
programa
Ingeniero de Datos Asociado en SQL
30 h
La ingeniería de datos es un campo muy técnico, por lo que no es de extrañar que la mayor parte del proceso de entrevista incluya preguntas y ejercicios técnicos. En esta sección, trataremos diferentes tipos de preguntas y respuestas técnicas, centrándonos en preguntas para principiantes, en Python, en SQL, basadas en proyectos y sobre gestión.
Las entrevistas para ingenieros junior se centran en herramientas, Python y consultas SQL. También pueden incluir preguntas sobre gestión de bases de datos y procesos ETL, incluyendo retos de programación y pruebas para realizar en casa.
Cuando las empresas contratan a recién graduados, quieren asegurarse de que puedes manejar sus datos y sistemas de manera eficaz.
Existen tres esquemas principales de diseño de modelos de datos: estrella, copo de nieve y galaxia.
Ejemplo de esquema en estrella. Imagen de guru99
Ejemplo de esquema Snowflake. Imagen de guru99
Ejemplo de esquema Galaxy. Imagen de guru99
Al responder a esta pregunta, menciona las herramientas ETL que dominas y explica por qué elegiste herramientas específicas para determinados proyectos. Analiza las ventajas y desventajas de cada herramienta y cómo encajan en tu flujo de trabajo. Entre las herramientas de código abierto más populares se incluyen:
Si necesitas refrescar tus conocimientos sobre ETL, considera la posibilidad de realizar el curso Introducción a la ingeniería de datos.
La orquestación de datos es un proceso automatizado que permite acceder a datos sin procesar procedentes de múltiples fuentes, realizar tareas de limpieza, transformación y modelado de datos, y utilizarlos para tareas analíticas. Garantiza que los datos fluyan sin problemas entre los diferentes sistemas y etapas del procesamiento.
Entre las herramientas más populares para la orquestación de datos se incluyen:
La ingeniería analítica consiste en transformar datos procesados, aplicar modelos estadísticos y visualizarlos mediante informes y paneles de control.
Entre las herramientas más populares para la ingeniería analítica se incluyen:
Estas herramientas ayudan a acceder, transformar y visualizar datos para obtener información significativa y respaldar los procesos de toma de decisiones.
OLAP (procesamiento analítico en línea) analiza datos históricos y admite consultas complejas. Está optimizado para cargas de trabajo con gran volumen de lectura y se utiliza a menudo en almacenes de datos para tareas de inteligencia empresarial. OLTP ( procesamiento de transacciones en línea) está diseñado para gestionar datos transaccionales en tiempo real. Está optimizado para cargas de trabajo con gran volumen de escritura y se utiliza en bases de datos operativas para las operaciones comerciales diarias.
La principal diferencia radica en su finalidad: OLAP te ayuda en la toma de decisiones, mientras que OLTP te ayuda en las operaciones diarias.
Si aún tienes dudas, te recomiendo leer la entrada del blog OLTP vs OLAP.
Python es el lenguaje más popular en ingeniería de datos debido a su versatilidad y al rico ecosistema de bibliotecas disponibles para el procesamiento, análisis y automatización de datos. A continuación, te presentamos algunas preguntas relacionadas con Python que podrían plantearte en una entrevista de ingeniería de datos.
Las bibliotecas de procesamiento de datos más populares en Python incluyen:
Cada una de estas bibliotecas tiene ventajas e inconvenientes, y la elección depende de los requisitos específicos de los datos y de la magnitud de las tareas de procesamiento de datos.
