
Lernpfad
SQL Grundlagen
26 Std.
Trainiere dein Team in SQL mit DataCamp for Business. Umfassende Schulungen, praktische Projekte und detaillierte Leistungskennzahlen für dein Unternehmen.

Pivoting in SQL bedeutet, dass Daten von einem zeilenbasierten Format in ein spaltenbasiertes Format umgewandelt werden. Diese Umwandlung ist nützlich für Berichte und Datenanalysen, da sie eine strukturiertere und kompaktere Datenansicht ermöglicht. Das Pivotieren von Zeilen in Spalten ermöglicht es den Nutzern außerdem, Daten so zu analysieren und zusammenzufassen, dass die wichtigsten Erkenntnisse deutlicher hervortreten.
Betrachte das folgende Beispiel: Ich habe eine Tabelle mit täglichen Verkaufstransaktionen, und jede Zeile enthält das Datum, den Produktnamen und den Verkaufsbetrag.
| Datum | Produkt | Verkäufe |
|---|---|---|
| 2024-01-01 | Laptop | 100 |
| 2024-01-01 | Maus | 200 |
| 2024-01-02 | Laptop | 150 |
| 2024-01-02 | Maus | 250 |
Wenn ich diese Tabelle schwenke, kann ich sie so umstrukturieren, dass jedes Produkt als Spalte angezeigt wird und die Verkaufsdaten für jedes Datum in der entsprechenden Spalte stehen. Beachte auch, dass eine Aggregation stattfindet.
| Datum | Laptop | Maus |
|---|---|---|
| 2024-01-01 | 100 | 200 |
| 2024-01-02 | 150 | 250 |
Bisher waren für Pivot-Operationen komplexe SQL-Abfragen mit bedingter Aggregation erforderlich. Im Laufe der Zeit haben sich die SQL-Implementierungen weiterentwickelt. Viele moderne Datenbanken enthalten jetzt PIVOT und UNPIVOT Operatoren, um effizientere und einfachere Transformationen zu ermöglichen.
Die SQL-Pivot-Operation wandelt Daten um, indem sie Zeilenwerte in Spalten umwandelt. Im Folgenden wird die grundlegende Syntax und Struktur von SQL Pivot mit den folgenden Teilen beschrieben:
SELECT: Die Anweisung SELECT verweist auf die Spalten, die in der SQL-Pivot-Tabelle zurückgegeben werden sollen.
Unterabfrage: Die Unterabfrage enthält die Datenquelle oder Tabelle, die in die SQL-Pivot-Tabelle aufgenommen werden soll.
PIVOT: Der Operator PIVOT enthält die Aggregationen und Filter, die in der Pivot-Tabelle angewendet werden sollen.
-- Select static columns and pivoted columns
SELECT <static columns>, [pivoted columns]
FROM
(
-- Subquery defining source data for pivot
<subquery that defines data>
) AS source
PIVOT
(
-- Aggregate function applied to value column, creating new columns
<aggregation function>(<value column>)
FOR <column to pivot> IN ([list of pivoted columns])
) AS pivot_table;Im folgenden Beispiel wird Schritt für Schritt gezeigt, wie du in SQL Zeilen in Spalten umwandeln kannst. Schau dir die folgende Tabelle SalesData an.
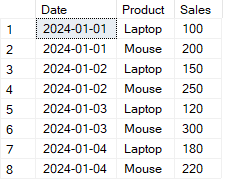
Beispiel für eine Tabelle, die mit dem SQL-Operator PIVOT umgewandelt werden soll. Bild vom Autor.
Ich möchte diese Daten drehen, um die täglichen Verkäufe der einzelnen Produkte zu vergleichen. Ich beginne mit der Auswahl der Unterabfrage, die den PIVOT Operator strukturieren wird.
-- Subquery defining source data for pivot
SELECT Date, Product, Sales
FROM SalesData;Jetzt verwende ich den Operator PIVOT, um die Werte von Product in Spalten umzuwandeln und Sales mit dem Operator SUM zu aggregieren.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;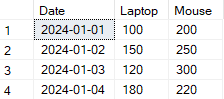
Beispiel für die Umwandlung von Zeilen in Spalten mithilfe von SQL Pivot. Bild vom Autor.
Das Pivotieren von Daten vereinfacht zwar die Datenzusammenfassung, aber diese Technik hat auch ihre Tücken. Im Folgenden werden die potenziellen Herausforderungen von SQL Pivot und ihre Bewältigung beschrieben.
