Los grandes modelos lingüísticos (LLM) son componentes fundamentales de las aplicaciones modernas de inteligencia artificial, especialmente para el procesamiento del lenguaje natural. Tienen el potencial de procesar y comprender eficazmente el lenguaje humano, con aplicaciones que van desde los asistentes virtuales y la traducción automática hasta el resumen de textos y la respuesta a preguntas.
Bibliotecas como LangChain facilitan la implementación de aplicaciones de IA de extremo a extremo como las mencionadas anteriormente. Nuestro tutorial Introducción a LangChain para Ingeniería de Datos y Aplicaciones de Datos proporciona una visión general de lo que puede hacer con Langchain, incluyendo los problemas que LangChain resuelve, junto con ejemplos de casos de uso de datos.
Este artículo explicará todo el proceso de entrenamiento de un gran modelo de lenguaje, desde la configuración del espacio de trabajo hasta la implementación final utilizando Pytorch 2.0.1, un marco de aprendizaje profundo dinámico y flexible que permite una implementación del modelo fácil y clara.
Requisitos previos
Para sacar el máximo provecho de este contenido, es importante sentirse cómodo con la programación en Python, tener una comprensión básica de los conceptos de aprendizaje profundo y transformadores, y estar familiarizado con el marco Pytorch. El código fuente completo estará disponible en GitHub.
Antes de sumergirnos en la implementación del núcleo, tenemos que instalar e importar las bibliotecas pertinentes. También es importante señalar que el guión de entrenamiento está inspirado en este repositorio de Hugging Face.
Instalación de la biblioteca
A continuación se detalla el proceso de instalación:
En primer lugar, utilizamos la sentencia %%bash para ejecutar los comandos de instalación en una única celda como un comando bash en el Jupyter Notebook.
- Trl: se utiliza para entrenar modelos de lenguaje transformador con aprendizaje por refuerzo.
- Peft utiliza los métodos de ajuste fino eficiente de parámetros (PEFT) para permitir una adaptación eficaz del modelo preentrenado.
- Torch: una biblioteca de aprendizaje automático de código abierto ampliamente utilizada.
- Conjuntos de datos: se utiliza para ayudar a descargar y cargar muchos conjuntos de datos comunes de aprendizaje automático.
Transformers: una biblioteca desarrollada por Hugging Face y que viene con miles de modelos preentrenados para diversas tareas basadas en texto, como clasificación, resumen y traducción.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers
Ahora, esos módulos pueden importarse del siguiente modo:
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArgumentsCarga y preparación de datos
Para esta ilustración se utilizará el conjunto de datos de alpacas, disponible gratuitamente en Hugging Face. El conjunto de datos tiene tres columnas principales: instrucciones, entrada y salida. Estas columnas se combinan para generar una columna de texto final.
La instrucción para cargar el conjunto de datos se da a continuación proporcionando el nombre del conjunto de datos de interés, que es tatsu-lab/alpaca:
train_dataset = load_dataset("tatsu-lab/alpaca", split="train")
print(train_dataset)Podemos ver que los datos resultantes están en un diccionario de dos claves:
- Características: contiene las principales columnas de los datos
- Num_rows: corresponde al número total de filas de los datos

Estructura del conjunto de datos de entrenamiento
Las cinco primeras filas pueden visualizarse con la siguiente instrucción. En primer lugar, convierta el diccionario en un marco de datos pandas y, a continuación, muestre las filas.
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())
Cinco primeras filas del conjunto de datos de entrenamiento
Para una mejor visualización, vamos a imprimir la información de las tres primeras filas, pero antes necesitamos instalar la librería textwrap para establecer el número máximo de palabras por línea en 50. La primera sentencia print separa cada bloque con 15 guiones.
import textwrap
for index in range(3):
print("---"*15)
print("Instruction:
{}".format(textwrap.fill(pandas_format.iloc[index]["instruction"],
width=50)))
print("Output:
{}".format(textwrap.fill(pandas_format.iloc[index]["output"],
width=50)))
print("Text:
{}".format(textwrap.fill(pandas_format.iloc[index]["text"],
width=50)))
Detalles de las tres primeras filas
Formación de modelos
Antes de proceder a entrenar el modelo, debemos establecer algunos requisitos previos:
- Modelo preentrenado: Utilizaremos el modelo preentrenado Salesforce/xgen-7b-8k-base, que está disponible en Hugging Face. Salesforce entrenó esta serie de LLM 7B denominada XGen-7B con atención densa estándar en hasta 8K secuencias para hasta 1,5T tokens.
- Tokenizer: Esto es necesario para las tareas de tokenización en los datos de entrenamiento. El código para cargar el modelo preentrenado y el tokenizador es el siguiente:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)Configuración de la formación
El entrenamiento requiere algunos argumentos de entrenamiento y configuraciones, y los dos objetos de configuración importantes se definen a continuación, una instancia del modelo TrainingArguments, una instancia del modelo LoraConfig, y finalmente el modelo SFTTrainer.
TrainingArguments
Se utiliza para definir los parámetros para el entrenamiento del modelo.
En este escenario específico, comenzamos definiendo el destino donde se almacenará el modelo entrenado utilizando el atributo output_dir antes de definir hiperparámetros adicionales, como el método de optimización, el learning rate, el number of epochs, y más.
