
programa
Fundamentos de SQL
26 h
Forma a tu equipo en SQL con DataCamp para empresas. Formación completa, proyectos prácticos y métricas de rendimiento detalladas para tu organización.

Pivotar en SQL se refiere a transformar datos de un formato basado en filas a un formato basado en columnas. Esta transformación es útil para la elaboración de informes y el análisis de datos, ya que permite una visión de los datos más estructurada y compacta. Pasar las filas a columnas también permite a los usuarios analizar y resumir los datos de forma que destaquen las ideas clave con mayor claridad.
Considera el siguiente ejemplo: Tengo una tabla con transacciones de ventas diarias, y cada fila registra la fecha, el nombre del producto y el importe de la venta.
| Fecha | Producto | Ventas |
|---|---|---|
| 2024-01-01 | Portátil | 100 |
| 2024-01-01 | Ratón | 200 |
| 2024-01-02 | Portátil | 150 |
| 2024-01-02 | Ratón | 250 |
Pivotando esta tabla, puedo reestructurarla para que muestre cada producto como una columna, con los datos de ventas de cada fecha bajo su columna correspondiente. Observa también que se produce una agregación.
| Fecha | Portátil | Ratón |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Tradicionalmente, las operaciones pivotantes requerían complejas consultas SQL con agregación condicional. Con el tiempo, las implementaciones de SQL han evolucionado, y muchas bases de datos modernas incluyen ahora los operadores PIVOT y UNPIVOT para permitir transformaciones más eficaces y sencillas.
La operación pivotante SQL transforma los datos convirtiendo los valores de las filas en columnas. A continuación se muestra la sintaxis básica y la estructura del pivote SQL con las siguientes partes:
SELECCIONA: La sentencia SELECT hace referencia a las columnas a devolver en la tabla pivotante SQL.
Subconsulta: La subconsulta contiene la fuente de datos o tabla que se incluirá en la tabla pivotante SQL.
PIVOT: El operador PIVOT contiene las agregaciones y el filtro que se aplicarán en la tabla dinámica.
-- Select static columns and pivoted columns
SELECT <static columns>, [pivoted columns]
FROM
(
-- Subquery defining source data for pivot
<subquery that defines data>
) AS source
PIVOT
(
-- Aggregate function applied to value column, creating new columns
<aggregation function>(<value column>)
FOR <column to pivot> IN ([list of pivoted columns])
) AS pivot_table;Veamos el siguiente ejemplo paso a paso para demostrar cómo hacer pivotar filas a columnas en SQL. Considera la siguiente tabla SalesData.
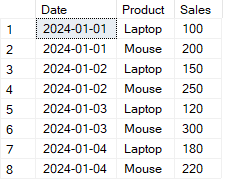
Ejemplo de tabla a transformar utilizando el operador PIVOT de SQL. Imagen del autor.
Quiero hacer pivotar estos datos para comparar las ventas diarias de cada producto. Empezaré seleccionando la subconsulta que estructurará el operador PIVOT.
-- Subquery defining source data for pivot
SELECT Date, Product, Sales
FROM SalesData;Ahora, utilizaré el operador PIVOT para convertir los valores de Product en columnas y agregaré Sales utilizando el operador SUM.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;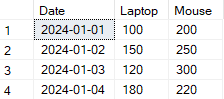
Ejemplo de transformación de salida utilizando filas pivotantes SQL a columnas. Imagen del autor.
Aunque pivotar los datos simplifica el resumen de los mismos, esta técnica tiene problemas potenciales. A continuación se exponen los retos potenciales del pivote SQL y cómo abordarlos.
Nombres de columna dinámicos: Cuando los valores a pivotar (por ejemplo, los tipos de Producto) son desconocidos, la codificación rígida de los nombres de columna no funcionará. Algunas bases de datos, como SQL Server, admiten SQL dinámico con procedimientos almacenados para evitar este problema, mientras que otras requieren manejarlo en la capa de aplicación.
Tratar con valores nulos: Cuando no hay datos para una columna pivotante concreta, el resultado puede incluir NULL. Puedes utilizar COALESCE para sustituir los valores de NULL por cero u otro marcador de posición.
Compatibilidad entre bases de datos: No todas las bases de datos admiten directamente el operador PIVOT. Puedes conseguir resultados similares con las sentencias CASE y la agregación condicional si tu dialecto SQL no lo permite.