Dynamische Spaltennamen: Wenn die zu drehenden Werte (z. B. Produkttypen) unbekannt sind, funktioniert das Festschreiben von Spaltennamen nicht. Einige Datenbanken, wie z.B. SQL Server, unterstützen dynamisches SQL mit gespeicherten Prozeduren, um dieses Problem zu vermeiden, während es bei anderen Datenbanken auf der Anwendungsebene behandelt werden muss.
Der Umgang mit NULL-Werten: Wenn es keine Daten für eine bestimmte Pivot-Spalte gibt, kann das Ergebnis NULL enthalten. Du kannst COALESCE verwenden, um die Werte von NULL durch Null oder einen anderen Platzhalter zu ersetzen.
Datenbankübergreifende Kompatibilität: Nicht alle Datenbanken unterstützen direkt den PIVOT Operator. Du kannst ähnliche Ergebnisse mit CASE Anweisungen und bedingter Aggregation erzielen, wenn dein SQL-Dialekt dies nicht tut.
Je nach verwendeter Datenbank oder anderen Anforderungen werden verschiedene Methoden zum Pivotieren von Daten in SQL verwendet. Während der PIVOT Operator in SQL Server häufig verwendet wird, ermöglichen andere Techniken, wie z.B. die CASE Anweisungen, ähnliche Datenbanktransformationen ohne direkte PIVOT Unterstützung. Ich werde die beiden gängigen Methoden zum Pivotieren von Daten in SQL behandeln und über die Vor- und Nachteile sprechen.
Der PIVOT Operator, der in SQL Server verfügbar ist, bietet eine einfache Möglichkeit, Zeilen in Spalten zu schwenken, indem du eine Aggregationsfunktion angibst und die zu schwenkenden Spalten definierst.
Betrachte die folgende Tabelle mit dem Namen sales_data.
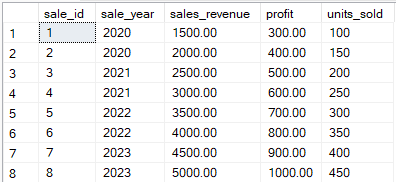
Beispiel Eine Tabelle mit Aufträgen, die mit dem PIVOT-Operator umgewandelt werden soll. Bild vom Autor.
Ich verwende den PIVOT Operator, um die Daten so zu aggregieren, dass die Gesamtsumme jedes Jahres sales_revenue in Spalten angezeigt wird.
-- Use PIVOT to aggregate sales revenue by year
SELECT *
FROM (
-- Select the relevant columns from the source table
SELECT sale_year, sales_revenue
FROM sales_data
) AS src
PIVOT (
-- Aggregate sales revenue for each year
SUM(sales_revenue)
-- Create columns for each year
FOR sale_year IN ([2020], [2021], [2022], [2023])
) AS piv;
Beispiel für die Umwandlung der Ausgabe mit SQL PIVOT. Bild vom Autor.
Die Verwendung des PIVOT Operators hat die folgenden Vorteile und Einschränkungen:
Vorteile: Die Methode ist effizient, wenn die Spalten richtig indiziert sind. Außerdem hat sie eine einfache, besser lesbare Syntax.
Beschränkungen: Nicht alle Datenbanken unterstützen den PIVOT Operator. Die Spalten müssen im Voraus festgelegt werden, und das dynamische Pivotieren erfordert zusätzliche Komplexität.
Du kannst die CASE Anweisungen auch verwenden, um Daten manuell in Datenbanken zu drehen, die keine PIVOT Operatoren unterstützen, wie z.B. MySQL und PostgreSQL. Bei diesem Ansatz wird die bedingte Aggregation verwendet, indem jede Zeile ausgewertet wird und den neuen Spalten anhand bestimmter Kriterien bedingte Werte zugewiesen werden.
Zum Beispiel können wir die Daten in derselben Tabelle sales_data mit CASE Anweisungen manuell drehen.
-- Aggregate sales revenue by year using CASE statements
SELECT
-- Calculate total sales revenue for each year
SUM(CASE WHEN sale_year = 2020 THEN sales_revenue ELSE 0 END) AS sales_2020,
SUM(CASE WHEN sale_year = 2021 THEN sales_revenue ELSE 0 END) AS sales_2021,
SUM(CASE WHEN sale_year = 2022 THEN sales_revenue ELSE 0 END) AS sales_2022,
SUM(CASE WHEN sale_year = 2023 THEN sales_revenue ELSE 0 END) AS sales_2023
FROM
sales_data;
Beispiel für die Umwandlung der Ausgabe mithilfe der SQL-Anweisung CASE. Bild vom Autor.
