Curso
Introducción a MongoDB en Python
3 h
24K
Si alguna vez has visto una película de crímenes reales, ya conoces el poder de conectar los puntos entre las relaciones. Siempre hay una escena en la que vemos una pared con los principales sospechosos y varios artículos de periódico que los relacionan.
Imagina que coges ese tablero y le añades un motor matemático para que pueda consultar rápidamente las distintas relaciones. Esa es la esencia de una base de datos de grafos.
En este artículo trataremos los siguientes temas:
Una base de datos de grafos es una plataforma especializada y de propósito único que se utiliza para crear y manipular datos de naturaleza asociativa y contextual. El propio grafo contiene nodos, aristas y propiedades que se unen para permitir a los usuarios representar y almacenar datos de una forma que las bases de datos relacionales no están equipadas para hacer.
El concepto principal de un sistema de base de datos de grafos es una relación. Las relaciones se definen como ciudadanos de primera clase, lo que significa que todo lo que puedes hacer con los demás elementos se puede hacer con una relación. Los datos se relacionan entre sí en un grafo para almacenar una colección de nodos y aristas, donde las aristas representan la relación entre nodos.
Las relaciones permiten vincular directamente los datos del sistema. Consultar las relaciones en una base de datos de grafos es rápido, ya que se almacenan de forma que no cambien. También puedes visualizarlos, lo que los hace ideales para obtener información sobre datos muy interconectados.
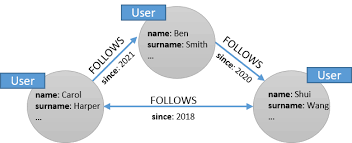
Una representación de las relaciones en una base de datos de grafos de redes sociales
Puede que aún te preguntes en qué se diferencia una base de datos de grafos de una relacional. Ambos tipos almacenan información y se utilizan para representar relaciones entre datos, pero la forma en que cada uno consigue este objetivo es diferente.
Dividiremos las diferencias entre ellas en cinco categorías:
Profundicemos en sus diferencias.
Las bases de datos relacionales utilizan tablas de datos para estructurar la información en filas y columnas. Cada columna define un atributo específico de la entidad de datos, mientras que las filas representan un registro de datos individual. Como las tablas de datos tienen un esquema fijo, los usuarios deben definir las relaciones entre las distintas tablas utilizando claves primarias y externas.
En cambio, una base de datos de grafos estructura los datos mediante una estructura de grafos en la que se utilizan nodos, aristas y propiedades para representar los datos. A saber, los nodos definen los objetos, las aristas ilustran las relaciones entre nodos, y las propiedades describen los atributos de los nodos y aristas. Más abajo encontrarás más información.
Las bases de datos relacionales aprovechan la potencia de SQL para manipular datos. SQL permite a los desarrolladores realizar diversas consultas y maneja eficazmente datos estructurados con relaciones bien definidas entre tablas. Destaca especialmente en el filtrado, la agregación y la unión de datos contra múltiples tablas.
Las bases de datos de grafos utilizan algoritmos transversales para consultar el modelo de datos de grafos. Los algoritmos de recorrido pueden ser de profundidad primero o de amplitud primero, lo que ayuda a descubrir y recuperar datos conectados rápidamente.
Aunque es posible escalar horizontalmente una base de datos de relaciones (es decir, utilizando la fragmentación), esto aumenta significativamente la complejidad del almacenamiento de datos y puede dar lugar a otros problemas, como el de la coherencia. La forma recomendada de escalar una base de datos relacional es verticalmente. El escalado vertical es cuando se actualiza el hardware (por ejemplo, CPU, almacenamiento, memoria, etc.) para aumentar la carga de trabajo que puede soportar un servidor.
Por otro lado, las bases de datos de grafos hacen un gran trabajo escalando horizontalmente. Consiguen esta hazaña utilizando el particionamiento, que es una técnica que divide los objetos almacenados de la base de datos en partes separadas en diferentes servidores. Estas particiones permiten entonces que muchos servidores procesen consultas sobre grafos en paralelo.
Las bases de datos de grafos suelen utilizar la adyacencia sin índices. Esto significa que cada nodo hace referencia directa a sus nodos vecinos. Así, acceder a las relaciones y a los datos relacionados consiste simplemente en buscar puntos de memoria. Esto significa esencialmente que es rápido.
Las bases de datos relacionales deben realizar exploraciones de las distintas tablas para identificar las relaciones entre entidades. Por ejemplo, si quisieras unir varias tablas, el sistema de base de datos tendría que escanear todos los datos para encontrar las relaciones. Esto significa que a medida que aumentan los datos, disminuye el rendimiento.
Las relaciones son fundamentales en las bases de datos de grafos. Esto hace que sean extremadamente fáciles de trabajar cuando se utilizan datos conectados, especialmente al realizar consultas multisalto, es decir, consultas para realizar recorridos transversales con múltiples relaciones. En una base de datos relacional, esto debe realizarse con SQL. Escribir una consulta multisalto en SQL no es algo natural. Pueden llegar a ser bastante complejas y dar lugar fácilmente a consultas masivas difíciles de leer y mantener.
