Python for Spreadsheet Users
BeginnerSkill Level
4 h
29.1K learners
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoInstalar pandas es sencillo; sólo tienes que utilizar el comando pip install en tu terminal.
pip install pandasTambién puedes instalarlo a través de conda:
conda install pandasDespués de instalar pandas, es una buena práctica comprobar la versión instalada para asegurarse de que todo funciona correctamente:
import pandas as pd
print(pd.__version__) # Prints the pandas versionEsto confirma que pandas está instalado correctamente y te permite verificar la compatibilidad con otros paquetes.
Para empezar a trabajar con pandas, importa el paquete pandas Python como se muestra a continuación. Al importar pandas, el alias más común para pandas es pd.
import pandas as pdUtiliza read_csv() con la ruta al archivo CSV para leer un archivo de valores separados por comas (para más detalles, consulta nuestro tutorial sobre la importación de datos con read_csv() ).
df = pd.read_csv("diabetes.csv")Esta operación de lectura carga el archivo CSV diabetes.csv para generar un objeto pandas Dataframe df. A lo largo de este tutorial, verás cómo manipular dichos objetos DataFrame.
La lectura de archivos de texto es similar a la de archivos CSV. El único matiz es que debes especificar un separador con el argumento sep, como se muestra a continuación. El argumento separador se refiere al símbolo utilizado para separar filas en un Marco de datos. La coma (sep = ","), el espacio en blanco (sep = "\s"), el tabulador (sep = "\t") y los dos puntos (sep = ":") son los separadores más utilizados. Aquí \s representa un único carácter de espacio en blanco.
df = pd.read_csv("diabetes.txt", sep="\s")Leer archivos excel (tanto XLS como XLSX) es tan fácil como utilizar la función read_excel(), utilizando la ruta del archivo como entrada.
df = pd.read_excel('diabetes.xlsx')También puedes especificar otros argumentos, como header para especificar qué fila se convierte en la cabecera del DataFrame. Tiene un valor por defecto de 0, que denota la primera fila como cabecera o nombre de columna. También puedes especificar los nombres de las columnas como una lista en el argumento names. El argumento index_col (por defecto es None) puede utilizarse si el archivo contiene un índice de filas.
Nota: En un DataFrame o Serie de pandas, el índice es un identificador que señala la ubicación de una fila o columna en un DataFrame de pandas. En pocas palabras, el índice etiqueta la fila o columna de un Marco de datos y te permite acceder a una fila o columna concreta utilizando su índice (lo verás más adelante). El índice de fila de un DataFrame puede ser un rango (por ejemplo, de 0 a 303), una serie temporal (fechas o marcas de tiempo), un identificador único (por ejemplo, employee_ID en una tablaemployees ) u otros tipos de datos. Para las columnas, suele ser una cadena (que denota el nombre de la columna).
Leer archivos Excel con varias hojas no es tan diferente. Sólo tienes que especificar un argumento adicional, sheet_name, en el que puedes pasar una cadena para el nombre de la hoja o un número entero para la posición de la hoja (ten en cuenta que Python utiliza la indexación 0, en la que se puede acceder a la primera hoja con sheet_name = 0).
# Extracting the second sheet since Python uses 0-indexing
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)De forma similar a la función read_csv(), puedes utilizar read_json() para tipos de archivo JSON con el nombre del archivo JSON como argumento (para más detalles, lee este tutorial sobre la importación de datos JSON y HTML en pandas). El código siguiente lee un archivo JSON del disco y crea un objeto DataFrame df.
df = pd.read_json("diabetes.json")Si quieres saber más sobre la importación de datos con pandas, consulta esta hoja de trucos sobre la importación de varios tipos de archivos con Python.
Para cargar datos de una base de datos relacional, utiliza pd.read_sql() junto con una conexión a la base de datos.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Para grandes conjuntos de datos, considera la posibilidad de utilizar SQLAlchemy para optimizar las consultas.
Si tus datos proceden de una API web, pandas puede leerlos directamente utilizando pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Si la respuesta de la API está paginada, o en un formato JSON anidado, puede que necesites un procesamiento adicional utilizando json_normalize() de pandas.io.json.
Al igual que pandas puede importar datos de varios tipos de archivos, también te permite exportar datos a varios formatos. Esto ocurre especialmente cuando los datos se transforman utilizando pandas y necesitan guardarse localmente en tu máquina. A continuación se explica cómo convertir los DataFrames de pandas a varios formatos.
Un DataFrame de pandas (aquí estamos utilizando df) se guarda como un archivo CSV utilizando el método .to_csv(). Los argumentos incluyen el nombre del archivo con la ruta y index - donde index = True implica escribir el índice del DataFrame.
df.to_csv("diabetes_out.csv", index=False)Exporta el objeto DataFrame a un archivo JSON llamando al método .to_json().
df.to_json("diabetes_out.json")Nota: Un archivo JSON almacena un objeto tabular como un DataFrame en forma de par clave-valor. De este modo, observarías cabeceras de columna repetidas en un archivo JSON.
