Dalam tutorial ini, Anda akan menjelajahi sejumlah metode visualisasi data dan statistik yang mendasarinya. Khususnya terkait dengan identifikasi tren dan hubungan antar variabel dalam sebuah data frame.
Tepat sekali, Anda akan berfokus pada konsep seperti korelasi dan regresi! Pertama, Anda akan diperkenalkan dengan korelasi di R. Kemudian, Anda akan melihat bagaimana cara membuat plot matriks korelasi di R menggunakan paket seperti ggplot2 dan GGally. Terakhir, Anda akan melihat jenis-jenis korelasi yang ada dan mengapa hal tersebut penting untuk analisis Anda selanjutnya.
Jika Anda tertarik untuk mendalami topik ini lebih jauh, pertimbangkan untuk mengikuti kursus Korelasi dan Regresi dari DataCamp.
Latar Belakang
Dalam tutorial hari ini, Anda akan bekerja dengan kumpulan data film yang diperoleh dari Kaggle untuk menemukan cara memahami hubungan antar variabel dengan lebih baik.
Saya telah sedikit mengolah data tersebut agar analisis kita menjadi “setara” (apples-to-apples) dengan memastikan hal-hal seperti mata uang menggunakan satuan yang sama. Tanpa langkah tersebut, analisis statistik kita terhadap variabel seperti gross, budget, dan profit akan menyesatkan. Anda dapat mengakses kumpulan data aslinya .
Mengimpor Data
Untuk mengakses kumpulan data movies dan menggunakannya, Anda dapat menggunakan fungsi read.csv() untuk mengimpor data Anda ke dalam data frame dan menyimpannya dalam variabel dengan nama yang sangat orisinal, yaitu movies!
movies <- read.csv(url("http://s3.amazonaws.com/dcwoods2717/movies.csv"))Hanya itu yang diperlukan untuk memulai!
Inspeksi Dasar Data Anda
Setelah data frame diimpor, ada baiknya untuk mendapatkan gambaran tentang data Anda. Pertama, periksa struktur data yang sedang diperiksa. Di bawah ini Anda dapat melihat hasil penggunaan fungsi str() yang sangat sederhana dan bermanfaat:
str(movies)## 'data.frame': 2961 obs. of 11 variables:
## $ title : Factor w/ 2907 levels "10 Cloverfield Lane",..: 1560 2143 34 2687 1405 1896 2633 894 1604 665 ...
## $ genre : Factor w/ 17 levels "Action","Adventure",..: 6 12 5 5 5 3 2 8 3 8 ...
## $ director : Factor w/ 1366 levels "Aaron Schneider",..: 474 472 781 828 175 1355 1328 1328 968 747 ...
## $ year : int 1920 1929 1933 1935 1936 1937 1939 1939 1940 1946 ...
## $ duration : int 110 100 89 81 87 83 102 226 88 144 ...
## $ gross : int 3000000 2808000 2300000 3000000 163245 184925485 22202612 198655278 84300000 20400000 ...
## $ budget : int 100000 379000 439000 609000 1500000 2000000 2800000 3977000 2600000 8000000 ...
## $ cast_facebook_likes: int 4 109 995 824 352 229 2509 1862 1178 2037 ...
## $ votes : int 5 4546 7921 13269 143086 133348 291875 215340 90360 6304 ...
## $ reviews : int 2 107 162 164 331 349 746 863 252 119 ...
## $ rating : num 4.8 6.3 7.7 7.8 8.6 7.7 8.1 8.2 7.5 6.9 ...Dalam data frame khusus ini, Anda dapat melihat dari konsol bahwa terdapat 2961 observasi dari 11 variabel.
Sebagai catatan samping, bahkan jika setiap film hanya berdurasi satu jam, Anda perlu menonton film tanpa henti selama lebih dari empat bulan untuk melihat semuanya!
Konsol juga mencantumkan setiap variabel berdasarkan nama, kelas dari setiap variabel, dan beberapa contoh dari setiap variabel. Ini memberi kita gambaran yang cukup baik tentang apa yang ada di dalam data frame, yang pemahamannya sangat penting untuk upaya analisis kita.