Die Verwendung der CASE Anweisung für die Umwandlung hat die folgenden Vorteile und Einschränkungen:
Vorteile: Die Methode funktioniert in allen SQL-Datenbanken und ist flexibel, um dynamisch neue Spalten zu erzeugen, auch wenn die Produktnamen unbekannt sind oder sich häufig ändern.
Beschränkungen: Abfragen können komplex und langwierig werden, wenn es viele Spalten zu drehen gibt. Aufgrund der mehrfachen Bedingungsprüfungen ist die Methode etwas langsamer als der PIVOT Operator.
Das Pivotieren von Zeilen zu Spalten in SQL kann sich auf die Leistung auswirken, vor allem wenn du mit großen Datensätzen arbeitest. Hier sind einige Tipps und Best Practices, die dir helfen, effiziente Pivot-Abfragen zu schreiben, ihre Leistung zu optimieren und häufige Fallstricke zu vermeiden.
Im Folgenden findest du die besten Methoden, um deine Abfragen zu optimieren und die Leistung zu verbessern.
Indizierungsstrategien: Die richtige Indizierung ist entscheidend für die Optimierung von Pivot-Abfragen, damit SQL die Daten schneller abrufen und verarbeiten kann. Indiziere immer die Spalten, die häufig in der WHERE Klausel verwendet werden, oder die Spalten, die du gruppierst, um die Suchzeiten zu reduzieren.
Vermeide verschachtelte Pivots: Das Stapeln mehrerer Pivot-Operationen in einer Abfrage kann schwer zu lesen und langsamer in der Ausführung sein. Vereinfache die Abfrage, indem du sie in Teile zerlegst oder eine temporäre Tabelle verwendest.
Spalten und Zeilen in Pivot begrenzen: Für die Analyse sind nur Pivot-Spalten erforderlich, da das Pivoting vieler Spalten ressourcenintensiv sein und große Tabellen erzeugen kann.
Im Folgenden sind die häufigsten Fehler aufgeführt, die dir bei Pivot-Abfragen begegnen können, und wie du sie vermeiden kannst.
Unnötige vollständige Scans der Tabelle: Pivot-Abfragen können vollständige Scans der Tabelle auslösen, insbesondere wenn keine relevanten Indizes vorhanden sind. Vermeide vollständige Scans der Tabelle, indem du Schlüsselspalten indizierst und Daten filterst, bevor du den Pivot anwendest.
Dynamisches SQL für häufiges Pivoting verwenden: Die Verwendung von dynamischem SQL kann die Leistung aufgrund der Neukompilierung von Abfragen verringern. Um dieses Problem zu vermeiden, solltest du dynamische Pivots zwischenspeichern oder auf bestimmte Szenarien beschränken und dynamische Spalten, wenn möglich, in der Anwendungsschicht behandeln.
Aggregieren von großen Datensätzen ohne Vorfilterung: Aggregationsfunktionen wie SUM oder COUNT können bei großen Datenmengen die Datenbankleistung verlangsamen. Anstatt den gesamten Datensatz zu schwenken, filterst du die Daten zunächst mit einer WHERE Klausel.
NULL-Werte in Pivot-Spalten: Pivot-Operationen ergeben oft NULL Werte, wenn es keine Daten für eine bestimmte Spalte gibt. Diese können Abfragen verlangsamen und die Interpretation der Ergebnisse erschweren. Um dieses Problem zu vermeiden, kannst du Funktionen wie COALESCE verwenden, um NULL durch einen Standardwert zu ersetzen.
Testen nur mit Beispieldaten: Pivot-Abfragen können sich bei großen Datensätzen anders verhalten, weil sie mehr Speicher und mehr Verarbeitungsaufwand erfordern. Teste Pivot-Abfragen immer mit echten oder repräsentativen Daten, um die Auswirkungen auf die Leistung genau zu beurteilen.
In unserem Lernpfad für SQL Server-Entwickler/innen erfährst du alles von Transaktionen und Fehlerbehandlung bis hin zur Verbesserung der Abfrageleistung.
