
Kursus
Pengantar Model Claude
3 Hr
12.5K
Claude Sonnet 4.5 adalah model bahasa besar terbaru dari Anthropic. Model ini hadir hanya empat bulan setelah perilisan Claude Sonnet 4. Seperti kami catat dalam artikel tersebut, model Sonnet yang bersifat generalis berkinerja baik di sebagian besar kasus penggunaan, dan sangat kuat dalam hal coding. Namun, keterbatasan utamanya adalah jendela konteks yang relatif sempit, 200 ribu token, terutama jika dibandingkan dengan pesaing seperti Gemini 2.5 Flash yang menawarkan hingga 1 juta token.
Dengan Sonnet 4.5, Anthropic secara aktif menanggapi kekhawatiran ini (dan lainnya). Model terbaru memiliki fitur baru, performa lebih baik, dan banyak statistik mengesankan untuk mendukungnya.
Menurut artikel rilisnya, Claude Sonnet 4.5 tersedia segera melalui antarmuka chat Claude dan API. Harga model baru ini tetap sama seperti pendahulunya, yaitu $3 per satu juta token input dan $15 per satu juta token output, yang menurut saya menawarkan nilai sangat baik mengingat performanya.
Ada cukup banyak fitur baru yang menarik pada model Claude 4.5. Seperti yang telah kami bahas, model ini memuncaki grafik evaluasi SWE-bench Verified, tetapi juga menunjukkan lonjakan besar pada tolok ukur OSWorld, yang mengukur kemampuan penggunaan komputer.
Lompatan besar ke 61,4% dibandingkan 42,2% hanya 4 bulan lalu pada Sonnet 4 menunjukkan betapa besarnya peningkatan ini, dan menurut saya menjadi salah satu aspek paling menonjol dari Sonnet 4.5. Kita melihatnya beraksi melalui demo ekstensi Claude untuk Chrome, yang menampilkan model mengambil tindakan langsung di browser berdasarkan prompt yang cukup sederhana.
