
Whisper es un modelo de reconocimiento automático del habla de uso general que se entrenó con un gran conjunto de datos de audio. El modelo puede realizar transcripciones multilingües, traducciones de voz y detección de idiomas.
Whisper puede utilizarse como asistente de voz, chatbot, traducción de voz al inglés, automatización de la toma de notas durante reuniones y transcripción.
La transcripción es un proceso de conversión del lenguaje hablado en texto. Antes se hacía manualmente, pero ahora disponemos de herramientas de inteligencia artificial como Whisper, capaces de comprender con precisión el lenguaje hablado.
Si tienes conocimientos básicos del lenguaje Python, puedes integrar la API OpenAI Whisper en tu aplicación. La API Whisper forma parte de openai/openai-pythonque te permite acceder a varios servicios y modelos de OpenAI.
Obtenga más información sobre la creación de aplicaciones de IA con LangChain en nuestro Building Multimodal AI Applications with LangChain & the OpenAI API AI Code Along, donde descubrirá cómo transcribir contenido de vídeo de YouTube con la IA de voz a texto Whisper y, a continuación, utilizar GPT para hacer preguntas sobre el contenido.
¿Cuáles son los buenos casos de uso de la transcripción?
- Transcripción de entrevistas, reuniones, conferencias y podcasts para su análisis, fácil acceso y mantenimiento de registros.
- Transcripción de voz en tiempo real para subtítulos (YouTube), subtitulación (reuniones Zoom) y traducción de lenguaje hablado.
- Transcripción de voz para uso personal y profesional. Transcripción de notas de voz, mensajes, recordatorios, memorandos y comentarios.
- Transcripción para personas con deficiencias auditivas.
- Transcripción de aplicaciones basadas en la voz que requieren la introducción de texto. Por ejemplo, chatbot, asistente de voz y traducción de idiomas.
¿Qué idiomas son compatibles?
Los idiomas admitidos para transcripciones y traducciones por la API OpenAI Whisper son:
Afrikaans, árabe, armenio, azerbaiyano, bielorruso, bosnio, búlgaro, catalán, chino, croata, checo, danés, neerlandés, inglés, estonio, finés, francés, gallego, alemán, griego, hebreo, hindi, húngaro, islandés, indonesio, italiano, japonés, kannada, kazajo, coreano, letón, lituano, macedonio, malayo, marathi, maorí, nepalí, noruego, persa, polaco, portugués, rumano, ruso, serbio, eslovaco, esloveno, español, swahili, sueco, tagalo, tamil, tailandés, turco, ucraniano, urdu, vietnamita y galés.
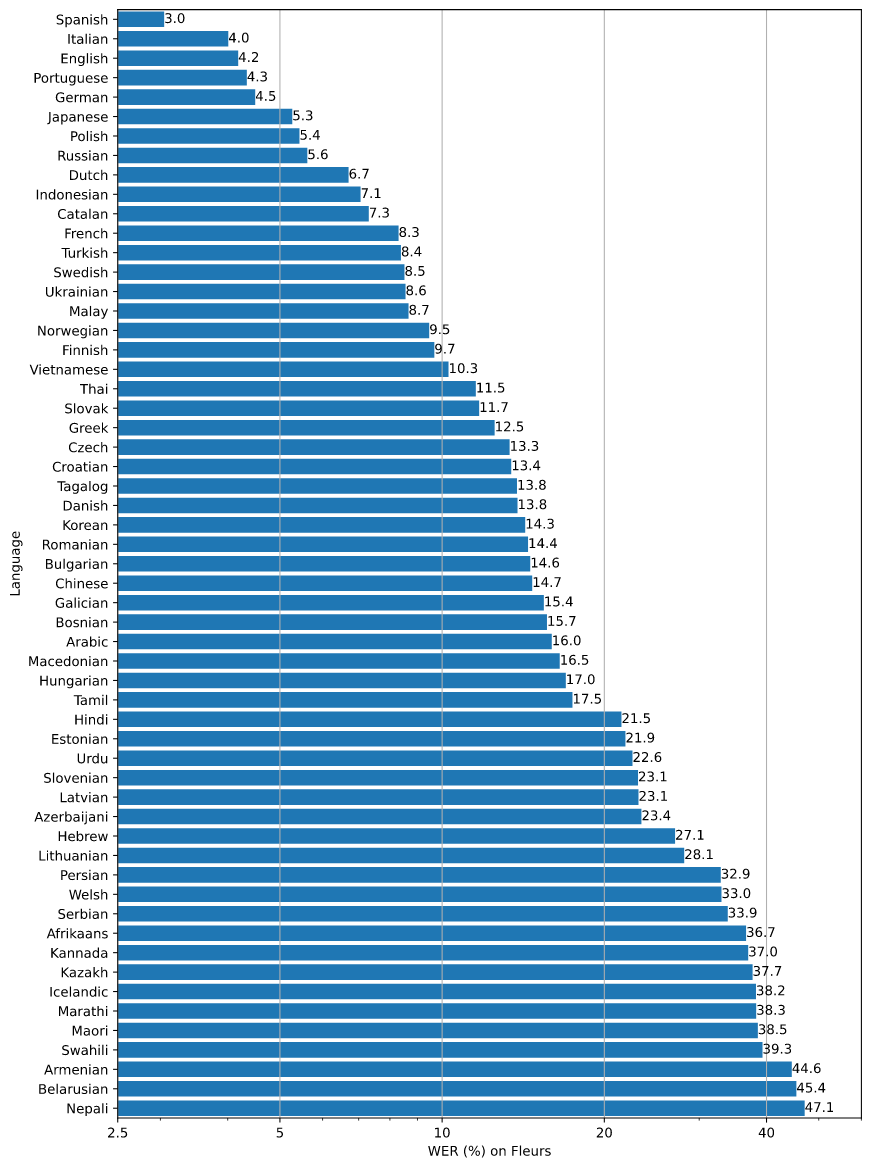
El desglose de la tasa de error por palabra (WER) para el conjunto de datos de Fleur utilizando el modelo large-v2 se presenta en la siguiente figura, clasificado por idiomas. Cuanto menor sea la WER, mayor será la precisión de la transcripción.
