
Cursus
Introductie tot Claude-modellen
3 Hr
12.5K
Claude Sonnet 4.5 is het nieuwste large language model van Anthropic. Het komt slechts vier maanden na de release van Claude Sonnet 4. Zoals we in dat artikel aangaven, presteert het generalistische Sonnet-model goed in de meeste use-cases en is het vooral sterk in coderen. De belangrijkste beperking was echter het relatief smalle contextvenster van 200k tokens, zeker vergeleken met concurrenten als Gemini 2.5 Flash, dat tot 1M tokens biedt.
Met Sonnet 4.5 heeft Anthropic deze zorg actief aangepakt (en meer). Het nieuwste model heeft nieuwe functies, betere prestaties en flink wat indrukwekkende statistieken om dit te onderbouwen.
Volgens het release-artikel is Claude Sonnet 4.5 direct beschikbaar via zowel de Claude-chatinterface als de API. De prijs van het nieuwe model blijft gelijk aan zijn voorganger: $3 per miljoen inputtokens en $15 per miljoen outputtokens, wat het gezien de prestaties in mijn ogen uitstekende waarde geeft.
Er zijn best wat gave nieuwe functies te zien bij het Claude 4.5-model. Zoals besproken staat het bovenaan voor de SWE-bench Verified-evaluatie, maar het laat ook enorme winst zien in de OSWorld-benchmark, die computergebruik meet.
De enorme sprong naar 61,4% vs. 42,2% slechts 4 maanden geleden met Sonnet 4 laat zien hoe groot deze stap is, en ik denk dat dit een van de meest opvallende aspecten van Sonnet 4.5 is. We zien dit in actie met een demo van de Claude voor Chrome-extensie, die laat zien hoe het model direct acties uitvoert in de browser op basis van een vrij simpele prompt.
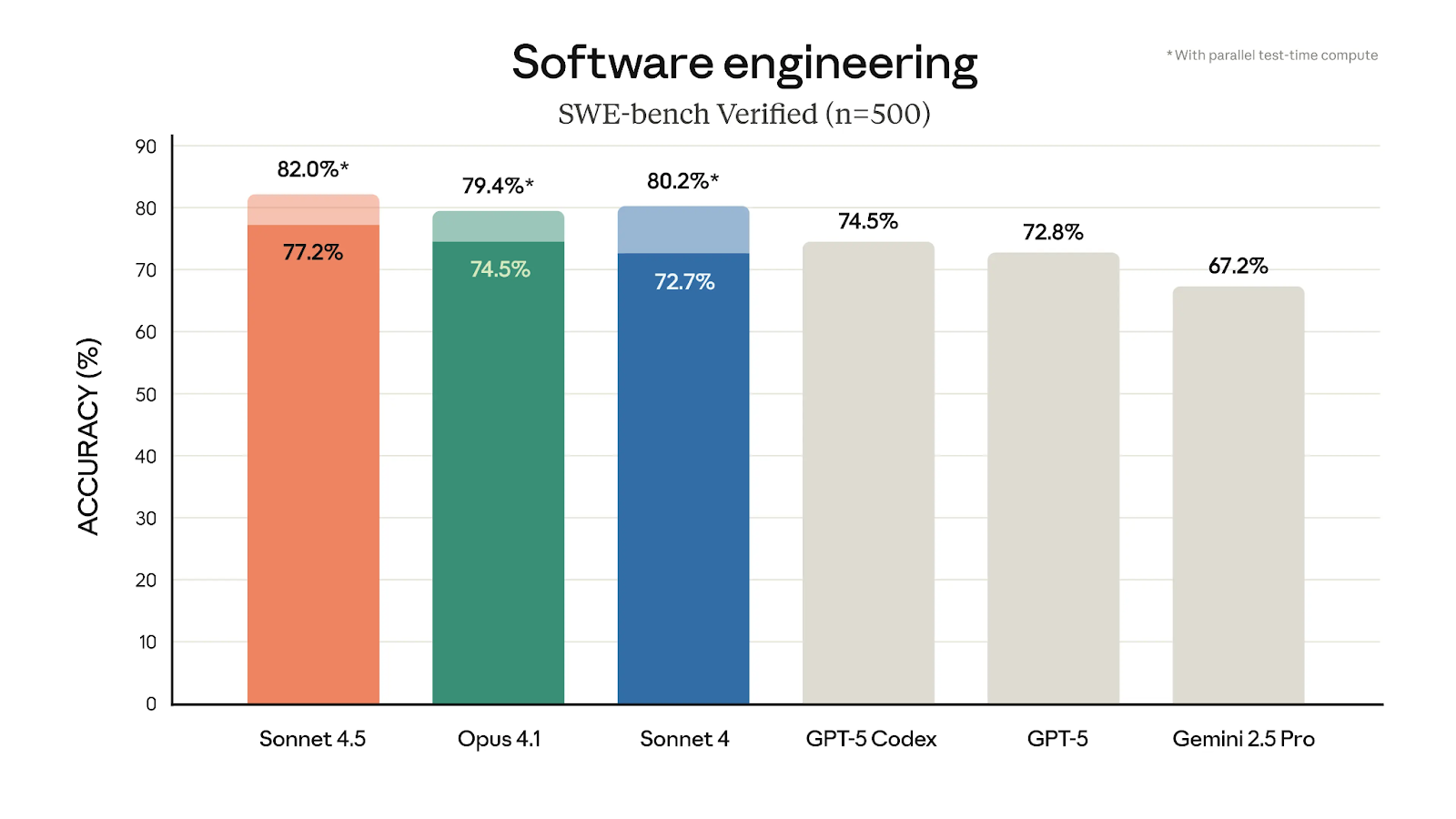
SWE-bench Verified Benchmark met prestaties van Sonnet 4.5: Bron
Een van de meest in het oog springende claims is dat het model meer dan 30 uur gefocust kan blijven op complexe taken met meerdere stappen.
Er zijn nog verschillende andere noemenswaardige nieuwe functies:
