Con el auge de los Grandes Modelos Lingüísticos (LLM) y sus aplicaciones, hemos asistido a un aumento de la popularidad de las herramientas de integración, los marcos LLMOps y las bases de datos vectoriales. Esto se debe a que trabajar con LLM requiere un enfoque diferente al de los modelos tradicionales de machine learning.
Una de las principales tecnologías que permiten los LLM son las incrustaciones vectoriales. Mientras que los ordenadores no pueden comprender directamente el texto, las incrustaciones representan el texto numéricamente. Todo el texto proporcionado por el usuario se convierte en incrustaciones, que se utilizan para generar respuestas.
Convertir el texto en incrustación es un proceso que lleva mucho tiempo. Para evitarlo, disponemos de bases de datos vectoriales diseñadas explícitamente para almacenar y recuperar de forma eficaz las incrustaciones vectoriales.
En este tutorial, aprenderemos sobre los almacenes vectoriales y Chroma DB, una base de datos de código abierto para almacenar y gestionar incrustaciones. Además, aprenderemos a añadir y eliminar documentos, a realizar búsquedas de similitud y a convertir nuestro texto en incrustaciones.

Imagen del autor
¿Qué son los almacenes vectoriales?
Los almacenes vectoriales son bases de datos diseñadas explícitamente para almacenar y recuperar incrustaciones vectoriales de forma eficiente. Se necesitan porque las bases de datos tradicionales, como SQL, no están optimizadas para almacenar y consultar grandes datos vectoriales.
Las incrustaciones representan datos (normalmente datos no estructurados como el texto) en formatos vectoriales numéricos dentro de un espacio de alta dimensión. Las bases de datos relacionales tradicionales no son adecuadas para almacenar y buscar estas representaciones vectoriales.
Los almacenes vectoriales pueden indexar y buscar rápidamente vectores similares mediante algoritmos de similitud. Permite a las aplicaciones encontrar vectores relacionados dada una consulta de vector objetivo.
En el caso de un chatbot personalizado, el usuario introduce una instrucción para el modelo generativo de IA. A continuación, el modelo busca textos similares dentro de una colección de documentos mediante un algoritmo de búsqueda por similitud. La información resultante se utiliza para generar una respuesta altamente personalizada y precisa. Es posible gracias a la incrustación y la indexación vectorial dentro de los almacenes vectoriales.
¿Qué es Chroma DB?
Chroma DB es un almacén vectorial de código abierto que se utiliza para almacenar y recuperar incrustaciones vectoriales. Su uso principal es guardar incrustaciones junto con metadatos para que los utilicen posteriormente grandes modelos lingüísticos. Además, también puede utilizarse para motores de búsqueda semántica sobre datos de texto.
Características principales de Chroma DB:
- Admite distintas opciones de almacenamiento subyacente, como DuckDB para autónomos o ClickHouse para escalabilidad.
- Proporciona SDK para Python y JavaScript/TypeScript.
- Se centra en la sencillez, la rapidez y la posibilidad de análisis.
