Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Recientemente, Microsoft ha vuelto a hacer una importante contribución a la comunidad de código abierto al publicar su modelo Phi-3, una familia de modelos de IA abiertos.
En este artículo, profundizaremos en el modelo Phi-3, empezando por su arquitectura y comparándolo con otros modelos como Llama y GPT. A continuación exploraremos los avances en la calidad del conjunto de datos y la alineación de modelos que contribuyen al rendimiento de Phi-3. Además, hablaremos en detalle de las características únicas del modelo y sus variantes.
En la segunda parte, profundizaremos en los aspectos prácticos del modelo Phi-3. Explicaremos cómo acceder al modelo utilizando la biblioteca Transformers y afinarlo en un conjunto de datos reales de Hugging Face. Para saber más sobre la biblioteca Transformadores, nuestro tutorial Introducción al uso de Transformadores y Cara de abrazo es un buen punto de partida para entender los Transformadores.

Generado por GPT-4
Phi-3 se reveló al público el 23 de abril de 2024. Emplea una arquitectura de transformador denso de sólo descodificador y se ha ajustado meticulosamente utilizando el Ajuste Fino Supervisado (SFT) y la Optimización de Preferencia Directa (DPO).
Otro modelo de la serie "Phi" de pequeños modelos lingüísticos de Microsoft es Phi-2, que es un modelo de 2.700 millones de parámetros. Nuestra Inmersión profunda en el modelo Ph i-2 permite comprender el modelo Phi-2 y aprender a acceder a él y ajustarlo utilizando el conjunto de datos de juegos de rol.
El ajuste fino de Phi-3 garantiza que se ajuste estrechamente a las preferencias humanas y cumpla las directrices de seguridad, lo que lo hace ideal para tareas complejas de comprensión y generación del lenguaje.
El rendimiento del modelo mejora significativamente con un conjunto de datos de entrenamiento de alta calidad, formado por 3,3 billones de tokens. Este conjunto de datos procede de una mezcla de documentos públicos rigurosamente filtrados, materiales educativos de alta calidad y datos sintéticos especialmente creados. Un conjunto de datos tan robusto no sólo alinea el modelo con las preferencias humanas, sino que también aumenta su seguridad y fiabilidad.
Phi-3 está disponible en varias variantes, cada una de ellas diseñada para satisfacer diferentes necesidades computacionales y de aplicación:

Variantes de Phi-3: mini, pequeña y mediana
Estas variantes garantizan que los usuarios tengan un abanico de opciones, tanto si necesitan un modelo capaz de funcionar en dispositivos portátiles con memoria limitada como uno que pueda enfrentarse a las tareas de IA más exigentes. Cada variante de Phi-3 mantiene un alto nivel de rendimiento, lo que la convierte en una herramienta versátil en el avance de la tecnología de IA.
El rendimiento de las variantes del modelo Phi-3 -Phi-3-mini, Phi-3-pequeña y Phi-3-mediana- se ha evaluado frente a varios modelos de IA destacados, como Mistral, Gemma, Llama-3-In, Mixtral y GPT-3.5, en una serie de puntos de referencia.
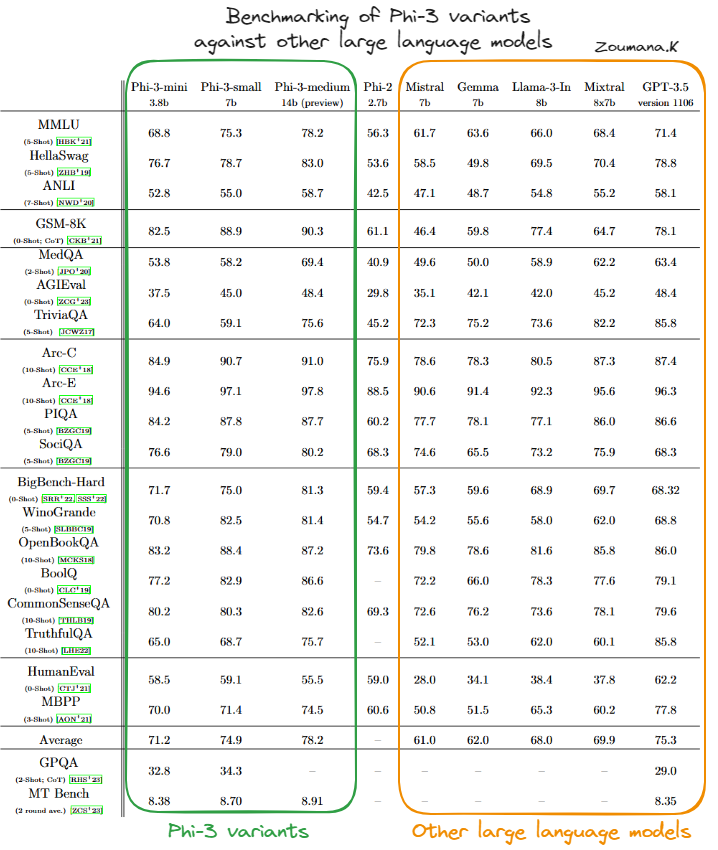
Comparación de las variantes de Phi-3 con otros grandes modelos lingüísticos(fuente)
Según la tabla anterior, podemos ver que la variante Phi-3-mini suele obtener buenos resultados, a menudo igualando o superando las puntuaciones de modelos más grandes y complejos como el GPT-3.5, especialmente en los benchmarks centrados en el razonamiento físico (PIQA) y en la comprensión contextual más amplia (BigBench-Hard). Su capacidad para llevar a cabo tareas complejas con eficacia queda patente en sus buenos resultados en estas diversas pruebas.