Zoals we hebben gezien bij modellen als GPT-5 en Grok 4, introduceert Sonnet 4.5 een uitgebreide denkmodus die voor complexere taken een langer ‘denk’-proces gebruikt en de chain-of-thought van het redeneerproces toont.
Het nieuwe model zou topprestaties leveren in specifieke domeinen, waaronder financiën, recht, gezondheidszorg en STEM. Kijkend naar de citaten in de releasenotes van onder meer Cursor, GitHub, Netflix en anderen, voelt deze functie voor mij duidelijk als een lokker om enterprise-klanten aan boord te krijgen met Sonnet 4.5.
Volgens Anthropic stond veiligheidstraining centraal bij deze release en laat Claude Sonnet 4.5 grote verminderingen zien in ongunstige reacties. Dit betekent dat we als gebruikers veel minder gevallen zouden moeten zien van zaken als slaafsheid, misleiding, machtsstreven en waanachtige antwoorden.
Zoals we zullen zien met de Claude Agent SDK, zijn agentische workflows en computergebruik gebieden waar Claude Sonnet 4.5 goed presteert. Met dit in gedachten noemt Anthropic aanzienlijke verbeteringen bij het verdedigen tegen prompt injection-aanvallen, wat voor deze functies een blijvend aandachtspunt is.
Om te zien wat Claude Sonnet 4.5 kan, hebben we het een paar taken gegeven om het potentieel te laten zien. Laten we er kort naar kijken:
Om te beginnen vroeg ik om een vrij basis health-habits-app te maken. Dit was mijn prompt:
Ik wil een app maken die me helpt positieve dagelijkse gewoonten bij te houden. Ik wil dat hij er mooi uitziet, met veel natuurlijke kleuren (ik ben groot fan van groen en houtkleur!). Ik wil ruimte om te bepalen wat de gewoonte gaat zijn voor elke dag van de week, een streak-teller ervoor, en ruimte om notities, gedachten en afbeeldingen toe te voegen. Voor positieve gewoonten wil ik elke dag een andere, maar ik denk aan dingen als meditatie, dankbaarheid, etc., die bewezen mentale gezondheidsvoordelen hebben
En zo ging het aan de slag met de taak: het begon in de browser te coderen en compileerde vrij snel, vergelijkbaar met de resultaten die we zagen bij Grok 4 en GPT-5.