El web scraping en Python suele implicar los siguientes pasos:
1. Accede a la página web utilizando la biblioteca requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')2. Extrae tablas e información utilizando BeautifulSoup:
tables = soup.find_all('table')3. Conviértelo a un formato estructurado utilizando pandas:
import pandas as pd
data = []
for table in tables:
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append(cols)
df = pd.DataFrame(data)4. Limpia los datos utilizando pandas y NumPy:
df.dropna(inplace=True) # Drop missing values5. Guarda los datos en forma de archivo CSV:
df.to_csv('scraped_data.csv', index=False)En algunos casos, pandas.read_html puede simplificar el proceso:
df_list = pd.read_html('http://example.com')
df = df_list[0] # Assuming the table of interest is the first oneEl manejo de grandes conjuntos de datos que no caben en la memoria requiere el uso de herramientas y técnicas diseñadas para el cálculo fuera del núcleo:
import dask.dataframe as dd
df = dd.read_csv('large_dataset.csv')from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('data_processing').getOrCreate()
df = spark.read.csv('large_dataset.csv', header=True, inferSchema=True)import pandas as pd
chunk_size = 10000
for chunk in pd.read_csv('large_dataset.csv', chunksize=chunk_size):
process(chunk) # Replace with your processing functionPara garantizar que el código Python sea eficiente y esté optimizado para el rendimiento, ten en cuenta las siguientes prácticas:
cProfile, line_profiler o memory_profiler para identificar cuellos de botella en tu código.import cProfile
cProfile.run('your_function()')numpy o pandas para operaciones vectorizadas en lugar de bucles.import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # Vectorized operationdata_dict = {'key1': 'value1', 'key2': 'value2'} # Faster lookups compared to listsfrom multiprocessing import Pool
def process_data(data_chunk):
# Your processing logic here
return processed_chunk
with Pool(processes=4) as pool:
results = pool.map(process_data, data_chunks)from functools import lru_cache
@lru_cache(maxsize=None)
def expensive_computation(x):
# Perform expensive computation
return resultLa integridad y la calidad de los datos son importantes para una ingeniería de datos fiable. Las mejores prácticas incluyen:
def validate_data(df):
assert df['age'].min() >= 0, "Age cannot be negative"
assert df['salary'].dtype == 'float64', "Salary should be a float"
# Additional checks...pandas para limpiar y preprocesar datos gestionando los valores perdidos, eliminando duplicados y corrigiendo errores. df.dropna(inplace=True) # Drop missing values
df.drop_duplicates(inplace=True) # Remove duplicatespytest.import pytest
def test_clean_data():
raw_data = pd.DataFrame({'age': [25, -3], 'salary': ['50k', '60k']})
clean_data = clean_data_function(raw_data)
assert clean_data['age'].min() >= 0
assert clean_data['salary'].dtype == 'float64' from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.email_operator import EmailOperator
# Define your DAG and tasks...El manejo de datos faltantes es una tarea común en la ingeniería de datos. Los enfoques incluyen:
df.dropna(inplace=True) df['column'].fillna(df['column'].mean(), inplace=True) df['column_missing'] = df['column'].isnull().astype(int) from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
df = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)Para gestionar los límites de velocidad de la API, existen estrategias como:
Ejemplo utilizando la biblioteca time de Python y el módulo requests:
import time
import requests
def fetch_data_with_rate_limit(url):
for attempt in range(5): # Retry up to 5 times
response = requests.get(url)
if response.status_code == 429: # Too many requests
time.sleep(2 ** attempt) # Exponential backoff
else:
return response.json()
raise Exception("Rate limit exceeded")Python es sin duda uno de los lenguajes más importantes en ingeniería de datos. Puedes perfeccionar tus habilidades con nuestro programa de ingeniero de datos en Python, que incluye un plan de estudios completo para que adquieras conocimientos sobre conceptos modernos de ingeniería de datos, lenguajes de programación, herramientas y marcos de trabajo.
La fase de programación SQL es una parte importante del proceso de contratación de ingenieros de datos. Practicar varios guiones sencillos y complejos puede ayudarte a prepararte. Los entrevistadores pueden pedirte que escribas consultas para el análisis de datos, expresiones de tabla comunes, clasificación, adición de subtotales y funciones temporales.
Los CTE se utilizan para simplificar uniones complejas y ejecutar subconsultas. Ayudan a que las consultas SQL sean más legibles y fáciles de mantener. A continuación se muestra un ejemplo de una CTE que muestra todos los estudiantes con especialización en Ciencias y calificación A:
SELECT *
FROM class
WHERE id IN (
SELECT DISTINCT id
FROM students
WHERE grade = "A"
AND major = "Science"
);Usando un CTE, la consulta queda así:
WITH temp AS (
SELECT id
FROM students
WHERE grade = "A"
AND major = "Science"
)
SELECT *
FROM class
WHERE id IN (SELECT id FROM temp);Los CTE se pueden utilizar para problemas más complejos y se pueden encadenar varios CTE.
