
course
Concepte privind Modelele de Limbaj de Mari Dimensiuni (LLM)
2 oră
102.8K
Running language models locally is becoming easier, even on older hardware. Bonsai is a 1-bit model designed to be small, fast, and efficient, which makes it a good option for local use on a Windows laptop.
In this tutorial, I will show you what Bonsai is and how 1-bit models work in a simple way. I will walk you through the full setup process step by step.
This includes downloading the Bonsai 8B GGUF model, setting up the PrismML fork of llama.cpp, testing the model in the command line, running it as a local server, and checking that everything works with both curl and the built-in WebUI.
I recommend checking out our guides on running GLM-5.1 and Qwen3.5-27B locally as well.
Bonsai is a family of compact 1-bit language models from PrismML that includes 1.7B, 4B, and 8B variants, giving users different size options depending on their device and performance needs.
The Bonsai line is designed for efficient local inference, with support across llama.cpp and related runtimes, and the flagship Bonsai 8B GGUF model is presented as being much smaller than a typical FP16 8B model while still remaining competitive in capability.
A 1-bit model works by storing each weight as a single bit instead of using standard full-precision values. In Bonsai’s Q1_0 format, a value of 0 maps to a negative scale and a value of 1 maps to a positive scale, with one FP16 scale shared across every 128 weights.
This approach reduces memory use significantly while still keeping the model functional and efficient for inference. Bonsai applies this 1-bit design across embeddings, attention projections, MLP projections, and the LM head, making it an end-to-end 1-bit model.
Source: prism-ml/Bonsai-8B-gguf · Hugging Face
In benchmark tests, Bonsai 8B shows that a much smaller 1-bit model can still stay competitive with full precision models in the 6B to 9B range. The model card reports an average score of 70.5 across six evaluation categories, which puts it near several standard 8B models. This makes Bonsai notable not just for its size and speed, but also for maintaining solid performance.
For this tutorial, I am running Bonsai on an older Windows laptop with a 12th Gen Intel processor and an NVIDIA RTX 3070 GPU. One of the biggest advantages of Bonsai 8B is that it can run with around 2 GB of VRAM or system RAM, which makes it a practical option for older laptops and lower memory systems.
For better speed, I recommend installing the latest NVIDIA GPU driver and the CUDA Toolkit from NVIDIA’s official download page. The CUDA Toolkit is NVIDIA’s official development environment for GPU-accelerated applications.
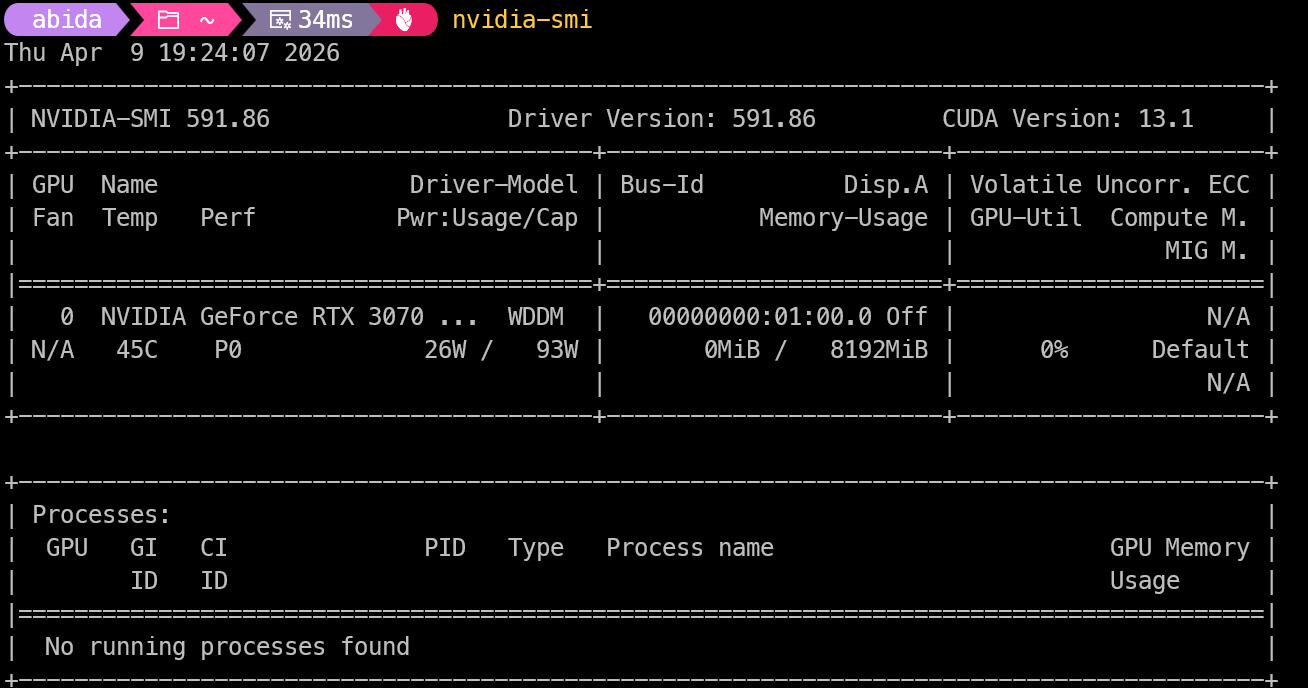
Once everything is installed, open Command Prompt or Terminal and run:
nvidia-smiThis command shows your NVIDIA GPU, driver version, and CUDA support. If your GPU is listed correctly, your system is ready to use GPU acceleration for running Bonsai locally.
