
programa
Científico de datos en Python
26 h
Independientemente de si eres estudiante, aspirante a científico de datos o profesional que busca un cambio de carrera, si quieres convertirte en un científico de datos con experiencia, tienes que seguir un camino. Esto no siempre es fácil, ya que el panorama de la ciencia de datos se ha ampliado considerablemente y, como resultado, hay diferentes tipos de profesionales de la ciencia de datos con diferentes actividades y conjuntos de habilidades.
Para acercarte al camino de la ciencia de datos, este artículo ofrece una visión general del panorama de la ciencia de datos para que puedas ver qué puestos se ajustan a tus ambiciones. Además, ofrece consejos sobre cómo acceder a diferentes puestos dentro de ese ámbito o crecer profesionalmente en ellos, respondiendo a preguntas como: ¿Qué habilidades debes desarrollar y con qué métodos debes familiarizarte?
Comencemos con nuestra hoja de ruta para la ciencia de datos.
En este artículo, profundizamos en todos los aspectos de la hoja de ruta. Sin embargo, si buscas un resumen rápido del esquema, lo encontrarás a continuación:
Siguiendo esta hoja de ruta, podrás orientarte eficazmente en el panorama de la ciencia de datos, desarrollar habilidades esenciales y desarrollar una carrera gratificante en este campo.
Para comprender el contexto de una hoja de ruta de ciencia de datos, es fundamental tener una idea de lo que es la ciencia de datos. Tenemos una guía completa que cubre las definiciones y explicaciones de la ciencia de datos, pero a efectos de este artículo, consideraremos la ciencia de datos como el conjunto de actividades destinadas a resolver problemas mediante el uso de datos.
Un problema muy frecuente es «tengo una pregunta, pero no sé la respuesta», por lo que si ejecutas una consulta SQL en una base de datos de ventas para averiguar cuántos ingresos obtuvo una organización el mes pasado, ¡eres un científico de datos!
A menudo, los problemas y las soluciones son más complejos y requieren un conjunto de habilidades más diverso. Para poder analizar esta amplia gama de funciones y habilidades relacionadas con la ciencia de datos a lo largo de esta hoja de ruta, utilizaremos el ciclo de vida de un proyecto de ciencia de datos como referencia. Esto nos permitirá mapear las diferentes actividades y funciones, y servirá como base para trazar el panorama de la ciencia de datos.
Los proyectos de ciencia de datos suelen comenzar con una pregunta o un problema empresarial. Un problema desencadena una fase inicial, en la que se define un conjunto de posibles soluciones y se evalúa la viabilidad inicial. Se lleva a cabo una recopilación inicial de datos o un análisis exploratorio de los datos disponibles para ver qué es posible y qué no. ¿Son suficientes los datos? ¿Contiene suficientes funciones?
Una vez que todas las luces estén en verde, comenzaremos a desarrollar un modelo predictivo. El modelo utilizará los datos introducidos para predecir los resultados. Inicialmente, este podría ser solo un modelo único, entrenado, probado y validado en un conjunto de validación cruzada k-fold (una técnica de machine learning para evaluar el rendimiento probable de un modelo con datos no vistos). Este es el trabajo que suelen realizar los científicos de datos clásicos. Una vez que el modelo funciona correctamente, es el momento de empezar a producirlo y colocarlo en un canal dentro de la infraestructura existente, donde se supervisará su rendimiento y se volverá a entrenar cuando sea necesario.
Cada una de estas fases requiere habilidades diferentes. Durante la fase inicial, es necesario tener visión para los negocios y estar familiarizado con la transformación de datos, la limpieza, la estadística descriptiva y la estadística inferencial básica. Este es un trabajo que puede realizar un analista de datos o un científico de datos.
En la fase de modelización, es necesario crear modelos predictivos. Los modelos simples, como las regresiones, pueden ser creados por un analista de datos, pero si se vuelven más complejos, necesitarás un científico de datos para crear un modelo utilizando un algoritmo existente o incluso un ingeniero de machine learning para modificar los algoritmos actuales o crear otros nuevos.