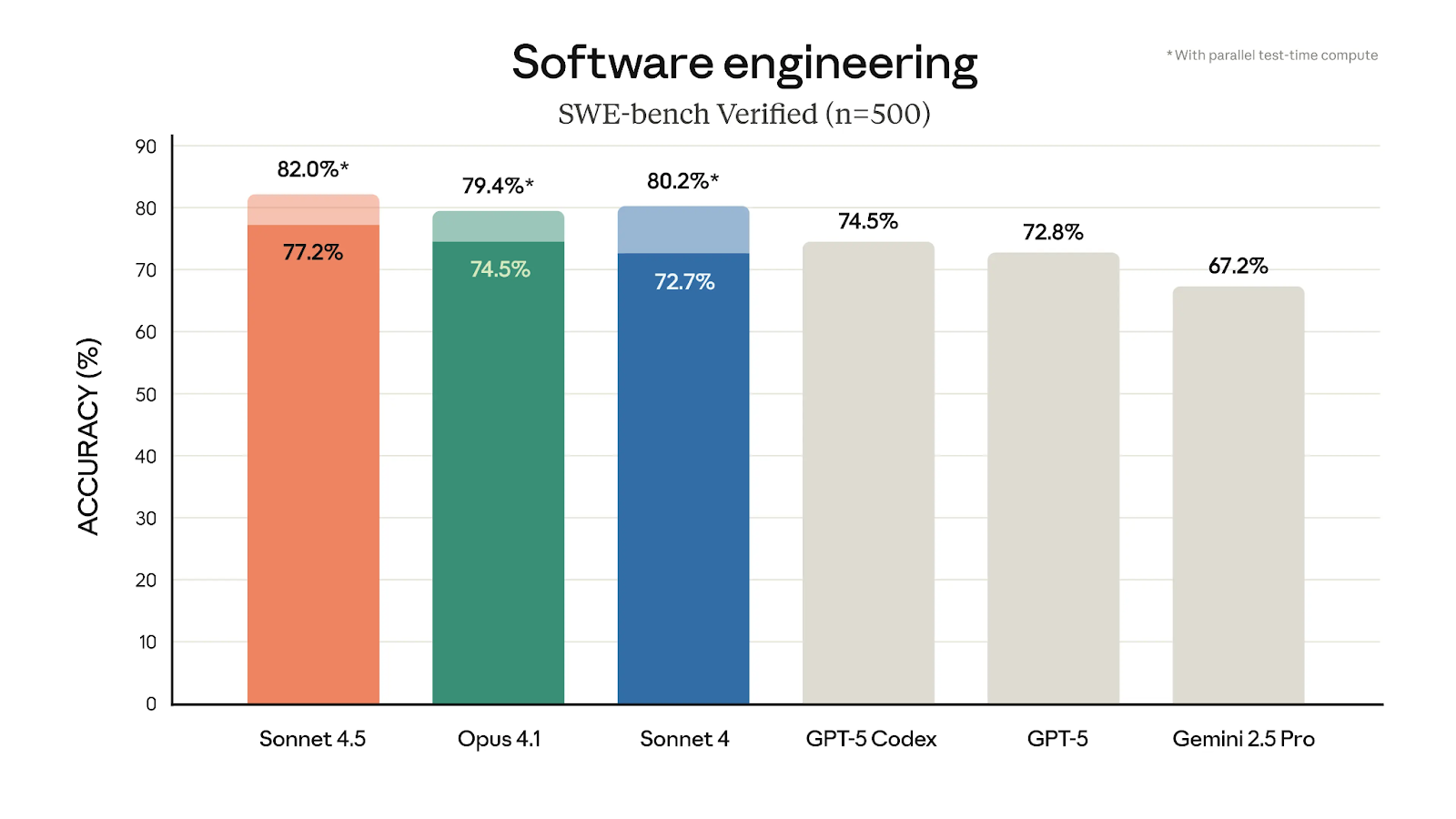
Tolok Ukur SWE-bench Verified menampilkan Performa Sonnet 4.5: Sumber
Salah satu klaim yang paling mencuri perhatian adalah kemampuan model untuk mempertahankan fokus lebih dari 30 jam pada tugas kompleks yang bertahap.
Ada juga beberapa fitur baru lain yang patut diperhatikan:
Seperti yang kita lihat pada model seperti GPT-5 dan Grok 4, Sonnet 4.5 memperkenalkan mode berpikir yang diperpanjang, yang untuk tugas lebih kompleks menggunakan proses ‘berpikir’ lebih lama dan menampilkan chain-of-thought untuk proses penalaran.
Model baru ini kabarnya mencatat performa teratas pada domain tertentu, termasuk keuangan, hukum, medis, dan STEM. Lagi-lagi, melihat kutipan dalam catatan rilis dari pihak seperti Cursor, GitHub, Netflix, dan lainnya, saya merasa fitur ini memang ditujukan untuk menarik pelanggan perusahaan agar mengadopsi Sonnet 4.5.
Menurut Anthropic, pelatihan keamanan menjadi pusat dari rilis baru ini, dan Claude Sonnet 4.5 menunjukkan penurunan besar pada respons yang tidak diinginkan. Artinya, sebagai pengguna, kita akan melihat berkurangnya secara drastis hal-hal seperti penjilat, tipu daya, mencari kekuasaan, dan respons delusional.
Seperti yang akan kita lihat pada Claude Agent SDK, alur kerja agentic dan penggunaan komputer adalah area di mana Claude Sonnet 4.5 berkinerja baik. Dengan ini, Anthropic menyebut adanya peningkatan besar dalam bertahan dari serangan prompt injection, yang tetap menjadi perhatian untuk fungsi-fungsi ini.