Pivot-Operationen unterscheiden sich erheblich zwischen Datenbanken wie SQL Server, MySQL und Oracle. Jede dieser Datenbanken hat eine spezifische Syntax und Einschränkungen. Ich werde Beispiele für das Pivoting von Daten in den verschiedenen Datenbanken und ihre wichtigsten Funktionen behandeln.
SQL Server bietet einen eingebauten PIVOT Operator, der das Pivotieren von Zeilen in Spalten vereinfacht. Der PIVOT Operator ist einfach zu bedienen und lässt sich mit den leistungsstarken Aggregationsfunktionen von SQL Server integrieren. Zu den wichtigsten Merkmalen des Pivotings in SQL gehören die folgenden:
Direkte Unterstützung für PIVOT und UNPIVOT: Der PIVOT Operator von SQL Server ermöglicht eine schnelle Umwandlung von Zeilen in Spalten. Der UNPIVOT Betreiber kann diesen Prozess auch umkehren.
Aggregationsoptionen: Der PIVOT Operator ermöglicht verschiedene Aggregationsfunktionen, wie SUM, COUNT und AVG.
Die Einschränkung des PIVOT Operators in SQL Server besteht darin, dass er voraussetzt, dass die zu drehenden Spaltenwerte im Voraus bekannt sind, was ihn weniger flexibel für sich dynamisch ändernde Daten macht.
Im folgenden Beispiel wandelt der Operator PIVOT die Werte von Product in Spalten um und aggregiert Sales mit dem Operator SUM.
-- Select Date and pivoted columns for each product
SELECT Date, [Laptop], [Mouse]
FROM
(
-- Subquery to fetch Date, Product, and Sales columns
SELECT Date, Product, Sales FROM SalesData
) AS source
PIVOT
(
-- Aggregate Sales by Product, pivoting product values to columns
SUM(Sales)
FOR Product IN ([Laptop], [Mouse])
) AS pivot_table;Ich empfehle den Kurs "Einführung in SQL Server" von DataCamp, um die Grundlagen von SQL Server für die Datenanalyse zu erlernen.
MySQL hat keine native Unterstützung für den PIVOT Operator. Du kannst jedoch die Anweisung CASE verwenden, um Zeilen manuell in Spalten zu drehen und andere Aggregatfunktionen wie SUM, AVG und COUNT zu kombinieren. Diese Methode ist zwar flexibel, aber sie kann kompliziert werden, wenn du viele Spalten zu drehen hast.
Die folgende Abfrage erzielt dieselbe Ausgabe wie das SQL Server PIVOT Beispiel, indem die Verkäufe für jedes Produkt mit der Anweisung CASE bedingt aggregiert werden.
-- Select Date and pivoted columns for each product
SELECT
Date,
-- Use CASE to create a column for Laptop and Mouse sales
SUM(CASE WHEN Product = 'Laptop' THEN Sales ELSE 0 END) AS Laptop,
SUM(CASE WHEN Product = 'Mouse' THEN Sales ELSE 0 END) AS Mouse
FROM SalesData
GROUP BY Date;Oracle unterstützt den PIVOT Operator, der eine einfache Umwandlung von Zeilen in Spalten ermöglicht. Genau wie bei SQL Server musst du die Spalten für die Transformation explizit angeben.
In der folgenden Abfrage wandelt der Operator PIVOT die Werte von ProductName in Spalten um und aggregiert SalesAmount mit dem Operator SUM.
SELECT *
FROM (
-- Source data selection
SELECT SaleDate, ProductName, SaleAmount FROM SalesData
)
PIVOT (
-- Aggregate Sales by Product, creating pivoted columns
SUM(SaleAmount)
FOR ProductName IN ('Laptop' AS Laptop, 'Mouse' AS Mouse)
);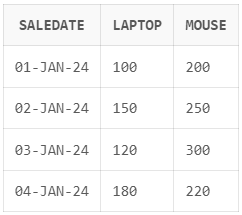
Beispiel für die Umwandlung der Ausgabe mit dem SQL-Operator PIVOT in Oracle. Bild vom Autor.
Fortgeschrittene Techniken zum Pivotieren von Zeilen in Spalten sind nützlich, wenn du Flexibilität bei der Handhabung komplexer Daten brauchst. Dynamische Techniken und die gleichzeitige Bearbeitung mehrerer Spalten ermöglichen es dir, Daten in Szenarien zu transformieren, in denen statisches Pivoting nur begrenzt möglich ist. Lass uns diese beiden Methoden im Detail untersuchen.
