
Curso
Comprender la inteligencia artificial
2 h
401.5K
Una base de datos vectorial es un tipo específico de base de datos que almacena información en forma de vectores multidimensionales que representan determinadas características o cualidades.
El número de dimensiones de cada vector puede variar considerablemente, desde unas pocas hasta varios miles, en función de la complejidad y el detalle de los datos. Estos datos, que pueden incluir texto, imágenes, audio y vídeo, se transforman en vectores mediante diversos procesos, como modelos de machine learning, incrustaciones de palabras o técnicas de extracción de características.
La principal ventaja de una base de datos vectorial es su capacidad para localizar y recuperar datos de forma rápida y precisa en función de su proximidad o similitud vectorial. Esto permite realizar búsquedas basadas en la relevancia semántica o contextual, en lugar de depender únicamente de coincidencias exactas o criterios establecidos, como ocurre con las bases de datos convencionales.
Por ejemplo, con una base de datos vectorial, puedes:
Las bases de datos tradicionales almacenan datos simples, como palabras y números, en formato de tabla. Sin embargo, las bases de datos vectoriales trabajan con datos complejos llamados vectores y utilizan métodos únicos para la búsqueda.
Mientras que las bases de datos normales buscan coincidencias exactas, las bases de datos vectoriales buscan la coincidencia más cercana utilizando medidas específicas de similitud.
Las bases de datos vectoriales utilizan técnicas de búsqueda especiales conocidas como búsqueda por vecino más cercano aproximado (ANN), que incluyen métodos como el hash y las búsquedas basadas en gráficos.
Para comprender realmente cómo funcionan las bases de datos vectoriales y en qué se diferencian de las bases de datos relacionales tradicionales como SQL, primero debemos entender el concepto de incrustaciones.
Los datos no estructurados, como el texto, las imágenes y el audio, carecen de un formato predefinido, lo que plantea retos para las bases de datos tradicionales. Para aprovechar estos datos en aplicaciones de inteligencia artificial y machine learning, se transforman en representaciones numéricas mediante incrustaciones.
Incrustar es como dar a cada elemento, ya sea una palabra, una imagen u otra cosa, un código único que captura su significado o esencia. Este código ayuda a los ordenadores a comprender y comparar estos elementos de una forma más eficiente y significativa. Piensa en ello como convertir un libro complicado en un breve resumen que aún capta los puntos principales.
Este proceso de incrustación se logra normalmente utilizando un tipo especial de red neuronal diseñada para la tarea. Por ejemplo, las incrustaciones de palabras convierten las palabras en vectores de tal manera que las palabras con significados similares están más cerca en el espacio vectorial.
Esta transformación permite a los algoritmos comprender las relaciones y similitudes entre los elementos.
Básicamente, las incrustaciones sirven de puente, ya que convierten los datos no numéricos en un formato con el que pueden trabajar los modelos de machine learning, lo que les permite discernir patrones y relaciones en los datos de forma más eficaz.