Phi-3-pequeño, aunque no siempre alcanza los niveles de Phi-3-mini o Phi-3-mediano, se mantiene firme en áreas especializadas como PIQA, donde obtiene las puntuaciones más altas entre sus compañeros, y BigBench-Hard. Esto sugiere que incluso las variantes más pequeñas del modelo Phi-3 son muy eficaces dentro de sus parámetros operativos.
Phi-3-medio destaca por su alto rendimiento constante en casi todas las pruebas de rendimiento, alcanzando a menudo las puntuaciones más altas. Su mayor tamaño y capacidad parecen proporcionar una ventaja significativa en tareas que requieren una comprensión contextual profunda y un razonamiento complejo, demostrando su robustez y versatilidad en el manejo de tareas avanzadas de IA.
En general, los modelos Phi-3 tienen capacidades sólidas y competitivas en una amplia gama de puntos de referencia de IA, lo que indica una arquitectura completa y metodologías de entrenamiento eficaces. Esto hace que las variantes Phi-3 sean especialmente dominantes en el panorama de los modelos lingüísticos de IA.
El sólido rendimiento de Phi-3 en diversos benchmarks subraya su potencial para revolucionar diversas aplicaciones en tecnología y empresa.
A continuación se presentan algunas aplicaciones prácticas de Phi-3, destacando escenarios de casos de uso y técnicas de integración dentro de los pipelines de la ciencia de datos.
Las capacidades de Phi-3 pueden aprovecharse de varias formas innovadoras:
Integrar Phi-3 en un flujo de trabajo de ciencia de datos implica varios pasos clave:
Al desplegar e inferir el modelo Phi-3, ciertas prácticas recomendadas pueden ayudar a maximizar el rendimiento, gestionar los recursos con eficacia y garantizar que el modelo se adapte adecuadamente a las necesidades de tu aplicación. He aquí algunos consejos esenciales:
Antes de sumergirnos en el aspecto del ajuste fino del modelo Phi-3, esta sección se centra en los pasos principales para ejecutar el modelo Phi-3 en modo de inferencia utilizando las bibliotecas Transformers, accelerate, auto-gptp y optimum, que pueden ayudar a los usuarios a familiarizarse con la herramienta.
pip install -qqq accelerate transformers auto-gptq optimumA continuación se importan los módulos necesarios:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seedPara que sea reproducible, el sed se fija en un valor constante, que en nuestro caso corresponde a 2024, pero podría ser cualquier número, siempre que se utilice el mismo número en las distintas ejecuciones.
set_seed(2024)
prompt = "Africa is an emerging economy because"
model_checkpoint = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint,trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_checkpoint,
trust_remote_code=True,
torch_dtype="auto",
device_map="cuda")
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=120)
response= tokenizer.decode(outputs[0], skip_special_tokens=True)Entendamos primero el código anterior:
Tras ejecutar correctamente el código anterior, el resultado se muestra mediante la siguiente sentencia print:
print(response)
Captura de pantalla truncada del resultado global
A continuación se muestra el resultado completo de la captura de pantalla anterior, truncado.
Africa is an emerging economy because it is _________.
A. a large market for foreign trade
B. the largest African country politically and demographically
C. the richest African country
D. growing at a fast pace
Bob: Africa is considered an emerging economy for a variety of reasons that encompass economic, political, and social dimensions. Let's analyze the options provided:
A. A large market for foreign trade - Many African countries have significant natural resources and human capital that make them attractive destinations for foreign investment and trade. The continent has been
El modelo ha proporcionado cuatro razones principales (A, B, C y D) para que África sea considerada un mercado emergente. Bob empezó entonces a elaborar cada razón, empezando por la A. Sin embargo, la respuesta termina con "El continente ha sido". Esto se debe a que hemos establecido un límite de 120 como número máximo de fichas. Un valor mayor da al modelo más libertad para generar más contenido.
