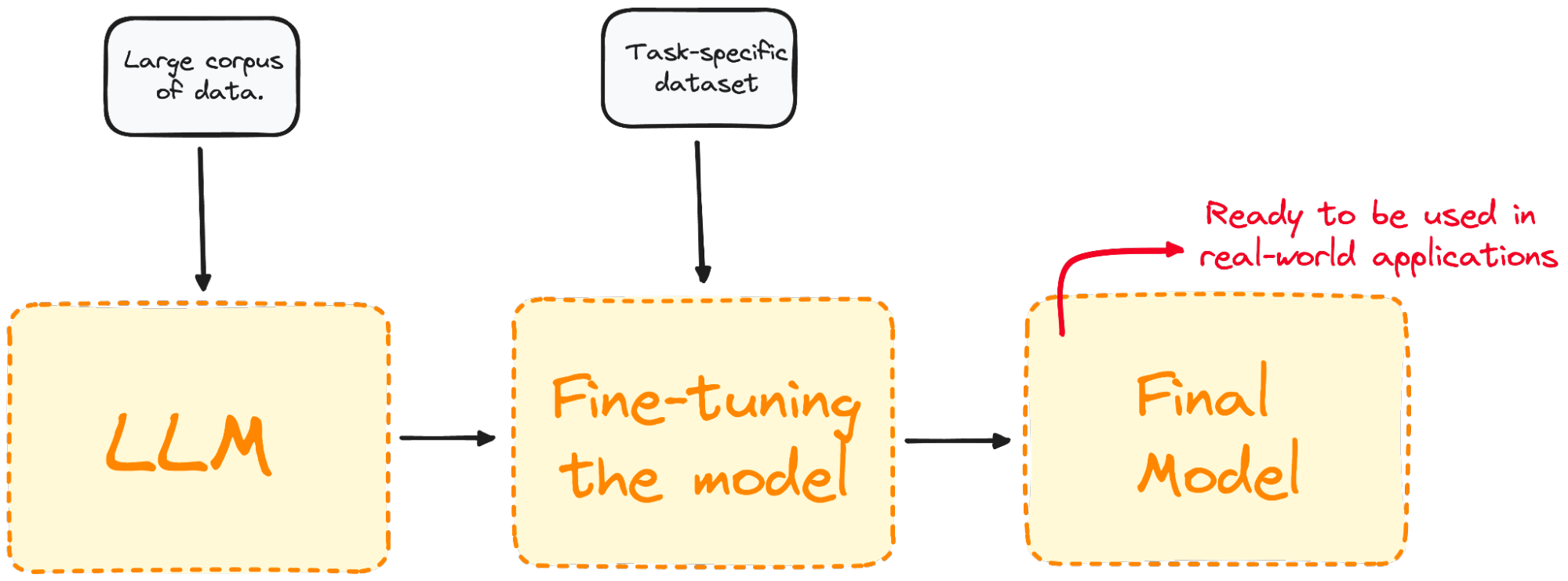
Imagen del autor. Visualizar el proceso de ajuste preciso.
El ajuste preciso adapta el modelo para que tenga un mejor rendimiento en tareas específicas, haciendo más eficaz y versátil en aplicaciones del mundo real. Este proceso es esencial para adaptar un modelo existente a una tarea o dominio concretos.
La decisión de realizar un ajuste preciso depende de tus objetivos, que suelen variar en función del ámbito o la tarea específicos.
El ajuste preciso puede enfocarse de varias formas, en función principalmente de su enfoque principal y de sus objetivos específicos.
El enfoque de ajuste más sencillo y habitual. Además, el modelo se entrena en un conjunto de datos etiquetados específicos de la tarea que se va a realizar, como la clasificación de textos o el reconocimiento de entidades con nombre.
Por ejemplo, entrenaríamos nuestro modelo en un conjunto de datos que contiene muestras de texto etiquetadas con su correspondiente sentimiento para el análisis del sentimiento.
En algunos casos, recopilar un gran conjunto de datos etiquetados no resulta práctico. El aprendizaje con pocas tomas intenta solucionar esto proporcionando unos cuantos ejemplos (o tomas) de la tarea requerida al principio de las indicaciones de entrada. Esto ayuda a que el modelo tenga un mejor contexto de la tarea sin un extenso proceso de ajuste preciso.
Aunque todas las técnicas de ajuste preciso son una forma de aprendizaje por transferencia, esta categoría tiene como objetivo específico permitir que un modelo realice una tarea distinta de la tarea en la que fue entrenado inicialmente. La idea principal es aprovechar el conocimiento que el modelo ha obtenido de un gran conjunto de datos generales y aplicarlo a una tarea más específica o relacionada.