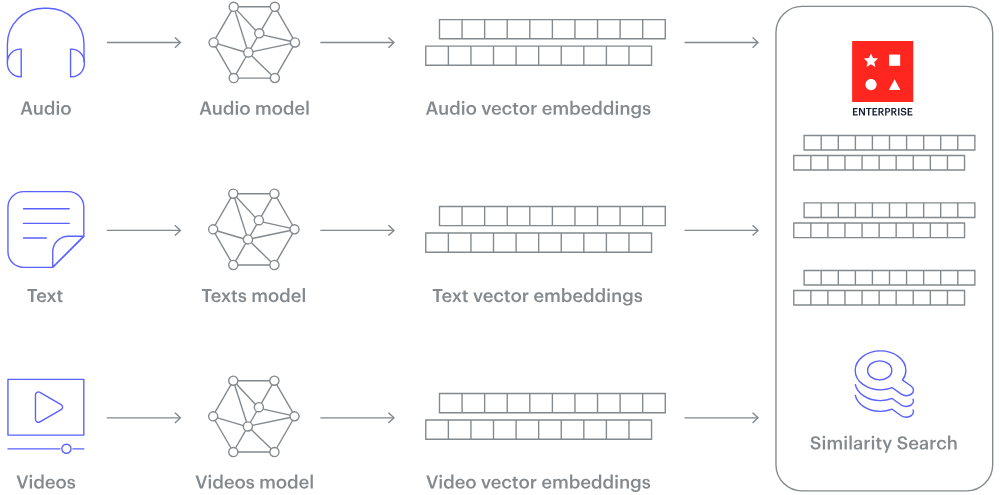
¿Cómo funciona una base de datos vectorial? (Fuente de la imagen)
Las bases de datos vectoriales, con sus capacidades únicas, están abriéndose hueco en multitud de sectores gracias a su eficiencia en la implementación de la «búsqueda por similitud». A continuación, se analizan más detenidamente sus diversas aplicaciones:
En el bullicioso sector minorista, las bases de datos vectoriales están transformando la forma en que ustedes compran. Permiten la creación de sistemas de recomendación avanzados, que ofrecen experiencias de compra personalizadas. Por ejemplo, un comprador online puede recibir sugerencias de productos no solo basadas en compras anteriores, sino también analizando las similitudes en las características de los productos, el comportamiento de los usuarios y sus preferencias.
El sector financiero está plagado de patrones y tendencias complejos. Las bases de datos vectoriales destacan en el análisis de estos datos densos, lo que ayuda a los analistas financieros a detectar patrones cruciales para las estrategias de inversión. Al reconocer similitudes o desviaciones sutiles, pueden pronosticar los movimientos del mercado y diseñar planes de inversión más informados.
En el ámbito de la atención sanitaria, la personalización es fundamental. Mediante el análisis de secuencias genómicas, las bases de datos de vectores permiten tratamientos médicos más personalizados, lo que garantiza que las soluciones médicas se ajusten mejor a la composición genética individual.
El mundo digital está experimentando un auge de los chatbots y los asistentes virtuales. Estas entidades impulsadas por la inteligencia artificial dependen en gran medida de la comprensión del lenguaje humano. Al convertir grandes cantidades de datos de texto en vectores, estos sistemas pueden comprender y responder con mayor precisión a las consultas humanas. Por ejemplo, empresas como Talkmap utilizan la comprensión del lenguaje natural en tiempo real, lo que permite interacciones más fluidas entre los clientes y los agentes.
Desde exploraciones médicas hasta imágenes de vigilancia, la capacidad de comparar y comprender imágenes con precisión es fundamental. Las bases de datos vectoriales agilizan este proceso al centrarse en las características esenciales de las imágenes, filtrando el ruido y las distorsiones. Por ejemplo, en la gestión del tráfico, las imágenes de las transmisiones de vídeo pueden analizarse rápidamente para optimizar el flujo del tráfico y mejorar la seguridad pública.
Detectar valores atípicos es tan importante como reconocer similitudes. Especialmente en sectores como las finanzas y la seguridad, detectar anomalías puede significar prevenir el fraude o adelantarse a una posible brecha de seguridad. Las bases de datos vectoriales ofrecen capacidades mejoradas en este ámbito, lo que hace que el proceso de detección sea más rápido y preciso.
Las bases de datos vectoriales se han convertido en potentes herramientas para navegar por el vasto terreno de los datos no estructurados, como imágenes, vídeos y textos, sin depender en gran medida de etiquetas o rótulos generados por personas. Sus capacidades, cuando se integran con modelos avanzados de machine learning, tienen el potencial de revolucionar numerosos sectores, desde el comercio electrónico hasta el farmacéutico. Estas son algunas de las características más destacadas que hacen que las bases de datos vectoriales sean revolucionarias:
Una base de datos vectorial robusta garantiza que, a medida que los datos crecen (alcanzando millones o incluso miles de millones de elementos), se pueda escalar sin esfuerzo a través de múltiples nodos. Las mejores bases de datos vectoriales ofrecen adaptabilidad, lo que permite a los usuarios ajustar el sistema en función de las variaciones en la tasa de inserción, la tasa de consulta y el hardware subyacente.
