
Curso
Conceptos de MLOps
2 h
42.6K
Los modelos de machine learning se entrenan con datos históricos, pero cuando pasan a producción pueden quedar desfasados y perder precisión con el tiempo por un fenómeno llamado drift. El drift es el cambio, a lo largo del tiempo, de las propiedades estadísticas de los datos con los que se entrenó un modelo. Esto puede hacer que el modelo pierda precisión o se comporte de forma distinta a como fue diseñado.
En otras palabras, el "drift" es la caída en la capacidad de un modelo para hacer predicciones precisas debido a cambios en el entorno en el que se utiliza.
Hay varias razones por las que los modelos de machine learning pueden derivar con el tiempo.
Una razón habitual es simplemente que los datos con los que se entrenó el modelo quedan obsoletos o dejan de representar las condiciones actuales.
Por ejemplo, imagina un modelo entrenado para predecir el precio de una acción a partir de datos históricos. Si lo entrenamos con datos de un mercado estable, quizá funcione bien al principio. Sin embargo, si el mercado se vuelve más volátil con el tiempo, el modelo podría dejar de predecir con precisión porque han cambiado las propiedades estadísticas de los datos.
Otra razón es que el modelo no esté diseñado para manejar cambios en los datos. Algunos modelos toleran mejor estos cambios que otros, pero ningún modelo puede evitar el drift por completo.
Veamos dos tipos de drift que debes tener en cuenta:
El concept drift, también llamado model drift, ocurre cuando la tarea para la que se diseñó el modelo cambia con el tiempo. Por ejemplo, piensa en un modelo entrenado para detectar spam en correos en función de su contenido. Si los tipos de correos de spam que la gente recibe cambian de forma significativa, el modelo puede dejar de detectarlos con precisión.
El concept drift puede dividirse en cuatro categorías (Learning under Concept Drift: A Review, Jie Lu et al.):
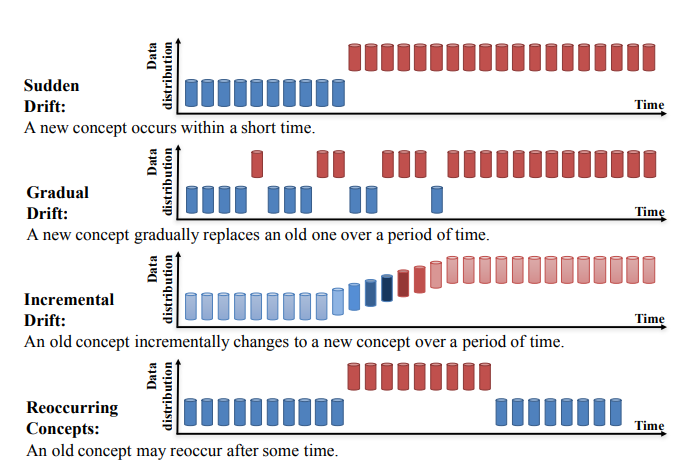
Source: https://arxiv.org/pdf/2004.05785.pdf
El data drift, también conocido como covariate shift, se produce cuando la distribución de los datos de entrada cambia con el tiempo. Por ejemplo, imagina un modelo entrenado para predecir la probabilidad de que un cliente compre un producto a partir de su edad y sus ingresos. Si la distribución de edades e ingresos cambia de forma significativa con el tiempo, el modelo puede dejar de predecir correctamente esa probabilidad.
Es importante tener presentes tanto el concept drift como el data drift y tomar medidas para prevenirlos o mitigar sus efectos. Algunas estrategias pasan por monitorizar y evaluar continuamente el rendimiento del modelo, actualizarlo con datos nuevos y utilizar modelos más robustos al drift.
Puedes saber más sobre la data science postdespliegue, incluido el drift, en nuestro episodio del pódcast DataFramed.
Los LLM introducen un tipo de drift para el que los métodos anteriores no estaban pensados. Los datos no son filas en una tabla, sino texto libre, y lo que cambia con el tiempo suele ser el significado de lo que piden los usuarios. Actualmente se habla de tres formas de drift en LLM que conviene monitorizar.
El embedding drift ocurre cuando cambia el significado del texto que envían los usuarios a un modelo, aunque a simple vista el texto parezca el mismo. Los LLM convierten el texto en listas largas de números llamadas embeddings, y el drift puede aparecer en esos números sin reflejarse en métricas textuales habituales.
Imagina un chatbot de soporte que al principio resolvía sobre todo dudas de configuración e inicio. Seis meses después, el volumen de mensajes y su longitud media no cambian, pero ahora la mayoría de preguntas son sobre facturación y bajas. Las estadísticas del texto parecen estables, pero la distribución de embeddings ha cambiado. Para detectarlo, los equipos comparan lotes de embeddings recientes con un lote de referencia usando una medida de distancia estadística.