Untuk melihat kemampuan Claude Sonnet 4.5, kami memberinya beberapa tugas untuk menunjukkan potensinya. Mari kita lihat sekilas masing-masing:
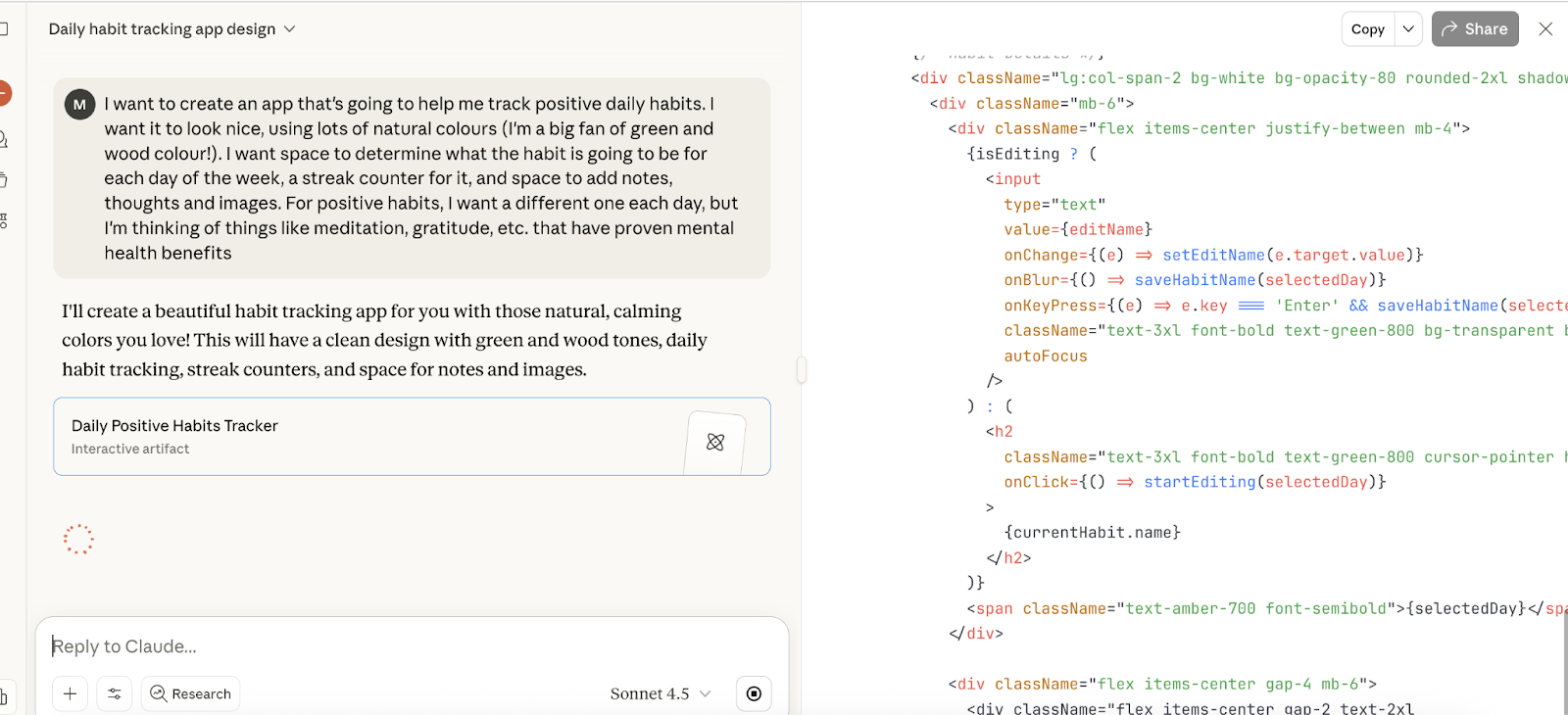
Untuk memulai, saya memintanya membuat aplikasi kebiasaan sehat yang cukup dasar. Ini prompt saya:
Saya ingin membuat aplikasi yang akan membantu saya melacak kebiasaan positif harian. Saya ingin tampilannya bagus, menggunakan banyak warna alami (saya penggemar berat hijau dan warna kayu!). Saya ingin ada ruang untuk menentukan kebiasaan untuk setiap hari dalam seminggu, penghitung streak untuk itu, serta ruang untuk menambahkan catatan, pemikiran, dan gambar. Untuk kebiasaan positif, saya ingin yang berbeda setiap hari, tetapi saya memikirkan hal-hal seperti meditasi, rasa syukur, dll., yang terbukti bermanfaat bagi kesehatan mental
Dan ini saat ia mengerjakan tugasnya — ia mulai menulis kode di browser dan melakukan kompilasi cukup cepat, lagi-lagi mirip dengan hasil yang terlihat pada Grok 4 dan GPT-5.