Acomodar a múltiples usuarios es una expectativa estándar para las bases de datos. Sin embargo, limitaros a crear una nueva base de datos vectorial para cada usuario no es eficiente. Las bases de datos vectoriales dan prioridad al aislamiento de los datos, lo que garantiza que cualquier cambio realizado en una recopilación de datos permanezca oculto para el resto, a menos que el propietario lo comparta intencionadamente. Esto no solo admite la multitenencia, sino que también garantiza la privacidad y la seguridad de los datos.
Una base de datos auténtica y eficaz ofrece un conjunto completo de API y SDK. Esto garantiza que el sistema pueda interactuar con diversas aplicaciones y se pueda gestionar de forma eficaz. Las principales bases de datos vectoriales, como Pinecone, proporcionan SDK en varios lenguajes de programación, como Python, Node, Go y Java, lo que garantiza flexibilidad en el desarrollo y la gestión.
Las interfaces fáciles de usar de las bases de datos vectoriales desempeñan un papel fundamental a la hora de reducir la pronunciada curva de aprendizaje asociada a las nuevas tecnologías. Estas interfaces ofrecen una visión general, una navegación sencilla y accesibilidad a funciones que, de otro modo, podrían pasar desapercibidas.
La lista no sigue ningún orden en particular; cada uno de ellos muestra muchas de las cualidades descritas en la sección anterior.
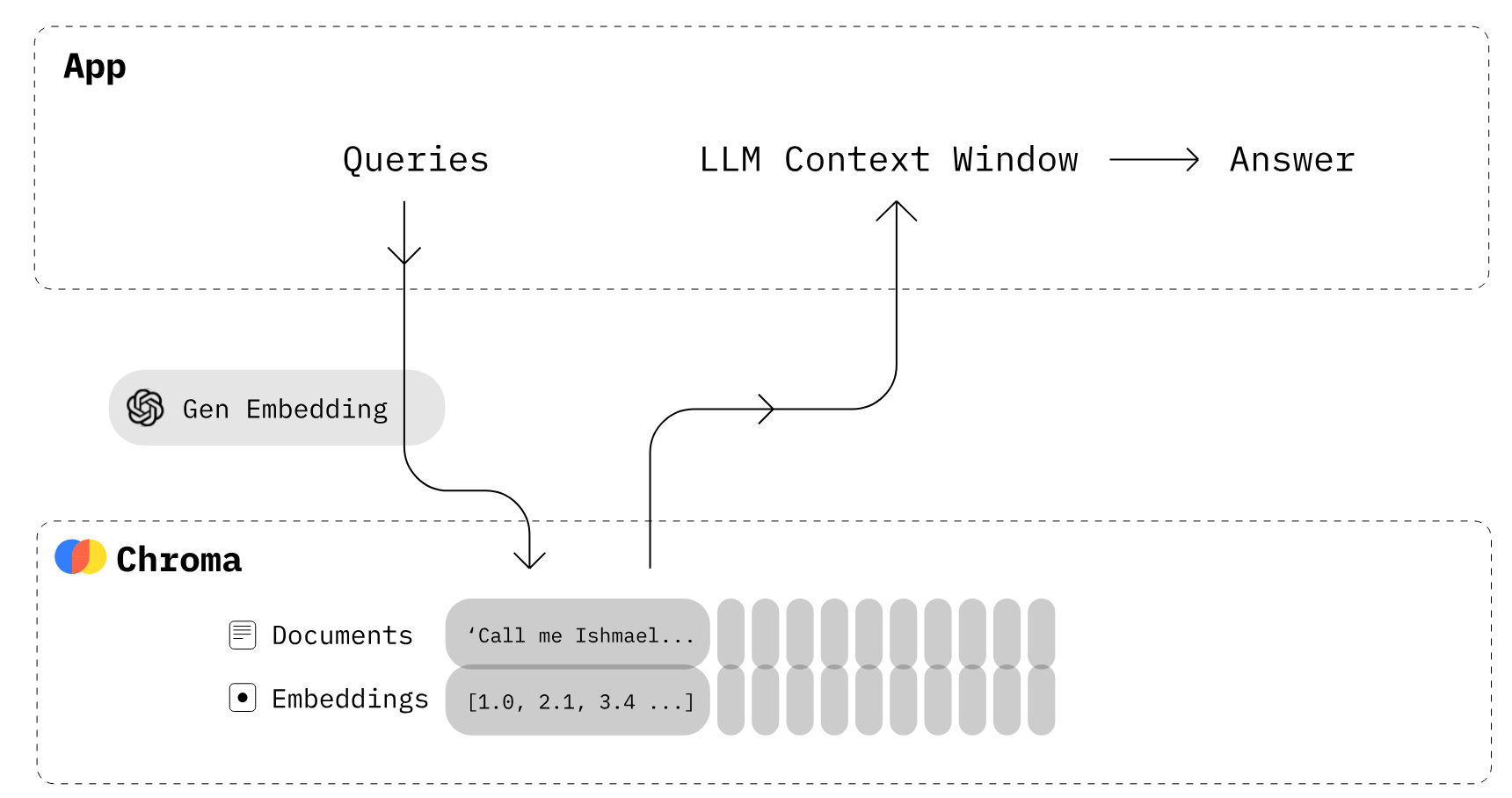
Creación de aplicaciones LLM con ChromaDB (Fuente de la imagen)
Chroma es una base de datos de incrustación de código abierto. Chroma facilita la creación de aplicaciones LLM al hacer que los conocimientos, los datos y las habilidades sean conectables para los LLM. Como exploramos en nuestro tutorial de Chroma DB, puedes gestionar fácilmente documentos de texto, convertir texto en incrustaciones y realizar búsquedas por similitud.
