
Program
SQL Server untuk Administrator Database
24 Hr
Bersiap untuk wawancara DBMS? Anda berada di tempat yang tepat.
Anda memahami basis data dari pekerjaan sehari-hari, tetapi wawancara menguji Anda secara berbeda dibanding skenario dunia nyata. Pewawancara tidak hanya ingin melihat apakah Anda bisa menulis kueri SQL - mereka akan menguji pemahaman Anda tentang normalisasi, properti ACID, dan bagaimana Anda menangani masalah kinerja basis data di bawah tekanan. Banyak profesional basis data tersandung karena tidak bisa menjelaskan konsep yang mereka gunakan setiap hari atau kesulitan dengan pertanyaan perilaku yang menguji cara mereka bekerja dengan tim data.
Panduan ini mencakup pertanyaan wawancara DBMS yang paling sering ditanyakan di semua tingkat kesulitan. Anda juga akan mendapatkan strategi yang terbukti untuk menaklukkan pertanyaan berbasis skenario dan tips agar menonjol dari kandidat lain.
Mari mulai dengan pertanyaan fondasi yang ada di setiap awal wawancara DBMS.
>Ingin fokus hanya pada bagian pengkodean wawanwara? Berikut 85 pertanyaan dan jawaban wawancara SQL untuk 2026.
Harapkan pertanyaan ini di awal wawancara teknis. Pertanyaan ini menguji pemahaman dasar Anda tentang sistem manajemen basis data.
Pewawancara menggunakan pertanyaan ini untuk melihat apakah Anda memahami konsep inti basis data sebelum beralih ke skenario kompleks. Mereka mencari penjelasan yang jelas dan contoh praktis yang menunjukkan bahwa Anda pernah bekerja dengan basis data, bukan sekadar menghafal definisi.
Sebuah DBMS adalah perangkat lunak yang mengelola basis data - menangani penyimpanan, pengambilan, dan pengorganisasian data sambil memastikan keamanan dan konsistensi.
Anggap saja sebagai perantara antara aplikasi Anda dan berkas data sebenarnya. Contoh populer termasuk MySQL, PostgreSQL, Oracle, dan SQL Server. DBMS menangani tugas seperti autentikasi pengguna, pencadangan data, dan memastikan banyak pengguna dapat mengakses data tanpa merusaknya.
Sebuah database adalah kumpulan data itu sendiri, sedangkan DBMS adalah perangkat lunak yang mengelola data tersebut.
Database berisi tabel, record, dan relasi Anda. DBMS menyediakan alat dan antarmuka untuk berinteraksi dengan data tersebut. Ini seperti perbedaan antara perpustakaan (database) dan sistem pustakawan (DBMS) yang membantu Anda menemukan dan meminjam buku.
Prinsip ACID memastikan transaksi basis data andal dan mempertahankan integritas data:
Contoh sehari-hari: Saat Anda mentransfer uang antar rekening, debit dan kredit harus terjadi bersama (atomicity), aturan saldo total tetap valid (consistency), transaksi lain tidak melihat keadaan parsial (isolation), dan perubahan tetap ada meski sistem crash (durability).
Key basis data digunakan untuk mengidentifikasi record secara unik dan membangun relasi. Berikut jenis-jenis yang perlu Anda ketahui:
Contoh sederhana:
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
department_id INT,
email VARCHAR(100) UNIQUE,
FOREIGN KEY (department_id) REFERENCES departments(id)
);Normalisasi menghilangkan redundansi data dengan mengorganisasi data ke dalam tabel-tabel terpisah yang saling berelasi.
Ini mencegah inkonsistensi data dan menghemat ruang penyimpanan. Berikut cara kerja bentuk normal utama:
First Normal Form (1NF): Setiap kolom berisi nilai atomik (tidak dapat dibagi) - tidak ada daftar atau banyak nilai dalam satu sel.