Al igual que al escribir DataFrames en archivos CSV, puedes llamar a .to_csv(). Las únicas diferencias son que el formato del archivo de salida está en .txt, y que necesitas especificar un separador utilizando el argumento sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Llama a .to_excel() desde el objeto DataFrame para guardarlo como un archivo “.xls” o “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Después de leer los datos tabulares como un DataFrame, necesitarás echar un vistazo a los datos. Puedes ver una pequeña muestra del conjunto de datos o un resumen de los datos en forma de estadísticas resumidas.
.head() y .tail()Puedes ver las primeras o las últimas filas de un Marco de Datos utilizando los métodos .head() o .tail(), respectivamente. Puedes especificar el número de filas mediante el argumento n (el valor por defecto es 5).
df.head()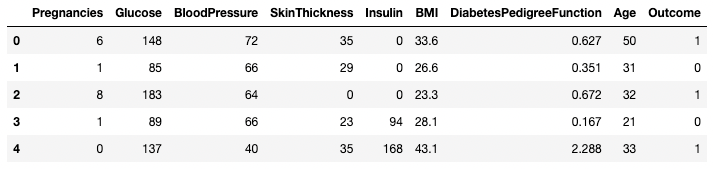
Cinco primeras filas del DataFrame
df.tail(n = 10)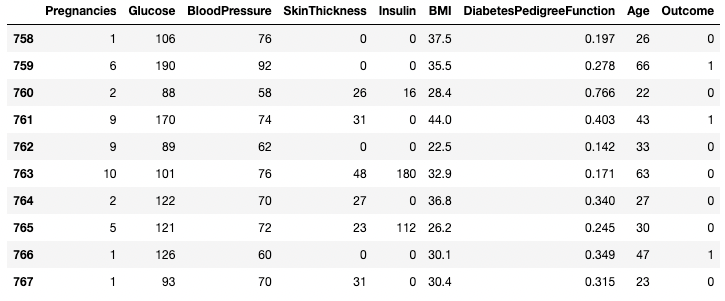
Primeras 10 filas del DataFrame
.describe()El método .describe() imprime los estadísticos de resumen de todas las columnas numéricas, como el recuento, la media, la desviación típica, el rango y los cuartiles de las columnas numéricas.
df.describe()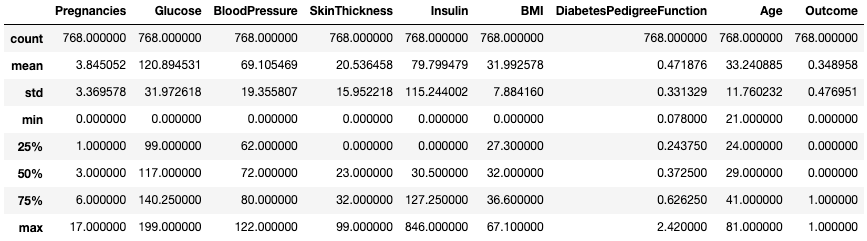
Obtén estadísticas resumidas con .describe()
Da un vistazo rápido a la escala, la inclinación y el rango de los datos numéricos.
También puedes modificar los cuartiles utilizando el argumento percentiles. Aquí, por ejemplo, estamos viendo los percentiles 30%, 50% y 70% de las columnas numéricas del DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])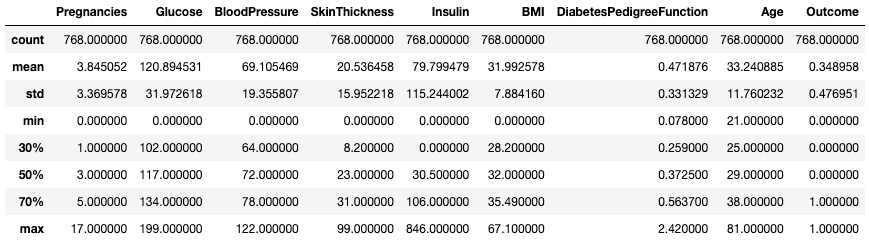
Obtener estadísticas resumidas con percentiles específicos
También puedes aislar tipos de datos específicos en tu salida resumida utilizando el argumento include. Aquí, por ejemplo, sólo estamos resumiendo las columnas con el tipo de datos integer.
df.describe(include=[int])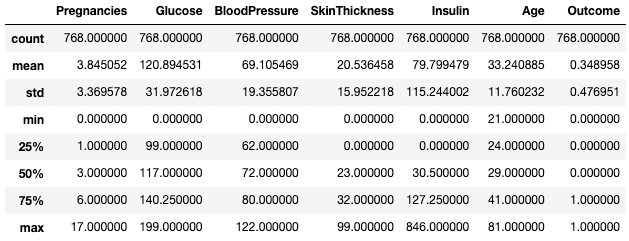
Obtener estadísticas resumidas sólo de columnas enteras
Del mismo modo, puede que quieras excluir determinados tipos de datos utilizando el argumento exclude.