Características de ChromaDB:

Base de datos vectorial de piñas (Fuente de la imagen)
Pinecone es una plataforma de base de datos vectorial gestionada que ha sido diseñada específicamente para abordar los retos únicos asociados a los datos de alta dimensión. Equipado con capacidades de indexación y búsqueda de vanguardia, Pinecone permite a los ingenieros y científicos de datos construir e implementar aplicaciones de machine learning a gran escala que procesan y analizan eficazmente datos de alta dimensión.
Las características principales de Pinecone incluyen:
Cabe destacar que Pinecone fue la única base de datos vectorial incluida en la lista inaugural Fortune 2023 50 AI Innovator.
Para obtener más información sobre Pinecone, consulta el tutorial Dominar las bases de datos vectoriales con Pinecone.
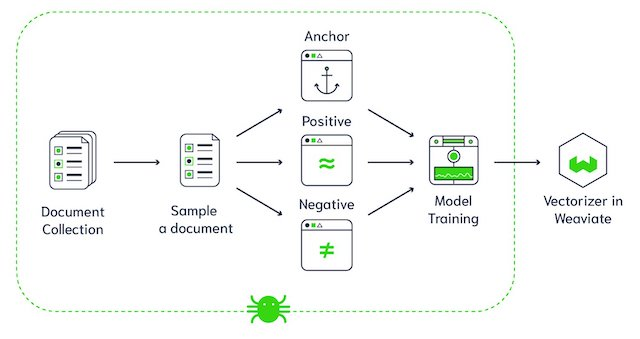
Arquitectura de la base de datos vectorial Weaviate (Fuente de la imagen)
Weaviate es una base de datos vectorial de código abierto. Te permite almacenar objetos de datos e incrustaciones vectoriales de tus modelos de aprendizaje automático favoritos y escalarlos sin problemas a miles de millones de objetos de datos. Algunas de las características principales de Weaviate son:

Faiss es una biblioteca de código abierto para la búsqueda vectorial creada por Facebook (Fuente de la imagen)
Faiss es una biblioteca de código abierto para la búsqueda rápida de similitudes y la agrupación de vectores densos. Alberga algoritmos capaces de realizar búsquedas en conjuntos de vectores de distintos tamaños, incluso aquellos que pueden superar la capacidad de la memoria RAM. Además, Faiss ofrece código auxiliar para evaluar y ajustar parámetros.