El drift de prompts sigue la misma idea que el embedding drift, pero un nivel por encima. En lugar de comparar embeddings en bruto, agrupas las consultas entrantes en categorías —con un clasificador u otro LLM— y observas los cambios en la mezcla.
Imagina que un asistente interno para programadores backend empieza poco a poco a recibir tráfico de data scientists con preguntas de pandas. El asistente quizá siga respondiendo bien, pero la población a la que sirve ya no es la que se usó en las pruebas, y el prompt del sistema o el índice de recuperación puede que dejen de encajar con el tiempo.
El drift de rúbrica es un cambio con el tiempo en las puntuaciones de calidad que un evaluador automático da a las respuestas de un modelo. Muchos equipos en producción usan ahora un LLM como juez, puntuando cada respuesta en utilidad, exactitud o tono. Cuando esas puntuaciones empiezan a caer para las mismas clases de entrada, algo suele haber cambiado: el modelo detrás de una API, los documentos que se recuperan o la mezcla de usuarios.
Lo que hace especialmente útil el drift de rúbrica es que te da una señal de calidad sin necesidad de etiquetas de verdad terreno, que rara vez están disponibles en tiempo real para salidas generativas.
Hay dos formas de detectar drift:
1. Enfoque basado en modelos de machine learning: usar un modelo para detectar si los datos de entrada que llegan han derivado o no.
2. Pruebas estadísticas: existen muchas pruebas para detectar data drift. Se dividen principalmente en tres categorías:
Los métodos basados en la distribución temporal utilizan técnicas estadísticas para calcular la diferencia entre dos distribuciones de probabilidad y así detectar drift. Entre ellos están el Population Stability Index, la divergencia KL, la divergencia JS, la prueba KS y la métrica de Wasserstein.
La prueba de Kolmogorov-Smirnov (K-S) es una prueba estadística no paramétrica que se usa para determinar si dos conjuntos de datos provienen de la misma distribución. Suele emplearse para comprobar si una muestra procede de una población concreta o para comparar dos muestras y ver si pertenecen a la misma población.
La hipótesis nula en esta prueba es que las distribuciones son iguales. Si se rechaza, sugiere que existe drift en el modelo.
La prueba K-S es una herramienta útil para comparar conjuntos de datos y determinar si proceden de la misma distribución.
El Population Stability Index (PSI) es una medida estadística que se utiliza para comparar la distribución de una variable (a menudo categórica) en dos conjuntos de datos distintos.
El Population Stability Index (PSI) sirve para medir cuánto ha cambiado la distribución de una variable entre dos muestras o a lo largo del tiempo. Suele utilizarse para monitorizar cambios en las características de una población e identificar posibles problemas en el rendimiento de un modelo de machine learning.
El PSI se desarrolló originalmente para vigilar cambios en la distribución de una puntuación en scorecards de riesgo, pero hoy se usa para examinar cambios de distribución en todos los atributos relacionados con el modelo, incluidas variables dependientes e independientes.
Un valor alto de PSI indica una diferencia significativa entre las distribuciones de la variable en ambos conjuntos, lo que puede sugerir drift en el modelo.
Si la distribución de una variable ha cambiado mucho, o si varias variables han cambiado en cierta medida, puede ser necesario recalibrar o reconstruir el modelo para mejorar su rendimiento.
El método de Page-Hinkley es una técnica estadística para detectar cambios en la media de una serie de datos a lo largo del tiempo. Se usa con frecuencia para monitorizar el rendimiento de modelos de machine learning y detectar cambios en la distribución de los datos que puedan indicar model drift.
Para usar Page-Hinkley, primero se define un umbral y una función de decisión. El umbral es el valor a partir del cual un cambio en la media se considera significativo, y la función de decisión devuelve 1 si se ha detectado un cambio y 0 si no.
Después, se calcula la media de la serie en cada instante y se aplica la función de decisión para determinar si ha ocurrido un cambio. Si la función devuelve 1, indica que se ha detectado un cambio y que el modelo puede estar derivando.
Page-Hinkley es una forma sencilla y eficaz de detectar cambios en la media de una serie temporal. Es especialmente útil para detectar cambios pequeños que podrían pasar desapercibidos a simple vista. No obstante, es importante seleccionar bien el umbral y la función de decisión para que el método sea lo bastante sensible como para detectar cambios sin generar falsas alarmas.