Al implementar y poner en producción el modelo, entras en el ámbito del ingeniero de machine learning o del ingeniero de datos. A diferencia de las etapas anteriores, no existe necesariamente un vínculo estrecho con el negocio, y la tarea en cuestión giraba en torno a la creación y supervisión de un canal en torno al modelo predictivo para proporcionar resultados fiables a los sistemas de destino adecuados.
A lo largo de todo el proceso, todos los datos deben estar disponibles en los lugares adecuados con la metainformación correcta, lo cual es responsabilidad del arquitecto de datos. A medida que se incorporan nuevos datos o se transforman los datos existentes en nueva información, también se aseguran de que los datos terminen en el lugar adecuado.
La forma en que las diferentes funciones contribuyen a lo largo de las distintas fases del ciclo de vida se ilustra en la imagen siguiente. Dado que las diferentes funciones contribuyen en diferentes etapas, requieren diferentes habilidades.
Las funciones al comienzo del ciclo de vida requieren más perspicacia empresarial y menos conocimientos de ingeniería, mientras que las fases posteriores requieren menos perspicacia empresarial y más conocimientos de ingeniería y optimización de algoritmos. Para ilustrar este punto, como científico de datos, puedes arreglártelas con un rendimiento computacional subóptimo para mostrar el valor y el rendimiento de tu modelo. Pero, tan pronto como te haces responsable de la producción de modelos, debes ser capaz de optimizar la complejidad computacional para garantizar que tu proceso sea (económicamente) eficiente.
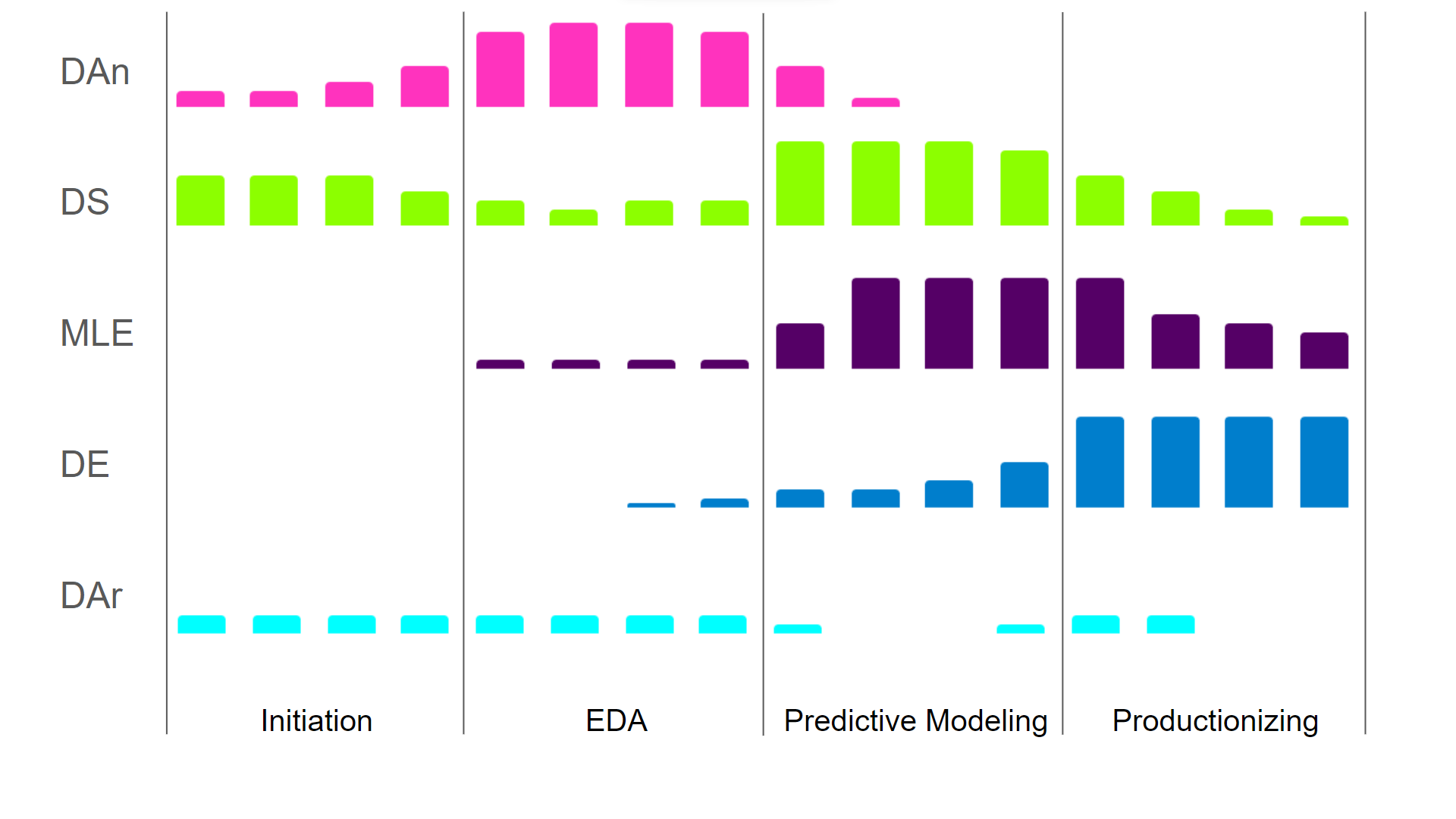
El nivel de contribución de las diferentes funciones de ciencia de datos a lo largo de un proyecto de ciencia de datos (DAn: analista de datos; DS: científico de datos; MLE: ingeniero de machine learning; DE: ingeniero de datos; DAr: arquitecto de datos). Imagen del autor.
Es importante saber que las delimitaciones entre las funciones no son estrictas. Muchos científicos de datos ya piensan en los sistemas fuente/destino adecuados y en la eficiencia computacional, y los tienen en cuenta en su código. Un ingeniero de machine learning podría darse cuenta de que ciertos enfoques de generación de características