Aunque está programado principalmente en C++, es totalmente compatible con la integración de Python/NumPy. Algunos de sus algoritmos clave también están disponibles para su ejecución en GPU. El desarrollo principal de Faiss corre a cargo del grupo de Investigación Fundamental en IA de Meta.
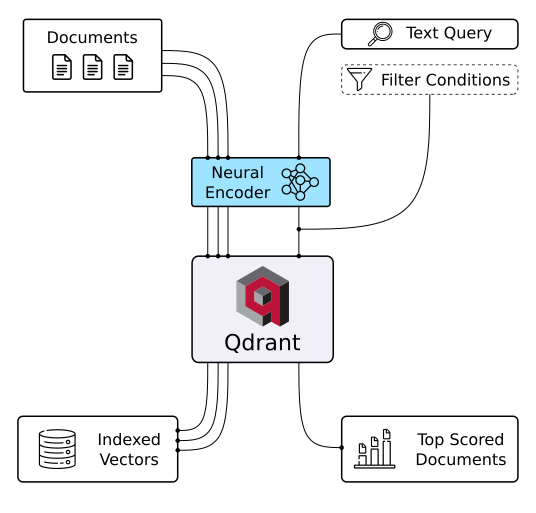
Base de datos vectorial Qdrant (Fuente de la imagen)
Qdrant es una base de datos vectorial y una herramienta para realizar búsquedas de similitud vectorial. Funciona como un servicio API, lo que permite realizar búsquedas de los vectores de alta dimensión más cercanos. Con Qdrant, puedes transformar incrustaciones o codificadores de redes neuronales en aplicaciones completas para tareas como emparejamiento, búsqueda, recomendaciones y mucho más. Estas son algunas de las características principales de Qdrant:
