Visualisasi membantu kita memahami dunia dan memungkinkan kita menyampaikan sejumlah besar informasi, data, dan prediksi yang kompleks dalam bentuk yang ringkas. Prediksi pakar yang perlu disampaikan kepada audiens non-pakar, baik itu jalur badai maupun hasil pemilihan umum, selalu mengandung tingkat ketidakpastian. Jika ketidakpastian ini tidak disampaikan dalam visualisasi yang relevan, hasilnya bisa menyesatkan bahkan berbahaya.
Di sini, kita akan mengeksplorasi peran visualisasi data dalam memetakan jalur prediksi badai. Kita akan menelusuri berbagai metode visual untuk menyampaikan ketidakpastian prediksi pakar dan dampaknya terhadap interpretasi orang awam. Selain itu, kita akan menghubungkannya dengan diskusi yang lebih luas mengenai praktik terbaik terkait bagaimana media berita melaporkan model pakar dan hasil ilmiah tentang topik-topik yang penting bagi masyarakat luas.
Tidak Perlu Spaghetti Plot?
Kita baru saja melihat kerusakan yang ditimbulkan oleh sistem badai tropis di Amerika. Media berita seperti New York Times telah menyampaikan banyak informasi tentang apa yang terjadi menggunakan visualisasi interaktif untuk Badai Harvey dan Irma, misalnya. Visualisasi tersebut mencakup visualisasi geografis persentase orang yang tidak mendapatkan listrik, jumlah curah hujan, jumlah kerusakan, dan jumlah orang di tempat penampungan, di antara banyak hal lainnya.
Satu jenis plot tertentu akhir-akhir ini cukup sering muncul dan menimbulkan kontroversi: bagaimana cara memplot jalur prediksi badai, katakanlah, selama 72 jam ke depan. Ada beberapa cara untuk memvisualisasikan jalur prediksi, masing-masing dengan kekurangan dan kesalahpahamannya sendiri. Baru-baru ini, kita bahkan melihat artikel di Ars Technica berjudul Tolong, tolong berhenti membagikan spaghetti plot model badai, yang ditujukan kepada Nate Silver dan fivethirtyeight.
Selanjutnya, saya akan membandingkan tiga cara umum, mengeksplorasi pro dan kontranya, serta memberikan saran untuk jenis plot lainnya. Saya juga akan mendalami mengapa jenis-jenis ini penting, yang akan membantu kita memutuskan metode dan teknik visual mana yang paling tepat.
Penafian: Saya jelas bukan pakar dalam masalah meteorologi dan prakiraan badai. Namun, saya telah banyak memikirkan metode visual untuk menyampaikan data, prediksi, dan model. Saya menyambut dan sangat mendorong masukan dari para pakar, serta dari pihak lainnya.