Fungsi hebat lainnya untuk membantu kita melakukan tinjauan cepat tingkat tinggi terhadap data frame kita adalah summary(). Perhatikan persamaan dan perbedaan antara output yang dihasilkan dengan menjalankan str().
summary(movies)## title genre
## Home : 3 Comedy :848
## A Nightmare on Elm Street : 2 Action :738
## Across the Universe : 2 Drama :498
## Alice in Wonderland : 2 Adventure:288
## Aloha : 2 Crime :202
## Around the World in 80 Days: 2 Biography:135
## (Other) :2948 (Other) :252
## director year duration
## Steven Spielberg : 23 Min. :1920 Min. : 37.0
## Clint Eastwood : 19 1st Qu.:1999 1st Qu.: 95.0
## Martin Scorsese : 16 Median :2004 Median :106.0
## Tim Burton : 16 Mean :2003 Mean :109.6
## Spike Lee : 15 3rd Qu.:2010 3rd Qu.:119.0
## Steven Soderbergh: 15 Max. :2016 Max. :330.0
## (Other) :2857
## gross budget cast_facebook_likes
## Min. : 703 Min. : 218 Min. : 0
## 1st Qu.: 12276810 1st Qu.: 11000000 1st Qu.: 2241
## Median : 34703228 Median : 26000000 Median : 4604
## Mean : 58090401 Mean : 40619384 Mean : 12394
## 3rd Qu.: 75590286 3rd Qu.: 55000000 3rd Qu.: 16926
## Max. :760505847 Max. :300000000 Max. :656730
##
## votes reviews rating
## Min. : 5 Min. : 2.0 Min. :1.600
## 1st Qu.: 19918 1st Qu.: 199.0 1st Qu.:5.800
## Median : 55749 Median : 364.0 Median :6.500
## Mean : 109308 Mean : 503.3 Mean :6.389
## 3rd Qu.: 133348 3rd Qu.: 631.0 3rd Qu.:7.100
## Max. :1689764 Max. :5312.0 Max. :9.300
## Dengan satu perintah, Anda telah membuat R mengembalikan beberapa informasi statistik utama untuk setiap variabel dalam data frame kita. Sekarang setelah Anda mengetahui apa yang sedang Anda kerjakan, mari kita selami dan jelajahi data lebih lanjut!
Rekayasa Fitur: Menghitung Profit
Dalam meninjau variabel yang tersedia bagi Anda, tampaknya beberapa variabel numerik dapat dimanipulasi untuk memberikan wawasan baru ke dalam data frame kita.
Misalnya, Anda memiliki variabel gross dan budget, jadi mengapa tidak menggunakan sedikit subsetting untuk menghitung profit untuk setiap film?
Anda dapat menghitung profit dengan menggunakan rumus profit = gross - budget. Cobalah di potongan DataCamp Light di bawah ini!
Luar biasa!
Anda dapat melihat bahwa ada cukup banyak koleksi film yang menghasilkan uang dan film yang merugi dalam data frame kita.
profit dari film-film kita mungkin dapat digunakan untuk beberapa analisis menarik di masa mendatang, jadi mari kita tambahkan profit sebagai kolom baru ke data frame kita.
Korelasi
Sekarang setelah profit ditambahkan sebagai kolom baru di data frame kita, saatnya untuk melihat lebih dekat hubungan antara variabel-variabel dalam kumpulan data Anda.
Mari kita lihat bagaimana profit berfluktuasi relatif terhadap rating setiap film.
Untuk ini, Anda dapat menggunakan fungsi plot dan abline bawaan R, di mana plot akan menghasilkan scatter plot dan abline akan menghasilkan garis regresi atau “garis kecocokan terbaik” karena penyertaan argumen model linear kita seperti yang akan Anda lihat di bawah.
Apakah outputnya sesuai dengan yang Anda harapkan?
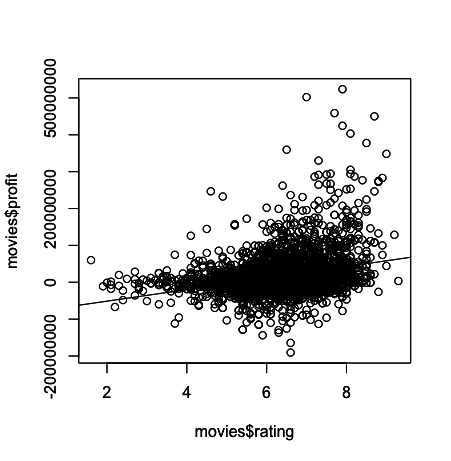
Secara umum, tampaknya film dengan rating yang lebih tinggi cenderung memiliki profit yang lebih tinggi. Cara lain untuk mengungkapkan pernyataan ini adalah dengan mengatakan bahwa terdapat korelasi positif antara rating dan profit, setidaknya dalam data frame kita.
