
Course
Generative AI Concepts
2 hr
106.6K
The release of GPT-4 marked a significant milestone in the field of artificial intelligence, particularly in natural language processing. In this article, we offer a thorough analysis of its advanced capabilities and delve into the history and development of Generative Pre-trained Transformers (GPT), as well as the new capabilities that GPT-4 unlocks.
Check out our article on GPT-4o, the latest iteration of GPT, to find out more. Additionally, learn more about Large Language Models like GPT-4 in our AI Fundamentals Track.
Generative Pre-trained Transformers (GPT) are a type of deep learning model used to generate human-like text. Common uses include
There are endless applications for GPT models, and you can even fine-tune them on specific data to create even better results. By using transformers, you will be saving costs on computing, time, and other resources.
The current AI revolution for natural language only became possible with the invention of transformer models, starting with Google's BERT in 2017. Before this, text generation was performed with other deep learning models, such as recursive neural networks (RNNs) and long short-term memory neural networks (LSTMs). These performed well for outputting single words or short phrases but could not generate realistic longer content.
BERT's transformer approach was a major breakthrough since it is not a supervised learning technique. That is, it did not require an expensive annotated dataset to train it. BERT was used by Google for interpreting natural language searches, however, it cannot generate text from a prompt.
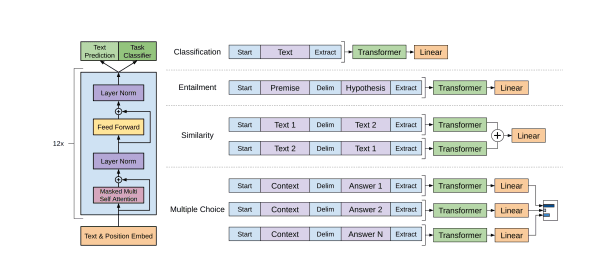
Transformer architecture | GPT-1 Paper
In 2018, OpenAI published a paper (Improving Language Understanding by Generative Pre-Training) about using natural language understanding using their GPT-1 language model. This model was a proof-of-concept and was not released publicly.
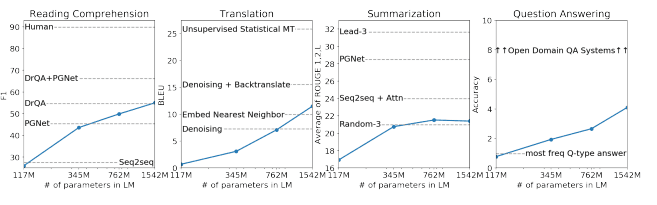
Model performance on various tasks | GPT-2 paper
The following year, OpenAI published another paper (Language Models are Unsupervised Multitask Learners) about their latest model, GPT-2. This time, the model was made available to the machine learning community and found some adoption for text generation tasks. GPT-2 could often generate a couple of sentences before breaking down. This was state-of-the-art in 2019.
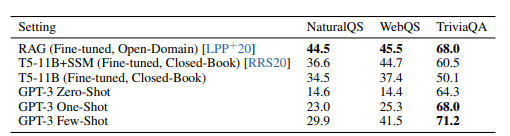
Results on three Open-Domain QA tasks | GPT-3 paper
In 2020, OpenAI published another paper (Language Models are Few-Shot Learners) about their GPT-3 model. The model had 100 times more parameters than GPT-2 and was trained on an even larger text dataset, resulting in better model performance. The model continued to be improved with various iterations known as the GPT-3.5 series, including the conversation-focused ChatGPT.
This version took the world by storm after surprising the world with its ability to generate pages of human-like text. ChatGPT became the fastest-growing web application ever, reaching 100 million users in just two months.
You can learn more about GPT-3, its uses, and how to use it in a separate article.
Get Started with ChatGPT
GPT-4 has been developed to improve model "alignment" - the ability to follow user intentions while also making it more truthful and generating less offensive or dangerous output.
To keep updated with the most recent models, you can view our guides on GPT-4 Turbo and our GPT-4o articles to give more details.
As you might expect, GPT-4 improves on GPT-3.5 models regarding the factual correctness of answers. The number of "hallucinations," where the model makes factual or reasoning errors, is lower, with GPT-4 scoring 40% higher than GPT-3.5 on OpenAI's internal factual performance benchmark.
It also improves "steerability," which is the ability to change its behavior according to user requests. For example, you can command it to write in a different style or tone or voice. Try starting prompts with "You are a garrulous data expert" or "You are a terse data expert" and have it explain a data science concept to you. You can read more about designing great prompts for GPT models here.
A further improvement is in the model's adherence to guardrails. If you ask it to do something illegal or unsavory, it is better at refusing the request.
One major change is that GPT-4 can use image inputs (research preview only; not yet available to the public) and text. Users can specify any vision or language task by entering interspersed text and images.
Examples showcased highlight GPT-4 correctly interpreting complex imagery such as charts, memes, and screenshots from academic papers.