First, go to the Bonsai 8B GGUF repository on Hugging Face and download the GGUF model file directly using the download button.
After that, create a folder named “Bonsai” on your system. Inside it, create another folder called “model”, then place the downloaded GGUF file inside that folder.
Next, open the PrismML llama.cpp release page and download the prebuilt Windows x64 build that matches your CUDA version. For this tutorial, you should download the Windows x64 (CUDA 13.1) file and the CUDA 13.1 DLLs from the same release page.
After downloading both ZIP files, extract them into the “Bonsai” folder you created earlier.
When this is done, the folder should include your model directory with the Bonsai GGUF file, as well as the llama.cpp files needed to run the model in the command line and as a local server.
Now open your “Bonsai” folder, right-click in an empty area, and select Open in Terminal. This lets you run the model directly from the folder that contains the llama.cpp files and your “model” directory.
Then run the following command to test Bonsai with llama-cli:
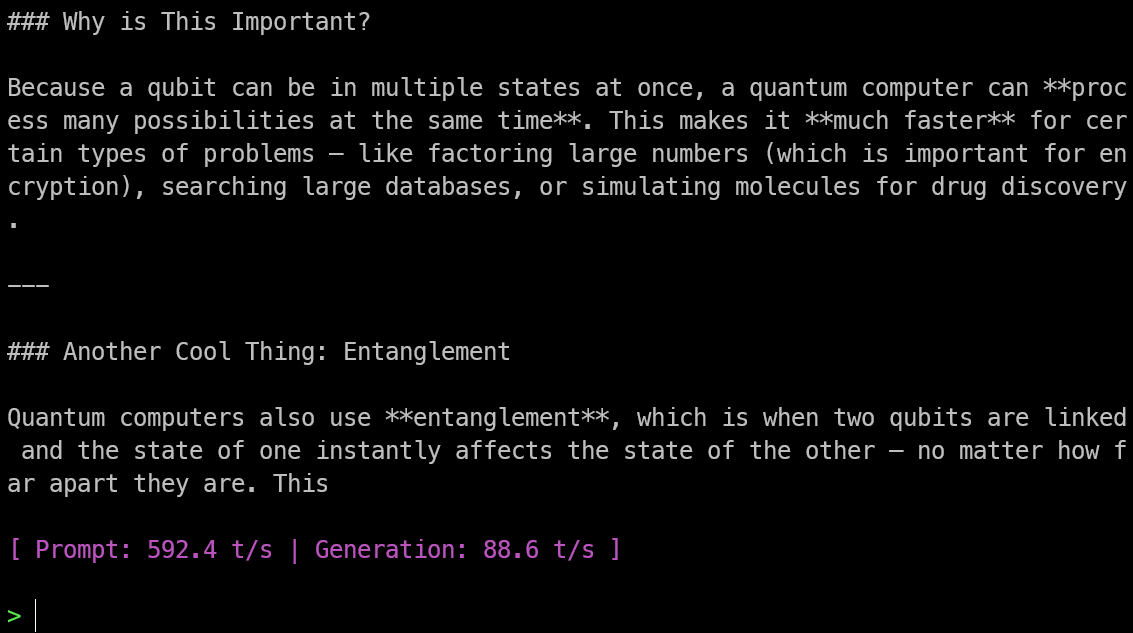
.\llama-cli -m model/Bonsai-8B.gguf -p "Explain quantum computing in simple terms." -n 256 --temp 0.5 --top-p 0.85 --top-k 20 -ngl 99This command follows the same recommended prompt and generation settings shown in the official Bonsai quickstart, including temperature 0.5, top-p 0.85, top-k 20, and -ngl 99 for offloading layers to the GPU.