Meskipun demikian, sekilas melihat plot tersebut mengungkapkan bahwa ada banyak film dengan rating tinggi yang tidak benar-benar sukses besar, dan ada sejumlah film yang sangat menguntungkan yang mendapatkan rating relatif rendah.
Korelasi TIDAK menyiratkan sebab-akibat!
Satu anekdot untuk membantu Anda memahami korelasi versus sebab-akibat adalah sebagai berikut: Saya menjalankan kedai es krim di pantai. Rata-rata jumlah orang yang menyeberang jalan sembarangan di kota cenderung meningkat ketika penjualan es krim saya meningkat, tetapi apakah es krim saya menyebabkan orang mengabaikan peraturan lalu lintas, atau ada kekuatan lain yang berperan? Es krim saya memang enak, tetapi sinar matahari di luar mungkin ada hubungannya dengan orang yang menginginkan es krim dan orang yang tidak ingin berdiri di bawah terik matahari di penyeberangan jalan. Hubungan (korelasi) memang ada antara penjualan es krim saya dan jumlah orang yang menyeberang jalan sembarangan, tetapi Anda tidak dapat secara definitif menyatakan bahwa itu adalah hubungan sebab-akibat.
Ingatlah alur penalaran itu saat Anda melanjutkan tutorial ini!
Menghitung Korelasi di R
Jadi, jenis hubungan apa yang ada antara variabel-variabel dalam movies, dan bagaimana Anda dapat mengevaluasi hubungan tersebut secara kuantitatif?
Cara pertama adalah dengan menghasilkan korelasi dan matriks korelasi dengan cor():
Catatan bahwa Anda juga dapat menentukan metode yang Anda inginkan untuk menunjukkan koefisien korelasi mana yang ingin Anda hitung. Berhati-hatilah, karena selalu ada beberapa asumsi yang digunakan oleh korelasi ini: metode Kendall dan Spearman hanya masuk akal untuk input yang berurutan. Ini berarti Anda perlu mengurutkan data Anda sebelum menghitung koefisien korelasi.
Selain itu, metode default, korelasi Pearson, mengasumsikan bahwa variabel Anda terdistribusi normal, bahwa terdapat hubungan garis lurus antara masing-masing variabel, dan bahwa data terdistribusi normal di sekitar garis regresi.
Perhatikan juga bahwa Anda dapat menggunakan rcorr(), yang merupakan bagian dari paket Hmisc untuk menghitung tingkat signifikansi untuk korelasi pearson dan spearman.
Anda juga akan melihat bahwa matriks korelasi sebenarnya adalah tabel yang menunjukkan koefisien korelasi antar kumpulan variabel. Ini sudah menjadi cara pertama yang bagus untuk mendapatkan gambaran tentang hubungan mana yang ada antara variabel-variabel dalam kumpulan data Anda, tetapi mari kita bahas lebih dalam di bagian selanjutnya.
Menjelajahi Korelasi Secara Visual: Matriks Korelasi R
Dalam eksplorasi berikutnya, Anda akan memplot matriks korelasi menggunakan variabel yang tersedia dalam data frame movies Anda. Plot sederhana ini akan memungkinkan Anda untuk memvisualisasikan dengan cepat variabel mana yang memiliki korelasi negatif, positif, lemah, atau kuat dengan variabel lainnya.
Untuk melakukan keajaiban ini, Anda akan menggunakan paket keren bernama GGally dan fungsi bernama ggcorr().
Bentuk pemanggilan fungsi ini adalah ggcorr(df), di mana df adalah nama data frame yang Anda gunakan untuk memanggil fungsi tersebut. Output dari fungsi ini akan berupa matriks berbentuk segitiga yang diberi kode warna dan diberi label dengan nama variabel kita. Koefisien korelasi dari setiap variabel relatif terhadap variabel lain dapat ditemukan dengan membaca matriks tersebut secara mendatar dan/atau menurun, tergantung pada lokasi variabel dalam matriks.
Mungkin terdengar membingungkan, tetapi sebenarnya sangat sederhana dalam praktiknya, jadi cobalah di potongan kode berikut!