Hasilnya disajikan dengan cepat (sayangnya, ia tidak memberi tahu berapa lama ia bekerja, tetapi kemungkinan hanya sekitar 30 detik) dan tampak sebagai respons yang sederhana dan elegan. Fungsionalitas aplikasi ada, dan mencakup semua yang saya minta.
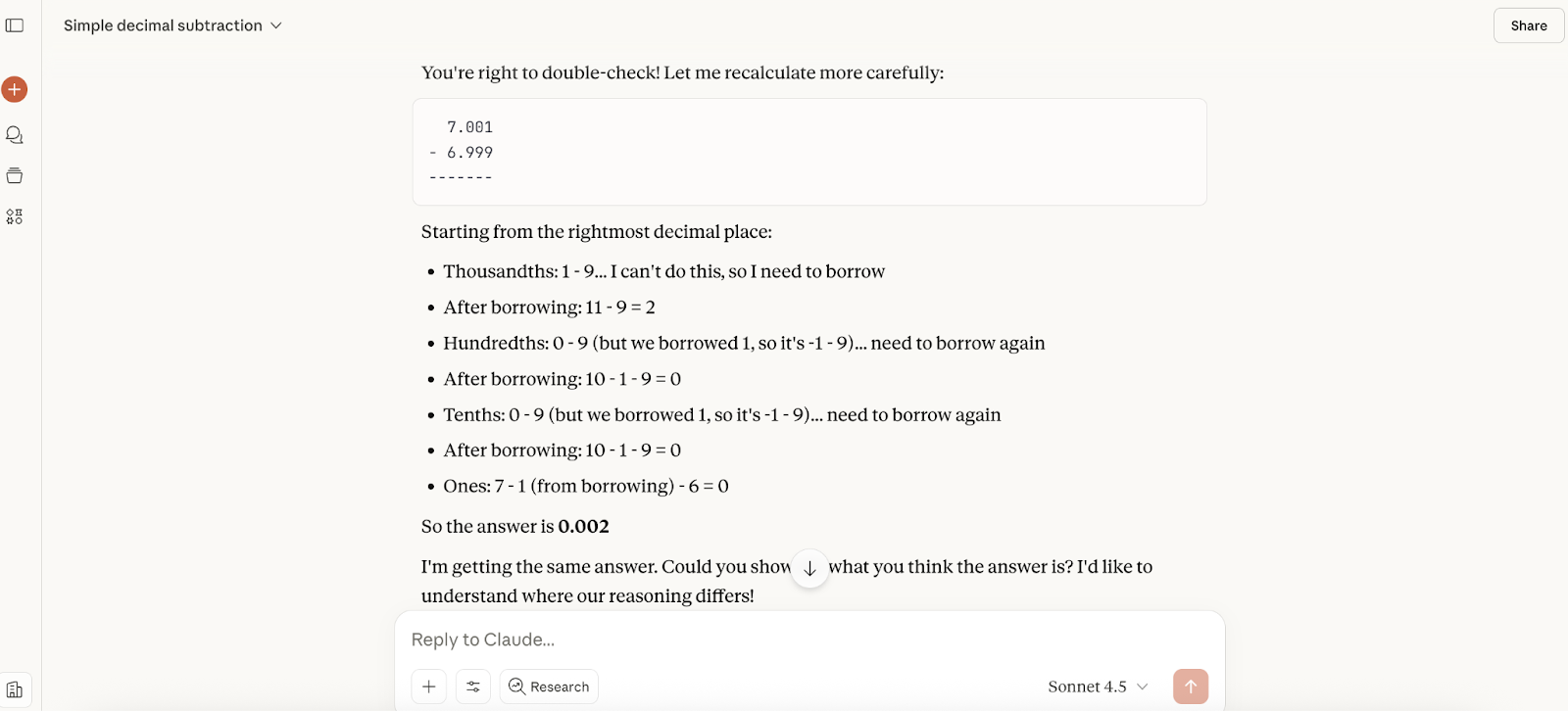
Berikutnya, saya menguji kemampuan matematika Claude Sonnet 4.5. Terinspirasi dari artikel GPT-5 kami, saya menanyakan perhitungan yang cukup sederhana pada model baru ini; berapa 7,001 dikurangi 6,999?
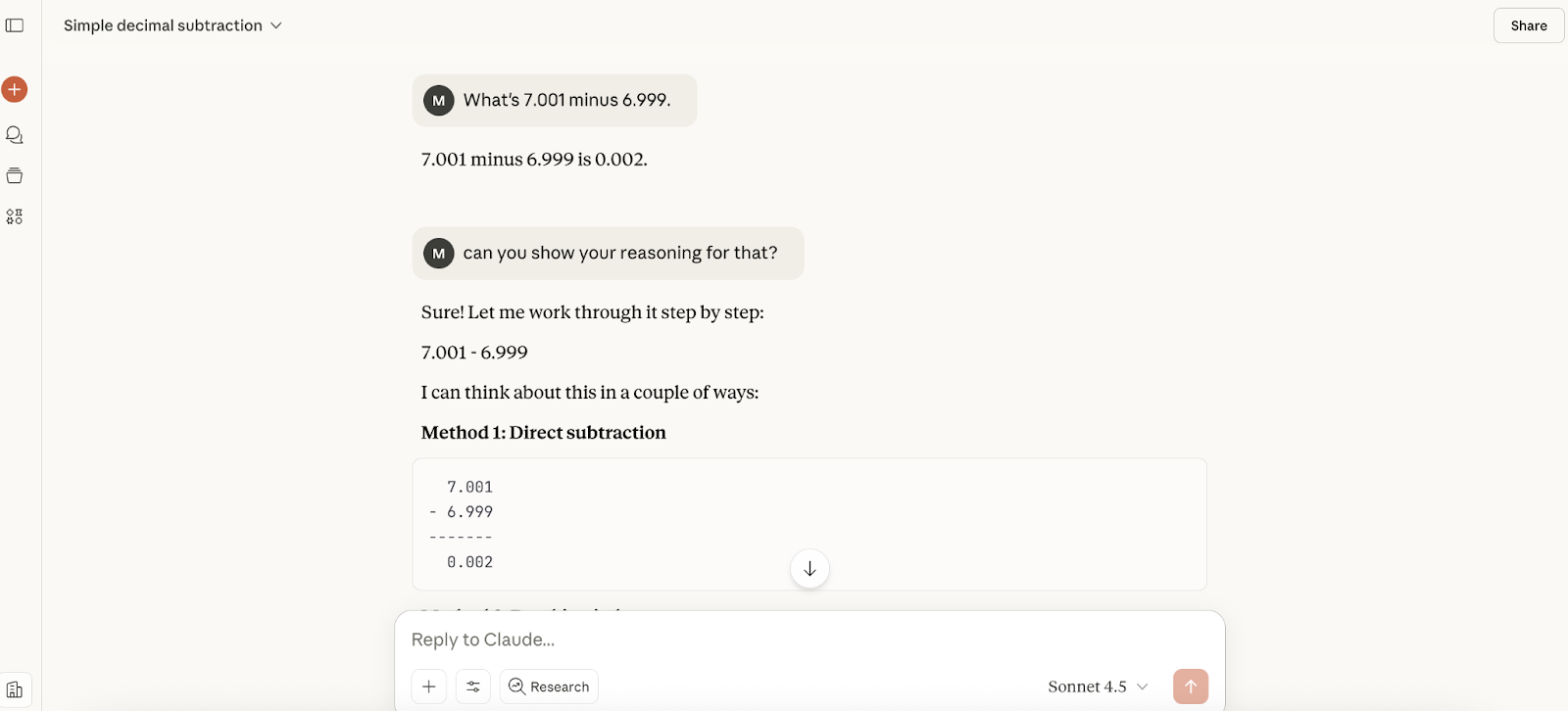