podrían mejorar el rendimiento del modelo. Un analista de datos puede dar buenos consejos sobre dónde almacenar en el catálogo de datos las características generadas para el arquitecto de datos. En otras palabras, todos los roles deben, en cierta medida, ser conscientes del trabajo de los demás roles, pero no es necesario que comprendan en profundidad las responsabilidades de los demás.
En cuanto a las habilidades y herramientas que necesitarás, hay una base clara. Independientemente de la fase del ciclo de vida de un proyecto de ciencia de datos en la que participes, necesitarás tener algunos conocimientos básicos de matemáticas y estadística, desarrollo de software colaborativo y manipulación de datos. En términos generales, el inicio de cualquier hoja de ruta de ciencia de datos consiste en:
Existen diferentes tipos de puestos relacionados con la ciencia de datos que requieren diferentes habilidades: un analista de datos necesitará un conocimiento más profundo de SQL que un ingeniero de datos. Un científico de datos necesita conocer machine learning mejor que un arquitecto de datos. Aquí es donde se divide la hoja de ruta de la ciencia de datos: dependiendo de cuáles sean tus ambiciones en el panorama de la ciencia de datos, tendrás que aprender diferentes habilidades. Las siguientes secciones describirán las diferentes ramas de la hoja de ruta que puedes imaginar.
Independientemente de lo avanzado que estés en tu trayectoria en ciencia de datos, ya seas un veterano con amplia experiencia o alguien que acaba de empezar, todos los proyectos de ciencia de datos comienzan por comprender tus datos.
Es fundamental comprender a fondo tus datos para evaluar la viabilidad de tu proyecto. Empezando por preguntas básicas como «¿qué variables tienes?» y «¿cuántas observaciones tienes?», y terminando con preguntas más complejas como «¿cuáles son las relaciones entre las variables?».
A menudo, los resultados de un EDA pueden ser la respuesta a las preguntas de tus partes interesadas. Cuando se visualizan y presentan adecuadamente de forma coherente, por ejemplo en un panel de control, los resultados de un análisis de datos sencillo pueden utilizarse para responder a preguntas complejas. Sin embargo, esto depende de la habilidad para visualizar datos.