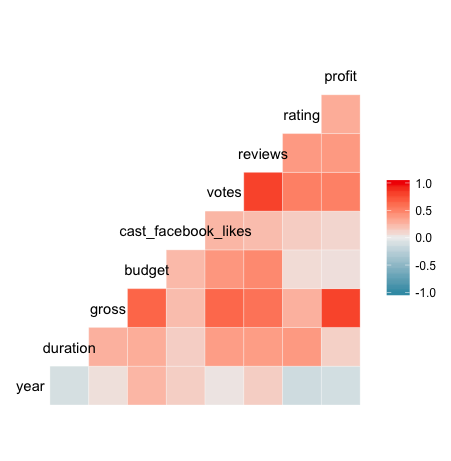
Jadi, dalam matriks korelasi yang baru saja Anda buat (kerja bagus!), Anda dapat pergi ke baris atau kolom yang terkait dengan variabel, seperti year, dan melihat koefisien korelasinya sebagaimana ditunjukkan oleh warna sel yang sesuai dengan variabel lain.
Dalam memeriksa year, misalnya, Anda dapat melihat bahwa terdapat korelasi positif yang lemah dengan budget dan korelasi negatif yang sama lemahnya dengan rating.
Koefisien korelasi selalu berada di antara -1 dan 1, inklusif. Koefisien korelasi -1 menunjukkan kecocokan negatif yang sempurna di mana nilai-y menurun pada tingkat yang sama dengan peningkatan nilai-x. Koefisien korelasi 1 menunjukkan kecocokan positif yang sempurna di mana nilai y meningkat pada tingkat yang sama dengan peningkatan nilai x.
Dalam kebanyakan kasus, seperti contoh year Anda di atas, koefisien korelasi akan berada di antara -1 dan 1.
Apakah Anda melihat sesuatu yang agak aneh tentang variabel yang ditampilkan dalam matriks korelasi?
Tidak semua variabel dalam movies ada di sana!
Itu karena tidak semua variabel dalam movies bersifat numerik. Fungsi ggcorr mengabaikan variabel non-numerik secara otomatis, yang menghemat waktu dengan membebaskan pengguna dari keharusan “menghapus subset” variabel tersebut sebelum membuat matriks.
Jika Anda ingin matriks korelasi Anda benar-benar “menonjol” (atau mungkin Anda sedikit buta warna, seperti saya), ada beberapa penyesuaian sederhana yang dapat Anda lakukan untuk menghasilkan matriks yang lebih menarik secara visual dan sarat data.
Dalam potongan kode berikut, Anda telah menyertakan argumen label, yang dapat diatur sama dengan TRUE atau FALSE. Pengaturan defaultnya adalah FALSE, tetapi jika Anda menambahkan label = TRUE, koefisien korelasi dari setiap hubungan akan disertakan dalam sel yang sesuai. Ini mencegah Anda menebak nilai setiap koefisien berdasarkan skala warna.
Argumen label_alpha memungkinkan Anda untuk meningkatkan atau menurunkan opasitas setiap label berdasarkan kekuatan koefisien korelasi. Ini sangat membantu dalam analisis data visual yang cepat.
Jangan hanya percaya kata-kata saya, cobalah sendiri!
Sekarang mari kita buat matriks korelasi yang lebih baik:
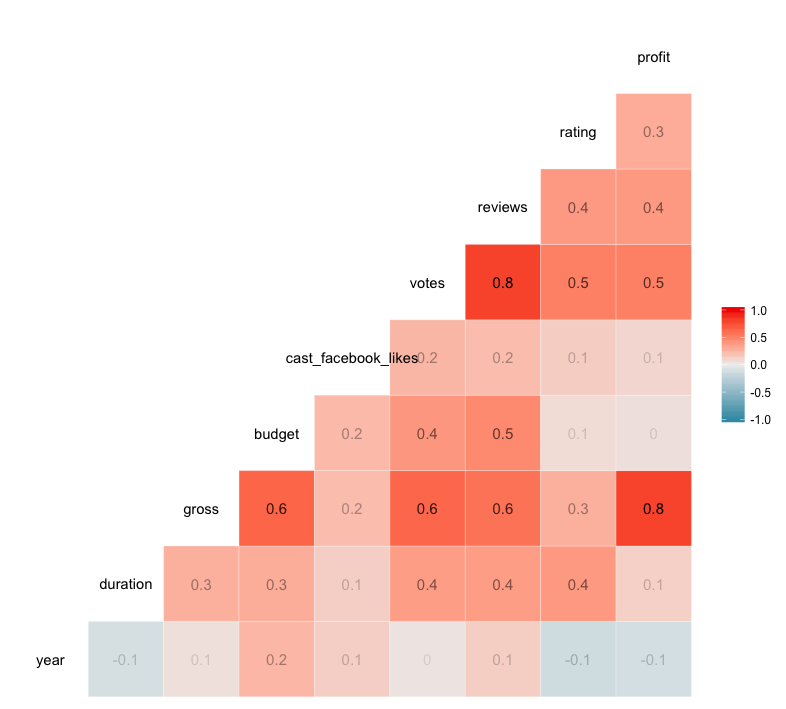
Dalam plot yang mengikuti, Anda akan melihat bahwa ketika plot dengan korelasi “kuat” dibuat, kemiringan garis regresinya (x/y) lebih mendekati 1/1 atau -1/1, sementara plot korelasi “lemah” mungkin memiliki garis regresi dengan kemiringan yang hampir tidak ada. Kemiringan yang lebih mendekati 1/1 atau -1/1 menyiratkan bahwa kedua variabel yang diplot berhubungan erat.