Chroma DB ofrece una opción de servidor autoalojado. Si necesitas una plataforma gestionada de bases de datos vectoriales, consulta la Guía Pinecone para dominar las bases de datos vectoriales.
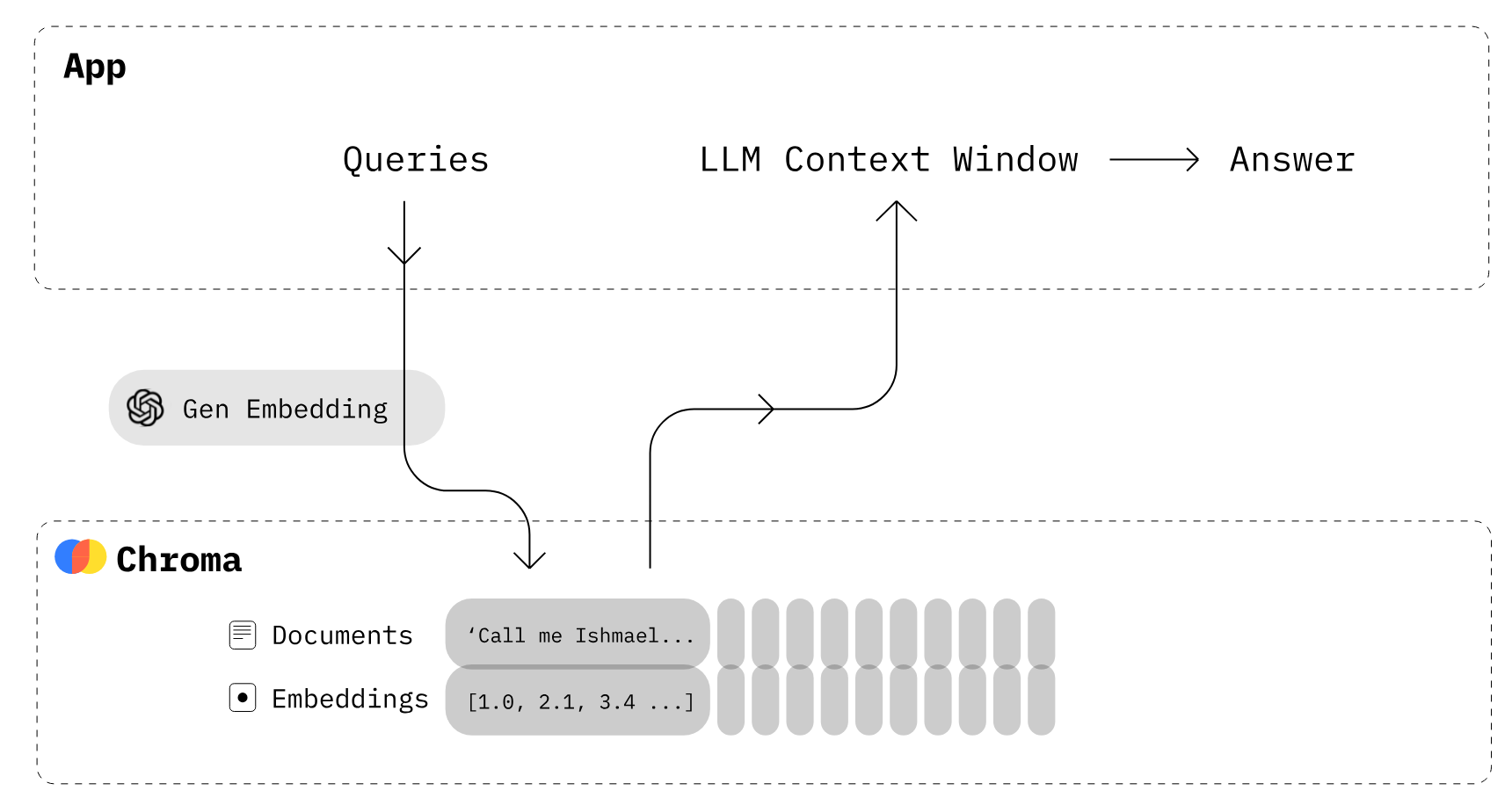
Imagen de Chroma
¿Cómo funciona Chroma DB?
- En primer lugar, tienes que crear una colección similar a las tablas de la base de datos de relaciones. De forma predeterminada, Chroma convierte el texto en las incrustaciones con
all-MiniLM-L6-v2, pero puedes modificar la colección para utilizar otro modelo de incrustación. - Añade documentos de texto a la colección recién creada con metadatos y un identificador único. Cuando tu colección recibe el texto, lo convierte automáticamente en incrustación.
- Consulta la colección por texto o incrustación para recibir documentos similares. También puedes filtrar los resultados en función de los metadatos.
En la siguiente parte, utilizaremos Chroma y la API OpenAI para crear nuestra propia BD vectorial.
Primeros pasos con Chroma DB
En esta sección, crearemos una base de datos vectorial, añadiremos colecciones, añadiremos texto a la colección y realizaremos una búsqueda de consulta.
En primer lugar, instalaremos chromadb para la base de datos vectorial y openai para un mejor modelo de incrustación. Asegúrate de que has configurado la clave API de OpenAI.
Nota: Chroma requiere SQLite versión 3.35 o superior. Si tienes problemas, actualiza a Python 3.11 o instala una versión anterior de chromadb.
!pip install chromadb openai Puedes crear una BD en memoria para pruebas al crear un cliente Chroma DB sin configuración.
En nuestro caso, crearemos una base de datos persistente que se almacenará en el directorio "db/" y utilizaremos DuckDB en el backend.
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="db/"
))Después, crearemos un objeto colección con el cliente. Es similar a crear una tabla en una base de datos tradicional.
collection = client.create_collection(name="Students")Para añadir texto a nuestra colección, necesitamos generar texto aleatorio sobre un estudiante, un club y una universidad. Puedes generar texto aleatorio mediante ChatGPT. Es muy sencillo.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.Ahora, utilizaremos la función add para añadir datos de texto con metadatos e identificadores únicos. Después, Chroma descargará automáticamente el modelo all-MiniLM-L6-v2 para convertir el texto en incrustaciones y lo almacenará en la colección "Estudiantes".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Para realizar una búsqueda de similitudes, puedes utilizar la función query y formular preguntas en lenguaje natural. Convertirá la consulta en incrustación y utilizará algoritmos de similitud para obtener resultados similares. En nuestro caso, devuelve dos resultados similares.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Incrustaciones
Puedes utilizar cualquier modelo de incrustación de alto rendimiento de la lista de incrustación. Incluso puedes crear tus funciones de incrustación personalizadas.