Memvisualisasikan Jalur Prediksi Badai
Ada tiga cara umum untuk membuat visualisasi jalur prediksi badai. Sebelum membahasnya, saya ingin Anda melihatnya dan mempertimbangkan informasi apa yang bisa Anda dapatkan dari masing-masing plot tersebut. Cobalah untuk menafsirkan apa yang ingin disampaikan oleh masing-masing plot tersebut, lalu kita akan mendalami apa tujuan, serta pro dan kontranya:
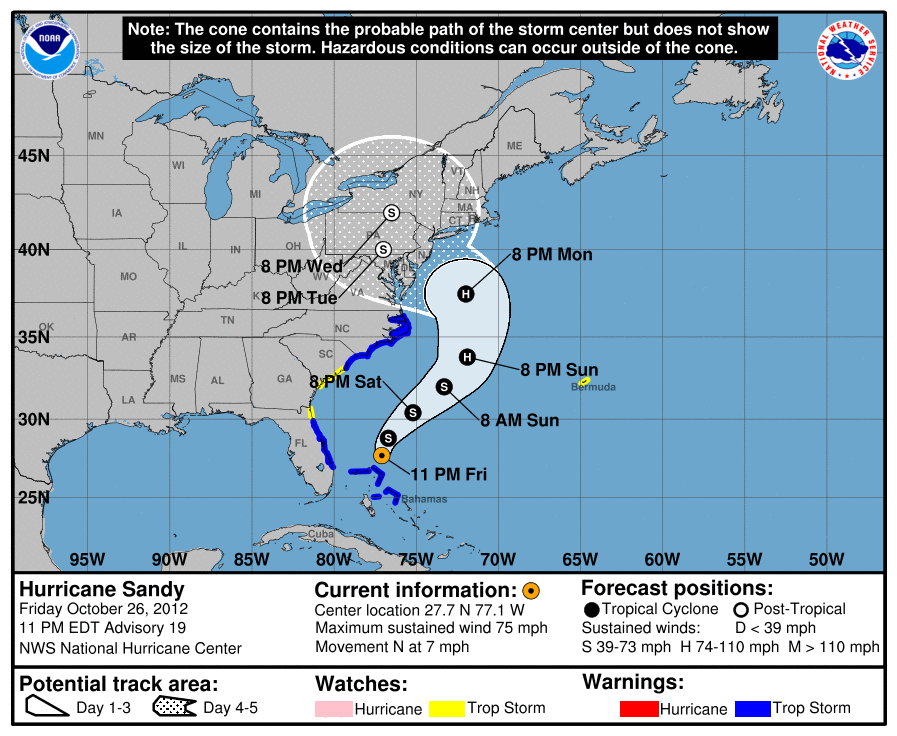
Kerucut Ketidakpastian (Cone of Uncertainty)
Spaghetti Plot (Tipe I)
Spaghetti Plot (Tipe II)
Interpretasi dan Dampak Visualisasi Jalur Prediksi Badai
Kerucut Ketidakpastian (Cone of Uncertainty)
Kerucut ketidakpastian, alat yang digunakan oleh National Hurricane Center (NHC) dan dikomunikasikan oleh banyak media berita, menunjukkan kepada kita jalur badai yang paling mungkin selama lima hari ke depan, yang ditandai dengan titik-titik hitam di dalam kerucut. Alat ini juga menunjukkan seberapa yakin mereka terhadap jalur tersebut. Seiring berjalannya waktu, prediksi menjadi kurang pasti dan hal ini ditangkap oleh kerucut tersebut, di mana terdapat peluang sekitar 66,6% bahwa pusat badai akan berada dalam batas kerucut.
Apakah hal ini terlihat jelas dari plot itu sendiri?
Awalnya tidak bagi saya, dan saya mengumpulkan informasi ini dari plot itu sendiri, halaman 'tentang kerucut ketidakpastian' milik NHC, dan postingan demistifikasi kerucut dari weather.com. Ada tiga poin penting lainnya, yang semuanya akan kita bahas kembali:
- Merupakan kesalahpahaman awal yang umum bahwa pelebaran kerucut seiring waktu menunjukkan bahwa badai akan membesar;
- Plot tersebut tidak berisi informasi tentang ukuran badai, hanya tentang potensi jalur pusatnya, sehingga kegunaannya terbatas dalam memberi tahu kita di mana harus mengantisipasi, misalnya, angin berkekuatan badai;
- Terdapat informasi penting yang terkandung dalam teks yang menyertai visualisasi, serta visualisasi itu sendiri, seperti catatan yang ditempatkan secara mencolok di bagian atas, '[k]erucut berisi jalur kemungkinan pusat badai tetapi tidak menunjukkan ukuran badai...'; saat menilai efikasi visualisasi data, kita perlu mempertimbangkan semua propertinya, termasuk teks (dan apakah kita benar-benar bisa mengharapkan orang untuk membacanya!); perhatikan bahwa interaktivitas adalah properti yang tidak dimiliki oleh visualisasi ini (tetapi mungkin seharusnya ada).
