Curso
Comprender ChatGPT
1 h
424.4K
Imagina que has pasado horas escribiendo un contenido.
Estás satisfecho con el producto final y lo pones a disposición del público.
Al cabo de un tiempo de ser de dominio público, te das cuenta de que estás rechazando a un público enorme, ya que mucha gente no cree tener tiempo para sentarse a leer tu obra.
Te planteas narrar tú mismo el contenido, pero el tiempo no está de tu parte. Coqueteas con la idea de contratar a un narrador, pero los presupuestos que has ido recibiendo se salen de tu presupuesto, y el tiempo que se tarda en encontrar a alguien con la voz "adecuada" también es una carga.
A la manera típica del siglo XXI, buscas una solución en la tecnología. Es entonces cuando conoces la API de texto a voz (TTS) de OpenAI.
Durante el resto de este tutorial, cubriremos la API TTS de OpenAI, es decir, sus características clave, cómo empezar, personalización y casos de uso en el mundo real.
La conversión de texto a voz (TTS) es un tipo de tecnología de apoyo que convierte el lenguaje natural, en formato de texto, en voz. Es decir, los sistemas de conversión de texto a voz toman palabras escritas en un ordenador (o cualquier otro dispositivo digital) y leen el texto en voz alta.
La API TTS de OpenAI es un punto final que permite a los usuarios interactuar con su modelo de inteligencia artificial TTS, que convierte el texto en lenguaje hablado con sonido natural. El modelo tiene dos variantes:
El endpoint viene preconfigurado con seis voces y, según la documentación de OpenAI TTS, puede utilizarse para:
Sin embargo, es importante tener en cuenta que las políticas de uso de OpenAI exigen que se informe claramente a los usuarios finales de que la voz TTS que oyen está generada por IA y no es una voz humana.
Veamos cómo puedes empezar a utilizar la API de texto a voz de OpenAI, cubriendo los requisitos previos y los pasos que debes seguir:
Una vez que hayas iniciado sesión en tu cuenta de OpenAI, accederás a la pantalla de inicio. Desde aquí, desplázate hasta el logotipo de OpenAI en la esquina superior izquierda de la página para activar la barra lateral.
Seleccione "Claves API".
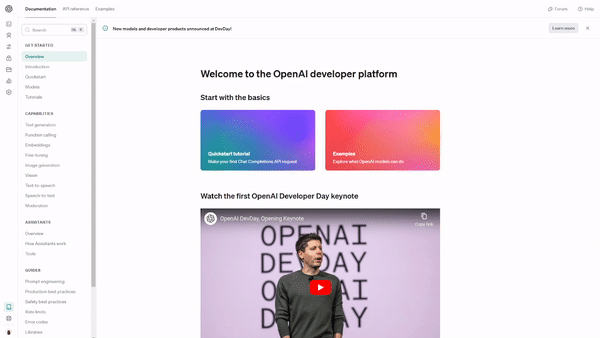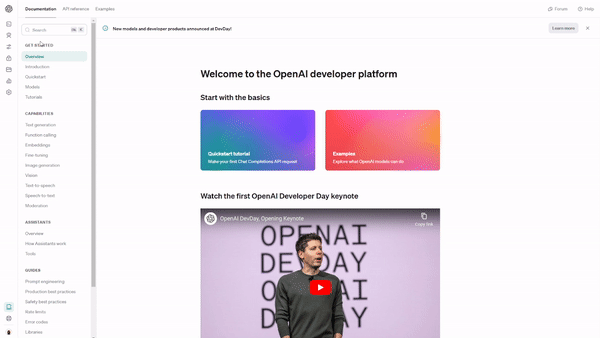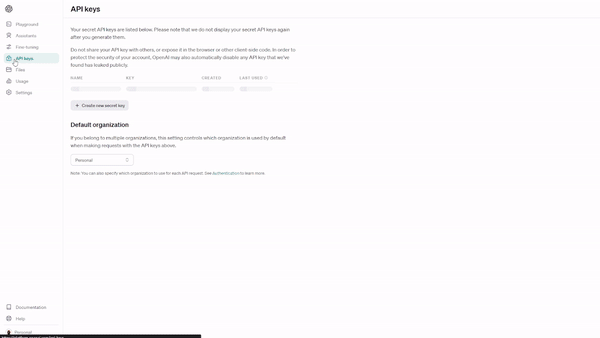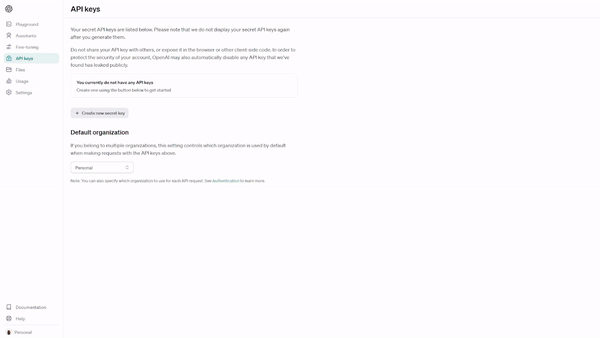
Selecciona "Crear nueva clave secreta" y dale un nombre a tu clave API: nosotros hemos llamado a la nuestra "tts-example".
Cuando cree su clave API, se generará una clave secreta. Asegúrese de guardar la llave en un lugar seguro.