df.describe(exclude=[int])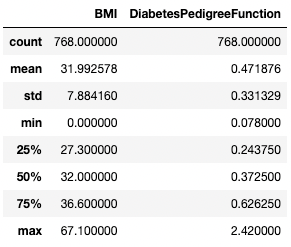
Obtener estadísticas de resumen sólo de columnas no enteras
A menudo, a los profesionales les resulta fácil ver estas estadísticas transponiéndolas con el atributo .T.
df.describe().T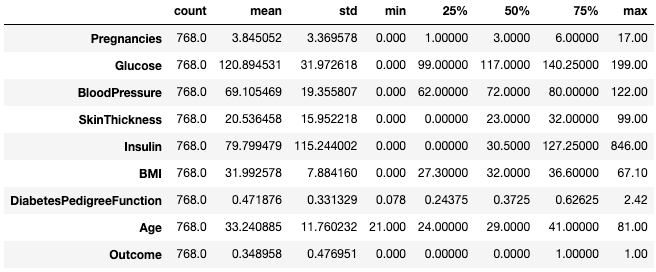
Transponer las estadísticas resumidas con .T
Para saber más sobre la descripción de los DataFrames, consulta la siguiente hoja de trucos.
.info()El método .info() es una forma rápida de ver los tipos de datos, los valores perdidos y el tamaño de los datos de un Marco de Datos. Aquí, estamos fijando el argumento show_counts en True, que da unos cuantos sobre el total de valores no ausentes en cada columna. También establecemos memory_usage a True, que muestra el uso total de memoria de los elementos del DataFrame. Cuando verbose se establece en True, imprime el resumen completo de .info().
df.info(show_counts=True, memory_usage=True, verbose=True)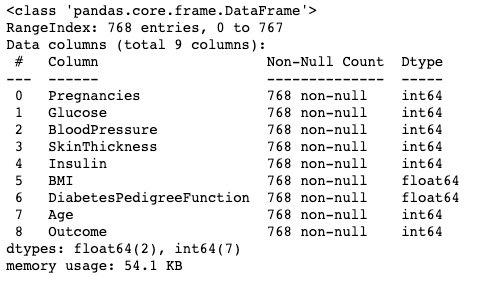
.shapeEl número de filas y columnas de un Marco de datos puede identificarse mediante el atributo .shape del Marco de datos. Devuelve una tupla (fila, columna) y puede indexarse para obtener sólo filas, y sólo las columnas cuentan como salida.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9La llamada al atributo .columns de un objeto DataFrame devuelve los nombres de las columnas en forma de objeto Index. Como recordatorio, un índice pandas es la dirección/etiqueta de la fila o columna.
df.columns
Se puede convertir en una lista utilizando una función list().
list(df.columns)
.isnull()El DataFrame de muestra no tiene valores perdidos. Introduzcamos algunos para hacer las cosas interesantes. El método .copy() hace una copia del DataFrame original. Esto se hace para garantizar que cualquier cambio en la copia no se refleje en el DataFrame original. Utilizando .loc (que veremos más adelante), puedes establecer las filas dos a cinco de la columna Pregnancies en valores NaN, que denotan valores omitidos.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)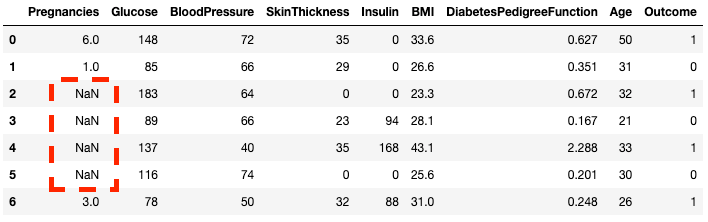
Puedes ver que ahora las filas 2 a 5 son NaN
Puedes comprobar si falta algún elemento de un Marco de datos utilizando el método .isnull().
df2.isnull().head(7)Dado que a menudo es más útil saber cuántos datos faltan, puedes combinar .isnull() con .sum() para contar el número de nulos de cada columna.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64También puedes hacer una suma doble para obtener el número total de nulos del DataFrame.
df2.isnull().sum().sum()4El paquete pandas ofrece varias formas de ordenar, subconjuntar, filtrar y aislar datos en tus DataFrames. Aquí veremos las formas más comunes.