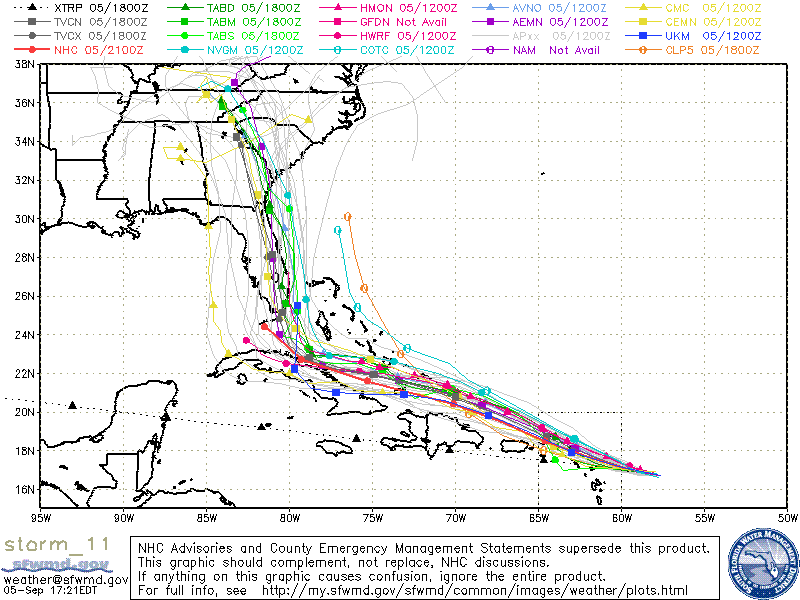
Spaghetti Plot (Tipe I)
Jenis plot ini menunjukkan beberapa prediksi dalam satu plot. Pada setiap spaghetti plot Tipe I, lintasan yang divisualisasikan adalah prediksi dari model berbagai lembaga (misalnya, NHC, National Oceanic and Atmospheric Administration, dan UK Met Office). Plot ini berguna karena, seperti kerucut ketidakpastian, plot ini memberi tahu kita wilayah umum yang mungkin berada di jalur badai. Plot ini sangat tidak berguna dan justru menyesatkan karena memberikan bobot yang sama pada setiap model (atau prediksi).
Pada spaghetti plot Tipe I di atas, terdapat prediksi dengan tingkat ketidakpastian yang bervariasi dari lembaga yang sebelumnya telah membuat prediksi dengan tingkat keberhasilan yang bervariasi. Jadi, beberapa jalur lebih mungkin terjadi daripada yang lain, berdasarkan apa yang kita ketahui saat ini. Informasi ini tidak ada. Yang lebih mengkhawatirkan, beberapa jalur bahkan hampir bukan merupakan prediksi. Ambil contoh garis putus-putus hitam XTRP, yang merupakan prediksi garis lurus berdasarkan lintasan badai saat ini. Ini bahkan bukan sebuah model. Eric Berger membahas lebih detail dalam artikel Ars Technica ini.
Pada dasarnya, jenis plot ini menyediakan model ansambel (bandingkan dengan agregator jajak pendapat). Namun, aspek kunci dari model ansambel adalah bahwa setiap model diberikan bobot yang sesuai dan bobot ini perlu dikomunikasikan dalam visualisasi data apa pun. Kita akan segera melihat cara melakukannya menggunakan variasi pada Tipe I.
