LlamaIndex es un marco de datos para aplicaciones basadas en Grandes Modelos Lingüísticos (LLM). Los LLM como GPT-4 vienen preentrenados en conjuntos de datos públicos masivos, lo que permite una capacidad increíble de procesamiento del lenguaje natural nada más sacarlos de la caja. Sin embargo, su utilidad es limitada sin acceso a tus propios datos privados.
LlamaIndex te permite ingerir datos de API, bases de datos, PDF y más mediante conectores de datos flexibles. Estos datos se indexan en representaciones intermedias optimizadas para los LLM. LlamaIndex permite entonces realizar consultas en lenguaje natural y conversar con tus datos mediante motores de consulta, interfaces de chat y agentes de datos potenciados por LLM. Permite a tus LLM acceder a datos privados e interpretarlos a gran escala, sin necesidad de volver a entrenar el modelo con datos más recientes.
Tanto si eres un principiante que busca una forma sencilla de consultar tus datos en lenguaje natural como si eres un usuario avanzado que requiere una personalización profunda, LlamaIndex te proporciona las herramientas. La API de alto nivel permite empezar en sólo cinco líneas de código, mientras que las API de nivel inferior permiten un control total sobre la ingestión de datos, la indexación, la recuperación y mucho más.
¿Cómo funciona LlamaIndex?
LlamaIndex utiliza sistemas de Generación Aumentada de Recuperación (RAG) que combinan grandes modelos lingüísticos con una base de conocimientos privada. Generalmente consta de dos etapas: la etapa de indexación y la etapa de consulta.
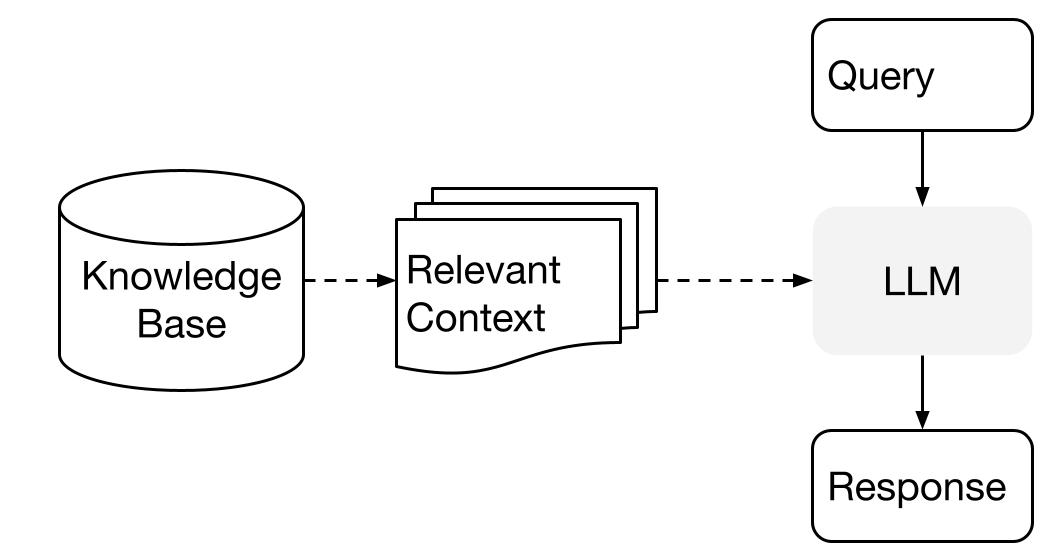
Imagen de Conceptos de alto nivel
Fase de indexación
LlamaIndex indexará eficazmente los datos privados en un índice vectorial durante la etapa de indexación. Este paso ayuda a crear una base de conocimientos específica de tu dominio en la que se puedan realizar búsquedas. Puedes introducir documentos de texto, registros de bases de datos, gráficos de conocimiento y otros tipos de datos.
Esencialmente, la indexación convierte los datos en vectores numéricos o incrustaciones que captan su significado semántico. Permite búsquedas rápidas de similitudes en el contenido.
Fase de consulta
Durante la fase de consulta, el canal RAG busca la información más relevante basándose en la consulta del usuario. A continuación, esta información se facilita al LLM, junto con la consulta, para crear una respuesta precisa.
Este proceso permite que el LLM tenga acceso a información actual y actualizada que puede no haber sido incluida en su formación inicial.
El principal reto durante esta etapa es recuperar, organizar y razonar sobre bases de conocimiento potencialmente múltiples.
Aprende más sobre RAG en nuestro code-along sobre Generación Aumentada de Recuperación con PineCone.
Configurar LlamaIndex
Antes de sumergirnos en nuestro tutorial y proyecto LlamaIndex, tenemos que instalar el paquete Python y configurar la API.