Los ingenieros de datos suelen clasificar los valores en función de parámetros como las ventas y los beneficios. La función RANK() se utiliza para clasificar datos en función de una columna específica:
SELECT
id,
sales,
RANK() OVER (ORDER BY sales DESC) AS rank
FROM bill;Como alternativa, puedes utilizar DENSE_RANK(), que no omite los rangos posteriores si los valores son iguales.
Al igual que en Python, puedes crear funciones en SQL para que tus consultas sean más elegantes y evitar sentencias case repetitivas. Aquí tienes un ejemplo de una función temporal get_gender:
CREATE TEMPORARY FUNCTION get_gender(type VARCHAR) RETURNS VARCHAR AS (
CASE
WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
);
SELECT
name,
get_gender(type) AS gender
FROM class;Este enfoque hace que tu código SQL sea más limpio y fácil de mantener.
Se pueden añadir subtotales utilizando las funciones « GROUP BY » y « ROLLUP() ». Aquí tienes un ejemplo:
SELECT
department,
product,
SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP(department, product);Esta consulta te dará un subtotal para cada departamento y un total general al final.
El manejo de los datos faltantes es esencial para mantener la integridad de los datos. Los enfoques comunes incluyen:
COALESCE(): Esta función devuelve el primer valor no nulo de la lista.SELECT id, COALESCE(salary, 0) AS salary FROM employees;CASE »: Para manejar los valores perdidos de forma condicional. SELECT id,
CASE
WHEN salary IS NULL THEN 0
ELSE salary
END AS salary
FROM employees;La agregación de datos implica el uso de funciones agregadas como SUM(), AVG(), COUNT(), MIN() y MAX(). Aquí tienes un ejemplo:
SELECT department,
SUM(salary) AS total_salary,
AVG(salary) AS average_salary,
COUNT(*) AS employee_count
FROM employees
GROUP BY department;Para optimizar las consultas SQL, puedes:
SELECT * » especificando solo las columnas necesarias.EXPLAIN ANALYZE
SELECT customer_id, COUNT(order_id)
FROM orders
GROUP BY customer_id;Resolver ejercicios de programación SQL es la mejor manera de practicar y repasar conceptos olvidados. Puedes evaluar tus conocimientos de SQL realizando la prueba de análisis de datos en SQL de DataCamp (necesitarás una cuenta para acceder a esta evaluación).