Ahora que ya tienes la llave, ¡estás listo para empezar!
Un Entorno Virtual se utiliza para crear un contenedor o entorno aislado donde se instalan las dependencias relacionadas con Python para un proyecto específico. Se puede trabajar con muchas versiones diferentes de Python con sus distintos paquetes.
Profundizar en los entornos virtuales queda fuera del alcance de este artículo. Consulta el tutorial Entorno virtual en Python para aprender más sobre cómo crear uno.
Hay tres entradas clave que toma el terminal de voz:
En la documentación de texto a voz de OpenAI hay un ejemplo de solicitud; así no tenemos que reinventar la rueda.
He aquí un ejemplo de solicitud:
from pathlib import Path
from openai import OpenAI
client = OpenAI()
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Tal y como están las cosas, el código no se ejecutará.
La razón por la que no se ejecuta es que no hemos pasado la clave API que generamos en el paso uno a nuestro cliente OpenAI...
La forma más sencilla de resolver este problema es añadir un parámetro api_key donde podemos pasar nuestra clave secreta al objeto OpenAI().
Por ejemplo:
client = OpenAI(api_key="secret key goes here") Hacer esto es una mala práctica en Python.
En su lugar, utilizaremos dotenv para leer la clave secreta de un archivo .env.
Lo primero que debe hacer es instalar dotenv en su entorno virtual. Ejecute este comando desde su entorno virtual:
pip install python-dotenvAhora que dotenv está instalado, podemos crear un archivo .env, que contiene pares clave-valor, y establecer los valores como variables de entorno.
Esto nos permite ocultar nuestra clave secreta, incluso si el código se comparte públicamente.
Lo primero es lo primero, debemos crear un archivo .env e insertar lo siguiente:
SECRET_KEY = "insert your secret key token here" En nuestro archivo main.py, ahora podemos llamar a nuestras variables de entorno utilizando dotenv.
Este es el aspecto del código.
import os
from pathlib import Path
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
SECRET_KEY = os.getenv("SECRET_KEY")
client = OpenAI(api_key=SECRET_KEY)
speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(
model="tts-1",
voice="alloy",
input="Today is a wonderful day to build something people love!"
)
response.stream_to_file(speech_file_path)Ahora el código se ejecuta.
El comportamiento por defecto del código es emitir un archivo MP3 del audio hablado. Si prefiere otro formato de archivo, puede configurar la salida en cualquiera de los formatos admitidos.
Hay montones de voces y acentos diferentes en el mundo.