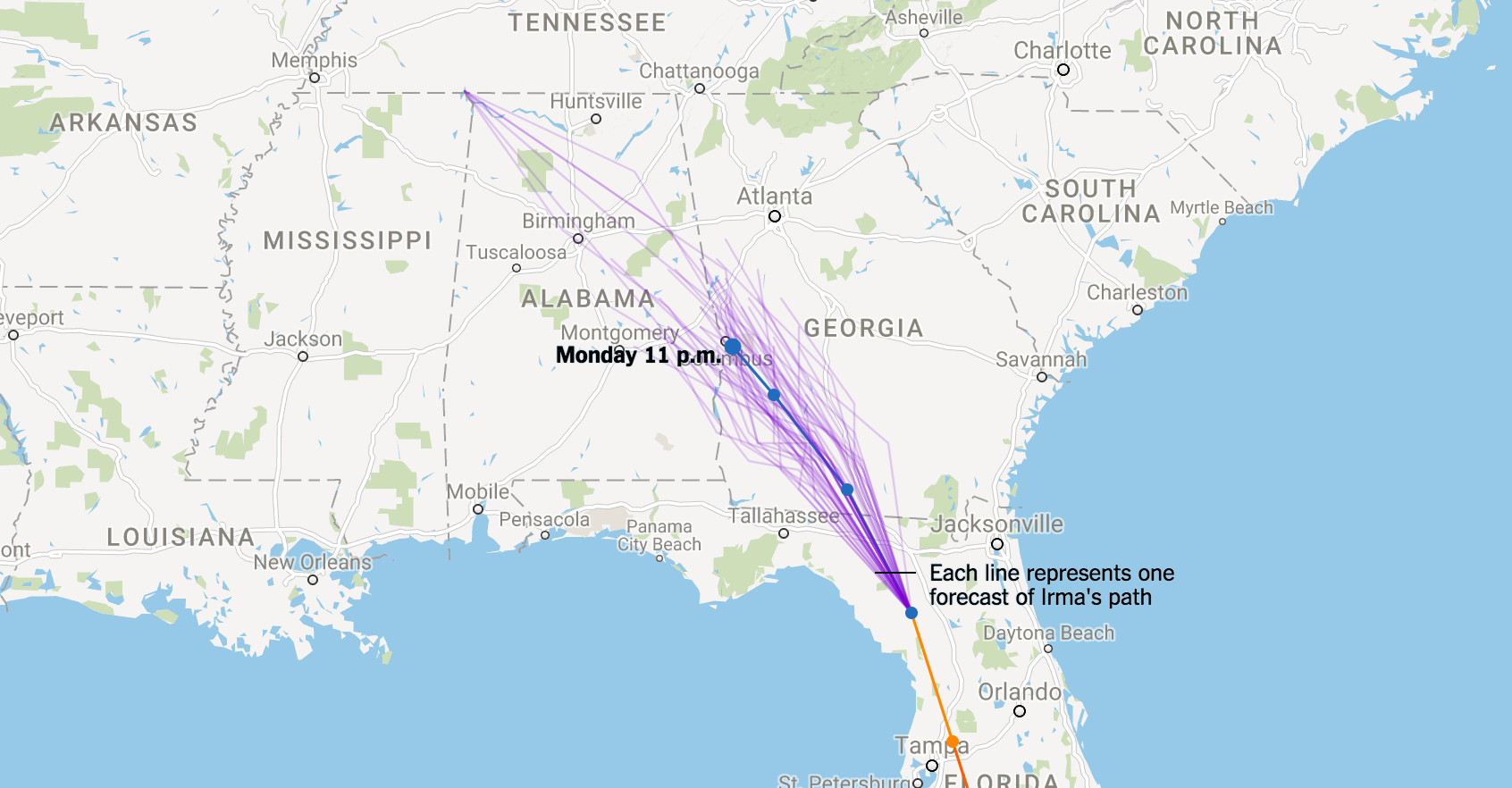
Spaghetti Plot (Tipe II)
Plot ini menunjukkan banyak, katakanlah 50, realisasi berbeda dari model tertentu. Intinya adalah jika kita mensimulasikan (menjalankan) suatu model beberapa kali, model tersebut akan memberikan lintasan yang berbeda setiap saat. Mengapa? Nate Cohen menjelaskannya dengan baik di The Upshot:
Sangat sulit untuk memperkirakan dengan tepat kapan badai akan berbelok. Perbedaan 15 atau 20 mil saja dalam waktu kapan badai berbelok ke utara dapat mengubah apakah Miami akan terkena dinding mata, cincin badai petir dahsyat yang mencakup angin terkuat badai dan mengelilingi mata badai yang lebih tenang.