Se utilizan distintos métodos para pivotar datos en SQL, según la base de datos utilizada u otros requisitos. Aunque el operador PIVOT se utiliza habitualmente en SQL Server, otras técnicas, como las sentencias CASE, permiten transformaciones similares de la base de datos sin soporte directo de PIVOT. Trataré los dos métodos habituales de pivotar datos en SQL, y hablaré de los pros y los contras.
El operador PIVOT, disponible en SQL Server, proporciona una forma sencilla de pivotar filas en columnas especificando una función de agregación y definiendo las columnas a pivotar.
Considera la siguiente tabla llamada sales_data.
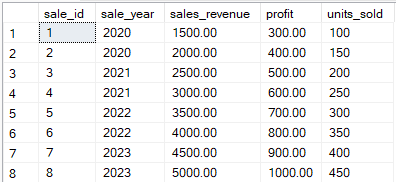
Ejemplo Tabla de órdenes a transformar utilizando el operador PIVOT. Imagen del autor.
Utilizaré el operador PIVOT para agregar los datos de forma que el total de cada año sales_revenue se muestre en columnas.
-- Use PIVOT to aggregate sales revenue by year
SELECT *
FROM (
-- Select the relevant columns from the source table
SELECT sale_year, sales_revenue
FROM sales_data
) AS src
PIVOT (
-- Aggregate sales revenue for each year
SUM(sales_revenue)
-- Create columns for each year
FOR sale_year IN ([2020], [2021], [2022], [2023])
) AS piv;
Ejemplo de transformación de salida utilizando SQL PIVOT. Imagen del autor.
Utilizar el operador PIVOT tiene las siguientes ventajas y limitaciones:
Ventajas: El método es eficaz cuando las columnas están bien indexadas. También tiene una sintaxis sencilla y más legible.
Limitaciones: No todas las bases de datos admiten el operador PIVOT. Requiere especificar las columnas de antemano, y el pivotaje dinámico requiere una complejidad adicional.
También puedes utilizar las sentencias CASE para pivotar datos manualmente en bases de datos que no admitan los operadores PIVOT, como MySQL y PostgreSQL. Este enfoque utiliza la agregación condicional evaluando cada fila y asignando condicionalmente valores a nuevas columnas en función de criterios específicos.
Por ejemplo, podemos hacer pivotar manualmente los datos de la misma tabla sales_data con sentencias CASE.
-- Aggregate sales revenue by year using CASE statements
SELECT
-- Calculate total sales revenue for each year
SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020,
SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021,
SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022,
SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023
FROM
sales_data;
Ejemplo de transformación de salida mediante la sentencia SQL CASE. Imagen del autor.
Utilizar la declaración CASE para la transformación tiene las siguientes ventajas y limitaciones:
Ventajas: El método funciona en todas las bases de datos SQL y es flexible para generar dinámicamente nuevas columnas, incluso cuando los nombres de los productos son desconocidos o cambian con frecuencia.
Limitaciones: Las consultas pueden volverse complejas y largas si hay que hacer pivotar muchas columnas. Debido a las múltiples comprobaciones condicionales, el método es ligeramente más lento que el operador PIVOT.
Pasar filas a columnas en SQL puede tener implicaciones de rendimiento, especialmente cuando se trabaja con grandes conjuntos de datos. Aquí tienes algunos consejos y buenas prácticas que te ayudarán a escribir consultas pivotantes eficientes, optimizar su rendimiento y evitar los errores más comunes.
A continuación se indican las mejores prácticas para optimizar tus consultas y mejorar el rendimiento.
Estrategias de indexación: Una indexación adecuada es crucial para optimizar las consultas pivotantes, permitiendo que SQL recupere y procese los datos más rápidamente. Indexa siempre las columnas utilizadas frecuentemente en la cláusula WHERE o las columnas que vayas a agrupar para reducir los tiempos de escaneado.
Evita los Pivotes Anidados: Apilar varias operaciones pivote en una consulta puede ser difícil de leer y más lento de ejecutar. Simplifica dividiendo la consulta en partes o utilizando una tabla temporal.
Limitar Columnas y Filas en Pivot: Sólo se necesitan columnas pivotantes para el análisis, ya que pivotar muchas columnas puede consumir muchos recursos y crear tablas de gran tamaño.
