Vivimos tiempos extraordinarios en los que los proyectos de código abierto impulsados por comunidades dedicadas rivalizan con las capacidades de las costosas soluciones propietarias de las grandes empresas. Entre los avances notables, encontramos modelos lingüísticos más pequeños pero muy eficientes, como Vicuna, Koala, Alpaca y StableLM, que requieren un mínimo de recursos informáticos a la vez que ofrecen resultados a la par que ChatGPT. Lo que les une es que se basan en los modelos LLaMA de Meta AI.
Lee 12 Alternativas de código abierto a GPT-4 para conocer otras tecnologías populares de desarrollo en código abierto.
En este post, conoceremos los modelos LLaMA de Meta AI, exploraremos su funcionalidad, accederemos a ellos a través de la biblioteca de transformadores, compararemos su rendimiento y discutiremos sus retos y limitaciones. Desde la redacción original de este artículo, hemos visto el lanzamiento tanto de LLaMA 2 como de LLaMA 3, y puedes encontrar más detalles sobre cada uno de ellos en nuestros artículos separados.
¿Qué es el LLaMA?
LLaMA(Large Language Model Meta AI) es una colección de modelos lingüísticos básicos de última generación que van de 7B a 65B parámetros. Estos modelos tienen un tamaño más reducido y, al mismo tiempo, ofrecen un rendimiento excepcional, lo que reduce significativamente la potencia y los recursos informáticos necesarios para experimentar con metodologías novedosas, validar el trabajo de otros y explorar casos de uso innovadores.
Los modelos de base se entrenaron en grandes conjuntos de datos sin etiquetar, lo que los hace ideales para afinarlos en diversas tareas. El modelo se entrenó con la siguiente fuente:
- 67,0% CommonCrawl
- 15.0% C4
- 4,5% GitHub
- 4,5% Wikipedia
- 4,5% Libros
- 2,5% ArXiv
- 2,0% StackExchange
La gran variedad de conjuntos de datos ha permitido a los modelos alcanzar un rendimiento de vanguardia que rivaliza con los modelos de mayor rendimiento, a saber, Chinchilla-70B y PaLM-540B.
Obtén una comprensión completa de la evolución de los modelos de OpenAI, incluidos GPT-1, GPT-2, GPT-3 y el estado actual del modelo GPT-4 leyendo: ¿Qué es la GPT-4 y por qué es importante?
¿Cómo funciona el LLaMA de Meta?
LLaMA, un modelo de lenguaje autorregresivo, está construido sobre la arquitectura del transformador. Al igual que otros modelos lingüísticos destacados, LLaMA funciona tomando una secuencia de palabras como entrada y prediciendo la palabra siguiente, generando texto recursivamente.
Lo que distingue al LLaMA es su formación en una amplia gama de datos de texto disponibles públicamente que abarcan numerosas lenguas, como el búlgaro, catalán, checo, danés, alemán, inglés, español, francés, croata, húngaro, italiano, neerlandés, polaco, portugués, rumano, ruso, esloveno, serbio, sueco y ucraniano. A partir de 2024, se ha introducido el LLaMA 2, con una arquitectura y unas metodologías de formación mejoradas, que aumentan aún más sus capacidades multilingües y su eficacia.
Los modelos LLaMA están disponibles en varios tamaños: Parámetros 7B, 13B, 33B y 65B, y puedes acceder a ellos en Hugging Face (modelos LLaMA convertidos para funcionar con Transformers) o en el repositorio oficial facebookresearch/llama.
Primeros pasos con los modelos LLaMA
El código oficial de inferencia está disponible en el repositorio facebookresearch/llama, pero para simplificar las cosas, utilizaremos el módulo LLaMA de la biblioteca `transformadores` de Cara Abrazada para cargar el modelo y generar el texto.
1. Instala todas las Bibliotecas Python necesarias para ejecutar el módulo.
Nota: estamos utilizando Google Colab para ejecutar la inferencia LLaMA.
%%capture
%pip install transformers SentencePiece accelerate2. Carga los tokens LLaMA y los pesos del modelo.
Nota: "decapoda-research/llama-7b-hf" no es el peso oficial del modelo. Decapoda Research ha convertido los pesos de los modelos originales para que funcionen con Transformers.
import transformers, torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
tokenizer = LlamaTokenizer.from_pretrained("decapoda-research/llama-7b-hf")
model = LlamaForCausalLM.from_pretrained(
"decapoda-research/llama-7b-hf",
load_in_8bit=False,
torch_dtype=torch.float16,
device_map="auto",
)3. Escribe la pregunta.