Pero con solo mostrar a través de tu EDA que, por ejemplo, existen diferentes segmentos de visitantes del sitio web, tú has aportado valor como científico de datos.
Hay múltiples formas de visualizar tus resultados. Ya sea en bibliotecas/paquetes de visualización en el lenguaje que utilices (como ggplot2 de R y matplotlib de Python) o en herramientas específicas de visualización de datos (como PowerBI, Tableau o incluso Excel) .
Especialmente cuando nos centramos más en las tareas de un analista de datos, resulta útil tener un conocimiento más profundo de la visualización de datos.
En la mayoría de los puestos relacionados con la ciencia de datos, las visualizaciones pueden servir para comprobar hipótesis mediante gráficos de dispersión e histogramas, pero cuando el análisis en sí mismo es el resultado final, como en el caso de un analista de datos, te encontrarás con situaciones en las que querrás que los resultados del análisis sean fáciles de digerir.
Piensa en estilos personalizados, nuevas visualizaciones o infografías que sirvan como aportación para una unidad de toma de decisiones. En estas situaciones, resulta útil poder crear una visualización de datos que sea prácticamente una obra de arte. Comprender la visualización de datos es un curso que realmente ayuda a profundizar tus competencias en visualización de datos.
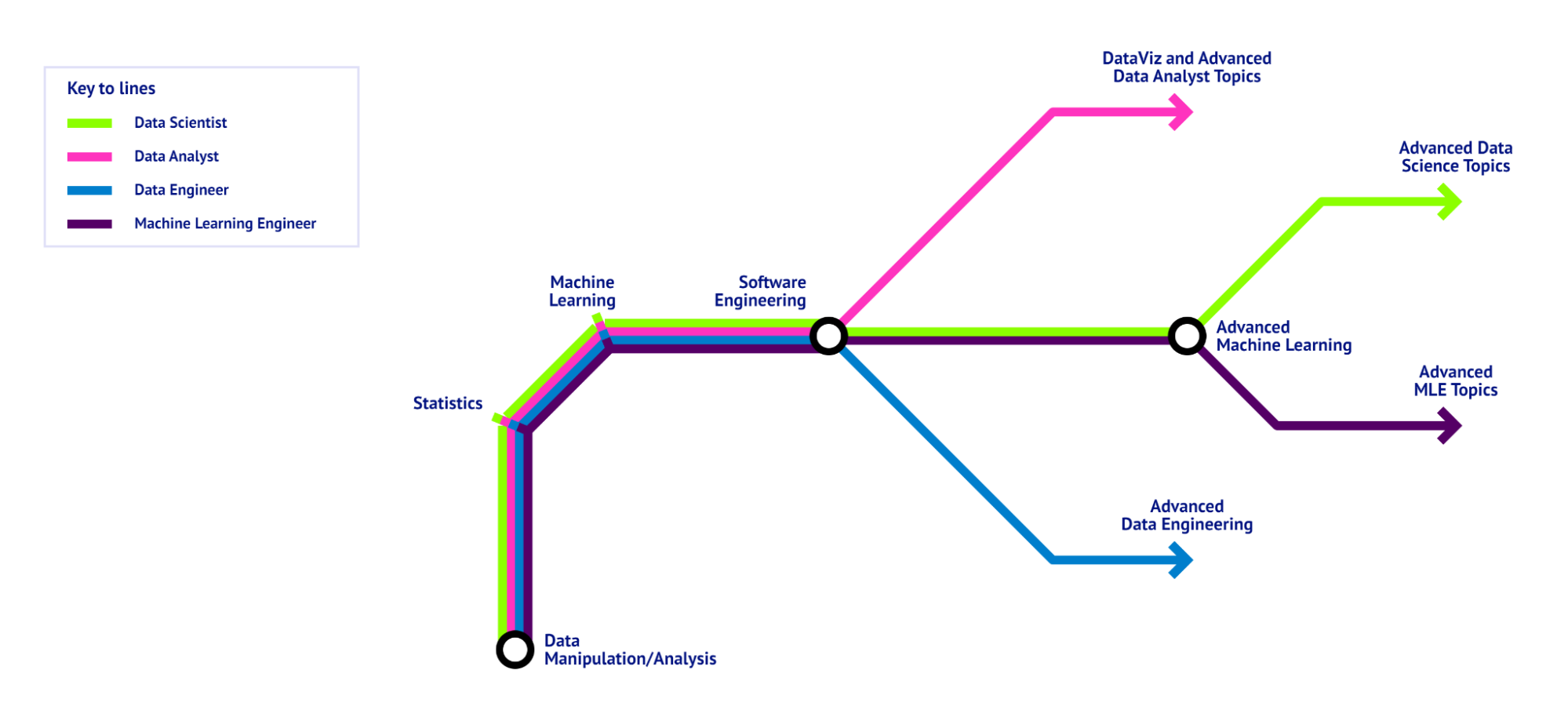
Una hoja de ruta de la ciencia de datos, visualizada como un mapa de metro, que muestra los fundamentos comunes a todas las funciones de la ciencia de datos y las habilidades específicas de las diferentes funciones. - Imagen del autor.