A continuación se indican los errores más comunes que puedes encontrar en las consultas pivotantes y cómo evitarlos.
Exploraciones innecesarias de toda la tabla: Las consultas pivotantes pueden desencadenar escaneos completos de la tabla, especialmente si no se dispone de índices relevantes. Evita escaneos completos de la tabla indexando las columnas clave y filtrando los datos antes de aplicar el pivote.
Utilizar SQL Dinámico para Pivotar Frecuentemente: Utilizar SQL dinámico puede ralentizar el rendimiento debido a la recompilación de las consultas. Para evitar este problema, almacena en caché o limita los pivotes dinámicos a escenarios específicos y considera la posibilidad de manejar columnas dinámicas en la capa de aplicación cuando sea posible.
Agregación en Grandes Conjuntos de Datos sin Prefiltrado: Las funciones de agregación como SUM o COUNT en grandes conjuntos de datos pueden ralentizar el rendimiento de la base de datos. En lugar de pivotar todo el conjunto de datos, filtra primero los datos mediante una cláusula WHERE.
Valores NULL en Columnas Pivotantes: Las operaciones pivotantes suelen producir valores NULL cuando no hay datos para una columna concreta. Pueden ralentizar las consultas y dificultar la interpretación de los resultados. Para evitar este problema, utiliza funciones como COALESCE para sustituir los valores de NULL por un valor por defecto.
Pruebas sólo con datos de muestra: Las consultas pivotantes pueden comportarse de forma diferente con grandes conjuntos de datos, debido a las mayores exigencias de memoria y procesamiento. Prueba siempre las consultas pivotantes en muestras de datos reales o representativas para evaluar con precisión el impacto en el rendimiento.
Prueba nuestro itinerario profesional de Desarrollador de SQL Server, que abarca desde las transacciones y la gestión de errores hasta la mejora del rendimiento de las consultas.
Las operaciones pivotantes difieren significativamente entre bases de datos como SQL Server, MySQL y Oracle. Cada una de estas bases de datos tiene una sintaxis y unas limitaciones específicas. Trataré ejemplos de datos pivotantes en las distintas bases de datos y sus características principales.
SQL Server proporciona un operador PIVOT incorporado, que resulta sencillo cuando se pivotan filas a columnas. El operador PIVOT es fácil de usar y se integra con las potentes funciones de agregación de SQL Server. Las características clave de la función pivotante en SQL son las siguientes:
Apoyo directo a PIVOT y UNPIVOT: El operador PIVOT de SQL Server permite una rápida transformación de fila a columna. El operador de UNPIVOT también puede invertir este proceso.
Opciones de agregación: El operador PIVOT permite varias funciones de agregación, como SUM, COUNT y AVG.
La limitación del operador PIVOT en SQL Server es que requiere que los valores de las columnas que se van a pivotar se conozcan de antemano, lo que lo hace menos flexible para los datos que cambian dinámicamente.
En el ejemplo siguiente, el operador PIVOT convierte los valores de Product en columnas y agrega Sales mediante el operador SUM.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;Te recomiendo que sigas el curso Introducción a SQL Server de DataCamp para dominar los fundamentos de SQL Server para el análisis de datos.
MySQL carece de soporte nativo para el operador PIVOT. Sin embargo, puedes utilizar la sentencia CASE para pivotar manualmente filas a columnas y combinar otras funciones agregadas como SUM, AVG y COUNT. Aunque este método es flexible, puede resultar complejo si tienes muchas columnas que hacer pivotar.
La consulta siguiente obtiene el mismo resultado que el ejemplo de SQL Server PIVOT agregando condicionalmente las ventas de cada producto mediante la sentencia CASE.
-- Select Date and pivoted columns for each product
SELECT
Date,
-- Use CASE to create a column for Laptop and Mouse sales
SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop,
SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse
FROM SalesData
GROUP BY Date;Oracle admite el operador PIVOT, que permite transformar directamente filas en columnas. Al igual que en SQL Server, tendrás que especificar explícitamente las columnas para la transformación.
En la consulta siguiente, el operador PIVOT convierte los valores de ProductName en columnas y agrega SalesAmount mediante el operador SUM.