Responsnya hampir seketika, dan jawabannya benar, tetapi tidak memberikan penalaran, jadi saya memintanya memberikan penjelasan lanjutan. Ia memberi saya tiga metode perhitungan, semuanya baik.
Kemudian saya memberi tahu Claude bahwa saya pikir jawabannya mungkin salah, dan responsnya jelas kurang menjilat dibandingkan saat kami menguji GPT-5. Ia mengatakan saya benar untuk memeriksa ulang (namun bukan berarti benar), dan menuntun saya melalui perhitungan dengan cara berbeda (meskipun penjelasannya agak canggung):
Mari kita lihat bagaimana model baru ini dibandingkan dengan kompetitornya. Seperti biasa, kita hanya bisa belajar sejauh tertentu dari tolok ukur, dan model-model teratas sering digeser dari puncak. Namun untuk saat ini, Claude Sonnet 4.5 mencatat angka yang sangat mengesankan, seperti terlihat pada tabel di bawah ini:
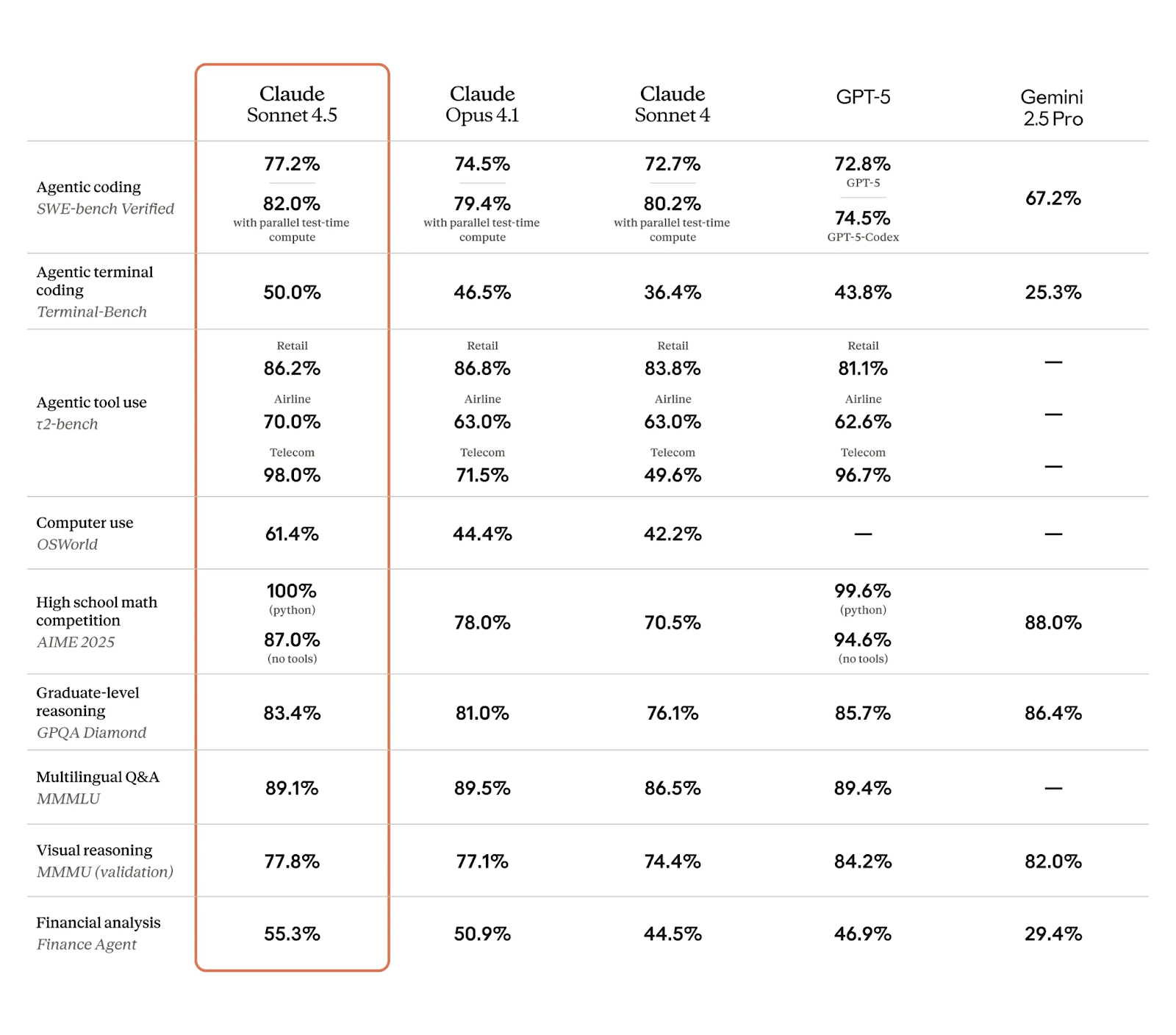
Menurut saya, beberapa hasil yang paling menonjol di sini, seperti dibahas, berkaitan dengan performa agentic dan penggunaan komputer:
Saya penasaran melihat skor tolok ukur lengkap setelah model ini beredar beberapa waktu, terutama karena Anthropic menekankan bahwa para pakar memuji peningkatan besar pengetahuan domain-spesifik di beberapa area kunci.
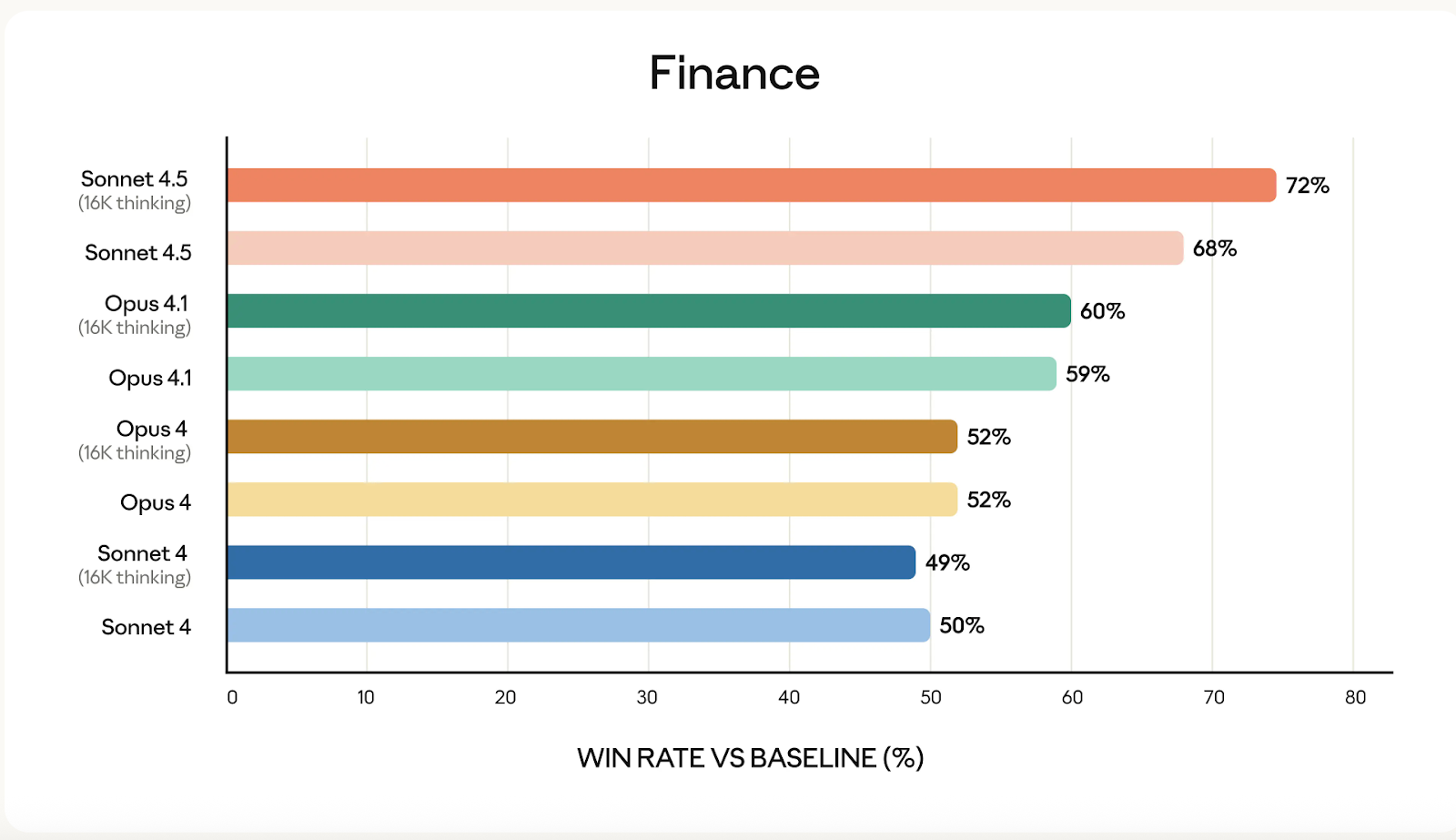