Otra de las primeras paradas en la hoja de ruta de la ciencia de datos es la estadística. Algunos conceptos estadísticos básicos deberían ser algo natural para cualquier tipo de científico de datos.
En cualquier momento, deberás ser capaz de describir tus datos y los subgrupos que los componen. ¿Cuál es el ingreso promedio en tu conjunto de datos? ¿Cuáles son los ingresos mínimos y máximos? ¿Qué es la desviación estándar o cuáles son otras medidas de dispersión? Y si tienes valores categóricos, ¿cuántos valores únicos hay? ¿Cuál es el más frecuente? ¿Todos los valores aparecen con la misma frecuencia o se distribuyen de forma menos uniforme?
Responder preguntas con análisis descriptivos sobre grupos/subgrupos ya puede proporcionar información valiosa, pero, en la mayoría de los casos, es necesario examinar la relación entre las variables del conjunto de datos y pasar a la estadística inferencial.
La parte más interesante y desafiante de la estadística inferencial son los diferentes tipos de valores categóricos y numéricos y las relaciones entre ellos. Algunos ejemplos son:
Para poder responder a estas preguntas, es necesario conocer los diferentes tipos de pruebas estadísticas, desde la más sencilla, la prueba T, hasta métodos más complejos, como las regresiones lineales multivariantes o el análisis de series temporales.
Puedes seguir cursos relevantes para profundizar tus conocimientos sobre estadística en: Python, R e incluso independientemente de las herramientas. Estos cursos proporcionan una base adecuada para empezar a trabajar con machine learning. Al comprender estadísticamente la relación entre los predictores y las variables objetivo, se comprenden los principios de los algoritmos utilizados para crear modelos de aprendizaje supervisado.
La profundidad con la que quieras profundizar en esta área depende, una vez más, del punto al que quieras llegar en la hoja de ruta de la ciencia de datos. Si tu objetivo es convertirte en analista de datos, comprender los conceptos básicos de la estadística podría ser suficiente. Es posible que los arquitectos de datos no necesiten ningún conocimiento estadístico. Pero los científicos de datos y los ingenieros de machine learning sin duda se encontrarán con situaciones en las que tendrán que recurrir a sus conocimientos estadísticos.
La ciencia de datos se basa en números y cálculos y, por lo tanto, las matemáticas desempeñan un papel importante. Aunque no es necesario tener un título superior en matemáticas para dedicarte a la ciencia de datos, comprender el álgebra y el cálculo te ayudará a entender conceptualmente una serie de métodos que se utilizan a menudo en este campo. La mayoría de los enfoques de reducción de dimensionalidad (como el PCA y la factorización de matrices) se basan en el álgebra lineal, y muchos algoritmos de optimización (como el descenso de gradiente) se basan en el cálculo.