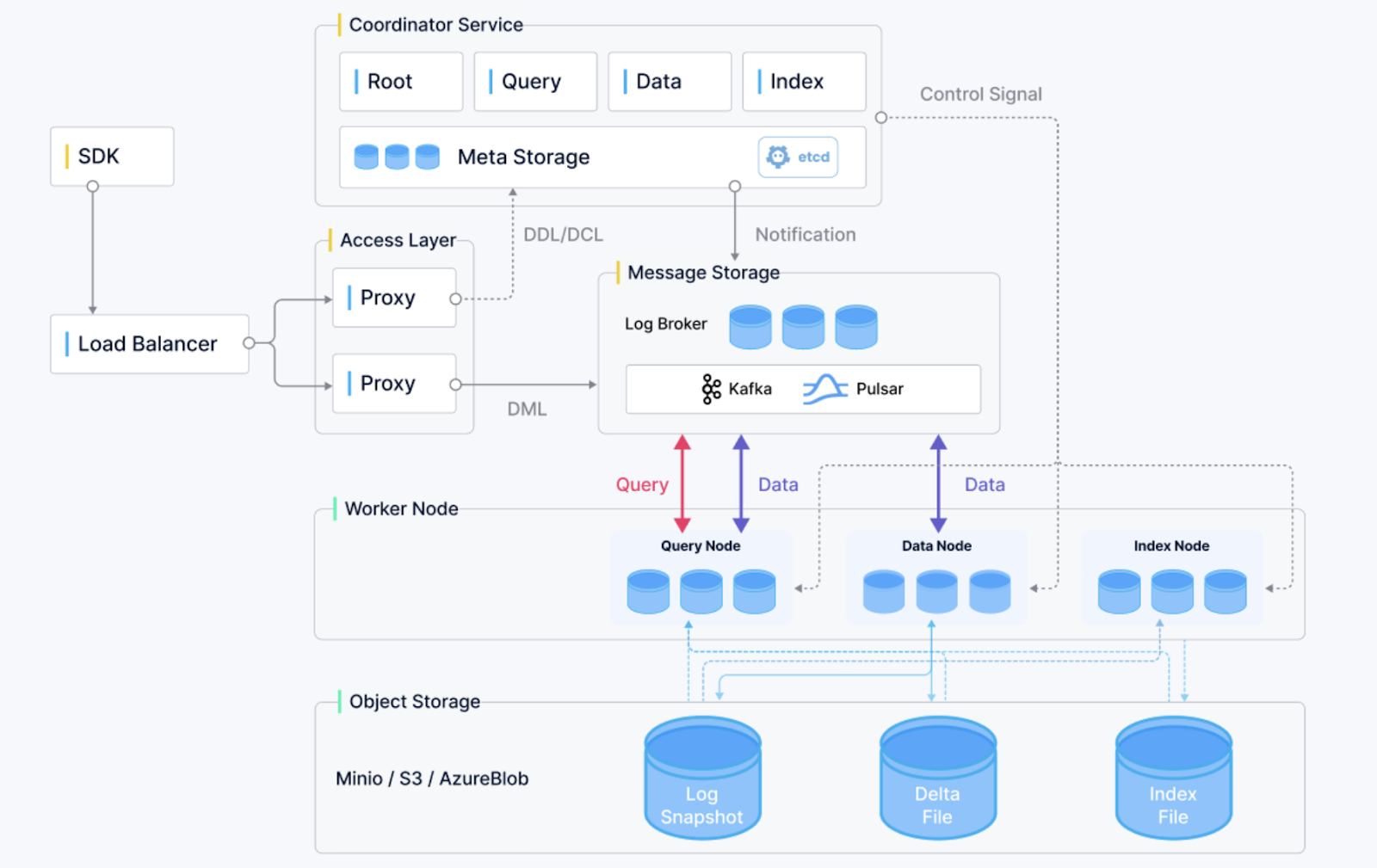
Descripción general de la arquitectura Milvus. (Fuente de la imagen)
Milvus es una base de datos vectorial de código abierto que ha ganado rápidamente popularidad por su escalabilidad, fiabilidad y rendimiento. Diseñado para búsquedas por similitud y aplicaciones basadas en inteligencia artificial, permite almacenar y consultar vectores de incrustación masivos generados por redes neuronales profundas. Milvus ofrece las siguientes características:
Milvus es ideal para aplicaciones en sistemas de recomendación, análisis de vídeo y experiencias de búsqueda personalizadas.
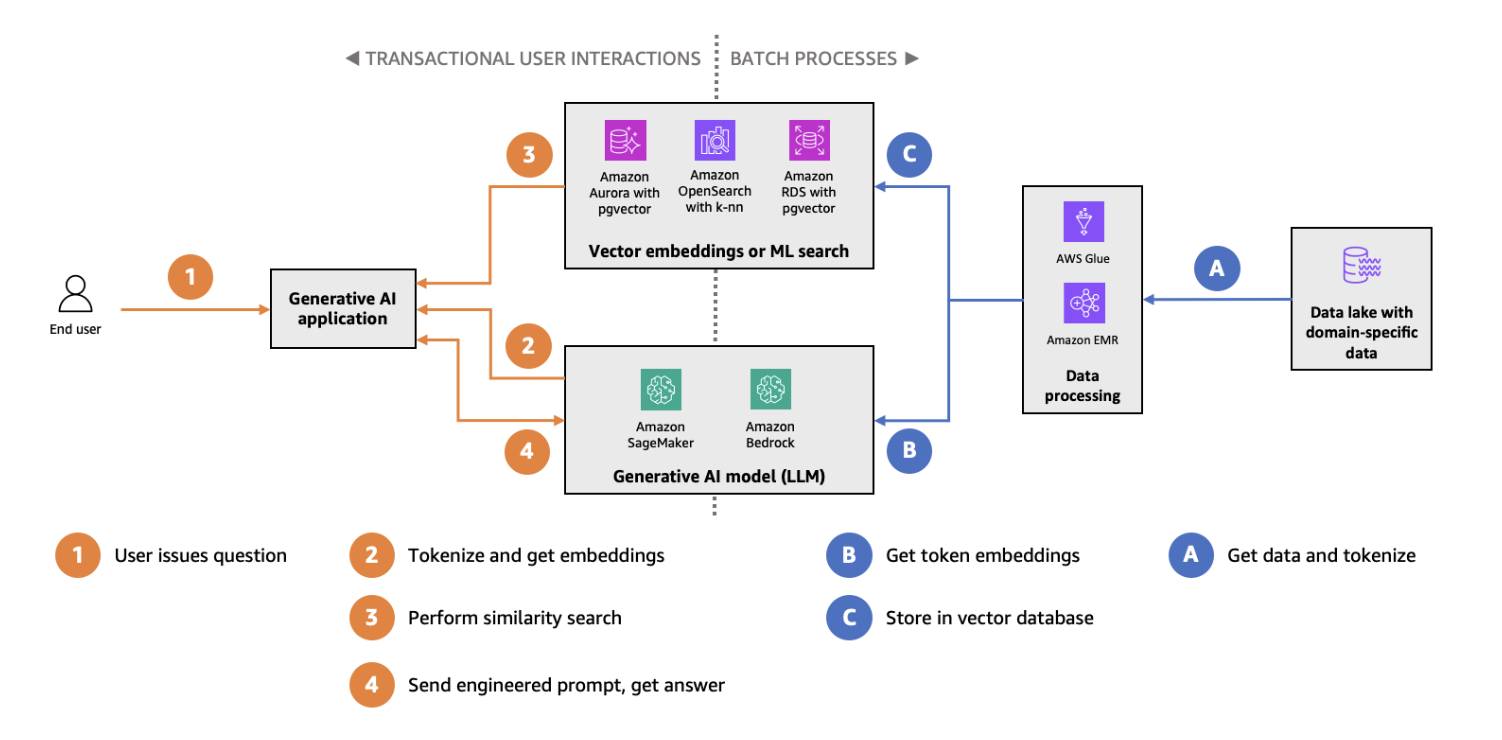
Indexación y búsqueda HNSW con pgvector en el diagrama de arquitectura de Amazon Aurora. (Fuente de la imagen)
pgvector es una extensión para PostgreSQL que introduce tipos de datos vectoriales y capacidades de búsqueda por similitud en la popular base de datos relacional. Al integrar la búsqueda vectorial en PostgreSQL, pgvector ofrece una solución perfecta para los equipos que ya utilizan bases de datos tradicionales pero que desean añadir capacidades de búsqueda vectorial. Las características principales de pgvector incluyen:
pgvector es especialmente adecuado para casos de uso de búsqueda vectorial a pequeña escala o entornos en los que se prefiere un único sistema de base de datos tanto para cargas de trabajo relacionales como basadas en vectores. Para empezar, consulta nuestro tutorial detallado sobre pgvector.