En esta sección, utilizaremos el modelo de incrustación de la línea OpenAI llamado "text-embedding-ada-002" para convertir el texto en incrustación.
Después de crear la función de incrustación de OpenAI, puedes añadir la lista de documentos de texto para generar incrustaciones.
Descubre cómo utilizar la API OpenAI para incrustaciones de texto y crear clasificadores de texto, sistemas de recuperación de información y detectores de similitud semántica.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
model_name="text-embedding-ada-002"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]En lugar de utilizar el modelo de incrustación de forma predeterminada, cargaremos incrustaciones ya creadas directamente en las colecciones.
- Utilizaremos la función
get_or_create_collectionpara crear una nueva colección llamada "Estudiantes2". Esta función es diferente decreate_collection. Obtendrá una colección o la creará si aún no existe. - Ahora añadiremos incrustaciones, documentos de texto, metadatos e IDs a nuestra colección recién creada.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)También existe otro método más sencillo. Puedes añadir una función de incrustación de OpenAI al crear o acceder a la colección. Además de OpenAI, puedes utilizar los modelos Cohere, Google PaLM, HuggingFace e Instructor.
En nuestro caso, al añadir nuevos documentos de texto se ejecutará una función de incrustación de OpenAI en lugar del modelo predeterminado para convertir el texto en incrustaciones.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Veamos la diferencia ejecutando una consulta similar en la nueva colección.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsNuestros resultados han mejorado. La búsqueda por similitud ahora devuelve información sobre la universidad en lugar de un club. Además, la distancia entre los vectores es inferior a la del modelo de incrustación por defecto, lo cual es positivo.

Actualizar y eliminar datos
Al igual que las bases de datos relacionales, puedes actualizar o eliminar los valores de las colecciones. Para actualizar el texto y los metadatos, proporcionaremos el ID específico del registro y el nuevo texto.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Ejecuta una consulta sencilla para comprobar si los cambios se han realizado correctamente.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsComo podemos ver, en lugar de Alexandra, tenemos a Kristiane.

Para eliminar un registro de la colección, utilizaremos la función `delete` y especificaremos un ID único.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsSe ha eliminado el texto de información del alumno; en su lugar, obtenemos los siguientes mejores resultados.

Gestión de colecciones
En esta sección, conoceremos la función de utilidad de recogida que nos hará la vida mucho más fácil.
Crearemos una nueva colección llamada "vectordb" y añadiremos la información sobre la hoja de trucos de Chroma DB, la documentación y la API JS con metadatos.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Utilizaremos la función count() para comprobar cuántos registros tiene la colección.
vector_collections.count()3Para ver todos los registros de la colección, utiliza la función .get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Para cambiar el nombre de la colección, utiliza la función modify(). Para ver todos los nombres de las colecciones, utiliza list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Parece que efectivamente hemos renombrado "vectordb" como "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Para acceder a cualquier colección nueva, puedes utilizar get_collection con el nombre de la colección.
vector_collections_new = client.get_collection(name="chroma_info")Podemos eliminar una colección utilizando la función cliente delete_collection y especificando el nombre de la colección.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Podemos eliminar toda la colección de la base de datos utilizando client.reset(). Sin embargo, no es recomendable, ya que no hay forma de restaurar los datos tras la eliminación.
client.reset()
client.list_collections()[]Conclusión
Los almacenes vectoriales como Chroma DB se están convirtiendo en componentes esenciales de los grandes sistemas de modelos lingüísticos. Al proporcionar un almacenamiento especializado y una recuperación eficaz de las incrustaciones vectoriales, permiten un acceso rápido a la información semántica relevante para potenciar los LLM.
En este tutorial de Chroma DB, cubrimos los aspectos básicos de la creación de una colección, la adición de documentos, la conversión de texto en incrustaciones, la consulta de similitud semántica y la gestión de colecciones.
El siguiente paso en el proceso de aprendizaje es integrar bases de datos vectoriales en tu aplicación de IA generativa. Puedes ingerir, gestionar y recuperar fácilmente datos privados y específicos del dominio para tu aplicación de IA siguiendo el tutorial de LlamaIndex, que es un marco de datos para aplicaciones basadas en Grandes Modelos Lingüísticos (LLM). Además, puedes seguir el tutorial Cómo crear aplicaciones LLM con LangChain para sumergirte en el mundo de las LLMOps.