Para ordenar un DataFrame por una columna concreta:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderPuedes ordenar por varias columnas:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Si filtras u ordenas un Marco de datos, tu índice podría desalinearse. Utiliza .reset_index() para solucionarlo:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnPara extraer datos en función de una condición:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100[ ] Puedes aislar una sola columna utilizando un corchete [ ] con el nombre de la columna dentro. La salida es un objeto pandas Series. Una Serie pandas es una matriz unidimensional que contiene datos de cualquier tipo, incluidos enteros, flotantes, cadenas, booleanos, objetos python, etc. Un DataFrame se compone de muchas series que actúan como columnas.
df['Outcome']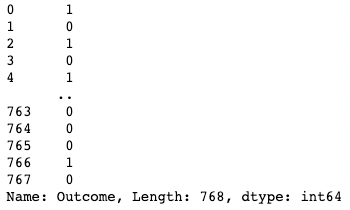
Aislar una columna en pandas
[[ ]] También puedes proporcionar una lista de nombres de columnas dentro de los corchetes para obtener más de una columna. Aquí, los corchetes se utilizan de dos formas distintas. Utilizamos los corchetes exteriores para indicar un subconjunto de un Marco de datos, y los corchetes interiores para crear una lista.
df[['Pregnancies', 'Outcome']]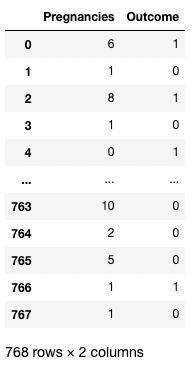
Aislar dos columnas en pandas
[ ] Se puede obtener una sola fila pasando una serie booleana con un valor True. En el ejemplo siguiente, se devuelve la segunda fila con index = 1. Aquí, .index devuelve las etiquetas de fila del DataFrame, y la comparación lo convierte en una matriz unidimensional booleana.
df[df.index==1]
Aislar una fila en pandas
[ ] Del mismo modo, se pueden devolver dos o más filas utilizando el método .isin() en lugar de un operador ==.
df[df.index.isin(range(2,10))]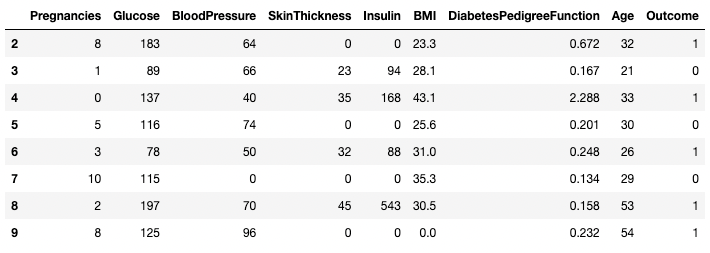
Aislar filas específicas en pandas
.loc[] y .iloc[] para recuperar filasPuedes obtener filas concretas por etiquetas o condiciones utilizando .loc[] y .iloc[] ("ubicación" y "posición numérica"). .loc[] utiliza una etiqueta para señalar una fila, columna o celda, mientras que .iloc[] utiliza la posición numérica. Para entender la diferencia entre ambos, vamos a modificar el índice de df2 creado anteriormente.
df2.index = range(1,769)El siguiente ejemplo devuelve un pandas Series en lugar de un DataFrame. El 1 representa el índice de la fila (etiqueta), mientras que el 1 en .iloc[] es la posición de la fila (primera fila).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64También puedes obtener varias filas indicando un rango entre corchetes.
df2.loc[100:110]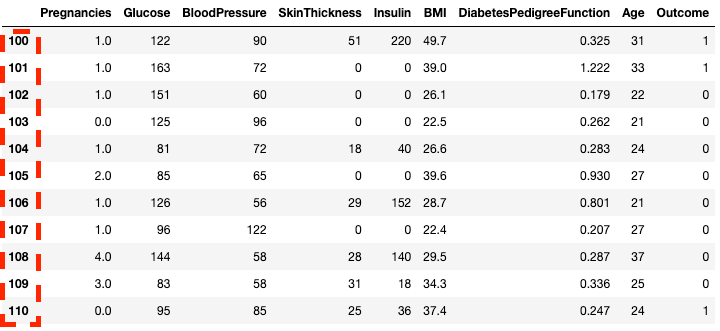
Aislar filas en pandas con .loc[]
df2.iloc[100:110]![Aislar filas en pandas con .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Aislar filas en pandas con .iloc[]
También puedes subconjuntar con .loc[] y .iloc[] utilizando una lista en lugar de un rango.