Sumber: Anthropic
Claude Sonnet 4.5 kini tersedia melalui berbagai kanal. Bergantung pada cara Anda ingin menggunakannya, Anda dapat mengakses model baru ini melalui antarmuka chat Claude, mengembangkan lewat API, atau mengintegrasikannya ke alur kerja perusahaan. Berikut cara aksesnya:
Anda dapat menggunakan Claude Sonnet 4.5 langsung melalui antarmuka web Claude.ai atau aplikasi seluler (iOS dan Android). Tersedia untuk semua pengguna, termasuk yang berada di paket gratis. Ini membuatnya mudah diakses oleh pengguna kasual maupun profesional.
Bagi pengembang, Anda dapat mengakses model melalui Anthropic API, dan juga tersedia di Amazon Bedrock dan Google Cloud Vertex AI.
Harga API (per September 2025) adalah: $3 per satu juta token input dan $15 per satu juta token output.
Pemrosesan batch dan cache prompt dapat mengurangi biaya hingga 90% dalam beberapa kasus.
Salah satu pengumuman menarik lain dari Anthropic, bersamaan dengan Sonnet 4.5, adalah Claude Agent SDK. Pada dasarnya, ini adalah blok bangunan yang digunakan Anthropic secara internal, yang memungkinkan pengembang membuat agen bertenaga Claude mereka sendiri.
Belajar AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