Y al igual que con las estadísticas y el análisis de datos, este conocimiento no es necesariamente relevante para todas las funciones relacionadas con la ciencia de datos. Si tu objetivo es convertirte en ingeniero de machine learning, no hay forma de evitar las matemáticas. Pero la mayoría de los demás puestos, incluso el de científico de datos, podrían desempeñarse sin necesidad de conocer álgebra ni cálculo.
Para obtener más información y comprender los conceptos algebraicos, consulta nuestro curso sobre Álgebra lineal para la ciencia de datos en R.
Machine learning es el arte de crear software que aprende a partir de datos. Es realmente el pan de cada día para los científicos de datos, los ingenieros de machine learning, y incluso los ingenieros de datos. ¿La parte de tu solución que proporciona los ingresos por ventas previstos para tu empresa, basándose en tu inventario y tus precios? ¡Eso se ha creado mediante machine learning!
El nivel mínimo de conocimientos que necesitas como científico de datos es ser capaz de entrenar y evaluar modelos. En determinadas situaciones, es posible que desees profundizar y aprender a modificar algoritmos existentes o incluso escribir nuevos algoritmos, entrando así en el ámbito de la ingeniería del machine learning.
Tienes mucha libertad a la hora de llevar a cabo el machine learning. Puedes programar todo tú mismo (en Python, R, C# o Java, con las bibliotecas pertinentes), puedes utilizar paquetes de software locales (como Weka y RapidMiner) o puedes utilizar soluciones en la nube (como Databricks y AWS SageMaker). Aunque esto hace que sea difícil decidir qué aprender, los conocimientos que adquieres se transfieren con bastante facilidad. Una buena idea para decidir qué kit de herramientas de machine learning empezar a utilizar sería partir de un lenguaje que ya conozcas o comprobar qué herramientas se utilizan en el sector que te interesa.
Puedes empezar con nuestro programa de científico de machine learning con Python, que abarca muchos de los fundamentos que necesitarás para iniciar tu carrera.
La relación entre machine learning, el aprendizaje profundo y la inteligencia artificial es discutible.
Cuando enseñaba machine learning, mi primera clase siempre consistía en un animado debate sobre la afirmación «machine learning es una forma de IA». Aunque a veces se utilizan indistintamente, creo firmemente que machine learning hace posible la IA, pero eso no significa que, si utilizas machine learning, hayas creado IA.
Para que una aplicación de datos se convierta en IA, es esencial que exista un bucle de retroalimentación en el que la aplicación o el modelo aprenda de sus resultados. En este caso, un algoritmo de aprendizaje supervisado de una sola vez no es necesariamente IA. Si retroalimentas la salida del modelo al modelo (como en el aprendizaje por refuerzo), obtienes IA, ya que tienes un sistema que sigue aprendiendo automáticamente de sus predicciones correctas e incorrectas.
El aprendizaje profundo no es mucho más que redes neuronales potenciadas. Lo que hace que las aplicaciones sean interesantes es que el aprendizaje profundo permite obtener resultados muy tangibles, ya que estos modelos pueden generar texto, imágenes y voz. Si trabajas en un proyecto de ciencia de datos en el que es esencial que los modelos generen resultados que puedan ser percibidos o experimentados por los usuarios finales humanos, comprender el aprendizaje profundo puede ser una verdadera ventaja. Un curso ideal para empezar es Introducción al aprendizaje profundo en Python.
Ningún esfuerzo en ciencia de datos existe en el vacío. A medida que avanzas en tu camino, es importante conservar y mostrar los artefactos que produces. Parte del trabajo de un científico de datos consiste en demostrar lo que eres capaz de hacer.
Para mí, lo más emocionante de la ciencia de datos es que no se necesita mucho. Solo necesitas un conjunto de datos públicos y un poco de creatividad para plantear una pregunta interesante y luego responderla utilizando los datos. O simplemente puedes entrar en DataLabo Kaggle y empezar a trabajar en las tareas y/o concursos, inspirándote en otras propuestas.
También puedes recopilar y utilizar tus propios datos. He analizado los datos de ciclismo descargados de Strava y he recopilado datos inmobiliarios para ayudarme en tu búsqueda en el mercado inmobiliario.