df2.loc[[100, 200, 300]]![Aislar filas utilizando una lista en pandas con .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Aislar filas utilizando una lista en pandas con .loc[]
df2.iloc[[100, 200, 300]]
Aislar filas utilizando una lista en pandas con .iloc[]
También puedes seleccionar columnas concretas junto con las filas. Aquí es donde .iloc[] es diferente de .loc[]: requiere la ubicación de las columnas y no las etiquetas de las columnas.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Aislar columnas utilizando una lista en pandas con .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Aislar columnas en pandas con .loc[]
df2.iloc[100:110, :3]![Aislar columnas utilizando en pandas con .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Aislar columnas con .iloc[]
Para flujos de trabajo más rápidos, puedes pasar el índice inicial de una fila como rango.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Aislar columnas utilizando en pandas con .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Aislar columnas y filas en pandas con .loc[]
df2.iloc[760:, :3]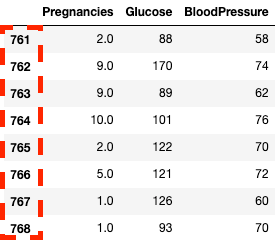
Aislar columnas y filas en pandas con .iloc[]
Puedes actualizar/modificar determinados valores utilizando el operador de asignación =
df2.loc[df['Age']==81, ['Age']] = 80pandas te permite filtrar datos mediante condiciones sobre valores de fila/columna. Por ejemplo, el código siguiente selecciona la fila en la que la Tensión Arterial es exactamente 122. Aquí, estamos aislando filas utilizando los corchetes [ ] como se ha visto en secciones anteriores. Sin embargo, en lugar de introducir índices de fila o nombres de columna, estamos introduciendo una condición en la que la columna BloodPressure es igual a 122. Denotamos esta condición mediante df.BloodPressure == 122.
df[df.BloodPressure == 122]
Aislar filas basándose en una condición en pandas
El siguiente ejemplo obtiene todas las filas en las que Outcome es 1. Aquí df.Outcome selecciona esa columna, df.Outcome == 1 devuelve una Serie de valores booleanos determinando cuáles Outcomes son iguales a 1, luego [] toma un subconjunto de df donde esa Serie booleana es True.
df[df.Outcome == 1]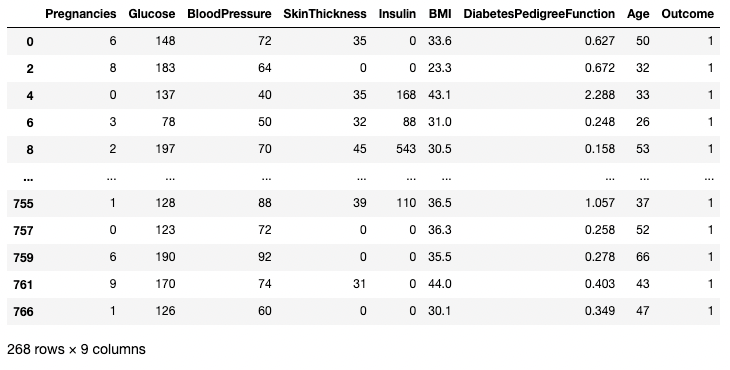
Aislar filas basándose en una condición en pandas
Puedes utilizar un operador > para establecer comparaciones. El código siguiente busca Pregnancies, Glucose, y BloodPressure para todos los registros con BloodPressure mayor que 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]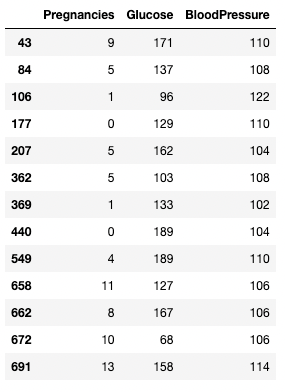
Aislar filas y columnas en función de una condición en pandas
La limpieza de datos es una de las tareas más comunes en la ciencia de datos. pandas te permite preprocesar datos para cualquier uso, incluido, entre otros, el entrenamiento de modelos de aprendizaje automático y aprendizaje profundo. Utilicemos el DataFrame df2 de antes, que tiene cuatro valores perdidos, para ilustrar algunos casos de uso de la limpieza de datos. A modo de recordatorio, he aquí cómo puedes ver cuántos valores perdidos hay en un Marco de datos.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Una forma de tratar los datos que faltan es eliminarlos. Esto es especialmente útil en los casos en que tienes muchos datos y la pérdida de una pequeña parte no afectará al análisis posterior. Puedes utilizar un método .dropna() como se muestra a continuación. Aquí, estamos guardando los resultados de .dropna() en un DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2El argumento axis te permite especificar si estás eliminando filas, o columnas, con valores perdidos. La opción por defecto axis elimina las filas que contienen NaNs. Utiliza axis = 1 para eliminar las columnas con uno o más valores NaN. Además, fíjate en que estamos utilizando el argumento inplace=True, que te permite omitir guardar la salida de .dropna() en un nuevo DataFrame.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()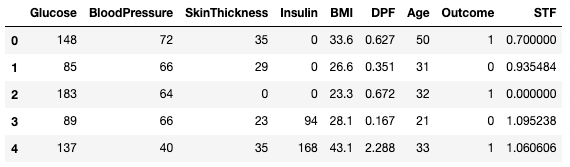
Eliminación de datos perdidos en pandas
También puedes eliminar tanto las filas como las columnas con valores perdidos estableciendo el argumento how como 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')En lugar de descartar, sustituir los valores perdidos por una estadística de resumen o un valor específico (según el caso de uso) quizá sea la mejor forma de proceder. Por ejemplo, si falta una fila de una columna de temperatura que indica las temperaturas a lo largo de los días de la semana, sustituir ese valor que falta por la temperatura media de esa semana puede ser más eficaz que suprimir los valores por completo. Puedes sustituir los datos que faltan por la media de la fila o de la columna utilizando el código siguiente.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Vamos a añadir algunos duplicados a los datos originales para aprender a eliminar duplicados en un Marco de Datos. Aquí, estamos utilizando el método .concat() para concatenar las filas del Marco de Datos df2 con el Marco de Datos df2, añadiendo duplicados perfectos de cada fila en df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Puedes eliminar todas las filas duplicadas (por defecto) del DataFrame utilizando el método .drop_duplicates() .