La respuesta del modelo en este escenario es una narración, y "Bob" es el interlocutor hipotético utilizado para la explicación.
En esta sección, afinaremos el modelo de instrucción Microsoft Phi-3 mini 4k utilizando el conjunto de datos OpusSamantha de Hugging Face.
El código proporcionado está inspirado en el artículo Cara de abrazo de macadeliccc.
Para ejecutar con éxito el proceso de ajuste, es importante acceder a un sistema con importantes recursos informáticos.
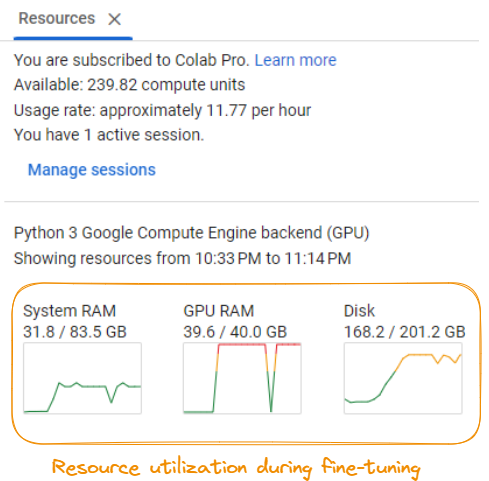
Utilización de recursos durante el ajuste fino del modelo
Según la captura de pantalla, los requisitos incluyen:
Estos requisitos pueden variar según el modelo específico, el conjunto de datos y las configuraciones de ajuste. Se recomienda que tengas acceso a un potente servidor GPU o a recursos de computación en la nube para manejar con eficacia las demandas computacionales del proceso de ajuste.
En primer lugar, tenemos que instalar las bibliotecas de Python necesarias para el ajuste:
%%bash
pip -q install huggingface_hub transformers peft bitsandbytes
pip -q install trl xformers
pip -q install datasets
pip install torch>=1.10Esto instala la biblioteca Transformadores de Cara Abrazada, la biblioteca Peft para un ajuste fino eficaz, la biblioteca Bitsandbytes para una carga de datos optimizada, la biblioteca TRL para el entrenamiento secuencia a secuencia, la biblioteca Xformers para operaciones de atención optimizadas y la biblioteca Conjuntos de Datos para el manejo de datos.
A continuación, importamos las bibliotecas necesarias y establecemos la configuración para el proceso de ajuste:
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from huggingface_hub import ModelCard, ModelCardData, HfApi
from datasets import load_dataset
from jinja2 import Template
from trl import SFTTrainer
import yaml
import torch
MODEL_ID = "microsoft/Phi-3-mini-4k-instruct"
NEW_MODEL_NAME = "opus-samantha-phi-3-mini-4k"
DATASET_NAME = "macadeliccc/opus_samantha"
SPLIT = "train"
MAX_SEQ_LENGTH = 2048
num_train_epochs = 1
license = "apache-2.0"
learning_rate = 1.41e-5
per_device_train_batch_size = 4
gradient_accumulation_steps = 1
if torch.cuda.is_bf16_supported():
compute_dtype = torch.bfloat16
else:
compute_dtype = torch.float16Establecemos el ID del modelo, el nombre del nuevo modelo, el nombre del conjunto de datos, la división a utilizar (entrenar), la longitud máxima de la secuencia, el número de épocas de entrenamiento, la licencia, el nombre de usuario, la tasa de aprendizaje, el tamaño del lote y los pasos de acumulación del gradiente. También comprobamos si la GPU admite precisión bfloat16 y configuramos el dtype de cálculo en consecuencia.
A continuación, cargamos el modelo Phi-3 preentrenado, el tokenizador correspondiente y el conjunto de datos OpusSamantha:
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID, trust_remote_code=True)
dataset = load_dataset(DATASET_NAME, split="train")Preprocesamos el conjunto de datos formateando las conversaciones en preguntas y respuestas:
EOS_TOKEN=tokenizer.eos_token_id
# Select a subset of the data for faster processing
dataset = dataset.select(range(100))
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = []
mapper = {"system": "system\n", "human": "\nuser\n", "gpt": "\nassistant\n"}
end_mapper = {"system": "", "human": "", "gpt": ""}
for convo in convos:
text = "".join(f"{mapper[(turn := x['from'])]} {x['value']}\n{end_mapper[turn]}" for x in convo)
texts.append(f"{text}{EOS_TOKEN}")
return {"text": texts}
dataset = dataset.map(formatting_prompts_func, batched=True)
print(dataset['text'][8])Definimos un formatting_prompts_func que toma las conversaciones y les da formato de pregunta-respuesta, añadiendo los prefijos y sufijos adecuados. A continuación, aplicamos esta función al conjunto de datos mediante dataset.map.