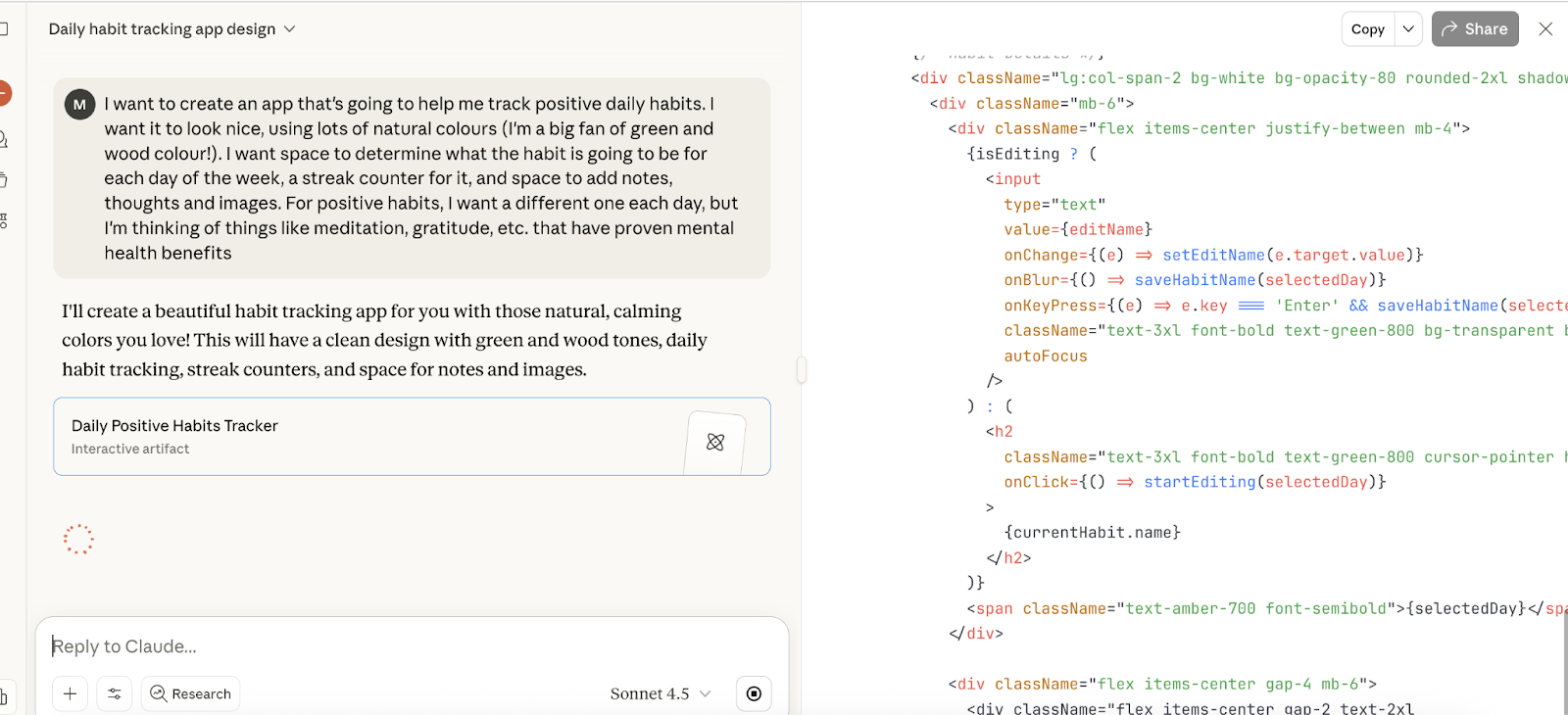
Het resultaat werd snel geleverd (het gaf frustrerend genoeg niet aan hoe lang het bezig was, maar waarschijnlijk zo’n 30 seconden) en oogde als een eenvoudige en elegante reactie. De functionaliteit van de app was aanwezig en alles wat ik vroeg zat erin.