A continuación se muestra una tabla en la que se destacan las características de las principales bases de datos vectoriales mencionadas anteriormente:
| Característica | Chroma | Piña | Weaviate | Faiss | Cuadrante | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Código abierto | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Caso de uso principal | Desarrollo de aplicaciones LLM | Base de datos vectorial gestionada para ML | Almacenamiento y búsqueda vectorial escalable | Búsqueda y agrupación de similitudes a alta velocidad | Búsqueda por similitud vectorial | Búsqueda con IA de alto rendimiento | Añadir la búsqueda vectorial a PostgreSQL |
| Integración | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, ejecución en GPU | OpenAPI v3, clientes en varios idiomas | TensorFlow, PyTorch, HuggingFace | Integrado en el ecosistema PostgreSQL |
| Escalabilidad | Escalas desde cuadernos Python hasta clústeres | Altamente escalable | Escalabilidad perfecta a miles de millones de objetos | Capaz de manejar conjuntos más grandes que la RAM. | Nativo en la nube con escalabilidad horizontal | Escalas a miles de millones de vectores | Depende de la configuración de PostgreSQL. |
| Velocidad de búsqueda | Búsquedas rápidas por similitud | Búsqueda de baja latencia | Milisegundos para millones de objetos | Rápido, compatible con GPU | Algoritmo HNSW personalizado para búsqueda rápida | Optimizado para búsquedas de baja latencia. | Vecino más cercano aproximado (ANN) |
| Privacidad de los datos | Admite múltiples usuarios con aislamiento de datos. | Servicio totalmente gestionado | Hace hincapié en la seguridad y la replicación. | Principalmente para investigación y desarrollo. | Filtrado avanzado de cargas útiles vectoriales | Arquitectura multitenant segura | Heredas la seguridad de PostgreSQL. |
| Lenguaje de programación | Python, JavaScript | Python | Python, Java, Go, otros | C++, Python | Óxido | C++, Python, Go | Extensión PostgreSQL (basada en SQL) |
Las bases de datos vectoriales se especializan en almacenar vectores de alta dimensión, lo que permite realizar búsquedas de similitud rápidas y precisas. Dado que los modelos de IA, especialmente los del ámbito del procesamiento del lenguaje natural y la visión artificial, generan y trabajan con estos vectores, la necesidad de contar con sistemas eficientes de almacenamiento y recuperación se ha convertido en algo primordial. Aquí es donde entran en juego las bases de datos vectoriales, que proporcionan un entorno altamente optimizado para estas aplicaciones impulsadas por la inteligencia artificial.
Un ejemplo claro de esta relación entre la IA y las bases de datos vectoriales se observa en la aparición de grandes modelos lingüísticos (LLM, por sus siglas en inglés) como GPT-3.
Estos modelos están diseñados para comprender y generar texto similar al humano mediante el procesamiento de grandes cantidades de datos, transformándolos en vectores de alta dimensión. Las aplicaciones basadas en GPT y modelos similares dependen en gran medida de las bases de datos vectoriales para gestionar y consultar estos vectores de manera eficiente. La razón de esta dependencia radica en el enorme volumen y la complejidad de los datos que manejan estos modelos. Dado el aumento sustancial de los parámetros, modelos como GPT-4 generan una gran cantidad de datos vectorizados, lo que puede suponer un reto para que las bases de datos convencionales los procesen de manera eficiente. Esto subraya la importancia de contar con bases de datos vectoriales especializadas capaces de manejar datos de tan alta dimensión.
El panorama en constante evolución de la inteligencia artificial y machine learning subraya la indispensabilidad de las bases de datos vectoriales en el mundo actual, centrado en los datos. Estas bases de datos, con su capacidad única para almacenar, buscar y analizar vectores de datos multidimensionales, están demostrando ser fundamentales para impulsar aplicaciones basadas en la inteligencia artificial, desde sistemas de recomendación hasta análisis genómicos.
Recientemente hemos visto un impresionante arreglo de bases de datos vectoriales, como Chroma, Pinecone, Weaviate, Faiss y Qdrant, cada una de las cuales ofrece capacidades e innovaciones distintas. A medida que la IA continúa su ascenso, el papel de las bases de datos vectoriales en la configuración del futuro de la recuperación, el procesamiento y el análisis de datos crecerá sin duda, prometiendo soluciones más sofisticadas, eficientes y personalizadas en diversos sectores.
Aprende a dominar las bases de datos vectoriales con nuestro tutorial sobre Pinecone, o inscríbete en nuestro programa de Deep Learning en Python para mejorar tus habilidades en IA y mantenerte al día de las últimas novedades.
¡Aprende más sobre la IA con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
12 min
blog
Yuliya Melnik
15 min
blog
Kurtis Pykes
11 min
blog
Javier Canales Luna
8 min
blog
Austin Chia
Tutorial
Moez Ali