df3 = df3.drop_duplicates()
df3.shape(768, 9)Una tarea habitual de limpieza de datos es renombrar columnas. Con el método .rename(), puedes utilizar columns como argumento para renombrar columnas concretas. El código siguiente muestra el diccionario para asignar nombres de columnas antiguos y nuevos.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()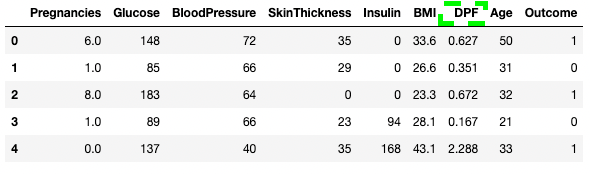
Renombrar columnas en pandas
También puedes asignar directamente los nombres de las columnas como una lista al Marco de datos.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()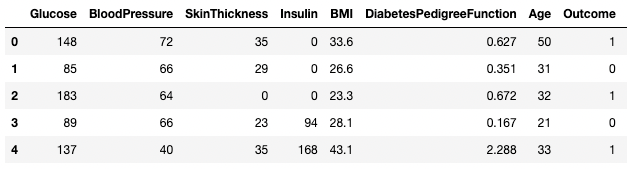
Renombrar columnas en pandas
Para saber más sobre la limpieza de datos, y para que los flujos de trabajo de limpieza de datos sean más fáciles y predecibles, consulta la siguiente lista de comprobación, que te proporciona un conjunto completo de tareas habituales de limpieza de datos.
La principal propuesta de valor de pandas reside en su rápida funcionalidad de análisis de datos. En esta sección, nos centraremos en un conjunto de técnicas de análisis que puedes utilizar en pandas.
Como has visto antes, puedes obtener la media de cada valor de columna utilizando el método .mean().
df.mean()
Imprimir la media de las columnas en pandas
Un modo puede calcularse de forma similar utilizando el método .mode().
df.mode()
Imprimir el modo de las columnas en pandas
Del mismo modo, la mediana de cada columna se calcula con el método .median()
df.median()
Imprimir la mediana de las columnas en pandas
pandas proporciona un cálculo rápido y eficaz combinando dos o más columnas como variables escalares. El código siguiente divide cada valor de la columna Glucose con el valor correspondiente de la columna Insulin para calcular una nueva columna llamada Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Crear una nueva columna a partir de columnas existentes en pandas
.value_counts()A menudo trabajarás con valores categóricos, y querrás contar el número de observaciones que tiene cada categoría en una columna. Los valores de las categorías pueden contarse utilizando los métodos .value_counts(). Aquí, por ejemplo, contamos el número de observaciones en las que Outcome es diabético (1) y el número de observaciones en las que Outcome no es diabético (0).
df['Outcome'].value_counts()
Uso de .value_counts() en pandas
Si añades el argumento normalize, obtendrás proporciones en lugar de recuentos absolutos.
df['Outcome'].value_counts(normalize=True)
Uso de .value_counts() en pandas con normalización
Desactiva la ordenación automática de los resultados mediante el argumento sort (True por defecto). La ordenación por defecto se basa en los recuentos en orden descendente.
df['Outcome'].value_counts(sort=False)
Uso de .value_counts() en pandas con ordenación
También puedes aplicar .value_counts() a un objeto DataFrame y a columnas concretas dentro de él, en lugar de sólo a una columna. Aquí, por ejemplo, estamos aplicando value_counts() en df con el argumento subconjunto, que recibe una lista de columnas.