Aunque sea imposible captar todas y cada una de ellas, el TTS de OpenAI ha intentado reflejar la diversidad del mundo en que vivimos integrando en la API seis voces únicas incorporadas:
Estos pueden transmitir diferentes personalidades, o puede utilizarlos según sus preferencias. Todo lo que tienes que hacer es establecer el voice que deseas utilizar utilizando el parámetro de voz en el objeto cliente.
response = client.audio.speech.create(
model="tts-1",
voice="alloy", # Update this to change voice
input="Today is a wonderful day to build something people love!"
)Consulta la documentación de la API de texto a voz de OpenAI para obtener más información sobre las voces disponibles.
También puedes modificar el formato de salida.
La respuesta por defecto de la API es un archivo MP3 con el texto convertido. Sin embargo, OpenAI ofrece otros formatos para satisfacer sus necesidades y preferencias. Como por ejemplo:
TLDR: el tipo de salida que elijas puede influir en la calidad del audio, el tamaño del archivo y su compatibilidad con distintos dispositivos y aplicaciones.
En cuanto a la compatibilidad lingüística, el modelo de conversión de texto a voz sigue el modelo Whisper utilizado para la conversión de voz a texto; las voces están optimizadas para el inglés, pero son compatibles con otros idiomas.
Ahora que ya sabemos cómo configurar la API TTS, veamos algunos ejemplos de cómo utilizarla.
Supongamos que has escrito un libro o una entrada de blog y quieres ampliar su alcance a un público más amplio convirtiéndolo a audio. Si lo hicieras a la antigua usanza, tendrías que encontrar un narrador (o narrarlo tú mismo), lo que puede ser un proceso largo.
La API OpenAI TTS puede utilizarse para acortar este proceso; todo lo que hay que hacer es pasar el documento de texto a la API, y ésta lo convertirá en voz.
En lugar de impartir clases en grupo, los profesores de idiomas pueden utilizar la API de conversión de texto a voz de OpenAI para crear lecciones personalizadas para alumnos que utilicen varios idiomas y dialectos. A pesar de que las voces están optimizadas para el inglés, la API puede utilizarse para generar contenidos de audio en varios idiomas.
La API OpenAI TTS puede utilizarse para crear voces de IA que suenen más realistas y expresivas que los sistemas TTS tradicionales. Los desarrolladores de videojuegos pueden aprovechar esta capacidad y aplicarla a los personajes para que la experiencia sea más envolvente para los jugadores.
Otro caso de uso puede ser la creación de asistentes virtuales y chatbots más atractivos que los tradicionales existentes.
Los límites de velocidad de la API TTS de OpenAI comienzan en 50 solicitudes por minuto (RPM) para las cuentas de pago, y el tamaño máximo de entrada es de 4096 caracteres, lo que equivale a aproximadamente 5 minutos de audio a la velocidad predeterminada.
En cuanto a los modelos TTS, los precios son los siguientes:
Si buscas una forma rentable de integrar la API TTS en un proyecto pequeño, quizá sea mejor que optes por el modelo TTS estándar. El modelo TTS HD es un poco más caro, pero ofrece audio de alta definición, lo que resulta ideal cuando la calidad del audio es primordial. Obtenga más información sobre los precios de los modelos de audio de OpenAI.
La API de conversión de texto a voz de OpenAI es un punto final para que los usuarios generen audio hablado de alta calidad a partir de texto. Viene con seis voces incorporadas, y los usuarios pueden seleccionar uno de los dos modelos, TTS-1 y TTS-1-HD, en función de su caso de uso; el modelo TTS-1 está optimizado para la conversión de texto a voz en tiempo real, mientras que el TTS-1-HD está optimizado para la calidad.
En esta entrada del blog, hemos cubierto:
Echa un vistazo a estos interesantes recursos para seguir aprendiendo:
Comience hoy mismo su viaje a la IA
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Adel Nehme
Tutorial
Moez Ali