Curso
Introducción al Deep Learning en Python
4 h
263.5K
La adopción masiva de herramientas como ChatGPT y otras herramientas de IA generativa ha dado lugar a un gran debate sobre las ventajas y los retos de la IA y sobre cómo remodelará nuestra sociedad. Para evaluar mejor estas cuestiones, es importante saber cómo funcionan los llamados Grandes Modelos Lingüísticos (LLM) que están detrás de las herramientas de IA de próxima generación.
Este artículo ofrece una introducción al Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF), una técnica innovadora que combina técnicas de aprendizaje por refuerzo y orientación humana para ayudar a LLMS como ChatGPT a obtener resultados impresionantes. Trataremos qué es el RLHF, sus ventajas, limitaciones y su relevancia en el futuro desarrollo del vertiginoso campo de la IA generativa. ¡Sigue leyendo!
Para comprender el papel de los RLHF, primero tenemos que hablar del proceso de formación de los LLM.
La tecnología subyacente de los LLM más populares es un transformador. Desde su desarrollo por investigadores de Google, los transformadores se han convertido en el modelo de vanguardia en el campo de la IA y el aprendizaje profundo, ya que proporcionan un método más eficaz para manejar datos secuenciales, como las palabras de una frase.
Para obtener una introducción más detallada a los LLM y los transformadores, consulta nuestro Curso de Conceptos de Modelos de Lenguaje Amplios (LLM).
Los Transformadores se entrenan previamente con un enorme corpus de texto recogido de Internet mediante aprendizaje autosupervisado, un tipo innovador de entrenamiento que no requiere la acción humana para etiquetar los datos. Los transformadores preentrenados son capaces de resolver una amplia gama de problemas de procesamiento del lenguaje natural (PLN).
Sin embargo, para que una herramienta de IA como ChatGPT proporcione respuestas atractivas, precisas y similares a las humanas, no bastará con utilizar un LLM preentrenado. Al final, la comunicación humana es un proceso creativo y subjetivo. Lo que hace que un texto sea "bueno" está profundamente influido por los valores y preferencias humanos, por lo que es muy difícil de medir o captar mediante una solución algorítmica clara.
La idea que subyace a la ELF es utilizar la información humana para medir y mejorar el rendimiento del modelo. Lo que hace que el RLHF sea único en comparación con otras técnicas de aprendizaje por refuerzo es el uso de la participación humana para optimizar el modelo en lugar de una función predefinida estadísticamente para maximizar la recompensa del agente.
Esta estrategia permite una experiencia de aprendizaje más adaptable y personalizada, lo que hace que los LLM sean adecuados para todo tipo de aplicaciones específicas del sector, como la asistencia de códigos, la investigación jurídica, la redacción de ensayos y la generación de poemas.
El RLHF es un proceso difícil que implica un proceso de entrenamiento con varios modelos y diferentes etapas de despliegue. En esencia, puede dividirse en tres pasos diferentes.
La primera etapa consiste en seleccionar un LLM preentrenado que luego se afinará mediante RLHF.
También podrías preparar tu LLM desde cero, pero es un proceso costoso y que requiere mucho tiempo. Por lo tanto, recomendamos encarecidamente elegir uno de los muchos LLM preformados disponibles para el público.
Si quieres saber más sobre cómo entrenar LLM, nuestro tutorial Cómo entrenar un LLM con PyTorch proporciona un ejemplo ilustrativo.
Ten en cuenta que, para satisfacer la necesidad específica de tu modelo, antes de iniciar la fase de ajuste fino mediante la retroalimentación humana, podrías ajustar tu modelo sobre textos o condiciones adicionales.
Por ejemplo, si quieres desarrollar un asistente jurídico de IA, podrías perfeccionar tu modelo con un corpus de texto jurídico para que tu LLM esté especialmente familiarizado con la redacción y los conceptos jurídicos.
En lugar de utilizar un modelo de recompensa predefinido estadísticamente (que sería muy restrictivo para calibrar las preferencias humanas), RLHF utiliza la retroalimentación humana para ayudar al modelo a desarrollar un modelo de recompensa más sutil. El proceso es el siguiente:
La siguiente imagen ilustra todo el proceso:
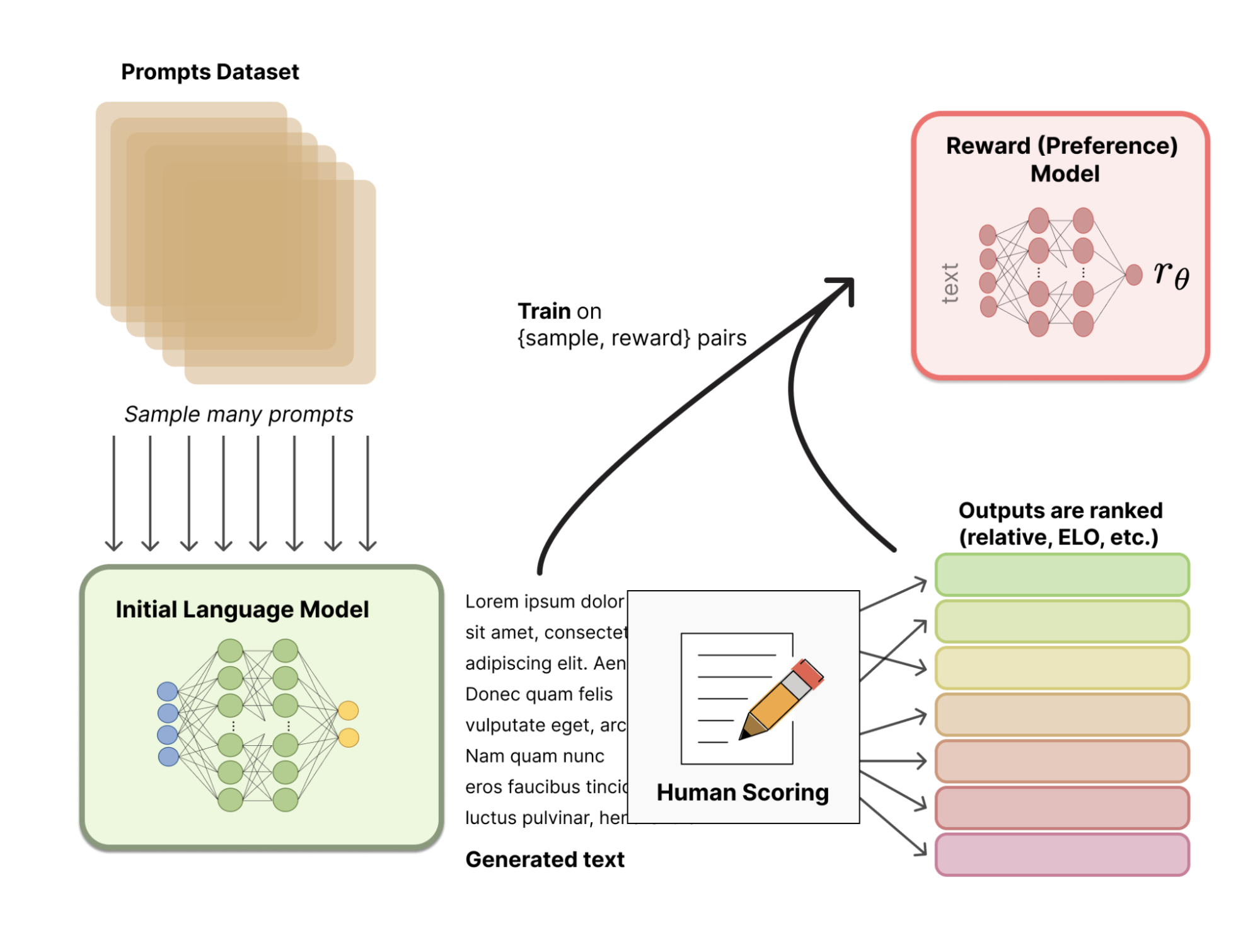
Fuente: Cara de abrazo
En la última etapa, el LLM produce nuevos textos y utiliza su modelo de recompensa basado en la retroalimentación humana para obtener una puntuación de calidad. A continuación, el modelo utiliza la puntuación para mejorar su rendimiento en las siguientes indicaciones.
De este modo, la retroalimentación humana y el ajuste con técnicas de aprendizaje por refuerzo se combinan en un proceso iterativo que continúa hasta que se alcanza un cierto grado de precisión.
RLHF es una técnica de vanguardia para afinar los LLM, como ChatGPT. Sin embargo, la RLHF es un tema popular, con una creciente literatura que explora otras posibilidades más allá de los problemas de PNL. A continuación encontrarás una lista de otros ámbitos en los que se ha aplicado con éxito el RLHF:
El RLHF es una técnica potente y prometedora sin la cual no serían posibles las herramientas de IA de próxima generación. Éstas son algunas de las ventajas del RLHF:
Sin embargo, el RLHF no es a prueba de balas. Esta técnica también plantea ciertos riesgos y limitaciones. A continuación, puedes ver algunas de las más relevantes:
RLHF es una de las columnas vertebrales de las herramientas modernas de IA generativa, como ChatGPT y GPT-4. A pesar de sus impresionantes resultados, la RLHF es una técnica relativamente nueva, y aún queda un amplio margen de mejora. La investigación futura sobre las técnicas de RLHF es fundamental para que los LLM sean más eficientes, reduzcan su huella medioambiental y aborden algunos de los riesgos y limitaciones de los LLM.
Para estar al día de los últimos avances en IA generativa, aprendizaje automático y LLM, te recomendamos encarecidamente que consultes nuestros materiales de aprendizaje curados:
Aprende los temas mencionados en este artículo
Curso
Curso
Curso
Tutorial
Matt Crabtree
Tutorial
Adel Nehme
Tutorial
Moez Ali
Tutorial
Moez Ali