Ini mungkin favorit saya dari ketiganya karena beberapa alasan:
- Dengan mensimulasikan beberapa kali jalannya model, plot ini memberikan indikasi ketidakpastian yang mendasari setiap model;
- Plot ini memberikan gambaran tentang kemungkinan relatif pusat badai melewati lokasi tertentu. Sederhananya, jika lebih banyak lintasan yang diplot melewati lokasi A daripada lokasi B, maka di bawah model saat ini, lebih mungkin pusat badai akan melewati lokasi A;
- Plot ini tidak mungkin disalahartikan (setidaknya dibandingkan dengan kerucut ketidakpastian dan plot Tipe I). Semua kata yang diperlukan pada visualisasi hanyalah 'Setiap garis mewakili satu prakiraan jalur Irma'.
Satu kekurangan Tipe II adalah plot ini tidak mewakili beberapa model, tetapi seperti yang akan kita lihat, ini dapat diubah dengan menggabungkannya dengan plot Tipe I. Kekurangan lainnya adalah, seperti yang lain, plot ini hanya mengomunikasikan jalur pusat badai dan tidak mengatakan apa pun tentang ukurannya. Segera kita juga akan melihat bagaimana kita bisa memperbaiki ini. Perhatikan bahwa perbedaan antara spaghetti plot Tipe I dan Tipe II bukanlah perbedaan yang saya temukan dalam literatur, melainkan perbedaan yang saya buat karena plot ini memiliki interpretasi dan efek yang sangat berbeda.
Namun untuk saat ini, perhatikan bahwa kita telah mendiskusikan efikasi jenis plot tertentu tanpa secara eksplisit mendiskusikan tujuannya, yaitu mengapa kita membutuhkannya sama sekali. Sebelum melangkah lebih jauh, mari kita mundur sedikit dan mencoba menjawab pertanyaan 'Apa tujuan memvisualisasikan jalur prediksi badai?' Melakukan tugas-tugas yang tampaknya naif sering kali mencerahkan.
Mengapa Memplot Jalur Prediksi Badai?
Mengapa kita mencoba menyampaikan jalur prediksi badai tropis? Saya akan memberikan beberapa jawaban untuk ini sebentar lagi.
Namun pertama-tama, izinkan saya mengatakan untuk apa visualisasi ini tidak ditujukan. Kita tidak menggunakan visualisasi ini untuk membantu orang memutuskan apakah akan mengungsi dari rumah atau kota mereka atau tidak. Memerintahkan atau menyarankan evakuasi adalah sesuatu yang dilakukan oleh otoritas setempat, setelah konsultasi berulang kali dengan pakar, ilmuwan, pemodel, dan pemangku kepentingan utama lainnya.
Poin utama dari jenis visualisasi ini adalah agar masyarakat umum mendapatkan informasi sebaik mungkin tentang kemungkinan jalur badai dan memungkinkan mereka untuk bersiap menghadapi yang terburuk jika ada kemungkinan bahwa tempat mereka berada atau akan berada berada di jalur kehancuran. Tujuannya bukan untuk menakut-nakuti orang secara berlebihan. Seperti yang dinyatakan weather.com terkait fungsi kerucut ketidakpastian, '[s]etiap sistem tropis diberikan kerucut prakiraan untuk membantu publik lebih memahami ke mana arahnya' dan '[k]erucut dirancang untuk menunjukkan meningkatnya ketidakpastian prakiraan seiring waktu.'
Untuk tujuan ini, menurut saya properti penting adalah agar pembaca dapat melihatnya dan berkata 'sangat mungkin/mungkin/50% mungkin/tidak mungkin/sangat tidak mungkin' bahwa rumah saya (misalnya) akan rusak parah oleh badai.
Lebih baik lagi, agar bisa berkata "Ada peluang 30-40%, berdasarkan pemodelan mutakhir saat ini, bahwa rumah saya akan rusak parah".
Maka kita memiliki hierarki tentang apa yang ingin kita komunikasikan melalui visualisasi kita:
- Paling tidak, kita ingin warga sadar akan kemungkinan jalur badai.