Podemos instalar simplemente LlamaIndex utilizando pip.
pip install llama-indexPor defecto, LlamaIndex utiliza el modelo OpenAI GPT-3 text-davinci-003. Para utilizar este modelo, debes tener configurado OPENAI_API_KEY. Puedes crear una cuenta gratuita y obtener una clave API accediendo al nuevo token API de OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "INSERT OPENAI KEY"Asegúrate también de que tienes instalado el paquete openai.
pip install openaiAñadir datos personales a los LLM mediante LlamaIndex
En esta sección, aprenderemos a utilizar LlamaIndex para crear un lector de currículum. Puedes descargar tu currículum entrando en la página de perfil de Linkedin, haciendo clic en Más y luego en Guardar en PDF.
Ten en cuenta que estamos utilizando DataLab para ejecutar el código Python. Puedes acceder a todo el código y resultados relevantes en LlamaIndex: Añadir datos personales al libro de trabajo LLMs; ¡puedes crear fácilmente tu propia copia para ejecutar todo el código sin tener que instalar nada en tu ordenador!
Antes de ejecutar nada, debemos instalar llama-index, openai, y pypdf. Estamos instalando pypdf para poder leer y convertir archivos PDF.
%pip install llama-index openai pypdfCargar datos y crear el índice
Tenemos un directorio llamado "Datos-Privados" que sólo contiene un archivo PDF. Utilizaremos el SimpleDirectoryReader para leerlo y luego lo convertiremos en un índice utilizando el TreeIndex.
from llama_index import TreeIndex, SimpleDirectoryReader
resume = SimpleDirectoryReader("Private-Data").load_data()
new_index = TreeIndex.from_documents(resume)Ejecutar una consulta
Una vez indexados los datos, puedes empezar a hacer preguntas utilizando as_query_engine(). Esta función te permite hacer preguntas sobre información específica dentro del documento y recibir una respuesta correspondiente con la ayuda del modelo OpenAI GPT-3 text-davinci-003.
Nota: puedes configurar la API OpenAI en DataLab siguiendo el tutorial Utilizar GPT-3.5 y GPT-4 mediante la API OpenAI en Python.
Como vemos, el modelo LLM ha respondido con precisión a la consulta. Buscó en el índice y encontró la información pertinente.
query_engine = new_index.as_query_engine()
response = query_engine.query("When did Abid graduated?")
print(response)Abid graduated in February 2014.Podemos informarnos sobre la certificación. Parece que LlamaIndex ha conseguido un conocimiento completo del candidato, lo que puede ser ventajoso para las empresas que buscan personas concretas.
response = query_engine.query("What is the name of certification that Abid received?")
print(response)Data Scientist ProfessionalGuardar y cargar el contexto
Crear un índice es un proceso que lleva mucho tiempo. Podemos evitar volver a crear índices guardando el contexto. Por defecto, el siguiente comando guardará el almacén de índices en el directorio ./storage.
new_index.storage_context.persist()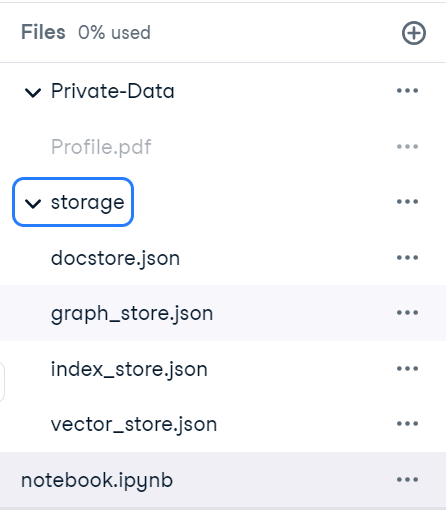
Una vez hecho esto, podemos cargar rápidamente el contexto de almacenamiento y crear un índice.
from llama_index import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)Para comprobar que funciona correctamente, haremos al motor de consulta la pregunta del currículum. Parece que hemos cargado correctamente el contexto.
query_engine = index.as_query_engine()
response = query_engine.query("What is Abid's job title?")
print(response)Abid's job title is Technical Writer.Chatbot
En lugar de preguntas y respuestas, también podemos utilizar LlamaIndex para crear un Chatbot personal. Sólo tenemos que inicializar el índice con la función as_chat_engine().
Vamos a hacer una pregunta sencilla.
query_engine = index.as_chat_engine()
response = query_engine.chat("What is the job title of Abid in 2021?")
print(response)Abid's job title in 2021 is Data Science Consultant.Y sin dar más contexto, haremos preguntas de seguimiento.
response = query_engine.chat("What else did he do during that time?")
print(response)In 2021, Abid worked as a Data Science Consultant for Guidepoint, a Writer for Towards Data Science and Towards AI, a Technical Writer for Machine Learning Mastery, an Ambassador for Deepnote, and a Technical Writer for Start It Up.Es evidente que el motor de chat funciona perfectamente.