df.value_counts(subset=['Pregnancies', 'Outcome'])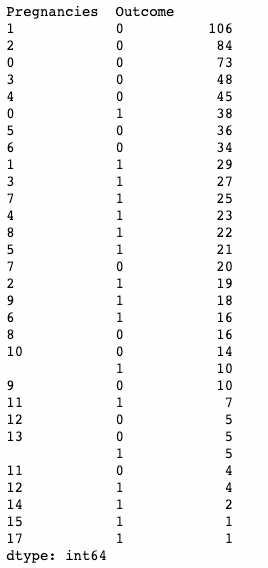
Utilizando .value_counts() en pandas al subconjuntar columnas
.groupby() en pandaspandas te permite agregar valores agrupándolos por valores de columna específicos. Puedes hacerlo combinando el método .groupby() con un método de resumen de tu elección. El código siguiente muestra la media de cada una de las columnas numéricas agrupadas por Outcome.
df.groupby('Outcome').mean()
Agregar datos por una columna en pandas
.groupby() permite agrupar por más de una columna pasando una lista de nombres de columnas, como se muestra a continuación.
df.groupby(['Pregnancies', 'Outcome']).mean()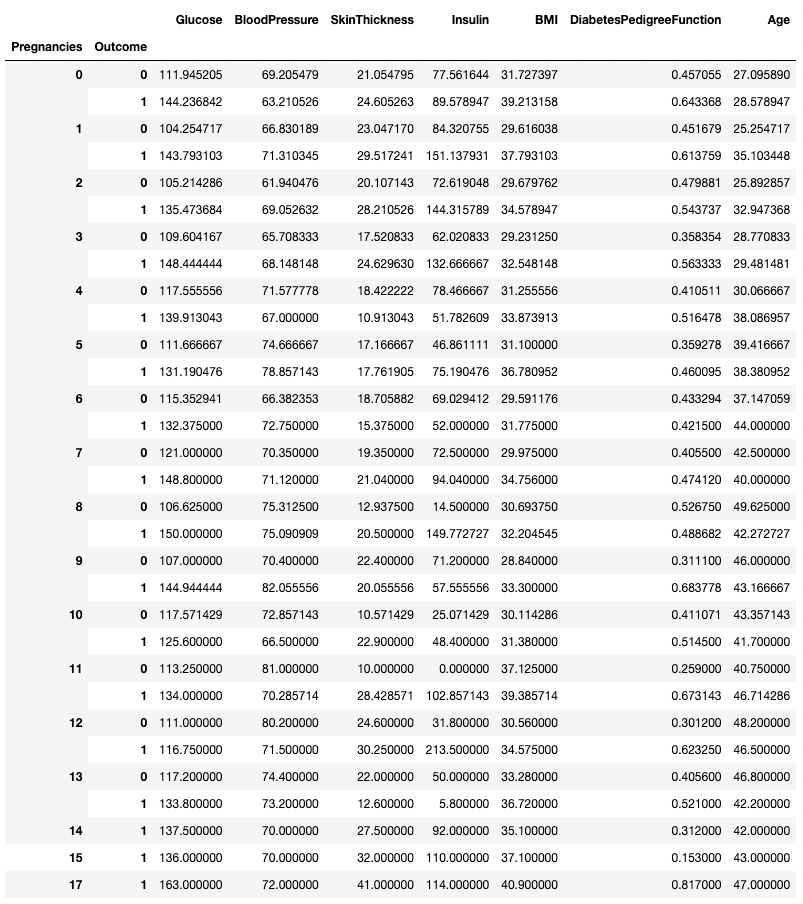
Agregar datos por dos columnas en pandas
Se puede utilizar cualquier método de resumen junto con .groupby(), incluyendo .min(), .max(), .mean(), .median(), .sum(), .mode(), y más.
pandas también te permite calcular estadísticas resumidas como tablas dinámicas. Esto facilita sacar conclusiones basadas en una combinación de variables. El código siguiente recoge las filas como valores únicos de Pregnancies, los valores de las columnas son los valores únicos de Outcome, y las celdas contienen el valor medio de BMI en el grupo correspondiente.
Por ejemplo, para Pregnancies = 5 y Outcome = 0, el IMC medio resulta ser de 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc=np.mean)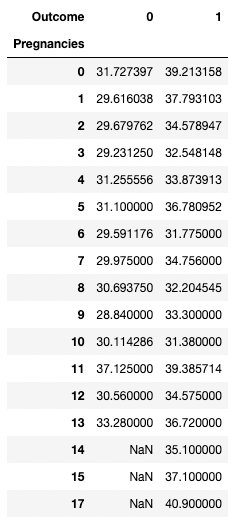
Agregar datos pivotando con pandas
pandas proporciona cómodas envolturas a las funciones de trazado de Matplotlib para facilitar la visualización de tus DataFrames. A continuación, verás cómo hacer visualizaciones de datos comunes utilizando pandas.
pandas te permite trazar las relaciones entre variables mediante gráficos de líneas. A continuación se muestra un gráfico lineal del IMC y la Glucosa frente al índice de filas.