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)LoRAConfig
Los principales argumentos utilizados para este escenario son el rango de la matriz de transformación de bajo rango en LoRA, que se fija en 16. A continuación, el factor de escala para los parámetros adicionales en LoRA se fija en 32.
Además, la proporción de abandonos es de 0,05, lo que significa que el 5% de las unidades de entrada se ignorarán durante el entrenamiento. Por último, dado que se trata de un modelado lingüístico causal, la tarea se inicializa con el atributo CAUSAL_LM.
SFTTrainer
Su objetivo es entrenar el modelo utilizando los datos de entrenamiento, el tokenizador e información adicional como los modelos anteriores.
Dado que estamos utilizando el campo de texto de los datos de entrenamiento, es importante echar un vistazo a la distribución para ayudar a establecer el número máximo de tokens en una secuencia dada.
import matplotlib.pyplot as plt
pandas_format['text_length'] = pandas_format['text'].apply(len)
plt.figure(figsize=(10,6))
plt.hist(pandas_format['text_length'], bins=50, alpha=0.5, color='g')
plt.title('Distribution of Length of Text')
plt.xlabel('Length of Text')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()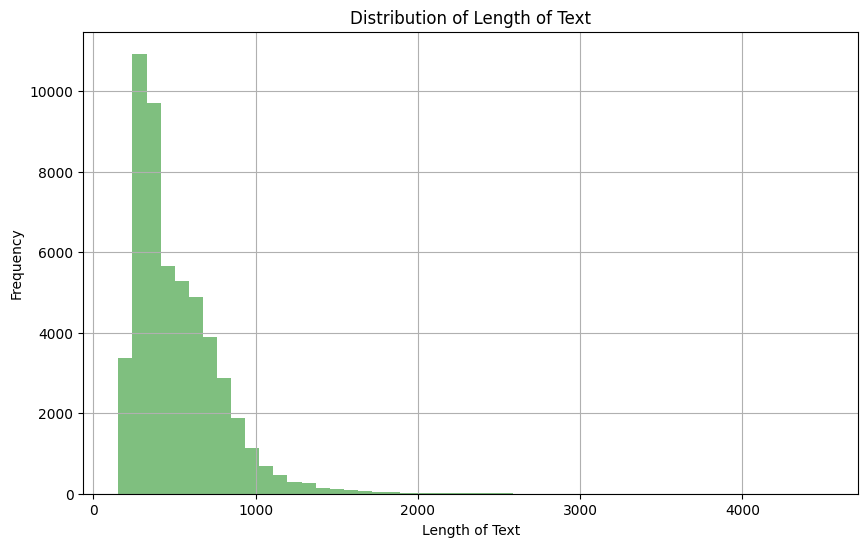
Distribución de la longitud de la columna de texto
Basándonos en la observación anterior, podemos ver que la mayoría del texto tiene una longitud entre 0 y 1000. También podemos ver a continuación que sólo el 4,5% de los documentos de texto tienen una longitud superior a 1024.
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

A continuación, fijamos el número máximo de tokens de la secuencia en 1024, de modo que cualquier texto que supere esta cifra quede truncado.
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)Ejecución de la formación
Una vez establecidos todos los requisitos previos, ya podemos ejecutar el proceso de entrenamiento del modelo del siguiente modo:
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()Es importante mencionar que este entrenamiento se está realizando en un entorno en la nube con una GPU, lo que hace que el proceso de entrenamiento en general sea más rápido. Sin embargo, la formación en un ordenador local requeriría más tiempo.
Nuestro blog, Pros and Cons of Using LLMs in the Cloud Versus Running LLMs Locally, proporciona consideraciones clave para seleccionar la estrategia de despliegue óptima para LLMs
Entendamos lo que ocurre en el fragmento de código anterior:
- tokenizer.pad_token = tokenizer.eos_token: Establece que el token de relleno sea el mismo que el token de fin de frase.
- model.resize_token_embeddings(len(tokenizer)): Cambia el tamaño de la capa de incrustación de tokens del modelo para que coincida con la longitud del vocabulario del tokenizador.
- model = prepare_model_for_int8_training(model): Prepara el modelo para el entrenamiento con precisión INT8, probablemente realizando la cuantización.
- model = get_peft_model(model, lora_peft_config): Ajusta el modelo dado según la configuración PEFT.
- training_args = model_training_args: Asigna argumentos de entrenamiento predefinidos a training_args.
- trainer = SFT_trainer: Asigna la instancia SFTTrainer a la variable trainer.
- trainer.train(): Activa el proceso de entrenamiento del modelo según las especificaciones proporcionadas.
Conclusión
Este artículo ha proporcionado una guía clara sobre el entrenamiento de un gran modelo lingüístico utilizando PyTorch. Empezando por la preparación del conjunto de datos, recorrió los pasos de preparación de los requisitos previos, configuración del entrenador y, por último, ejecución del proceso de entrenamiento.
Aunque utilizó un conjunto de datos específico y un modelo preentrenado, el proceso debería ser en gran medida el mismo para cualquier otra opción compatible. Ahora que ya sabe cómo entrenar un LLM, puede aprovechar estos conocimientos para entrenar otros modelos sofisticados para diversas tareas de PNL.
Consulte nuestra guía sobre cómo crear aplicaciones LLM con LangChain para explorar más a fondo la potencia de los grandes modelos lingüísticos. O, si aún necesita explorar los conceptos de los grandes modelos lingüísticos, consulte nuestro curso para profundizar en su aprendizaje.