Dalam kasus data frame movies kita, garis regresi semacam itu dapat memberikan wawasan yang kuat tentang sifat variabel Anda dan dapat menunjukkan saling ketergantungan variabel-variabel tersebut.
Misalnya, dalam plot profit terhadap rating Anda sebelumnya, Anda melihat bahwa garis regresi kita memiliki kemiringan positif yang moderat. Melihat kembali matriks korelasi Anda, Anda melihat bahwa koefisien korelasi dari kedua variabel ini adalah 0,3.
Masuk akal, bukan?
Jenis-jenis Korelasi
Mari kita lihat plot tambahan yang mengilustrasikan berbagai jenis korelasi yang telah Anda lihat di bagian sebelumnya!
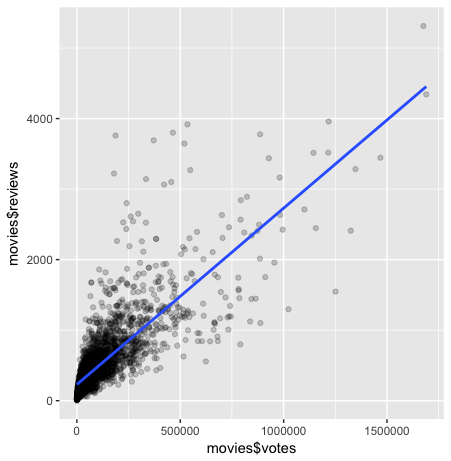
Korelasi Kuat: Memplot Votes Versus Reviews
Mari kita mulai dengan memplot dua variabel dengan korelasi positif yang kuat.
Melihat matriks korelasi kita, tampaknya votes versus reviews memenuhi kriteria Anda, dengan nilai korelasi 0,8. Itu berarti kemiringan kita harus relatif mendekati 1/1.
Anda akan menerapkan paket ggplot2 dalam latihan ini dan latihan-latihan berikutnya. Paket ggplot2 adalah perangkat serbaguna yang dapat digunakan untuk membuat visualisasi data yang menarik.
Dalam kasus ini, Anda akan memanfaatkan fungsi qplot di dalam paket ggplot2, yang dapat menghasilkan banyak jenis plot berdasarkan jenis plot apa yang diteruskan ke argumen geom (geometri).
Dalam potongan kode berikut, geom telah diatur ke vektor yang berisi dua jenis geometri, point dan smooth, di mana point menghasilkan scatterplot dan smooth menghasilkan garis tren. Anda juga akan melihat bahwa method telah diatur ke lm, yang berarti garis tren akan menjadi garis regresi lurus yang familier yang dibuat dalam plot profit terhadap years kita sebelumnya.
Singkatnya, Anda akan belajar betapa mudahnya menghasilkan visualisasi data yang keren dalam sekejap!
Anda mungkin mengenali argumen alpha yang disertakan dalam fungsi qplot di atas. Penggunaan alpha dalam qplot menerapkan gradien opasitas ke titik-titik dalam scatter plot mirip dengan bagaimana ia mengubah opasitas label koefisien korelasi di ggcorr.