Contoh buruk:

Gambar 1 - Contoh buruk 1NF
Contoh baik:
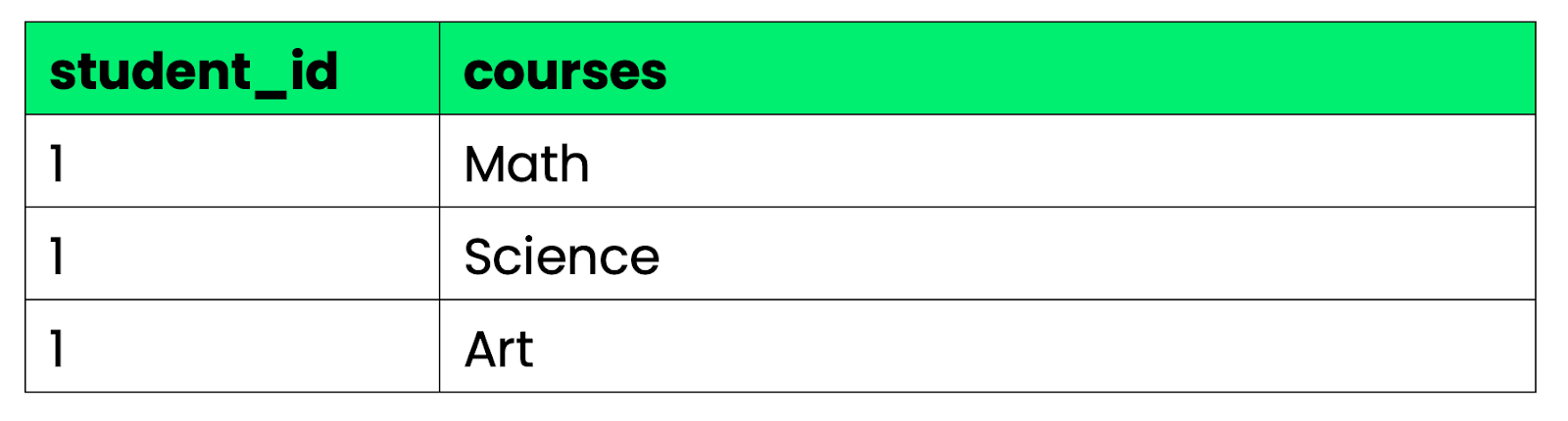
Gambar 2 - Contoh baik 1NF
Second Normal Form (2NF): Harus memenuhi 1NF dan menghapus ketergantungan parsial—kolom non-key harus bergantung pada seluruh primary key, bukan hanya sebagian.
Ini berlaku saat Anda memiliki primary key komposit. Jika Anda memiliki tabel dengan (student_id, course_id) sebagai primary key, maka student_name tidak boleh ada di tabel ini karena hanya bergantung pada student_id, bukan pada keduanya.
Third Normal Form (3NF): Harus memenuhi 2NF dan menghapus ketergantungan transitif. Kolom non-key tidak boleh bergantung pada kolom non-key lainnya.
Contoh buruk:

Gambar 3 - Contoh buruk 3NF
Di sini, advisor_office bergantung pada advisor_id, bukan langsung pada student_id. Pisahkan ke tabel terpisah.
Tanpa normalisasi, Anda akan menyimpan info pelanggan di setiap pesanan, yang membuang ruang dan menimbulkan masalah pembaruan saat detail pelanggan berubah.
Perintah ini menghapus data dengan cara berbeda:
DELETE FROM employees WHERE department_id = 5;TRUNCATE TABLE employees;DROP TABLE employees;INNER JOIN hanya mengembalikan record yang cocok dari kedua tabel:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.id;OUTER JOIN menyertakan record yang tidak cocok:
>Join SQL adalah topik yang kompleks pada dirinya sendiri - Berikut 20 pertanyaan wawancara khusus tentang join
Sebuah indeks adalah struktur data yang mempercepat pengambilan data dengan membuat jalan pintas ke baris-baris tabel.
Anggap seperti indeks buku - alih-alih membaca setiap halaman untuk menemukan topik, Anda mencarinya dan langsung lompat ke halaman yang tepat. Indeks membuat kueri SELECT lebih cepat, tetapi memperlambat operasi INSERT, UPDATE, dan DELETE karena indeks harus diperbarui.
CREATE INDEX idx_employee_email ON employees(email);Sebuah view adalah tabel virtual yang dibuat dari kueri SQL dan tidak menyimpan data itu sendiri.
View menyederhanakan kueri kompleks, memberikan keamanan dengan menyembunyikan kolom sensitif, dan menyajikan data dalam format berbeda. Saat Anda mengkueri view, basis data mengeksekusi SQL dasarnya dan mengembalikan hasil seperti seolah-olah itu tabel nyata.
CREATE VIEW active_employees AS
SELECT employee_id, name, email
FROM employees
WHERE status = 'active';
SELECT * FROM active_employees;Stored procedure adalah kode SQL yang sudah dikompilasi sebelumnya yang disimpan di basis data dan dapat dijalankan berdasarkan nama.
Mereka meningkatkan performa karena sudah dikompilasi, mengurangi lalu lintas jaringan dengan mengeksekusi banyak pernyataan dalam satu panggilan, dan memberikan keamanan lebih baik melalui kueri berparameter. Mereka juga memusatkan logika bisnis di basis data.
CREATE PROCEDURE GetEmployeesByDepartment(IN dept_id INT)
BEGIN
SELECT * FROM employees WHERE department_id = dept_id;
END;>SQL prosedural bisa menjadi topik wawancara utama, tergantung pada peran. Ini 20 pertanyaan wawancara yang berfokus pada Oracle PL/SQL
Setelah ini, mari lanjut ke pertanyaan tingkat menengah yang akan menguji pengetahuan Anda.
Pelajari lebih lanjut tentang DBMS dengan kursus-kursus ini!
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