¿Qué formatos de archivo son compatibles?
Los formatos de archivo compatibles con la API Whisper son mp3, mp4, mpeg, mpga, m4a, wav y webm. Actualmente, el tamaño de los archivos cargados está limitado a 25 MB. Si tiene archivos de gran tamaño, puede dividirlos en trozos más pequeños utilizando pydub.
Conversión de voz a texto con la API OpenAI
En esta sección, utilizaremos la API de OpenAI para la transcripción y la traducción. Además, también estudiaremos varios tipos de formatos de salida.
Configurar
Puede instalar la API Python de OpenAI utilizando pip.
pip install openaiDespués de eso, tenemos que generar claves de API accediendo a API de OpenAI haciendo clic en la foto de la pantalla y seleccionando la opción "Ver claves API". Todas las nuevas cuentas de OpenAI vienen con créditos gratuitos de 5 $, así que no hay que preocuparse por añadir los datos de la tarjeta de crédito.
A continuación, haga clic en el botón "Crear nueva clave de seguridad", escriba el nombre de la clave y copie la clave generada.
Configure su clave API con una variable de entorno
Podemos configurar la clave API en nuestro sistema local escribiendo el siguiente comando en el terminal. Configurará una variable de entorno de API para que puedas utilizar los servicios de OpenAI.
export OPENAI_API_KEY='sk-...kMEM'Configure su clave API utilizando el paquete OpenAI
Puede configurar una clave dentro de su programa Python using openai.api_key. Este método no es recomendable ya que expone su API al público.
import openai
openai.api_key = "sk-...kMEM"Configure fácilmente su clave API en DataLab
Si utiliza DataLabtiene que hacer clic en Entorno > el icono 'más' y, a continuación, rellenar los nombres y valores de sus variables de entorno.
A continuación, deberá activar la variable de entorno haciendo clic en el botón Conectar.
Conjunto de datos
Inglés
Utilizaremos una pequeña parte del vídeo de Youtube de la entrevista a Marvin Minsky sobre la IA y la convertiremos en audio. El archivo marvin_minsky.mp3 tiene una duración de un minuto y un tamaño de 970 KB.
Español
Hemos recortado una pequeña parte de ¿Cómo utilizan la IA los barceloneses? Vídeo de YouTube en español para crear un archivo Easy_spanish_315.mp3. Tiene un tamaño de 509 KB y una duración de 20 segundos.
Transcripciones en inglés
La API de transcripciones es muy sencilla. Sólo tiene que cargar el archivo de audio con la sentencia with y añadir el objeto de audio a openai.Audio.transcribe. La función de transcripción sólo requiere un nombre de modelo y un objeto de audio, pero puede proporcionar language argumentos para una mayor precisión.
import openai
with open("Audio/marvin_minsky.mp3", "rb") as audio_file:
transcript = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="text",
language="en"
)
print(transcript)of theories called Steps Toward Artificial Intelligence around 1970. That sort of charted several possible lines of research, which pretty much predicted what several communities of researchers would do in the next 20 years. Those predictions started to fall apart around--so that paper was 1970, roughly. By the late 1980s, the world had changed. It was interesting because when I started research in that general area, almost all of my students soon became professors.Consulte la API de OpenAI en Python para una rápida revisión de lo que hace cada función. Podemos utilizar la hoja de trucos para conocer varios comandos de la API de OpenAI para la generación de texto, la transcripción de voz, la generación de imágenes, la incrustación y mucho más.