Después de las rondas generales de entrevistas, normalmente pasarás a una fase técnica que consiste en retos de programación, resolución de problemas, diseño de sistemas de bases de datos en una pizarra, un examen para hacer en casa y preguntas analíticas.
Esta etapa puede ser bastante intensa, por lo que conocer algunas de las preguntas y respuestas habituales en las entrevistas de ingeniería de datos puede ayudarte a superar la entrevista con éxito.
Esta respuesta debería ser fácil si has trabajado anteriormente en un proyecto de ingeniería de datos como estudiante o profesional. Dicho esto, prepararse con antelación siempre es útil. A continuación te indicamos cómo estructurar tu respuesta:
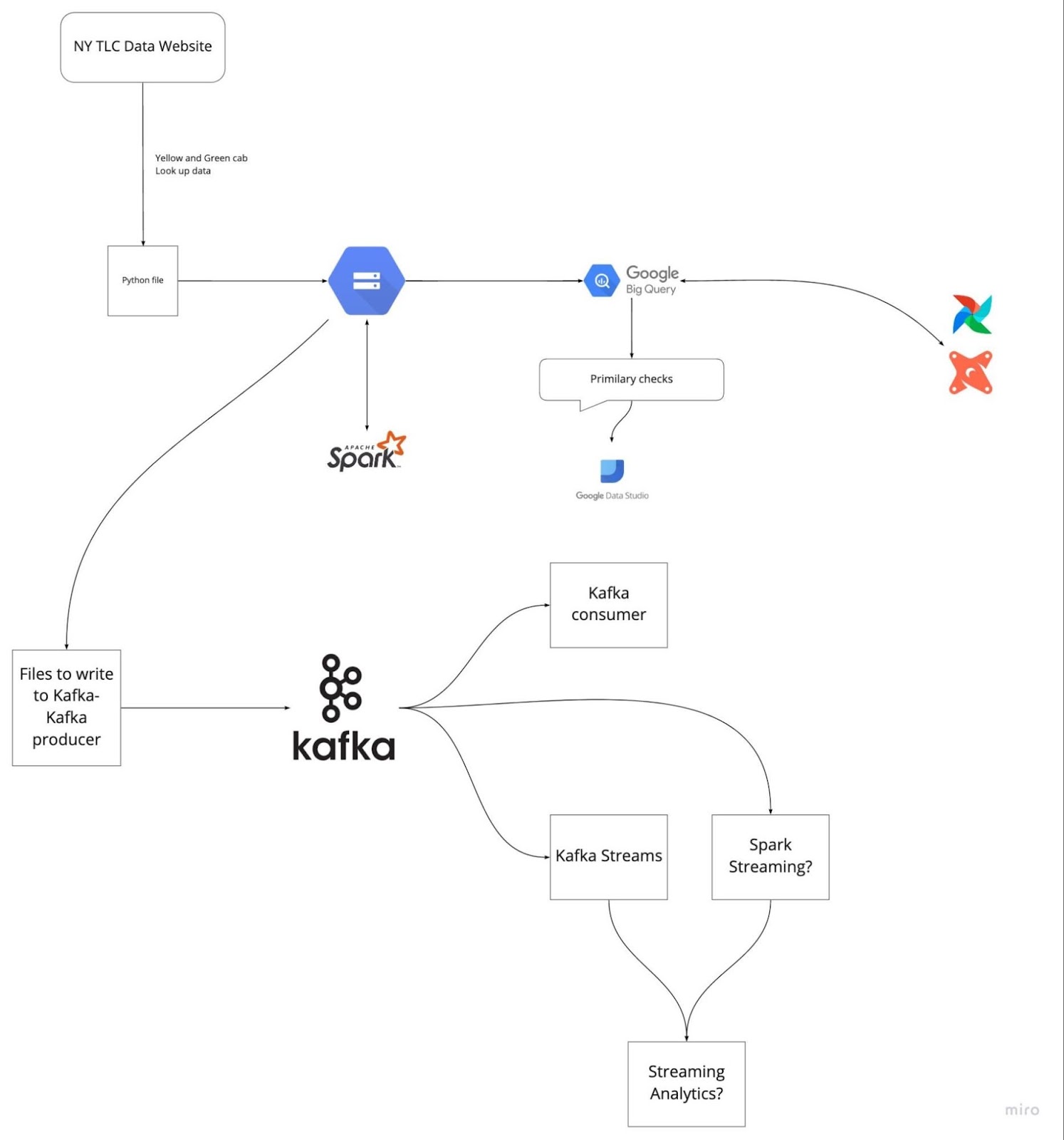
Imagen de DataTalksClub/data-engineering-zoomcamp
Prepararte con antelación revisando los últimos cinco proyectos en los que has trabajado puede ayudarte a evitar quedarte bloqueado durante la entrevista. Comprende la descripción del problema y las soluciones que implementaste. Practica explicando cada paso de forma clara y concisa.
En el caso de los puestos de director de ingeniería, las preguntas suelen estar relacionadas con la toma de decisiones, la comprensión del negocio, la gestión y el mantenimiento de conjuntos de datos, el cumplimiento normativo y las políticas de seguridad.
Un almacén de datos proporciona datos históricos para tareas de análisis de datos y toma de decisiones. Admite el procesamiento analítico de gran volumen, como el procesamiento analítico en línea (OLAP). Los almacenes de datos están diseñados para gestionar consultas complejas que acceden a múltiples filas y están optimizados para operaciones con un uso intensivo de lectura. Admiten varios usuarios simultáneos y están diseñados para recuperar grandes volúmenes de datos de forma rápida y eficiente.
Los sistemas de gestión de bases de datos operativas (OLTP) gestionan conjuntos de datos dinámicos en tiempo real. Admiten el procesamiento de grandes volúmenes de transacciones para miles de clientes simultáneos, lo que los hace adecuados para las operaciones diarias. Los datos suelen consistir en información actualizada sobre transacciones y operaciones comerciales. Los sistemas OLTP están optimizados para operaciones con gran volumen de escritura y procesamiento rápido de consultas.