- Kemudian kita ingin warga dapat mengatakan apakah sangat mungkin, mungkin, tidak mungkin, atau sangat tidak mungkin bahwa rumah mereka, misalnya, berada di jalur tersebut.
- Idealnya, seorang warga akan melihat visualisasi dan dapat membaca secara kuantitatif berapa probabilitas (atau kisaran probabilitas) rumah mereka berada di jalur badai.
Selain itu, kita ingin visualisasi kita tidak menyesatkan dan tidak mudah disalahartikan.
Kerucut Ketidakpastian versus Spaghetti Plot
Ketiga metode tersebut menjalankan fungsi minimum yang diperlukan, yaitu untuk memperingatkan warga akan kemungkinan jalur badai. Kerucut ketidakpastian melakukan pekerjaan yang cukup baik dalam memungkinkan warga untuk mengatakan seberapa besar kemungkinan badai melewati lokasi tertentu (di dalam kerucut, kemungkinannya sekitar dua pertiga). Setidaknya secara kualitatif, spaghetti plot Tipe II juga melakukan pekerjaan yang baik di sini, seperti yang dijelaskan di atas, 'jika lebih banyak lintasan melewati lokasi A daripada lokasi B, maka di bawah model saat ini, lebih mungkin pusat badai akan melewati lokasi A'.
Jika Anda memplot 50 lintasan, Anda mendapatkan gambaran di mana pusat badai kemungkinan besar berada, yaitu, jika sekitar setengah dari lintasan melewati suatu lokasi, maka ada peluang sekitar 50% (menurut model kita) bahwa pusat badai akan menghantam lokasi tersebut. Belum ada metode ini yang menjalankan fungsi ke-3 dan kita akan melihat di bawah bagaimana menggabungkan spaghetti plot Tipe I dan Tipe II akan memungkinkan kita melakukan ini.
Masalah utama dengan kerucut ketidakpastian dan model spaghetti Tipe I adalah bahwa kerucut ketidakpastian mudah disalahartikan (karena banyak orang menafsirkan kerucut sebagai badai yang membesar dan tidak menghargai peran ketidakpastian) dan bahwa model spaghetti Tipe I menyesatkan (membuat semua model terlihat sama dapat dipercaya). Model-model ini kemudian tidak memenuhi persyaratan dasar bahwa 'kita ingin visualisasi kita tidak menyesatkan dan tidak mudah disalahartikan.'
Praktik Terbaik untuk Memvisualisasikan Jalur Prediksi Badai
Spaghetti plot Tipe II adalah yang paling deskriptif dan paling tidak terbuka terhadap salah tafsir. Namun, plot ini gagal dalam menyajikan hasil dari semua model. Artinya, plot ini tidak mengagregasi beberapa model seperti yang kita lihat pada Tipe I.
Jadi bagaimana jika kita menggabungkan Tipe I dan Tipe II?
Untuk menjawab ini, saya melakukan eksperimen kecil menggunakan python, folium, dan numpy. Anda dapat menemukan semua kodenya di sini.
Saya pertama-tama mengambil salah satu jalur prediksi Badai Irma dari NHC minggu lalu, menambahkan beberapa derau acak, dan memplot 50 lintasan. Perhatikan bahwa, sekali lagi, saya bukan pakar dalam semua masalah meteorologi. Derau yang saya buat dan tambahkan ke sinyal/jalur prediksi tidak didasarkan pada model apa pun dan, dalam kasus penggunaan nyata, akan berasal dari model itu sendiri (jika Anda tertarik, saya menggunakan derau Gaussian). Sebagai catatan, saya juga merasa sulit menemukan data mengenai jalur prediksi apa pun yang dilaporkan di media. Data yang akhirnya saya gunakan saya temukan di sini.