As of June 2024, GPT-4's image input capability has been made available to a broader group of users. For example, I asked GPT-4o to analyze a picture of one of my plants. And, while I still don’t have access to the integrated vision features seen in GPT-4o, I had to take a picture and ask ChatGPT what plant it was:

This isn’t a bad effort, although it’s not quite accurate. While it is a bonsai tree, it’s an Ilex crenata rather than a Carmona retusa. Still, the two look pretty similar so it’s an easy mistake to make and I appreciated the extra context on how to take care of the plant.
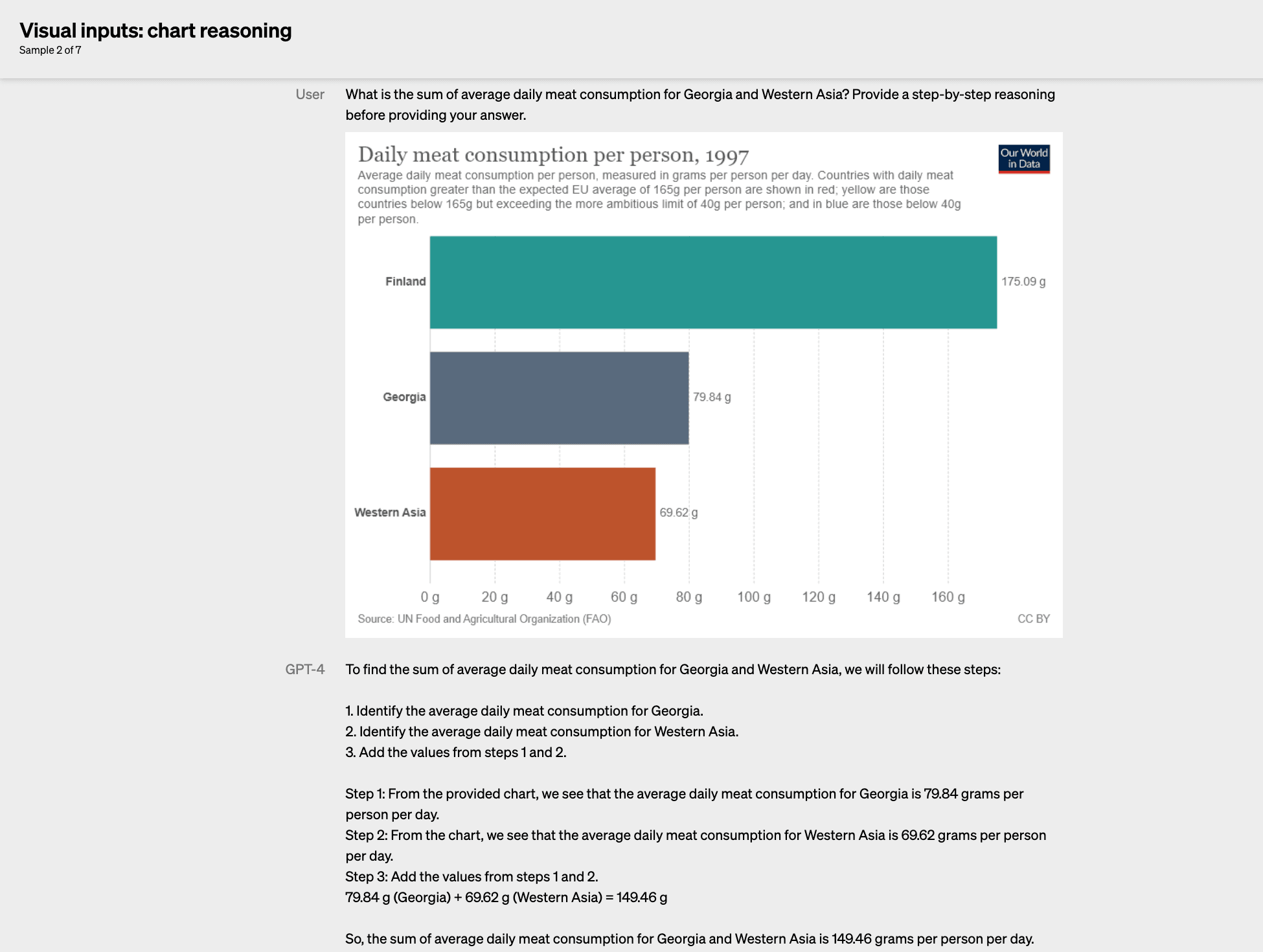
Below, we can also see an example of the visual reasoning from a chart:

OpenAI evaluated GPT-4 by simulating exams designed for humans, such as the Uniform Bar Examination and LSAT for lawyers, and the SAT for university admission. The results showed that GPT-4 achieved human-level performance on various professional and academic benchmarks.