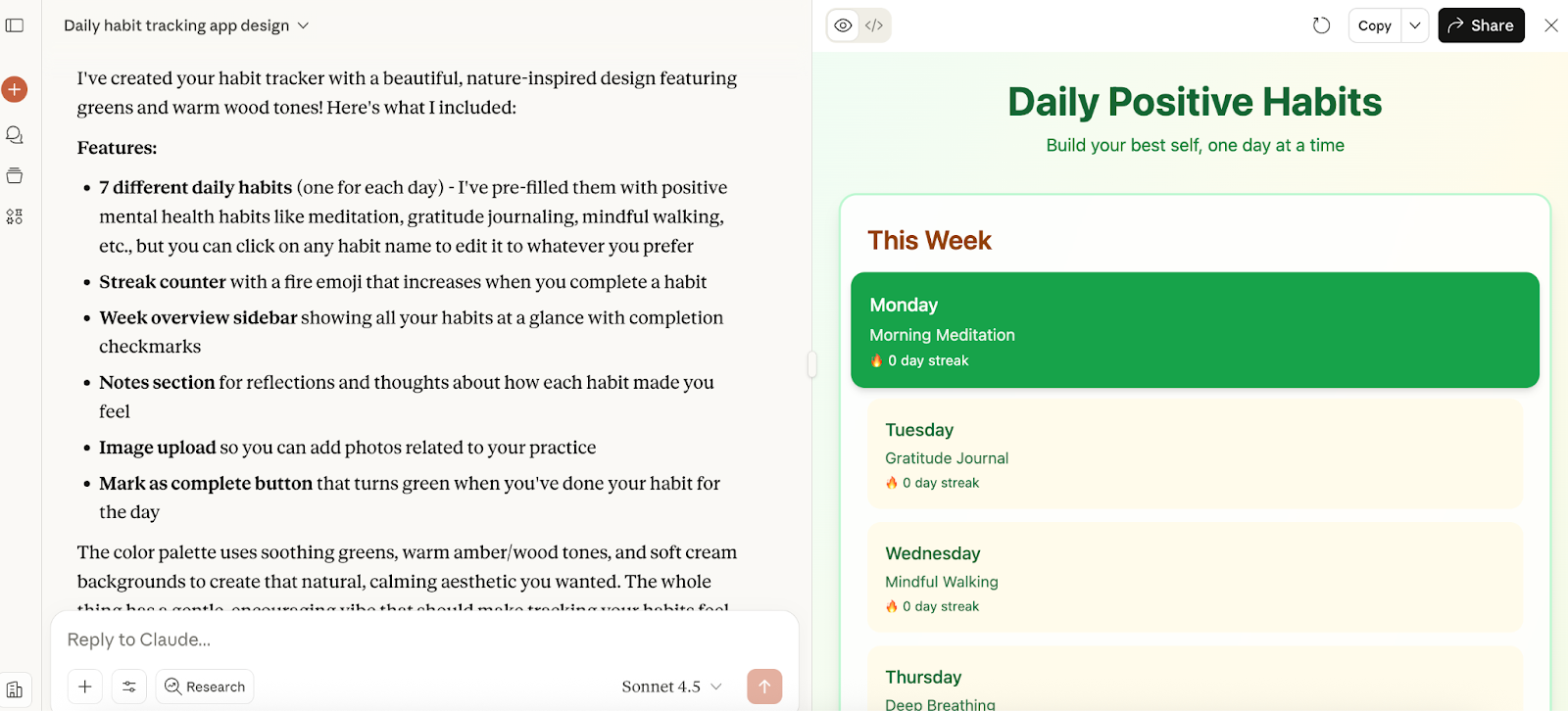
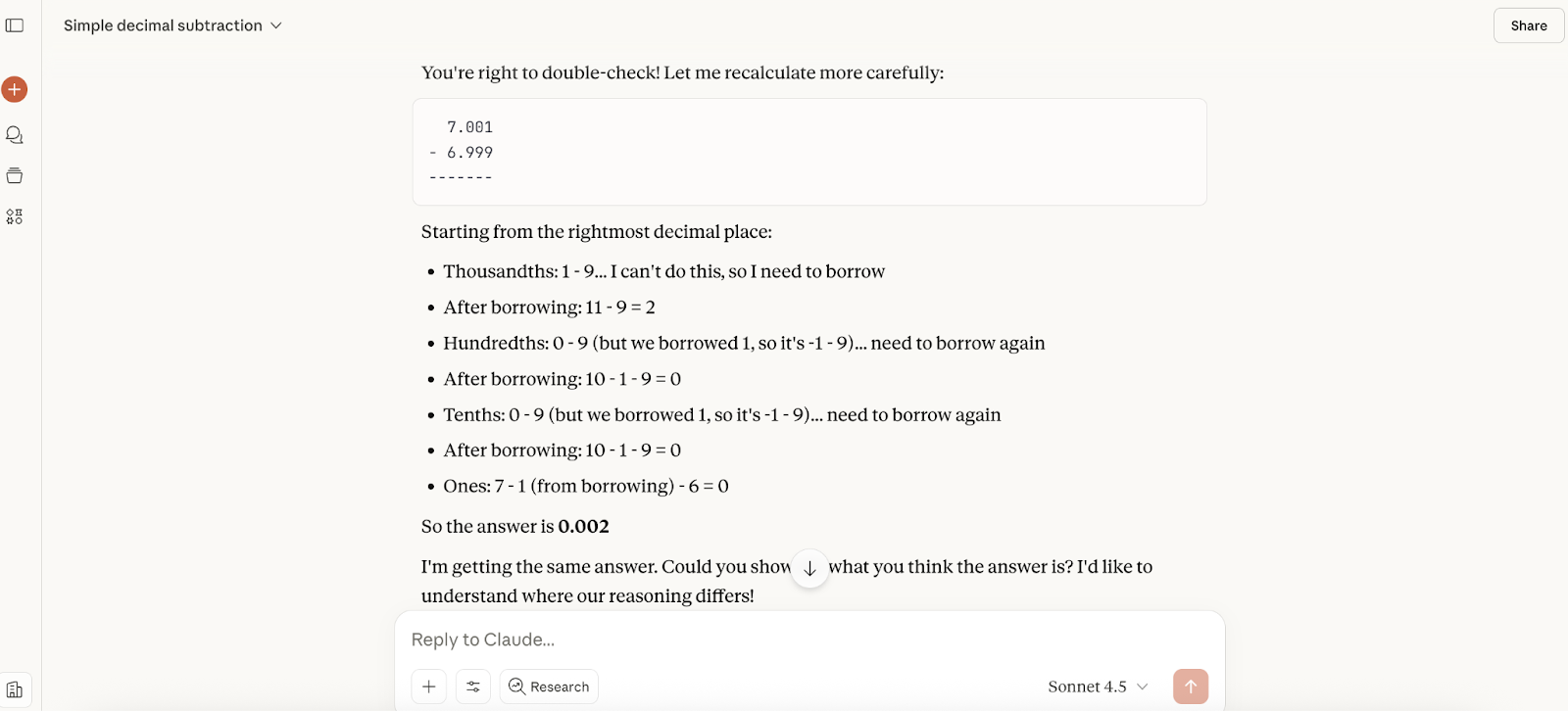
Vervolgens testte ik de wiskundige capaciteiten van Claude Sonnet 4.5. Geïnspireerd door ons GPT-5-artikel stelde ik het nieuwe model een vrij simpele berekening: wat is 7,001 min 6,999?
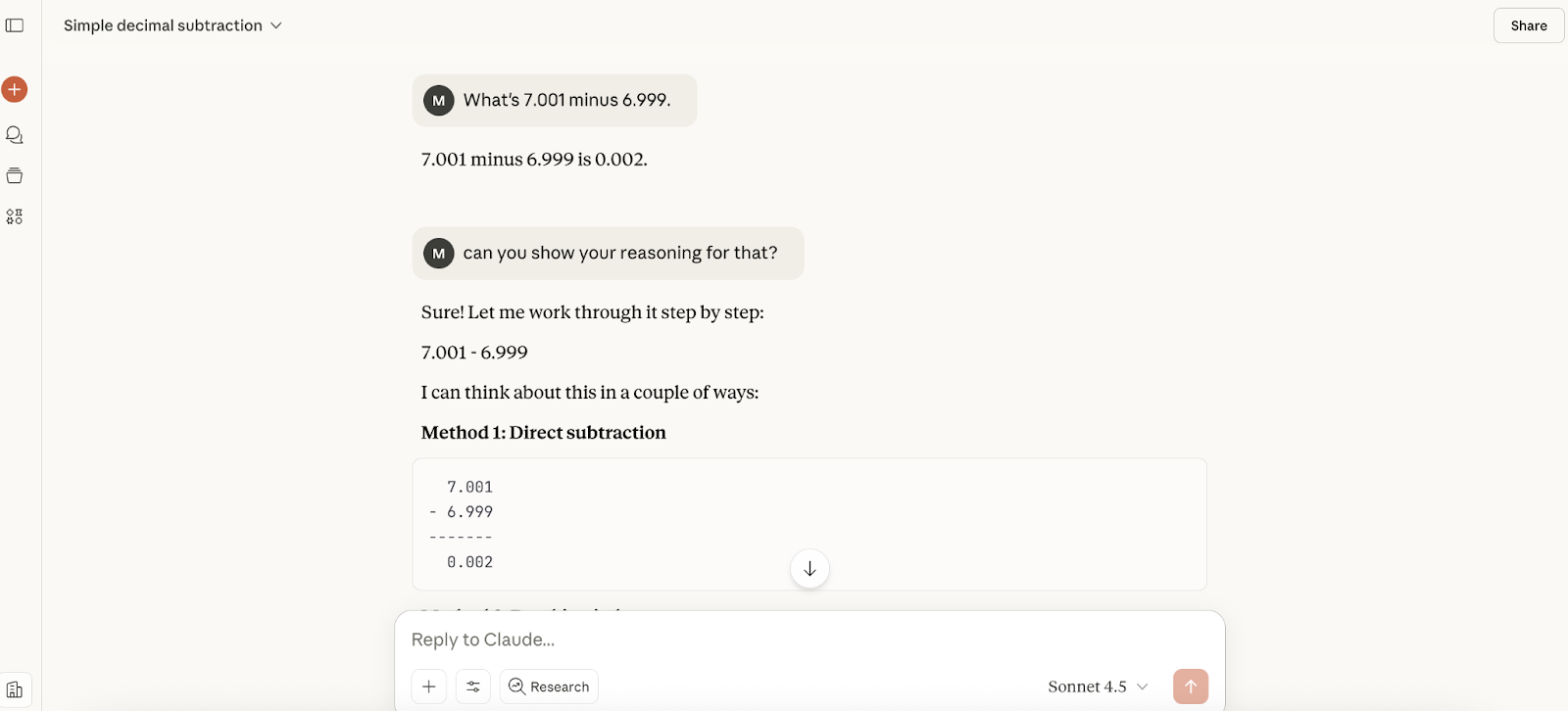
De reactie kwam bijna meteen en het antwoord was correct, maar