En esta sección usaremos Evidently para detectar drift. Evidently es una biblioteca de Python de código abierto para data scientists e ingenieros que trabajan con machine learning. Ayuda a probar, evaluar y hacer seguimiento del rendimiento de los modelos desde la validación hasta producción.
import pandas as pd
import numpy as np
from sklearn import datasets
from evidently import Report
from evidently.presets import DataDriftPreset# create ref and cur dataset for drift detection
adult_data = datasets.fetch_openml(name='adult', version=2, as_frame=True)
adult = adult_data.frame
adult_ref = adult[~adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur = adult[adult.education.isin(['Some-college', 'HS-grad', 'Bachelors'])].copy()
adult_cur.iloc[:2000, 3:5] = np.nan#dataset-level metrics
report = Report([DataDriftPreset()], include_tests=True)
my_eval = report.run(current_data=adult_cur, reference_data=adult_ref)
my_eval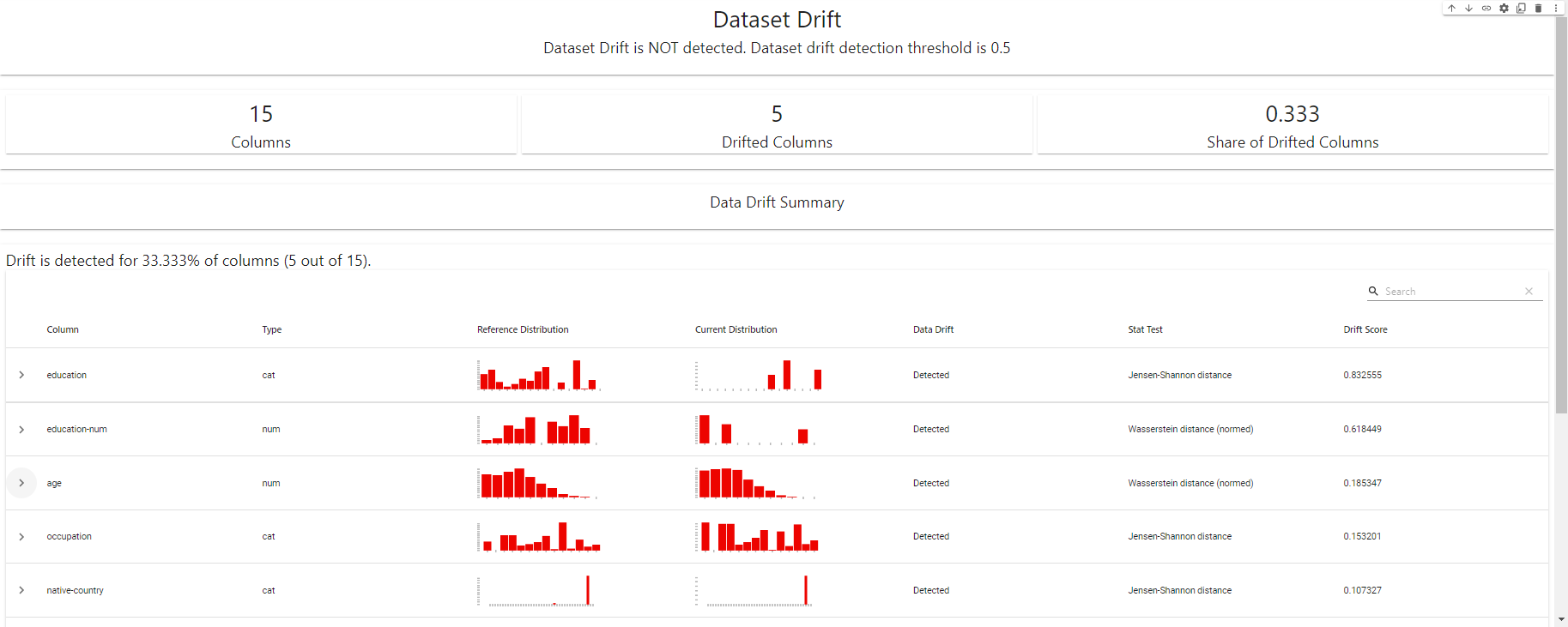
Panel de detección de drift - creado con EvidentlyAI
#report in a JSON format
my_eval.json()
Echa un vistazo al Notebook completo de Datacamp aquí.
El data drift y el model drift pueden suponer un reto importante para los sistemas de machine learning en producción. Si entiendes sus causas y efectos, e implementas prácticas eficaces de monitorización, tus modelos seguirán siendo precisos y fiables con el tiempo.
Monitorizar el rendimiento de tus modelos, usar un modelo de detección de drift y reentrenar periódicamente con datos actualizados son solo algunas de las mejores prácticas para mitigar sus riesgos. Si eres proactivo con la monitorización del drift, te asegurarás de que tu sistema de machine learning siga aportando valor a tu organización.
Vigilar el drift es solo una parte de un ámbito más amplio llamado MLOps. Entender los conceptos de MLOps es esencial para cualquier data scientist, ingeniero o líder que quiera llevar modelos desde un notebook local hasta producción.
Si quieres profundizar en MLOps y cómo puede impulsar tu carrera profesional, consulta nuestro curso MLOps Concepts. Aprenderás qué es MLOps, las distintas fases de sus procesos y los niveles de madurez. Con estos conceptos esenciales, estarás listo para implementar machine learning de forma continua, fiable y eficiente.
Cursos de MLOps
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Zoumana Keita