Dalam konfigurasi yang Anda gunakan, opasitas total hanya dicapai ketika satu titik ditumpuk oleh 5 titik lainnya. Meningkatkan atau menurunkan angka pada penyebut alpha akan memengaruhi jumlah titik tumpang tindih yang diperlukan untuk mengubah opasitas suatu titik. Salah satu alasan untuk menggunakan estetika ini adalah karena dapat membantu pengguna mengidentifikasi konsentrasi titik data dalam plot mereka dengan cepat, yang pada gilirannya dapat memunculkan wawasan baru tentang data kita hanya dengan sekali lihat.
Silakan utak-atik kodenya dan lihat sendiri cara kerjanya!
Korelasi Lemah: Memplot Profit Terhadap Tahun
Sekarang mari kita lihat seperti apa korelasi negatif yang “lemah” dengan memplot profit terhadap years. Kali ini, tidak ada method yang ditentukan, jadi garis tren kita akan bervariasi menurut data secara kurvilinear (kurva yang disesuaikan), yang merupakan default untuk fungsi ini. Anda akan melihat bahwa di sepanjang bagian tertentu dari garis tren terdapat area abu-abu muda yang ukurannya bertambah atau berkurang sesuai dengan interval kepercayaan garis tren.
Jika Anda tidak terbiasa dengan konsep interval kepercayaan, jangan khawatir! R akan melakukan pekerjaan itu untuk Anda, dan konsep tersebut akan dijelaskan lebih baik setelah latihan ini.
Untuk saat ini, cukup isi bagian yang kosong dengan kode yang diperlukan dan amati!
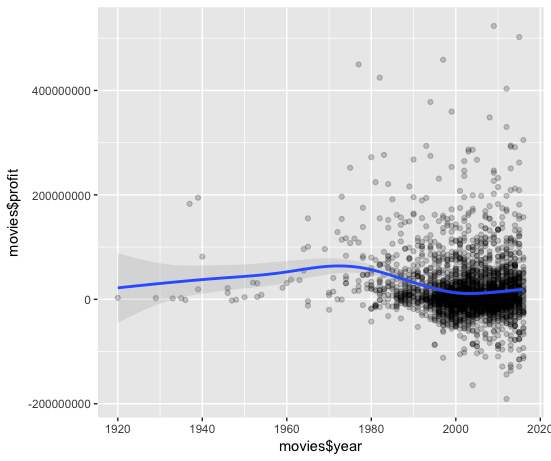
Jadi sekarang setelah Anda memiliki kesempatan untuk melihat interval kepercayaan dan kurva penghalusan beraksi, pengamatan apa yang dapat Anda buat?
- Pertama, Anda melihat bahwa pada bagian awal plot,
profittampaknya meningkat setiapyear. - Kedua, Anda melihat bahwa area abu-abu yang diimbangi dari kurva penghalusan Anda pada awalnya cukup besar dan jumlah titik data (atau observasi) cukup kecil.
- Ketiga, saat kurva bergerak ke konsentrasi observasi yang lebih besar, area abu-abu berkurang dan praktis memeluk kurva, yang mulai menurun di
year-yearberikutnya.
Kesimpulannya, memplot interval kepercayaan bersama dengan kurva penghalusan memungkinkan kita untuk melihat jumlah ketidakpastian yang terkait dengan garis regresi kita. Ketidakpastian itu meningkat dengan lebih sedikit observasi dan menurun dengan lebih banyak observasi.
Ini sangat membantu dalam memvisualisasikan bagaimana hubungan antara variabel kita berubah di seluruh data frame dan mengungkapkan bagaimana konsentrasi observasi mengubah kurva yang diplot.
Peringatannya di sini adalah bahwa plot tersebut mungkin sedikit menyesatkan, karena sulit untuk membedakan secara visual apakah ada korelasi positif atau negatif dari variabel Anda.
Mari kita sekarang memplot profit terhadap year dengan cara yang sama seperti Anda memplot votes versus reviews: cukup ganti “…..” di setiap argumen sehingga tahun diplot pada sumbu x dan profit ada pada sumbu y. Pastikan untuk menentukan data frame mana yang sama dengan “data”!