SELECT *
FROM (
-- Source data selection
SELECT SaleDate, ProductName, SaleAmount FROM SalesData
)
PIVOT (
-- Aggregate Sales by Product, creating pivoted columns
SUM(SaleAmount)
FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse)
);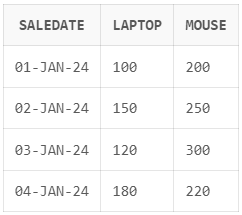
Ejemplo de transformación de salida utilizando el operador PIVOT de SQL en Oracle. Imagen del autor.
Las técnicas avanzadas para pivotar filas en columnas son útiles cuando necesitas flexibilidad en el manejo de datos complejos. Las técnicas dinámicas y el manejo simultáneo de varias columnas te permiten transformar datos en escenarios en los que el pivotaje estático es limitado. Exploremos estos dos métodos en detalle.
Los pivotes dinámicos te permiten crear consultas pivotantes que se adaptan automáticamente a los cambios en los datos. Esta técnica es especialmente útil cuando tienes columnas que cambian con frecuencia, como nombres de productos o categorías, y quieres que tu consulta incluya automáticamente las nuevas entradas sin actualizarla manualmente.
Supongamos que tenemos una tabla SalesData y podemos crear un pivote dinámico que se ajuste si se añaden nuevos productos. En la consulta siguiente, @columns construye dinámicamente la lista de columnas pivotadas, y sp_executesql ejecuta el SQL generado.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
-- Step 1: Generate a list of distinct products to pivot
SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ')
FROM (SELECT DISTINCT Product FROM SalesData) AS products;
-- Step 2: Build the dynamic SQL query
SET @sql = N'
SELECT Date, ' + @columns + '
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(
SUM(Sales)
FOR Product IN (' + @columns + ')
) AS pivot_table;';
-- Step 3: Execute the dynamic SQL
EXEC sp_executesql @sql;En situaciones en las que necesites hacer pivotar varias columnas simultáneamente, utilizarás el operador PIVOT y técnicas de agregación adicionales para crear varias columnas en la misma consulta.
En el ejemplo siguiente, he hecho pivotar las columnas Sales y Quantity por Product.
-- Pivot Sales and Quantity for Laptop and Mouse by Date
SELECT
p1.Date,
p1.[Laptop] AS Laptop_Sales,
p2.[Laptop] AS Laptop_Quantity,
p1.[Mouse] AS Mouse_Sales,
p2.[Mouse] AS Mouse_Quantity
FROM
(
-- Pivot for Sales
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales
) p1
JOIN
(
-- Pivot for Quantity
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Quantity FROM SalesData) AS source
PIVOT
(SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity
) p2
ON p1.Date = p2.Date;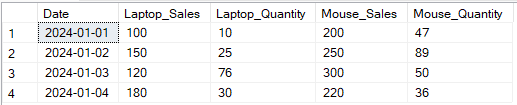
Ejemplo de transformación de salida de varias columnas mediante el operador PIVOT de SQL. Imagen del autor.
Hacer pivotar varias columnas permite obtener informes más detallados al hacer pivotar varios atributos por elemento, lo que permite una visión más rica. Sin embargo, la sintaxis puede ser compleja, sobre todo si existen muchas columnas. Puede ser necesaria la codificación rígida, a menos que se combine con técnicas de pivote dinámico, lo que añade más complejidad.
Pasar filas a columnas es una técnica SQL que merece la pena aprender. He visto utilizar técnicas de pivote SQL para crear una tabla de retención de cohortes, en la que podrías hacer un seguimiento de la retención de usuarios a lo largo del tiempo. También he visto técnicas pivotantes SQL utilizadas al analizar datos de encuestas, en las que cada fila representa a un encuestado, y cada pregunta puede pivotarse en su columna.
Nuestro curso de Informes en SQL es una gran opción si quieres aprender más sobre cómo resumir y preparar datos para su presentación y/o la creación de cuadros de mando. Nuestras trayectorias profesionales de Analista de Datos Asociado en SQL e Ingeniero de Datos Asociado en SQL son otra gran idea, y aportan mucho a cualquier currículum, así que inscríbete hoy mismo.
Aprende SQL con DataCamp
programa
programa
Curso
blog
Elena Kosourova
11 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Oluseye Jeremiah
Tutorial
Allan Ouko
Tutorial
Eugenia Anello