Este tipo de ajuste intenta adaptar el modelo para que comprenda y genere texto específico de un dominio o sector concreto. El modelo se pone a punto en un conjunto de datos compuesto por texto del dominio de destino para mejorar su contexto y su conocimiento de las tareas específicas del dominio.
Por ejemplo, para generar un chatbot para una aplicación médica, el modelo se entrenaría con historiales médicos, para adaptar sus capacidades de comprensión del lenguaje al ámbito sanitario.
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoYa sabemos que el ajuste preciso es el proceso de tomar un modelo preentrenado y actualizar sus parámetros entrenándolo en un conjunto de datos específico para tu tarea. Así pues, ejemplifiquemos este concepto ajustando un modelo real.
Imagina que estamos trabajando con GPT-2, pero detectamos que es bastante malo a la hora de inferir los sentimientos de los tuits.
Una pregunta natural que me viene a la mente es: ¿podemos hacer algo para mejorar su rendimiento?
Podemos aprovechar el ajuste entrenando nuestro modelo GPT-2 preentrenado a partir del modelo Hugging Face con un conjunto de datos que contenga tuits y sus correspondientes sentimientos, de modo que mejore el rendimiento. He aquí un ejemplo básico de ajuste preciso de un modelo de clasificación de secuencias:
Para afinar un modelo, siempre necesitamos tener en mente un modelo preentrenado. En nuestro caso, vamos a realizar algunos ajustes precisos sencillos utilizando GPT-2.
Captura de pantalla de Hugging Face Datasets Hub. Se selecciona el modelo GPT2 de OpenAI.
Ten siempre presente seleccionar un modelo de arquitectura adecuado a tu tarea.
Ahora que tenemos nuestro modelo, necesitamos datos de buena calidad con los que trabajar, y aquí es precisamente donde entra en juego la biblioteca datasets.
En mi caso, utilizaré la biblioteca de conjuntos de datos Hugging Face para importar un conjunto de datos que contenga tuits segmentados por su sentimiento (positivo, neutral o negativo).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
Si comprobamos el conjunto de datos que acabamos de descargar, se trata de un conjunto de datos que contiene un subconjunto para entrenamiento y otro para pruebas. Si convertimos el subconjunto de entrenamiento en un marco de datos, tiene el siguiente aspecto.

El conjunto de datos que se va a utilizar.
Ahora que ya tenemos nuestro conjunto de datos, necesitamos un tokenizador que lo prepare para que lo analice nuestro modelo.
Como los LLM trabajan con tokens, necesitamos un tokenizador para procesar el conjunto de datos. Para procesar tu conjunto de datos en un solo paso, utiliza el método de mapa de conjuntos de datos para aplicar una función de preprocesamiento sobre todo el conjunto de datos.
Por eso, el segundo paso consiste en cargar un Tokenizer preentrenado y tokenizar nuestro conjunto de datos para poder utilizarlo en el ajuste preciso.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)CONSEJO EXTRA: Para mejorar nuestros requisitos de procesamiento, podemos crear un subconjunto más pequeño del conjunto de datos completo para afinar nuestro modelo. El conjunto de entrenamiento se utilizará para realizar un ajuste preciso nuestro modelo, mientras que el conjunto de pruebas se utilizará para evaluarlo.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Empieza cargando tu modelo y especifica el número de etiquetas previstas. Por la ficha del conjunto de datos de sentimiento del tuit, sabes que hay tres etiquetas:
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Transformers proporciona una clase de entrenador optimizada para el entrenamiento. Sin embargo, este método no incluye cómo evaluar el modelo. Por eso, antes de empezar nuestro entrenamiento, tendremos que pasar a un entrenador una función para evaluar el rendimiento de nuestro modelo.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Nuestro último paso es configurar los argumentos de entrenamiento e iniciar el proceso de entrenamiento. La biblioteca de transformadores contiene la clase entrenador, que admite una amplia gama de opciones y funciones de entrenamiento, como el registro, la acumulación de gradientes y la precisión mixta. Primero definimos los argumentos de entrenamiento junto con la estrategia de evaluación. Una vez definido todo, podemos entrenar fácilmente el modelo utilizando simplemente el comando train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Tras el entrenamiento, evalúa el rendimiento del modelo en un conjunto de validación o prueba. De nuevo, la clase Entrenador ya contiene un método de evaluación que se encarga de esto.
import evaluate
trainer.evaluate()
Estos son los pasos más básicos para realizar un ajuste preciso de cualquier LLM. Recuerda que afinar un LLM es muy exigente desde el punto de vista computacional, y puede que tu ordenador local no tenga potencia suficiente para hacerlo.
Puedes aprender a afinar LLM más potentes directamente en la interfaz de OpenAI siguiendo este tutorial sobre Cómo ajustar con precisión GPT 3.5.
¡Comienza hoy tu viaje por la IA!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Stanislav Karzhev
12 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Moez Ali