df[['BMI', 'Glucose']].plot.line()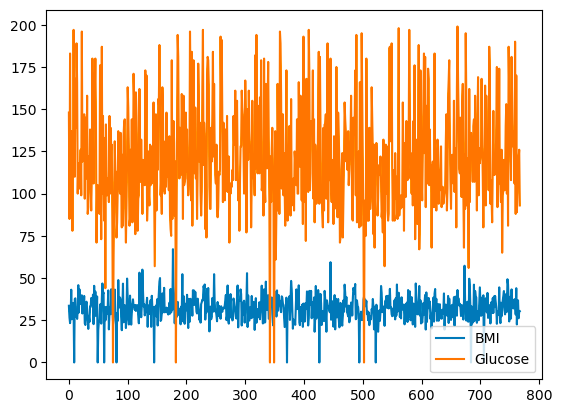
Gráfico lineal básico con pandas
Puedes seleccionar la elección de colores utilizando el argumento color.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})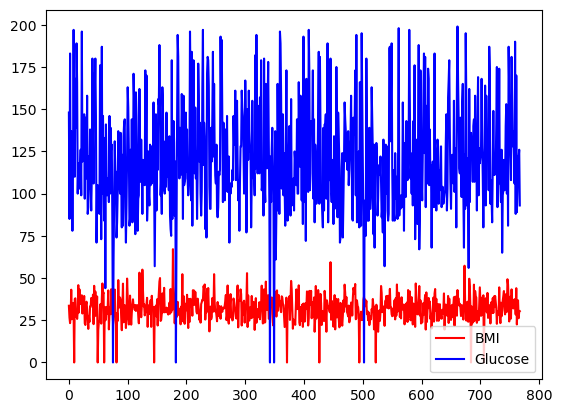
Gráfico lineal básico con pandas, con colores personalizados
Todas las columnas de df también pueden representarse en diferentes escalas y ejes utilizando el argumento subplots.
df.plot.line(subplots=True)
Subparcelas para gráficos lineales con pandas
Para columnas discretas, puedes utilizar un diagrama de barras sobre los recuentos de categorías para visualizar su distribución. La variable Outcome con valores binarios se visualiza a continuación.
df['Outcome'].value_counts().plot.bar()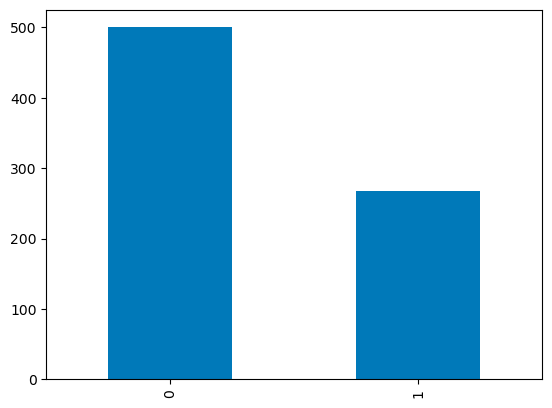
Gráficos de barras en pandas
La distribución por cuartiles de las variables continuas puede visualizarse mediante un diagrama de caja. El código siguiente te permite crear un boxplot con pandas.
df.boxplot(column=['BMI'], by='Outcome')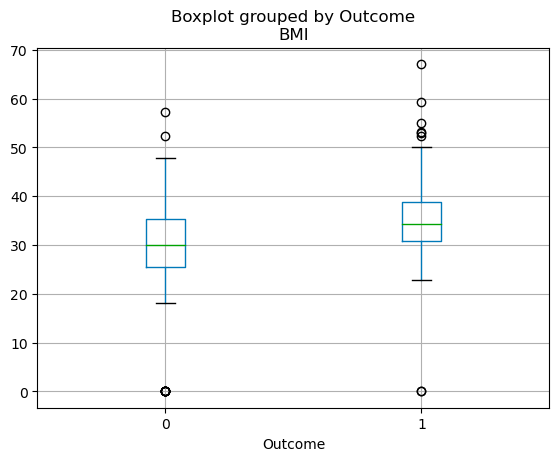
Boxplots en pandas
El tutorial anterior araña la superficie de lo que es posible con los pandas. Ya sea analizando datos, visualizándolos, filtrándolos o agregándolos, pandas proporciona un conjunto de funciones increíblemente rico que te permite acelerar cualquier flujo de trabajo de datos. Además, combinando pandas con otros paquetes de ciencia de datos, podrás crear cuadros de mando interactivos, crear modelos predictivos mediante aprendizaje automático, automatizar flujos de trabajo de datos y mucho más. Echa un vistazo a los siguientes recursos para acelerar tu viaje de aprendizaje de los pandas:
Más cursos para pandas
Curso
Curso
Curso
blog
Matt Crabtree
15 min
Tutorial
Karlijn Willems
Tutorial
Natassha Selvaraj
Tutorial
DataCamp Team
Tutorial
Karlijn Willems
Tutorial
Kurtis Pykes