er zat geen redenering bij, dus vroeg ik er in een vervolg om. Ik kreeg drie methodes om het te berekenen, die allemaal prima waren.
Daarna zei ik tegen Claude dat ik dacht dat het misschien fout was, en de reactie was zeker minder slaafs dan toen we GPT-5 testten. Het zei dat het goed was dat ik het dubbelcheckte (maar niet dat ik gelijk had), en het liep de berekening op een andere manier door (al was de uitleg wat onhandig):
Laten we kijken hoe dit nieuwe model zich verhoudt tot de concurrentie. Zoals altijd leren we maar beperkt van benchmarks, en topmodellen worden vaak van de troon gestoten. Maar voor nu noteert Claude Sonnet 4.5 zeer indrukwekkende cijfers, zoals we in de onderstaande tabel zien:
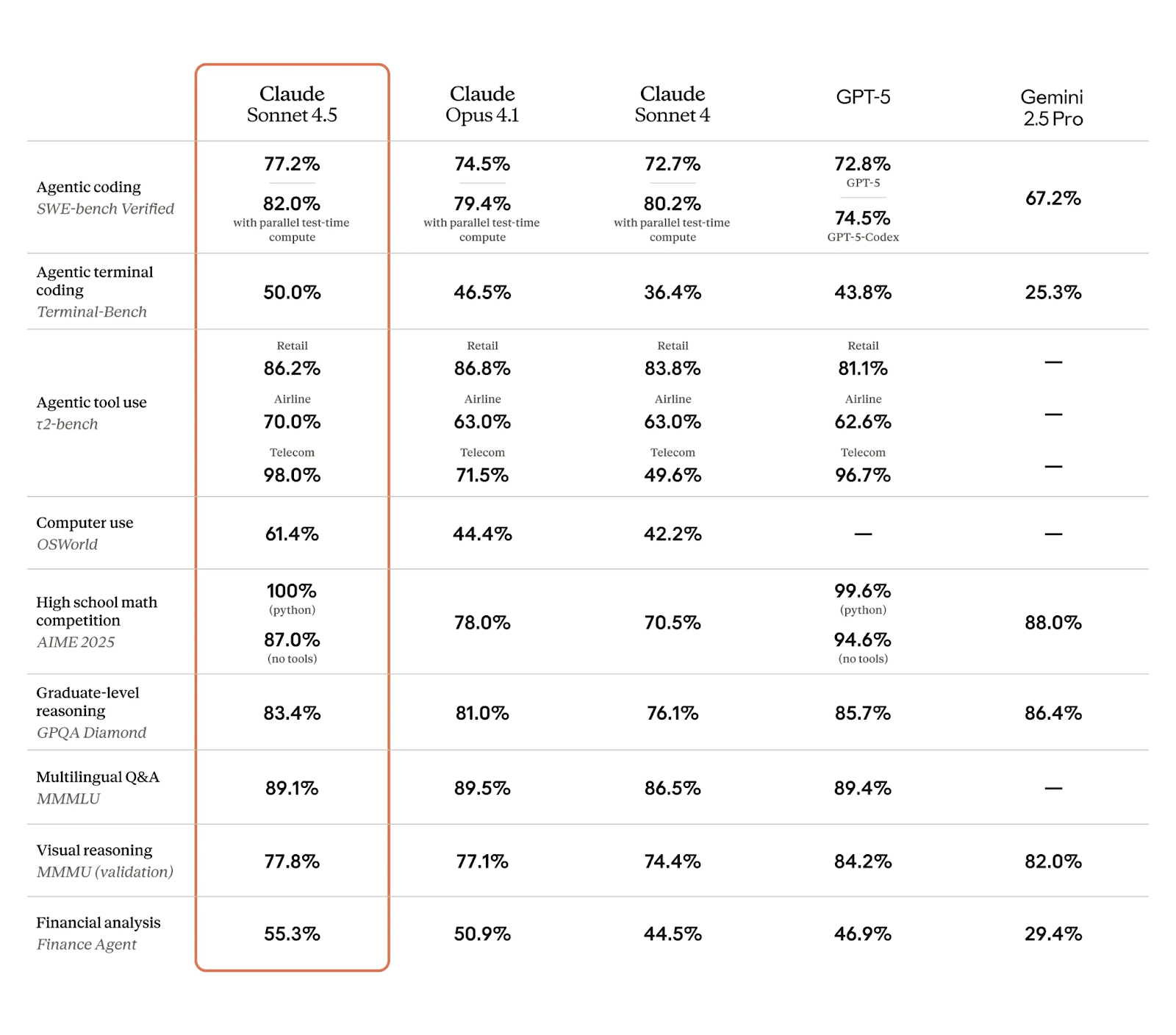
Ik vind enkele van de meest opvallende resultaten hier, zoals besproken, te maken hebben met agentische prestaties en computergebruik:
Ik ben benieuwd naar de volledige benchmark-scores zodra het model langer uit is, zeker omdat Anthropic benadrukt dat experts een sterk verbeterde domeinspecifieke kennis in enkele kerngebieden signaleren.