La gestión de desastres es responsabilidad de un gerente de ingeniería de datos. Un plan de recuperación ante desastres garantiza que los sistemas de datos puedan restaurarse y seguir funcionando en caso de un ciberataque, un fallo de hardware, un desastre natural u otros eventos catastróficos. Entre los aspectos relevantes se incluyen:
Como gerente de ingeniería de datos, la toma de decisiones implica equilibrar las consideraciones técnicas con los objetivos comerciales. Algunos enfoques incluyen:
El cumplimiento de la normativa de protección de datos implica varias prácticas, por ejemplo:
Al hablar de un proyecto complejo, puedes centrarte en los siguientes aspectos:
La evaluación y la implementación de nuevas tecnologías de datos implica:
Una forma eficaz de priorizar las tareas se basa en su impacto en los objetivos empresariales y en su urgencia. Puedes utilizar marcos de trabajo como la matriz de Eisenhower para clasificar las tareas en cuatro cuadrantes: urgentes e importantes, importantes pero no urgentes, urgentes pero no importantes, y ninguna de las dos cosas. Además, comunícate con las partes interesadas para alinear las prioridades y garantizar que el equipo se centre en actividades de alto valor.
En esta sección, exploramos las preguntas más frecuentes en las entrevistas de ingeniería de datos realizadas por los responsables de Facebook, Amazon y Google para puestos de ingeniería de datos.
Un clúster Kafka consta de varios brokers que distribuyen datos entre múltiples instancias. Esta arquitectura proporciona escalabilidad y tolerancia a fallos sin tiempo de inactividad. Si el clúster principal deja de funcionar, otros clústeres de Kafka pueden prestar los mismos servicios, lo que garantiza una alta disponibilidad.
La arquitectura del clúster Kafka comprende temas, corredores, ZooKeeper, productores y consumidores. Maneja de manera eficiente los flujos de datos para aplicaciones de big data, lo que permite la creación de aplicaciones robustas basadas en datos.
Apache Airflow te permite gestionar y programar canalizaciones para flujos de trabajo analíticos, gestión de almacenes de datos y transformación y modelado de datos. Proporciona:
Para determinar la validez de una dirección IP, puedes dividir la cadena en «.» y crear varias comprobaciones para validar cada segmento. Aquí tienes una función Python para lograrlo:
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if len(i) > 3 or int(i) < 0 or int(i) > 255:
return False
if len(i) > 1 and int(i) == 0:
return False
if len(i) > 1 and int(i) != 0 and i[0] == '0':
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"
print(is_valid(A)) # True
print(is_valid(B)) # FalseHadoop funciona principalmente en tres modos:
Para gestionar los duplicados en SQL, puedes utilizar la palabra clave « DISTINCT » (mantener duplicados) o eliminar las filas duplicadas utilizando « ROWID » (mantener duplicados) con la función « MAX » (mantener duplicados) o « MIN » (mantener duplicados). Aquí hay algunos ejemplos:
Usando DISTINCT:
SELECT DISTINCT Name, ADDRESS
FROM CUSTOMERS
ORDER BY Name;Eliminación de duplicados con ROWID:
DELETE FROM Employee
WHERE ROWID NOT IN (
SELECT MAX(ROWID)
FROM Employee
GROUP BY Name, ADDRESS
);Este problema habitual de codificación se puede resolver utilizando un enfoque matemático:
def search_missing_number(list_num):
n = len(list_num)
# Check if the first or last number is missing
if list_num[0] != 1:
return 1
if list_num[-1] != n + 1:
return n + 1
# Calculate the sum of the first n+1 natural numbers
total = (n + 1) * (n + 2) // 2
# Calculate the sum of all elements in the list
sum_of_L = sum(list_num)
# Return the difference, which is the missing number
return total - sum_of_L
# Validation
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list)) # The missing number is 12Antes de acudir a una entrevista, debes repasar todos los conceptos y términos estándar utilizados en ingeniería de datos. Estas son algunas de las áreas más importantes en las que debes centrarte:
Prepararse para una entrevista de ingeniería de datos puede ser todo un reto, pero con los recursos adecuados y la práctica necesaria, puedes destacar y conseguir el trabajo de tus sueños. Para mejorar aún más tus habilidades y conocimientos, consulta estos valiosos recursos:
Aprovecha estos cursos para consolidar tus conocimientos básicos y mantenerte a la vanguardia en tu carrera como ingeniero de datos. ¡Buena suerte con tus entrevistas!
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
programa
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
9 min
blog
Matt Crabtree
12 min
blog
Javier Canales Luna
15 min