Lo más importante es que documentes lo que haces. Intenta que tu trabajo sea reproducible, explica los pasos que has seguido, comparte tu código y comparte los resultados de tu análisis o sistema. ¿Quién sabe? Quizás tu ejercicio práctico sea la solución exacta al problema de alguien.

En mi opinión, los proyectos más interesantes son aquellos que surgen de tu propia pasión e intereses. Si utilizas un conjunto de datos de un lugar que conoces bien, es probable que se te ocurran preguntas únicas e interesantes. Conoces el dominio y conoces los datos... Pero si realmente empiezas desde cero, hay muchas cosas en las que puedes empezar a trabajar, como aplicaciones para citas, comercio, deportes...
También puedes encontrar una amplia gama de proyectos de ciencia de datos en DataCamp, que te permitirán familiarizarte con este tipo de trabajo. Ya sea que comiences con algunos proyectos de análisis de datos o trabajes en proyectos específicos de Python, puedes avanzar hasta llegar a proyectos de machine learning e incluso de inteligencia artificial. Hay muchas opciones para ayudarte a empezar.
Si, a pesar de todo lo que hay, no encuentras la manera de empezar, otra alternativa útil podría ser participar en hackatones. Muchos institutos de investigación y grandes empresas organizan hackatones periódicos.
Estos hackatones suelen tener como objetivo que equipos de científicos de datos aporten sus ideas sobre un problema relevante y, por lo tanto, brindan la oportunidad de colaborar con otros profesionales de la ciencia de datos y aprender de ellos. Te permite así crear una red de contactos y llamar la atención de posibles empleadores, al tiempo que adquieres una experiencia útil.
Hoy en día es difícil imaginar a un científico de datos que no tenga un perfil en GitHub, un portafolio en DataCamp, una página en Medium o un blog con código. Un portafolio es algo crucial en la ciencia de datos, al igual que en otras industrias creativas.
Poder mostrar proyectos anteriores es una forma estupenda de convencer a la gente de que tienes lo que hay que tener. Por eso vale la pena empezar a documentar tu trabajo en un portafolio. Como alternativa, puedes documentar tu trabajo y tus puntos de vista en forma de entradas de blog o incluso de publicaciones académicas. Echa un vistazo a nuestra publicación sobre cómo mostrar tu experiencia en datos con un portafolio para inspirarte.
Independientemente de lo que elijas, asegúrate de mantener una visión general presentable de los proyectos en los que has trabajado.
En este artículo se han destacado las diferentes habilidades, conocimientos y herramientas que están a disposición de un científico de datos. Pero, ¿por dónde empezar a la hora de decidir una carrera profesional?
En mi opinión, esto depende realmente de cuáles sean tus ambiciones. Hasta ahora, este artículo debería haber dejado claro que no creo que exista una hoja de ruta única para la ciencia de datos.
Por supuesto, todas las funciones relacionadas con la ciencia de datos se basan en los fundamentos de la estadística, la manipulación de datos, machine learning y la ingeniería de software. Pero, aparte de eso, realmente depende.
Un científico de datos utiliza algoritmos, mientras que un ingeniero de machine learning modifica o crea algoritmos. Por lo tanto, el científico de datos puede limitarse a conocer muchos algoritmos y saber cuándo aplicarlos, mientras que el ingeniero de machine learning realmente tiene que comprender los conceptos matemáticos que hay detrás de los algoritmos.
Del mismo modo, si obtienes tu energía al compartir los resultados de los análisis, como un científico de datos o un analista de datos, es muy probable que te beneficies más de un conocimiento profundo de la visualización de datos y el EDA que de ser muy bueno en el modelado de datos.
Por lo tanto, la hoja de ruta de la ciencia de datos tiene bastantes bifurcaciones, y tú mismo puedes decidir hasta qué punto deseas profundizar en las diferentes ramas de la ciencia de datos.
A pesar de las diferencias entre los puestos, en cualquier entrevista se evaluarán tus habilidades técnicas y sociales. Estas pruebas serán diferentes según el puesto que estés solicitando.