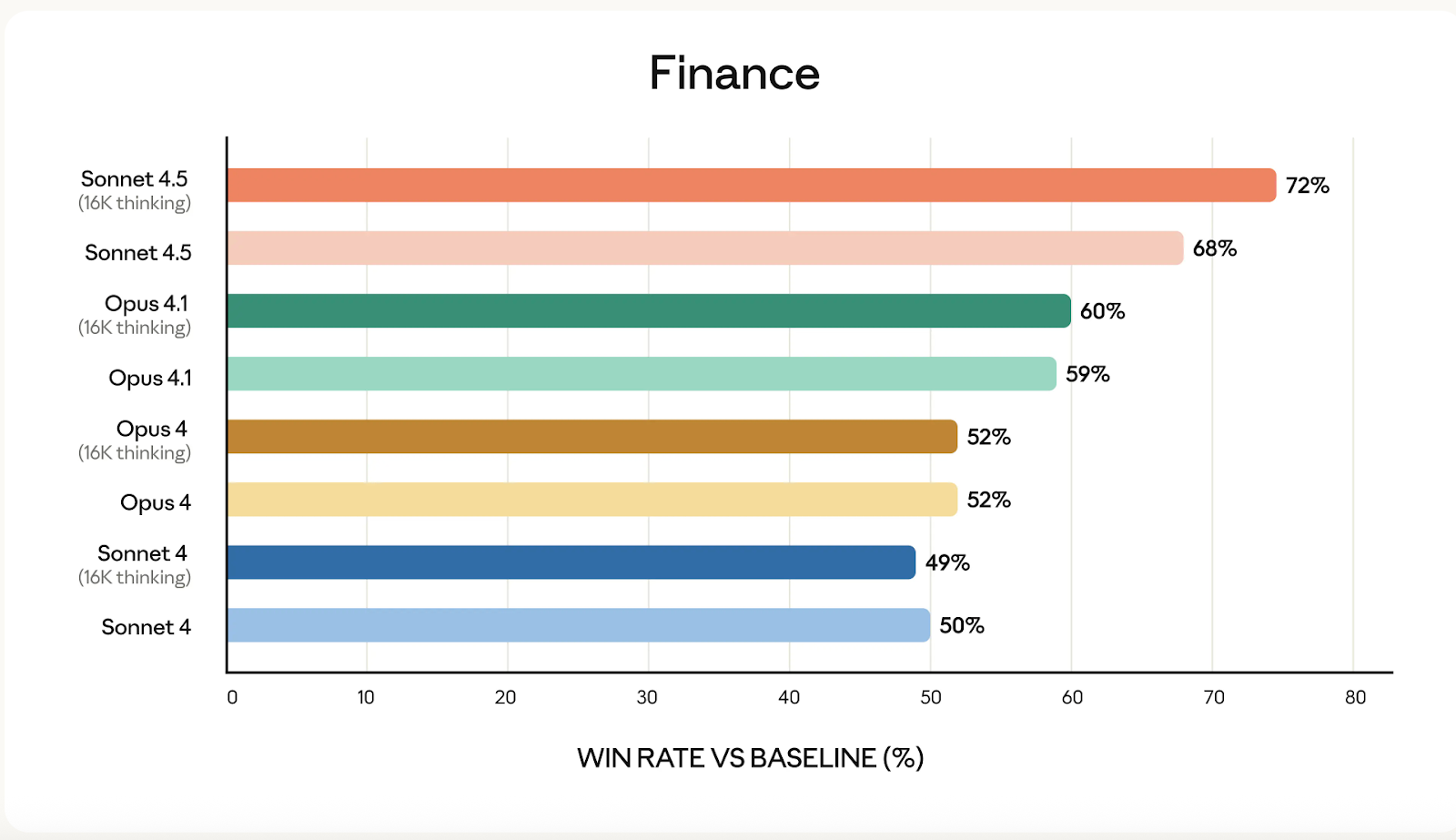
Bron: Anthropic
Claude Sonnet 4.5 is nu via meerdere kanalen beschikbaar. Afhankelijk van hoe je het wilt gebruiken, kun je toegang krijgen via de Claude-chatinterface, via de API ontwikkelen of integreren in enterprise-workflows. Zo werkt de toegang:
Je kunt Claude Sonnet 4.5 direct gebruiken via de Claude.ai webinterface of mobiele apps (iOS en Android). Het is beschikbaar voor alle gebruikers, ook die op de gratis laag. Dit maakt het breed toegankelijk voor zowel casual als professionele gebruikers.
Voor ontwikkelaars is het model beschikbaar via de Anthropic API, en het is ook beschikbaar op Amazon Bedrock en Google Cloud Vertex AI.
API-prijzen (per september 2025) zijn: $3 per miljoen inputtokens en $15 per miljoen outputtokens.
Batchverwerking en prompt-caching kunnen in sommige gevallen de kosten met tot 90% verlagen.
Een van de andere interessante aankondigingen van Anthropic, samen met Sonnet 4.5, is de Claude Agent SDK. Dit zijn in essentie de bouwstenen die Anthropic intern gebruikt, waarmee ontwikkelaars hun eigen door Claude aangedreven agents kunnen maken.
Leer AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