El enfoque en las relaciones hace que las bases de datos de grafos sean muy adecuadas para tareas que observan con frecuencia cambios y adaptaciones dinámicas. Tales tareas incluyen la búsqueda semántica y los motores de recomendación. En cambio, la rigidez de las bases de datos relacionales las hace ideales para datos que primero hayan sido bien estructurados en tablas. Ejemplos de estos datos son los datos de los clientes y las transacciones.
|
Base de datos de grafos |
Base de datos relacional |
|
|
Modelo de datos / Esquema |
Fijo |
Flexible |
|
Funcionamiento |
Algoritmos transversales |
SQL |
|
Escalabilidad |
Horizontal mediante la creación de particiones |
Verticalmente (puede hacerse horizontalmente, pero añade complejidad). |
|
Rendimiento |
Rápido (incluyendo grandes conjuntos de datos) |
Más lento a medida que aumenta el conjunto de datos |
|
Facilidad de uso |
Intuitivo |
No son naturales (pero son mucho más maduros y populares en muchos casos de uso). |
|
Aplicación |
Tareas que observan con frecuencia cambios y adaptaciones dinámicas (por ejemplo, búsqueda semántica, motores de recomendación, etc.). |
Tareas que dependen de la integridad de los datos (por ejemplo, datos de clientes, transacciones, etc.). |
Como ya se ha dicho, las bases de datos de grafos permiten a los usuarios representar los datos como un grafo. Los tres componentes vitales utilizados para modelar datos en este formato son los nodos, las aristas y las propiedades.
Los objetos o instancias se representan mediante un nodo. Conceptualmente, los nodos son el equivalente a una fila en una base de datos relacional y actúan como un vértice dentro de un grafo. Agrupar un nodo se hace simplemente aplicando una etiqueta a cada miembro.
Otro nombre para las aristas (edges) de un grafo son relaciones. Las relaciones siempre constan de un nodo inicial, un nodo final, un tipo y una dirección. Forman los patrones de datos describiendo las relaciones padre-hijo, las acciones, la propiedad y similares.
En pocas palabras, las propiedades son la información asociada a los nodos.
Echemos un vistazo a algunas de las bases de datos de grafos más populares que se pueden utilizar hoy en día, que nos ayudarán a comprender cuáles son sus características principales.

Algunas bases de datos de grafos populares
Neo4j es una de las principales bases de datos de grafos del mundo que permite a los usuarios descubrir de forma profunda, fácil y rápida patrones y perspectivas en miles de millones de conexiones de datos. En concreto, Neo4j es una base de datos NoSQL de código abierto altamente escalable desarrollada con Java. Consulta nuestro curso de conceptos NoSQL para saber más.
Las características principales son:
Las aplicaciones que trabajan con datos densamente conectados pueden desarrollarse y ejecutarse rápida y fácilmente utilizando Amazon Neptune, un servicio de base de datos de grafos rápido, fiable y totalmente administrado. La base de Neptune es un motor de base de datos de grafos de alto rendimiento creado específicamente. Este motor está diseñado para consultar el grafo con una latencia de milisegundos, manteniendo miles de millones de relaciones.
Las características principales son:
Otras dos opciones populares son ArangoDB y OrientDB.
ArangoDB es un sistema de base de datos de grafos NoSQL gratuito y de código abierto. Admite tres modelos de datos (grafos, documentos JSON y clave/valor), lo que significa que es multimodelo, con un único núcleo de base de datos y un lenguaje de consulta unificado, ArangoDB Query Language (AQL). La herramienta es predominantemente un lenguaje de consulta y permite combinar varios patrones de acceso a datos en una sola consulta.
OrientDB es un sistema de gestión de bases de datos NoSQL de código abierto escrito en Java. Similar a ArangoDB, OrientDB también es una base de datos multimodelo que admite grafos, documentos JSON, clave/valor y modelos de objetos; sin embargo, las relaciones se gestionan como en las bases de datos de grafos (es decir, conexiones directas entre registros). La herramienta dispone de un sólido sistema de perfiles de seguridad basado en usuarios y roles, y admite consultas con Gremlin junto con SQL extendido para atravesar grafos.
Nuestra guía sobre bases de datos NoSQL explora más razones por las que son tan útiles para la ciencia de datos.
Las redes de medios sociales se representan de forma natural con el modelo de datos de grafos. Aprovechar una base de datos de grafos simplifica el proceso de captura de relaciones, ya que no es necesario convertir los datos de un gráfico a una tabla y viceversa. El modelo de datos de grafos puede utilizarse directamente para representar cosas como los usuarios y sus relaciones.
Las relaciones entre categorías de información, como los amigos de una red, los intereses de un cliente y el historial de compras, pueden almacenarse en una base de datos de grafos. A continuación, se pueden hacer recomendaciones de productos a un usuario basadas en los productos adquiridos por otros usuarios con intereses o historiales de compra similares. En el escenario de amigos en una red, puedes utilizar la base de datos de grafos para descubrir usuarios con amigos en común que aún no estén conectados y recomendárselos entre sí.
Las bases de datos de grafos pueden utilizarse para almacenar relaciones entre transacciones, personas y otra información relevante que permita a los usuarios encontrar patrones comunes y crear aplicaciones capaces de detectar actividades fraudulentas. Por ejemplo, puede utilizarse para descubrir fácilmente patrones de relación indicativos de fraude, como múltiples individuos asociados a una misma dirección de correo electrónico o múltiples personas que comparten la misma dirección IP pero residen en direcciones físicas diferentes.
En esta guía, has aprendido que las bases de datos de grafos son plataformas especializadas de propósito único que se utilizan para crear y manipular datos de naturaleza asociativa y contextual. También aprendiste que, a pesar de la obvia obligación de almacenar datos y representar relaciones, las bases de datos relacionales y las gráficas son bastante diferentes en la forma de lograr su objetivo. Por ejemplo, las bases de datos relacionales utilizan SQL para sus operaciones, mientras que las bases de datos de grafos utilizan algoritmos transversales, que las hacen mucho más rápidas, incluso para grandes conjuntos de datos, y más adecuadas para datos con mucha interconexión.
Aprende más sobre bases de datos con estos recursos:
¡Comienza hoy tu viaje por las bases de datos!
Curso
Curso
Curso
blog
Tim Lu
12 min
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal