Focus on solid data foundations and tooling
Having good quality data is a huge challenge in itself. We recommend companies that want to leverage machine learning, artificial intelligence, and data science to consider Monica Rogati’s AI Hierarchy of Needs, which has machine learning close to the top as one of the final pieces of the puzzle.
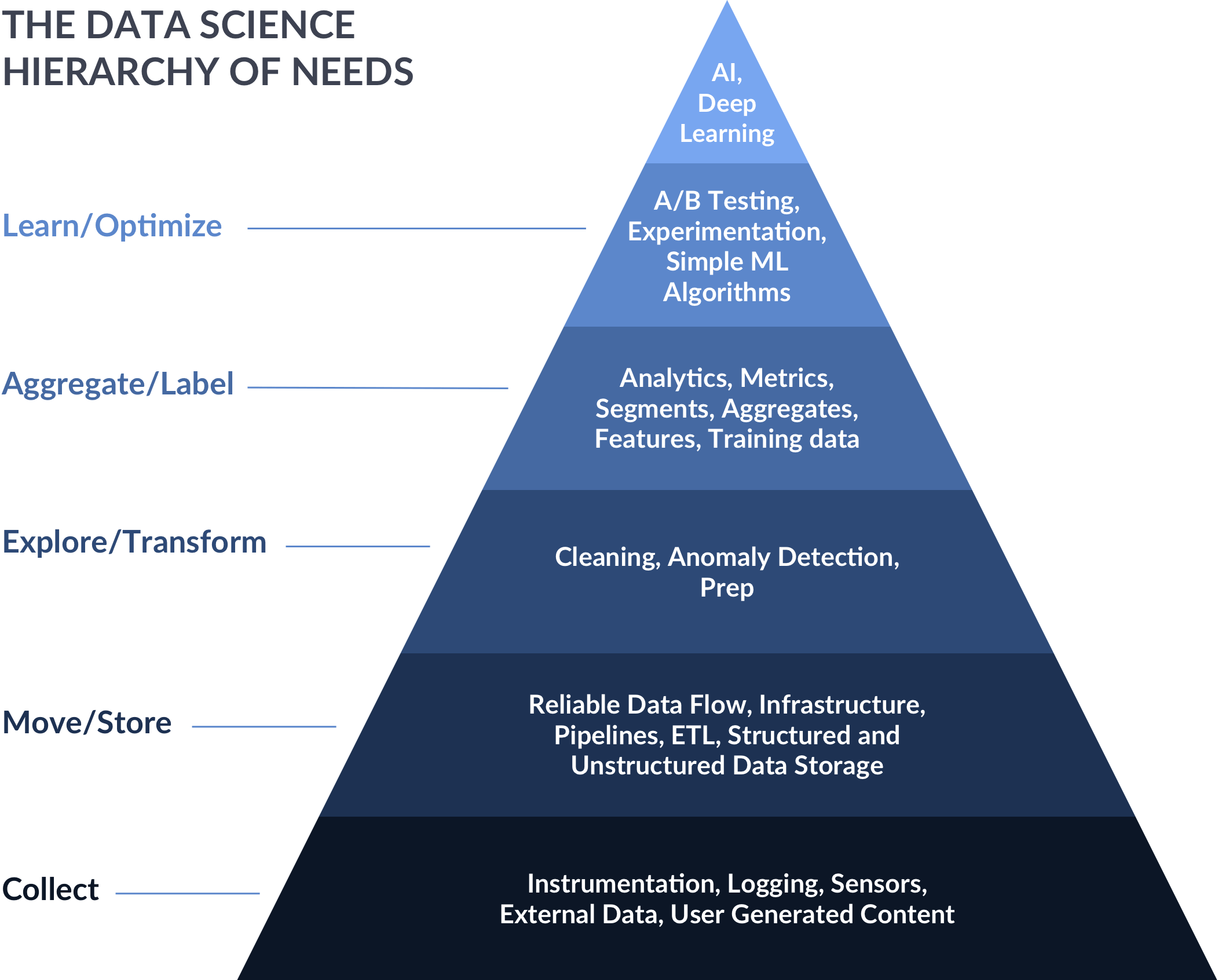
Source: Hackernoon
This hierarchy illustrates that before machine learning can happen, you need solid data foundations and tools for extracting, loading, and transforming data (ETL), as well as tools for cleaning and aggregating data from disparate sources.
This requires strong data engineering practices—you’ll need to leverage databases, understand how to process data correctly, schedule your workflows, and make use of cloud computing.
So before you hire your first machine learning engineer, you should first set up your data engineering, data science, and data analysis functions.
Beware of bias in your data and algorithms
Machine learning can only be as good as the data you feed it. If your data is biased, your model will be too. For example, Amazon built a ML recruiting tool to predict the success of applicants based on resumes with ten years’ worth of training data that favored males due to historic male dominance across the tech industry—which caused the ML tool to also be biased against women.
This is why data ethics has emerged as such an important topic in recent years. As more and more data is generated, the impact of how that data is used also scales dramatically. This requires principled consideration and monitoring. As Cassie Kozyrkov, Google's Chief Decision Scientist, has analogized, a teacher is only as good as the books they’re using to teach the students. If the books are biased, their lessons will be too.
Keep tabs on your model and improve it
Remember that the job of machine learning doesn’t end when your model is in production, making predictions, or performing classifications. Models that are deployed and doing work still need to be monitored and maintained.
If you have a model predicting credit card fraud based on transaction data, you get useful information every time your model makes a prediction and you act on it. On top of this, the activity you’re trying to monitor and predict—in this case, credit card fraud—may be dynamic and change over time. This process, where data that’s generated is constantly in flux, is called data drift—and it proves how essential it is to regularly update your model.
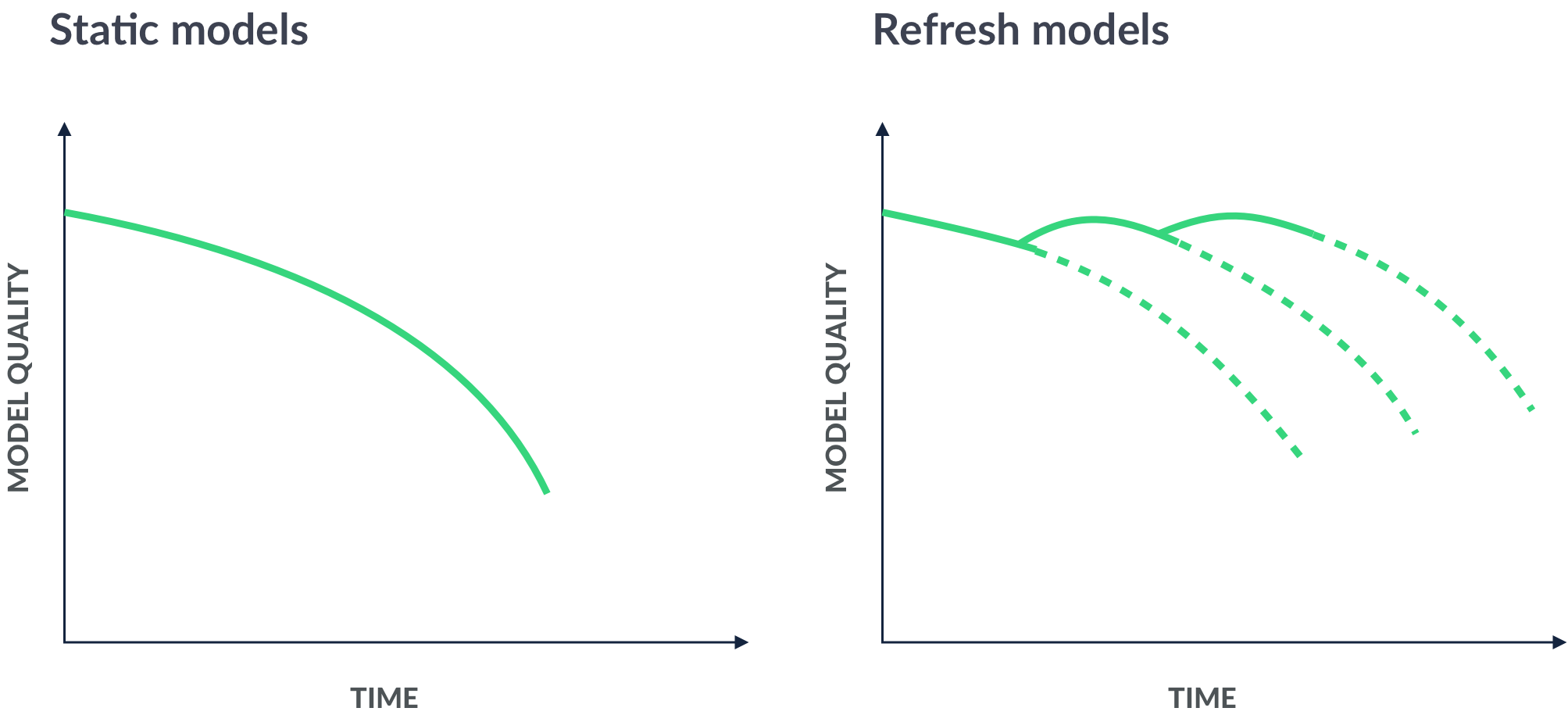
Source: DataBricks