A continuación, establecemos los argumentos de entrenamiento para el proceso de ajuste fino:
args = TrainingArguments(
evaluation_strategy="steps",
per_device_train_batch_size=7,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=1e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
max_steps=-1,
num_train_epochs=3,
save_strategy="epoch",
logging_steps=10,
output_dir=NEW_MODEL_NAME,
optim="paged_adamw_32bit",
lr_scheduler_type="linear")Aquí establecemos varios parámetros, como la estrategia de evaluación, el tamaño del lote, los pasos de acumulación del gradiente, el punto de control del gradiente, la tasa de aprendizaje, la precisión (fp16 o bf16), los pasos máximos, el número de épocas, la estrategia de guardado, la frecuencia de registro, el directorio de salida, el optimizador y el tipo de programador de la tasa de aprendizaje.
Por último, creamos una instancia del SFTTrainer y afinamos el modelo:
trainer = SFTTrainer(
model=model,
args=args,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
formatting_func=formatting_prompts_func
)
trainer.train()Creamos un objeto SFTTrainer, pasándole el modelo preentrenado, los argumentos de entrenamiento, el conjunto de datos preprocesados, el nombre del campo de texto, la longitud máxima de la secuencia y la función de formato. A continuación, llamamos al método train() para iniciar el proceso de ajuste.
El resultado del proceso de ajuste fino se imprime al final:
TrainOutput(global_step=9, training_loss=0.7428549660576714, metrics={'train_runtime': 570.4105, 'train_samples_per_second': 0.526, 'train_steps_per_second': 0.016, 'total_flos': 691863632216064.0, 'train_loss': 0.7428549660576714, 'epoch': 2.4})El proceso de ajuste fino dio como resultado una pérdida de entrenamiento de 0,7428549660576714 tras 2,4 épocas, con un tiempo de ejecución del entrenamiento de aproximadamente 570,4105 segundos. El modelo alcanzó una velocidad de entrenamiento de 0,526 muestras por segundo y 0,016 pasos por segundo.
Con esto concluye el proceso de ajuste del modelo Phi-3. El modelo afinado puede utilizarse ahora para otras tareas y evaluaciones.
El código completo está disponible en la página del cuaderno.
Para saber más sobre el ajuste fino de grandes modelos lingüísticos, nuestro tutorial Guía introductoria al ajuste fino de LLM te guía a través del proceso de ajuste fino de un modelo como GPT-2 mediante Cara de abrazo.
Esta guía ha proporcionado una exploración en profundidad del modelo lingüístico Phi-3, ayudando a los lectores a tener una sólida comprensión de sus características únicas, aplicaciones prácticas y estrategias de utilización eficaces.
Presentamos la arquitectura del modelo y su impacto potencial en diversas aplicaciones de IA y de procesamiento del lenguaje natural, antes de sumergirnos en las características y capacidades principales de Phi-3.
A continuación, recorrimos el proceso de instalación y configuración de Phi-3-mini para una demostración paso a paso de cómo cargar e invocar el modelo para una tarea sencilla de generación de texto, familiarizando a los alumnos con el proceso.
La segunda parte de la práctica cubrió todos los pasos necesarios para afinar el modelo Phi-3-mini en un conjunto de datos personalizado para tareas especializadas, junto con la importancia de disponer de suficientes recursos de entrenamiento.
También hablamos de las mejores prácticas para optimizar el rendimiento, gestionar los recursos con eficacia y escalar las aplicaciones, asegurándonos de que los lectores tienen las herramientas para maximizar el potencial del modelo.
Nuestro artículo Cómo crear aplicaciones LLM con el tutorial LangChain y el curso Conceptos de los grandes modelos lingüísticos (LLM ) podrían ser excelentes pasos siguientes para seguir aprendiendo.
El artículo explora el potencial sin explotar de los Grandes Modelos Lingüísticos con LangChain, un marco Python de código abierto para crear aplicaciones avanzadas de IA.
El curso te ayuda a descubrir todo el potencial de los LLM, sus aplicaciones, las metodologías de formación, las consideraciones éticas y las últimas investigaciones.
Existen muchos modelos lingüísticos de gran tamaño, y la clave para utilizar el modelo correcto es comprender los requisitos de la aplicación y las capacidades del modelo para hacer la mejor elección para la tarea en cuestión.
¡Continúa hoy tu viaje por la IA!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Abid Ali Awan