Berikut adalah spaghetti plot Tipe II sederhana dengan 50 lintasan:
Tetapi ini adalah kemungkinan lintasan yang dihasilkan oleh satu model. Bagaimana jika kita memiliki beberapa model dari lembaga yang berbeda? Nah, kita bisa memplot 50 lintasan dari masing-masing model:
Salah satu aspek yang sangat keren dari spaghetti plot Tipe II adalah, jika kita memplot cukup banyak, setiap lintasan menjadi tidak jelas dan kita mulai melihat peta panas (heatmap) di mana pusat badai kemungkinan besar berada. Semua ini berarti bahwa semakin biru suatu wilayah, semakin besar kemungkinan jalur badai melewatinya. Perbesar untuk melihatnya.
Selain itu, jika kita yakin bahwa satu model lebih mungkin daripada yang lain (jika, misalnya, para pakar yang membuat model tersebut telah membuat model yang jauh lebih akurat sebelumnya), kita dapat memberi bobot pada model-model ini, misalnya melalui transparansi lintasan, seperti yang kita lakukan di bawah ini. Perhatikan bahwa memberi bobot pada model-model ini adalah tugas bagi seorang pakar dan bagian penting dari proses pemodelan agregat ini.
Apa yang dilakukan di atas adalah menyelesaikan tugas yang diperlukan oleh dua properti pertama yang kita inginkan dari visualisasi kita. Untuk mencapai yang ke-3, yaitu pembaca dapat membaca bahwa, katakanlah 30-40% kemungkinan pusat badai melewati lokasi tertentu, ada dua solusi:
- mengubah peta panas sehingga bergerak di antara, katakanlah, merah dan biru dan menyertakan kunci yang mengatakan, misalnya, merah berarti probabilitas lebih besar dari 90%;
- Mengubah peta panas menjadi peta kontur yang menunjukkan wilayah di mana probabilitas mengambil nilai tertentu.
Perhatikan juga bahwa ini akan memberi tahu seseorang probabilitas bahwa lokasi tertentu akan terkena pusat badai. Anda dapat menggabungkan (atau mengonvolusi) ini dengan informasi tentang ukuran badai untuk mengubah peta panas menjadi peta probabilitas lokasi terkena angin berkekuatan badai. Jika Anda ingin melakukan ini, silakan utak-atik kode yang saya tulis untuk menghasilkan plot di atas (saya berencana menulis postingan tindak lanjut yang melakukan ini dan menelusuri kodenya).
Memvisualisasikan Ketidakpastian dan Jurnalisme Data
Apa yang bisa kita ambil dari ini? Kita telah mengeksplorasi beberapa jenis metode visualisasi untuk jalur prediksi badai, mendiskusikan pro dan kontra masing-masing, serta menyarankan jalan ke depan untuk plot jalur tersebut yang lebih informatif dan tidak menyesatkan, plot yang mengomunikasikan tidak hanya hasil tetapi juga ketidakpastian di sekitar model.
Ini adalah bagian dari percakapan yang lebih luas yang perlu kita lakukan tentang melaporkan ketidakpastian dalam visualisasi dan jurnalisme data, secara umum. Kita perlu berpartisipasi aktif dalam percakapan tentang bagaimana pakar melaporkan ketidakpastian kepada warga melalui media berita. Berikut adalah artikel hebat dari The Upshot yang menunjukkan seperti apa laporan pekerjaan jika dilihat karena derau statistik, bahkan jika pekerjaan stabil. Berikut adalah artikel Upshot lainnya yang menunjukkan peran derau dan ketidakpastian dalam menafsirkan jajak pendapat. Saya sangat sadar bahwa kita membutuhkan berita utama untuk menjual berita dan peran click-bait dalam lanskap media berita modern, tetapi kita perlu mengomunikasikan tidak hanya hasil, tetapi ketidakpastian di sekitar hasil tersebut agar tidak menyesatkan masyarakat umum dan mungkin diri kita sendiri. Mungkin yang lebih penting, sistem pendidikan perlu bergeser dan membekali semua warga dengan tingkat literasi data dan literasi statistik untuk menghadapi pergerakan ke era berbasis data ini. Kita semua dapat berkontribusi untuk ini.