In my test, the model loaded into GPU memory in less than a second, and the response was both fast and accurate.
I was also getting around 88.6 tokens per second, which is very impressive for running a local model on an older laptop.
After testing the model in the CLI, you can run it as a local inference server with llama-server:
.\llama-server -m model/Bonsai-8B.gguf -ngl 99 --host 127.0.0.1 --port 8033This follows the same local server setup shown on the official Bonsai model page, where PrismML uses llama-server to serve the model over a local HTTP endpoint.
In my test, the model loaded into memory in less than 5 seconds.
Once it finishes loading, the terminal shows that the server is running at 127.0.0.1:8033, which means Bonsai is now available through a local API endpoint on your machine.
Now that the Bonsai server is running, the next step is to test the local API with curl. The llama-server endpoint is OpenAI-compatible, so you can send a request to /v1/chat/completions and get a normal chat completion response back.
Run the following command in your terminal:
curl -X POST "http://127.0.0.1:8033/v1/chat/completions" -H "Content-Type: application/json" --data-raw '{"model":"Bonsai-8B","messages":[{"role":"system","content":"You are a helpful assistant."},{"role":"user","content":"Write a short Python function to reverse a string."}],"temperature":0.7,"max_tokens":200,"stream":false}'If everything is working correctly, the server will return a JSON response with the generated output.

Once the server is running, open http://127.0.0.1:8033/ in your browser. The llama.cpp server includes a built-in web UI.
This gives you a simple ChatGPT-like interface for testing your locally running model. In my case, the UI opened right away, and I was able to start chatting with Bonsai directly from the browser.
I first asked it to write a story, and within a few seconds, it returned a response at around 85 tokens per second.
To see how well it handled a real coding task, I gave it this prompt:
Write Python code to build a command-line number guessing game where the user guesses a randomly selected number, receives "too high" or "too low" hints after each guess, and sees the total number of attempts once they guess correctly.Again, the response was fast. The model generated the code along with simple instructions on how to save the file and run it with Python.
I copied the code into a Python file, ran it in the terminal, and it worked out of the box without any issues.
I also tested a second prompt to see how it handled front-end generation:
Create a simple, clean HTML personal profile website for Abid Ali Awan, a Data Scientist, with sections for a hero intro, about, skills, projects, and contact, using modern styling and placeholder content that can be customized later.The response was fast again. I copied the generated code into an HTML file and opened it in the browser, and the page rendered correctly.
For a model this small, the result was genuinely impressive.
What surprised me most about Bonsai was the combination of speed, size, and intelligence. I did not expect a model this small to feel this fast and usable on an older Windows laptop.
The full setup was also much easier than I expected. I only had to download the GGUF file from Hugging Face and the PrismML llama.cpp build files, place everything into one folder, and run the commands in the terminal to test and serve the model locally. From start to finish, it took me less than two minutes to go from zero setup to actually using the model.
The llama.cpp WebUI made the whole experience even more approachable, especially for someone with limited knowledge about local AI setup or compute. Once the server was running, I could test prompts, generate code, and try creative writing tasks through a simple browser interface without any extra tools.
I also liked the quality of the outputs. For a model of this size, Bonsai handled both coding and creative writing surprisingly well. It was fast in the CLI, fast through the local server, and fast in the WebUI. That said, I do not think a model this small is the right choice for agentic coding or more complex tasks that need deeper reasoning and longer context handling.
Still, if you want to run a model locally, I think 1-bit models are a very promising direction. They offer a strong balance between efficiency and intelligence, and they make local AI much more practical on everyday hardware. I would be very interested in trying a larger 1-bit model next, something closer to the Qwen3.5-27B range, because that could offer an even better balance between speed, memory use, and capability.
LLM Courses
course
course
course
tutorial
Abid Ali Awan
tutorial
Abid Ali Awan
tutorial
Abid Ali Awan
tutorial
François Aubry
tutorial
Abid Ali Awan
tutorial
Abid Ali Awan