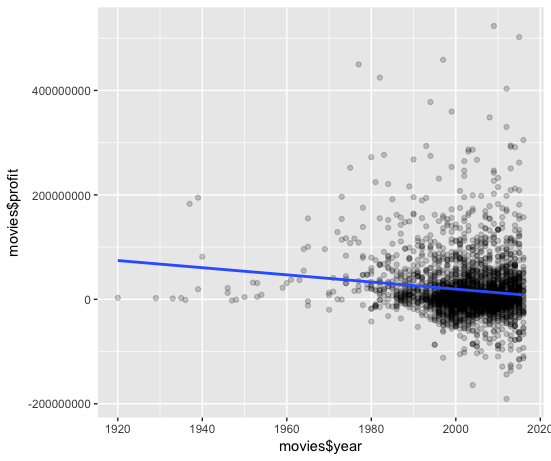
Melihat kembali matriks korelasi Anda, Anda melihat bahwa koefisien korelasi profit dan year adalah -0,1, yang mungkin lebih mudah divisualisasikan dalam plot yang menggabungkan garis kecocokan terbaik daripada dalam plot yang menggunakan kurva yang disesuaikan.
Menyatukan Semuanya
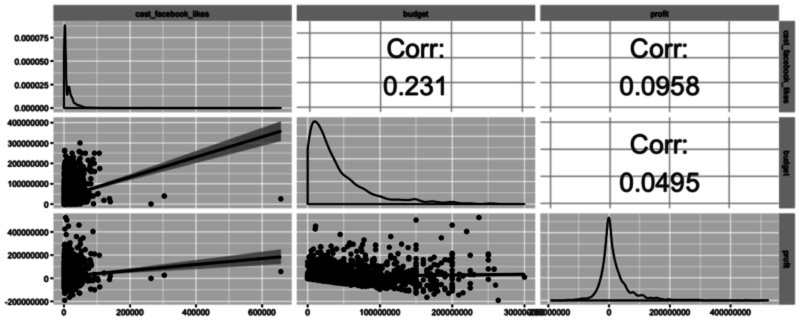
Mari kita sekarang melihat fungsi kuat lainnya yang tersedia di GGally bernama ggpairs. Fungsi ini hebat karena memungkinkan pengguna untuk membuat matriks yang menunjukkan koefisien korelasi dari beberapa variabel bersama dengan scatterplot (termasuk garis kecocokan terbaik dengan interval kepercayaan) dan plot kepadatan.
Menggunakan satu fungsi ini, Anda dapat secara efektif menggabungkan semua yang telah Anda bahas dalam tutorial ini dengan cara yang ringkas dan mudah dipahami.
Dalam potongan kode berikut, pilih tiga variabel favorit Anda dari data frame (tidak perlu subsetting!), masukkan, dan mainkan!
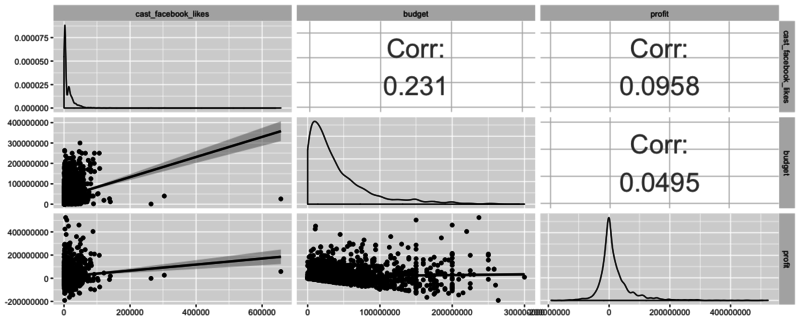
Seperti yang mungkin sudah Anda duga, ada banyak skenario di mana satu jenis plot ideal - kuncinya adalah mempelajari teknik visualisasi apa yang tersedia, cara menggunakannya, dan apa arti hasil akhirnya!
Melangkah Lebih Jauh
Anda telah membahas banyak hal dalam tutorial ini, jadi selamat karena telah berhasil sampai akhir!
Saya harap Anda dapat menerapkan konsep-konsep ini dalam petualangan analitis Anda sendiri! Ini benar-benar dasar-dasar eksplorasi data di R dan masih banyak lagi yang dapat Anda lakukan untuk memastikan bahwa Anda mendapatkan gambaran yang baik tentang data Anda sebelum Anda mulai menganalisis dan memodelkannya. Mengapa tidak meningkatkan upaya Anda dan memulai kursus Analisis Data Eksploratif dari DataCamp?
Sementara itu, saya mendorong Anda untuk mengunjungi Kaggle dan menemukan kumpulan data yang kaya dan menarik untuk Anda jelajahi sendiri jika Anda tidak ingin melanjutkan dengan kumpulan data movies!