Si no estás buscando un puesto como ingeniero de machine learning o ingeniero de datos, lo más probable es que no te hagan preguntas como «¿Cómo optimizarías el algoritmo A o B?». Por lo tanto, es importante centrarse en las habilidades y, por lo tanto, en las cuestiones en las que se espera que trabajes y en las que estás dispuesto a trabajar. Recibir preguntas sobre temas con los que no estás familiarizado puede ser una señal de que el puesto no es adecuado para ti.
Porque en este campo relativamente nuevo, especialmente en empresas donde los datos son algo relativamente nuevo, existen muchos conceptos erróneos sobre lo que son los científicos de datos o lo que hacen.
Sé que he solicitado el puesto de científico de datos, en cuya entrevista se utilizaron indistintamente los términos «científico de datos» e «ingeniero de machine learning». Por lo tanto, es muy posible que el responsable de contratación haya cometido un error si te hace preguntas que no puedes responder. Por ejemplo, casi nunca se le debería preguntar a un ingeniero de datos cómo gestionarías las partes interesadas en un proyecto.
Afortunadamente, existen varios recursos disponibles para ayudarte a prepararte para las entrevistas en el campo, dependiendo del puesto que solicites:
El campo de la ciencia de datos es muy dinámico, y es fundamental mantenerse al día con las últimas tendencias. Con chatGPT, la IA generativa se ha convertido en algo habitual, y ahora es difícil imaginar a un científico de datos que no tenga al menos alguna noción de las incrustaciones de tokens y/o los modelos de atención. Del mismo modo, la introducción de MLOps hace difícil imaginar que un ingeniero de datos compruebe manualmente el rendimiento y la deriva de los modelos.
Con este crecimiento dinámico, diferentes aspectos de la IA cobran importancia. Actualmente, se presta mucha atención a los aspectos éticos y legales de la IA, como lo demuestran varios debates académicos y políticos que, entre otras cosas, han dado lugar a nuevas normas y reglamentos.
Independientemente de las decisiones que tomen los gobiernos con respecto a la IA, nadie quiere ser responsable del próximo escándalo en el ámbito de la ciencia de datos. La única forma de evitarlo es siendo consciente de los límites éticos y legales. O mejor aún, como profesional de la ciencia de datos, puedes empezar a contribuir a estos avances utilizando tu experiencia y formando y expresando tu opinión.
Hay muchas maneras de mantenerse al día. Por supuesto, existe DataCamp como plataforma, pero también puedes empezar a buscar y seguir a profesionales inspiradores del campo de la ciencia de datos en tu área. Comprueba si tienen blogs, publicaciones en X o Medium, o cualquier otra cosa que te permita hacerte una idea de cómo ven el panorama cambiante y dinámico.

Como hemos destacado a lo largo de este artículo, existen muchos recursos disponibles para cualquiera que desee iniciarse o crecer en el campo de la ciencia de datos. Por otra parte, si deseas estar realmente cerca de la fuente, puedes consultar conferencias técnicas como NeurIPS, ICML o KDD. Echa un vistazo a estas y otras conferencias en nuestra lista de las mejores conferencias sobre ciencia de datos para 2026.
Aunque hay muchas paradas en la hoja de ruta de la ciencia de datos, no existe un único camino hacia la ciencia de datos. Para orientarte en el panorama de la ciencia de datos, necesitas 1) tener una idea general del panorama (que esperamos que hayas obtenido con este artículo) y 2) conocer tus puntos fuertes, tus puntos débiles y tus intereses, de modo que puedas decidir qué camino seguir.
Si cumples estos requisitos, puedes confiar en este artículo para orientarte en la dirección correcta y saber en qué habilidades debes centrarte durante tu formación. Afortunadamente, existen algunos recursos útiles para empezar, como los programas profesionales de DataCamp, que te proporcionan las habilidades necesarias para empezar a explorar diferentes profesiones:
¡Comienza hoy mismo tu aventura en la ciencia de datos!
programa
Curso
Curso
blog
Kevin Babitz
10 min
blog
Javier Canales Luna
13 min
blog
Javier Canales Luna
15 min