Después de crear tu aplicación lingüística, el siguiente paso en tu línea de tiempo es leer sobre los pros y los contras de utilizar Grandes Modelos Lingüísticos (LLM) en la nube frente a ejecutarlos localmente. Esto te ayudará a determinar qué enfoque se adapta mejor a tus necesidades.
Construir wiki de texto a voz con LlamaIndex
Nuestro próximo proyecto consiste en desarrollar una aplicación que pueda responder a preguntas procedentes de Wikipedia y convertirlas en voz.
El código fuente y la información adicional están disponibles en este libro de trabajo de DataLab.
Página de Wikipedia de raspado web
En primer lugar, rasparemos los datos de la página web Italia - Wikipedia y los guardaremos como archivo italy_text.txt en la carpeta data.
from pathlib import Path
import requests
response = requests.get(
"https://en.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": "Italy",
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
italy_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open("data/italy_text.txt", "w") as fp:
fp.write(italy_text)
Cargar los datos y construir el índice
A continuación, tenemos que instalar los paquetes necesarios. El paquete elevenlabs nos permite convertir fácilmente texto en voz mediante una API.
%pip install llama-index openai elevenlabsUtilizando SimpleDirectoryReader cargaremos los datos y convertiremos el archivo TXT en un almacén vectorial utilizando VectorStoreIndex.
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from IPython.display import Markdown, display
from llama_index.tts import ElevenLabsTTS
from IPython.display import Audio
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)Consulta
Nuestro plan es hacer una pregunta general sobre el país y recibir una respuesta del LLM query_engine.
query = "Tell me an interesting fact about the country?"
query_engine = index.as_query_engine()
response = query_engine.query(query)
display(Markdown(f"<b>{query}</b>"))
display(Markdown(f"<p>{response}</p>"))
Texto a voz
Después, utilizaremos el módulo llama_index.tts para acceder a la api ElevenLabsTTS. Necesitas proporcionar la clave API de ElevenLabs para iniciar la función de generación de audio. Puedes obtener una clave API en el sitio web de ElevenLabs de forma gratuita.
import os
elevenlabs_key = os.environ["ElevenLabs_key"]
tts = ElevenLabsTTS(api_key=elevenlabs_key)Añadiremos la respuesta a la función generate_audio para generar una voz natural. Para escuchar el audio, utilizaremos la función Audio de IPython.display.
audio = tts.generate_audio(str(response))
Audio(audio)
Este es un ejemplo sencillo. Puedes utilizar varios módulos para crear tu asistente, como Siri, que responde a tus preguntas interpretando tus datos privados. Para más información, consulta la documentación de LlamaIndex.
Además de LlamaIndex, LangChain también te permite crear aplicaciones basadas en LLM. Además, puedes leer Introducción a LangChain para Ingeniería de Datos y Aplicaciones de Datos para comprender una visión general de lo que puedes hacer con LangChain, incluidos los problemas que resuelve LangChain y ejemplos de casos de uso de datos.
Casos prácticos de LlamaIndex
LlamaIndex proporciona un completo conjunto de herramientas para crear aplicaciones basadas en el lenguaje. Además, puedes utilizar varios cargadores de datos y herramientas de agente de Llama Hub para desarrollar aplicaciones complejas con múltiples funcionalidades.
Puedes conectar fuentes de datos personalizadas a tu LLM con uno o varios plugins Cargadores de datos.
Cargadores de datos de Llama Hub
También puedes utilizar herramientas de Agente para integrar herramientas y API de terceros.
Herramientas de Agente de Llama Hub
En resumen, puedes utilizar LlamaIndex para construir:
- Preguntas y respuestas sobre documentos
- Chatbots
- Agentes
- Datos estructurados
- Aplicación Web Full-Stack
- Configuración privada
Para conocer estos casos de uso en detalle, dirígete a la documentación de LlamaIndex.
Conclusión
LlamaIndex proporciona un potente conjunto de herramientas para construir sistemas de generación de recuperación aumentada que combinan los puntos fuertes de los grandes modelos lingüísticos con las bases de conocimiento personalizadas. Permite crear un almacén indexado de datos específicos del dominio y aprovecharlo durante la inferencia para proporcionar un contexto relevante al LLM que genere respuestas de alta calidad.
En este tutorial, hemos aprendido sobre LlamaIndex y cómo funciona. Además, construimos un lector de currículum y un proyecto de texto a voz con sólo unas pocas líneas de código Python. Crear una aplicación LLM con LlamaIndex es sencillo, y ofrece una amplia biblioteca de plugins, cargadores de datos y agentes.
Para convertirte en un experto desarrollador de LLM, el siguiente paso natural es matricularte en el curso de Maestría en Conceptos de Grandes Modelos Lingüísticos. Este curso te proporcionará un conocimiento exhaustivo de los LLM, incluidas sus aplicaciones, métodos de formación, consideraciones éticas y las últimas investigaciones.