4. Convertir el texto en tokens.
5. Crear configuración de generación de modelos.
6. Utiliza los tokens y la configuración de generación para generar el texto de salida.
7. Descodificar la impresión de la respuesta.
instruction = "How old is the universe?"
inputs = tokenizer(
f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {instruction}
### Response:""",
return_tensors="pt",
)
input_ids = inputs["input_ids"].to("cuda")
generation_config = transformers.GenerationConfig(
do_sample=True,
temperature=0.1,
top_p=0.75,
top_k=80,
repetition_penalty=1.5,
max_new_tokens=128,
)
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
attention_mask=torch.ones_like(input_ids),
generation_config=generation_config,
)
output_text = tokenizer.decode(
generation_output[0].cuda(), skip_special_tokens=True
).strip()
print(output_text)Salida:
El modelo no sólo produce una estimación precisa de 13.000 millones de años para la edad del universo, sino que también revela el razonamiento que subyace a su cálculo.
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction: How old is the universe?
### Response: The age of our Universe can be calculated by measuring
how fast it expands and then using this information to calculate its
size at different points in time, which allows us determine when
things happened relative to each other (evolutionary biology). This
method has been used for many years now with great success; however
there are still some uncertainties about what exactly we're seeing
because light takes so long travel from distant galaxies back here on
Earth! So while scientists have determined roughly 13 billion
year-old as being correct they don't know if their calculations were
off or not due to these limitations mentioned aboveAdemás, la transformers puede utilizarse para afinar diversas tareas y conjuntos de datos, lo que permite una mejora significativa tanto de la precisión como del rendimiento.
Si te interesa el lado más práctico del desarrollo de código abierto, consulta el artículo 5 Proyectos Construidos con Modelos Generativos para inspirarte.
¿En qué se diferencia el LLaMA de otros modelos de IA?
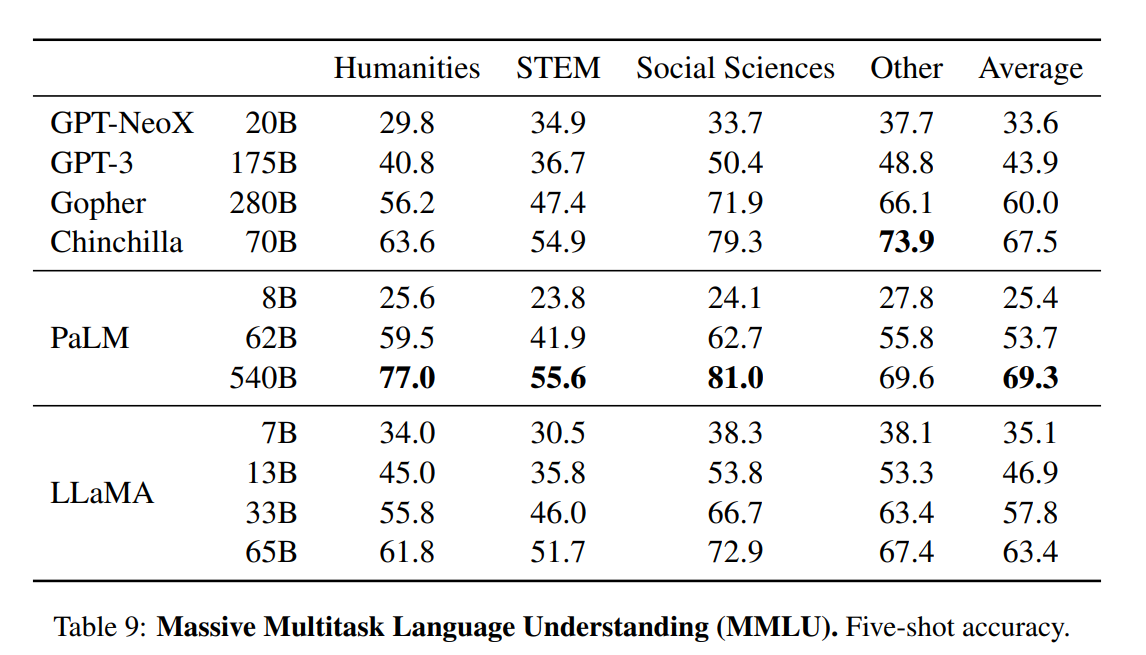
El artículo presenta una evaluación exhaustiva de los modelos LLaMA, comparándolos con otros modelos lingüísticos del estado de la técnica, como GPT-3, GPT-NeoX, Gopher, Chinchilla y PaLM. Las pruebas de referencia incluyen razonamiento de sentido común, trivialidades, comprensión lectora, respuesta a preguntas, razonamiento matemático, generación de código y conocimientos generales del dominio.