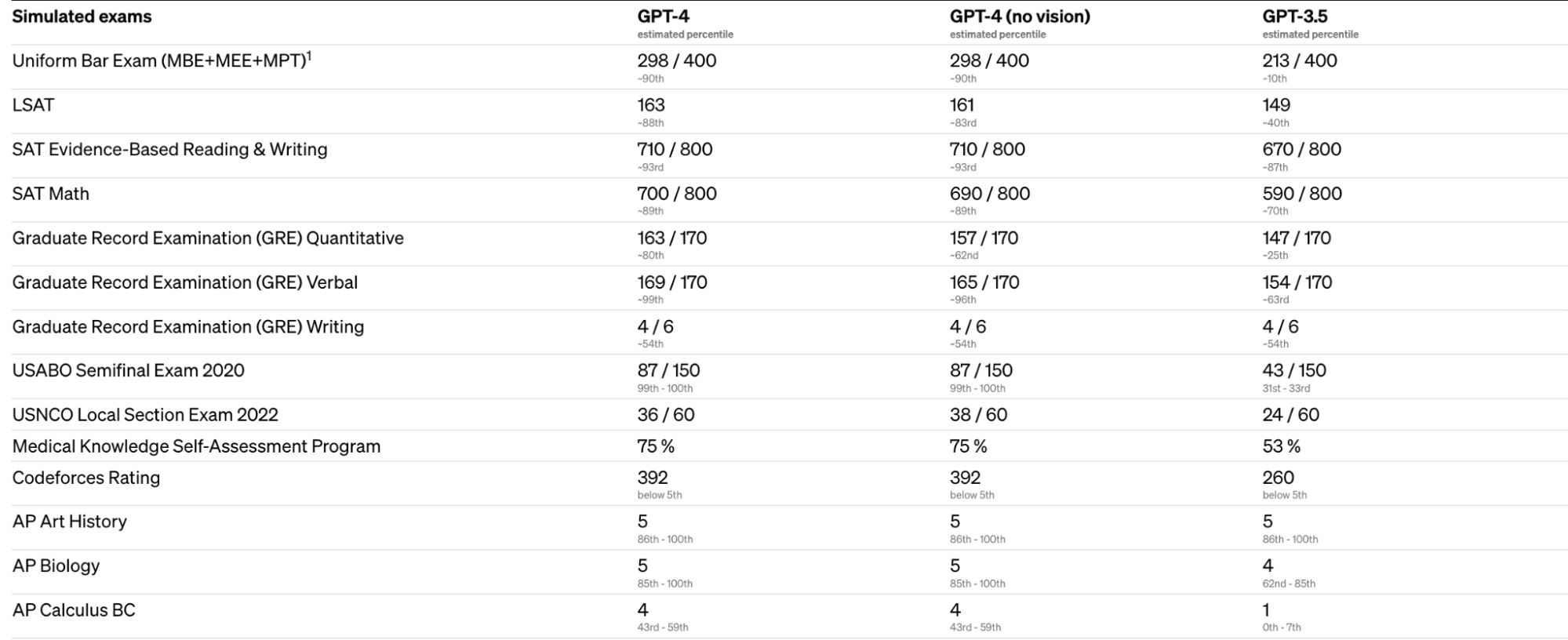
OpenAI also evaluated GPT-4 on traditional benchmarks designed for machine learning models, where it outperformed existing large language models and most state-of-the-art models that may include benchmark-specific crafting or additional training protocols. These benchmarks included multiple-choice questions in 57 subjects, commonsense reasoning around everyday events, grade-school multiple-choice science questions, and more.
OpenAI tested GPT-4's capability in other languages by translating the MMLU benchmark, a suite of 14,000 multiple-choice problems spanning 57 subjects, into various languages using Azure Translate. In 24 out of 26 languages tested, GPT-4 outperformed the English-language performance of GPT-3.5 and other large language models.
Recent testing indicates that GPT-4 continues to lead in multilingual capabilities, particularly in underrepresented languages, demonstrating superior performance in 28 out of 30 languages tested against the latest models.
Overall, GPT-4's more grounded results indicate significant progress in OpenAI's effort to develop AI models with increasingly advanced capabilities.
Want to tap into the power of GPT-4, GPT-4 Turbo, GPT-4o, and GPT-4o mini? Here's how you can do it:
Model Capabilities: All models support text, image, and audio inputs/outputs.
OpenAI has open-sourced OpenAI Evals, a framework for automated evaluation of AI model performance, to allow anyone to report shortcomings in their models and guide further improvements.
In the meantime, you can learn AI and read more about topics such as GPT-4 and ChatGPT, in the following resources:
Learn more about artificial intelligence and GPT with these courses!
Course
Course
Course
blog
Richie Cotton
8 min
blog
Adel Nehme
7 min
blog
Abid Ali Awan
9 min
blog
Ryan Ong
8 min
blog
Josep Ferrer
8 min
Tutorial
Arunn Thevapalan