Mit dynamischen Pivots kannst du Pivot-Abfragen erstellen, die sich automatisch an Änderungen in den Daten anpassen. Diese Technik ist besonders nützlich, wenn du Spalten hast, die sich häufig ändern, wie z. B. Produktnamen oder Kategorien, und du möchtest, dass deine Abfrage automatisch neue Einträge enthält, ohne dass du sie manuell aktualisieren musst.
Angenommen, wir haben eine Tabelle SalesData und können einen dynamischen Pivot erstellen, der sich anpasst, wenn neue Produkte hinzugefügt werden. In der folgenden Abfrage erstellt @columns dynamisch die Liste der Pivot-Spalten und sp_executesql führt die generierte SQL aus.
DECLARE @columns NVARCHAR(MAX), @sql NVARCHAR(MAX);
-- Step 1: Generate a list of distinct products to pivot
SELECT @columns = STRING_AGG(QUOTENAME(Product), ', ')
FROM (SELECT DISTINCT Product FROM SalesData) AS products;
-- Step 2: Build the dynamic SQL query
SET @sql = N'
SELECT Date, ' + @columns + '
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(
SUM(Sales)
FOR Product IN (' + @columns + ')
) AS pivot_table;';
-- Step 3: Execute the dynamic SQL
EXEC sp_executesql @sql;In Szenarien, in denen du mehrere Spalten gleichzeitig drehen musst, verwendest du den PIVOT Operator und zusätzliche Aggregationstechniken, um mehrere Spalten in derselben Abfrage zu erstellen.
Im folgenden Beispiel habe ich die Spalten Sales und Quantity nach Product gepivotet.
-- Pivot Sales and Quantity for Laptop and Mouse by Date
SELECT
p1.Date,
p1.[Laptop] AS Laptop_Sales,
p2.[Laptop] AS Laptop_Quantity,
p1.[Mouse] AS Mouse_Sales,
p2.[Mouse] AS Mouse_Quantity
FROM
(
-- Pivot for Sales
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Sales FROM SalesData) AS source
PIVOT
(SUM(Sales) FOR Product IN ([Laptop], [Mouse])) AS pivot_sales
) p1
JOIN
(
-- Pivot for Quantity
SELECT Date, [Laptop], [Mouse]
FROM
(SELECT Date, Product, Quantity FROM SalesData) AS source
PIVOT
(SUM(Quantity) FOR Product IN ([Laptop], [Mouse])) AS pivot_quantity
) p2
ON p1.Date = p2.Date;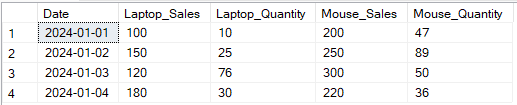
Beispiel für die Umwandlung von mehreren Spalten mit dem SQL PIVOT-Operator. Bild vom Autor.
Die Pivotierung mehrerer Spalten ermöglicht detailliertere Berichte, indem mehrere Attribute pro Artikel gepivotet werden, was einen tieferen Einblick ermöglicht. Die Syntax kann jedoch komplex sein, vor allem wenn viele Spalten vorhanden sind. Hardcoding kann erforderlich sein, es sei denn, es wird mit dynamischen Pivot-Techniken kombiniert, was die Komplexität weiter erhöht.
Das Pivotieren von Zeilen in Spalten ist eine SQL-Technik, die man lernen sollte. Ich habe gesehen, dass SQL-Pivot-Techniken verwendet werden, um eine Tabelle mit Kohortenbindung zu erstellen, in der du die Nutzerbindung im Laufe der Zeit verfolgen kannst. Ich habe auch gesehen, dass SQL-Pivot-Techniken bei der Analyse von Umfragedaten verwendet werden, bei denen jede Zeile einen Befragten darstellt und jede Frage in die zugehörige Spalte gedreht werden kann.
Unser Kurs Reporting in SQL ist eine gute Option, wenn du mehr über die Zusammenfassung und Aufbereitung von Daten für Präsentationen und/oder die Erstellung von Dashboards lernen möchtest. Unsere Lernpfade "Associate Data Analyst in SQL" und "Associate Data Engineer in SQL" sind ebenfalls eine tolle Idee und werten jeden Lebenslauf auf, also melde dich noch heute an.
SQL lernen mit DataCamp
Lernpfad
Lernpfad
Kurs
Tutorial
Allan Ouko
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Satyabrata Pal
Tutorial
Kurtis Pykes