- Razonamiento de sentido común. El modelo LLaMA-65B ha superado a las arquitecturas del modelo SOTA en las pruebas de razonamiento PIQA, SIQA y OpenBookQA. Incluso el modelo 33B, más pequeño, ha superado a todos ellos en ARC, fácil y desafiante.
- Respuestas a preguntas y trivialidades a libro cerrado. La prueba mide la capacidad de LLM para interpretar y responder a preguntas realistas y humanas. El modelo LLaMA ha superado sistemáticamente a GPT3, Gopher, Chinchilla y PaLM en las pruebas comparativas de Preguntas Naturales y TrivialQA.
- Comprensión lectora. Utiliza las pruebas de referencia RACE-middle y RACE-high. Los modelos LLaMA han superado al GPT-3 y tienen un rendimiento similar al PaLM 540B.
- Razonamiento Matemático. LLaMA no se afinó con ningún dato matemático, y su rendimiento fue bastante inferior al de Minerva.
- Generación de código. Utiliza las pruebas de referencia HumanEval y MBPP. LLaMA ha superado tanto a LAMDA como a PaLM en HumanEval@100, MBP@1 y MBP@80.
Conocimientos de dominio. Los modelos LLaMA han obtenido peores resultados en comparación con el modelo masivo de parámetros PaLM 540B. PaLM tiene un amplio conocimiento del dominio debido a un mayor número de parámetros.
Retos y limitaciones del LLaMA
Al igual que otros Grandes Modelos Lingüísticos, LLaMA también sufre de alucinación. Puede generar información objetivamente errónea.
Aparte de eso:
- Dado que la mayor parte de nuestro conjunto de datos está formado por texto en inglés, es importante señalar que el rendimiento del modelo en otras lenguas puede ser comparativamente inferior.
- La finalidad principal de los modelos LLaMA es para aplicaciones de investigación (licencia no comercial). La publicación de estos modelos pretende facilitar a los investigadores la evaluación y el tratamiento de cuestiones como los sesgos, los riesgos, la generación de contenidos tóxicos o nocivos y las alucinaciones.
- El LLaMA es un modelo base, y no debe utilizarse para crear aplicaciones sin evaluar y mitigar los riesgos.
- No es bueno en razonamiento matemático y conocimiento del dominio.
Para conocer mejor el desarrollo de código cerrado, lee Lo último sobre OpenAI, Google AI y lo que significa para la Ciencia de Datos. El blog habla de las tecnologías disruptivas del lenguaje, la visión y la multimodalidad y de cómo nos están haciendo más productivos y eficaces.
Con la posterior publicación de LLaMA 2 y LLaMA 3, se han identificado nuevos retos y limitaciones. Se han introducido mejoras en áreas como las limitaciones de longitud de contexto y, con métodos como el ajuste fino, cada vez es más posible superar las dificultades con tareas que requieren un profundo conocimiento específico del dominio. Como siempre, la comunidad está trabajando activamente en estos aspectos para mejorar la solidez y aplicabilidad de estos modelos.
Conclusión
Los modelos LLaMA han desencadenado una ola revolucionaria en el desarrollo de la IA de código abierto. Con el modelo base más pequeño LLaMA-13B superando las capacidades de GPT-3 y LLaMA-65B, y demostrando un rendimiento comparable al de modelos punteros como Chinchilla-70B y PaLM-540B, estos avances han desvelado el potencial para conseguir resultados punteros mediante el entrenamiento con datos disponibles públicamente, todo ello utilizando unos recursos informáticos mínimos.
Además, el artículo destaca la mejora potencial del rendimiento que se consigue ajustando los modelos LLaMA mediante instrucciones. En particular, los modelos Vicuna y Stanford Alpaca, afinados a partir de LLaMA en demostraciones de seguimiento de instrucciones, han mostrado resultados similares a ChatGPT y Bard.
Si te interesa aprovechar los grandes modelos lingüísticos para tus proyectos de ciencia de datos, consulta Guía de uso de ChatGPT para proyectos de ciencia de datos. También puedes mejorar tus habilidades en ingeniería de prontos revisando ChatGPT Cheat Sheets for Data Science.