Formatos de salida alternativos
En el ejemplo anterior, hemos establecido que el formato de respuesta de salida sea texto simple, pero siempre puede cambiarlo a subtítulos subrip (response_format="srt"), subtítulos de pista de texto de vídeo (response_format="vtt") y metadatos (response_format="verbose_json").
En nuestros ejemplos, cambiaremos response_format por "srt" para obtener subtítulos como salida.
with open("Audio/marvin_minsky.mp3", "rb") as audio_file:
transcript2 = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="srt",
language="en"
)
print(transcript2)Como podemos ver, el texto de salida se divide en función de la marca de tiempo.
1
00:00:00,000 --> 00:00:10,960
of theories called Steps Toward Artificial Intelligence around 1970.
2
00:00:10,960 --> 00:00:24,320
That sort of charted several possible lines of research, which pretty much predicted what
3
00:00:24,320 --> 00:00:31,920
several communities of researchers would do in the next 20 years.
4
00:00:31,920 --> 00:00:42,040
Those predictions started to fall apart around--so that paper was 1970, roughly.
5
00:00:42,040 --> 00:00:48,200
By the late 1980s, the world had changed.
6
00:00:48,200 --> 00:00:56,760
It was interesting because when I started research in that general area, almost all
7
00:00:56,760 --> 00:01:16,920
of my students soon became professors.Transcripción al español
El Whisper ha sido entrenado en 98 idiomas, lo que le permite transcribir a múltiples lenguas. Para ello, hay que cambiar el argumento language.
En nuestro caso, estamos transcribiendo audio en español, y para ello, hemos configurado language="es"
with open("Audio/easy_spanish_315.mp3", "rb") as audio_file:
transcript_es = openai.Audio.transcribe(
file = audio_file,
model = "whisper-1",
response_format="text",
language="es"
)
print(transcript_es)¿Qué crees que es la inteligencia artificial? ¿Qué creo que es? Eh... no sé, no sé cómo describirlo. Algo que no es natural, obviamente. Eh... Pues la inteligencia artificial es mediante... mediante datos, eh... introducirle a un algoritmo.Traducciones del español al inglés
Sólo puede traducir su audio a la transcripción inglesa.
En el ejemplo, proporcionaremos la función `translate` con audio en español, y traducirá el audio en español al inglés.
with open("Audio/easy_spanish_315.mp3", "rb") as audio_file:
translate = openai.Audio.translate(
file = audio_file,
model = "whisper-1",
response_format="text",
language="en"
)
print(translate)What do you think artificial intelligence is? What do I think it is? I don't know how to describe it. Something that is not natural, obviously. Artificial intelligence is, through data, introduced to an algorithm.Pruebe este ejemplo dirigiéndose a este libro de trabajo DataLab. Contiene archivos de audio y un código fuente. Sólo tienes que hacer una copia del libro de trabajo y configurar una variable de entorno para que funcione.
Además, echa un vistazo a Uso de ChatGPT a través de la API OpenAI en el tutorial Python de Python. Le enseñará a utilizar la API de OpenAI para completar chats utilizando el modelo gpt-3.5-turbo.
¿Cómo mejorar el rendimiento de la transcripción?
Podemos mejorar la calidad de la transcripción utilizando un prompt argumento. Al proporcionar una transcripción parcial en el argumento prompt, estamos ayudando al modelo a comprender el estilo de escritura, la puntuación, las mayúsculas y la ortografía.
Uno de los principales inconvenientes del sistema actual es que ofrece poco control sobre el texto generado. Además, este proceso no puede automatizarse, ya que implica que una persona transcriba parcialmente el audio de forma manual.
¿Y ahora qué?
Puedes usar el código de ejemplo de este tutorial para crear un asistente de voz o usarlo para crear J.A.R.V.I.S. de Iron Man. Para conseguirlo, sólo tienes que descubrir la interfaz de usuario y cómo combinar Whisper, la conversión de texto a voz y la API ChatGPT, que hemos tratado en este formación en directo.
Si eres nuevo en ChatGPT, puedes tomar el curso de Introducción a ChatGPT para aprender las mejores prácticas para escribir avisos y traducir ChatGPT en valor empresarial. Y si está interesado en conocer la GPT-4 y cómo funcionan los modelos generativos, lea ¿Qué es GPT-4 y por qué es importante? También puede encontrar más recursos a continuación:
- [Webinar] Guía para principiantes sobre ingeniería de avisos con ChatGPT
- [Hoja de trucos] Hoja de trucos ChatGPT para científicos de datos
- [Hoja informativa] La API de OpenAI en Python
- [Podcast] ChatGPT y cómo la IA Generativa está aumentando los flujos de trabajo
- Empieza a aprender IA con DataCamp

