
Cursus
Exploratory Data Analysis in R
4 Hr
118.1K
Data-analyticsprojecten zijn cruciale opstapjes voor iedereen die wil uitblinken in de huidige datagedreven wereld. Dit is waarom ze essentieel zijn:
Kortom: data-analyticsprojecten scherpen niet alleen je technische skills, maar bereiden je ook voor op de uitdagingen en eisen van de moderne werkplek.
Als beginner focus je op het importeren, opschonen, manipuleren en visualiseren van data.
In het project Exploring the NYC Airbnb Market pas je skills in data-import en -opschoning toe om de Airbnb-markt in New York te analyseren. Je leest en combineert data uit meerdere bestandstypen, en schoont strings op en formatteert datums om nauwkeurige informatie te extraheren.
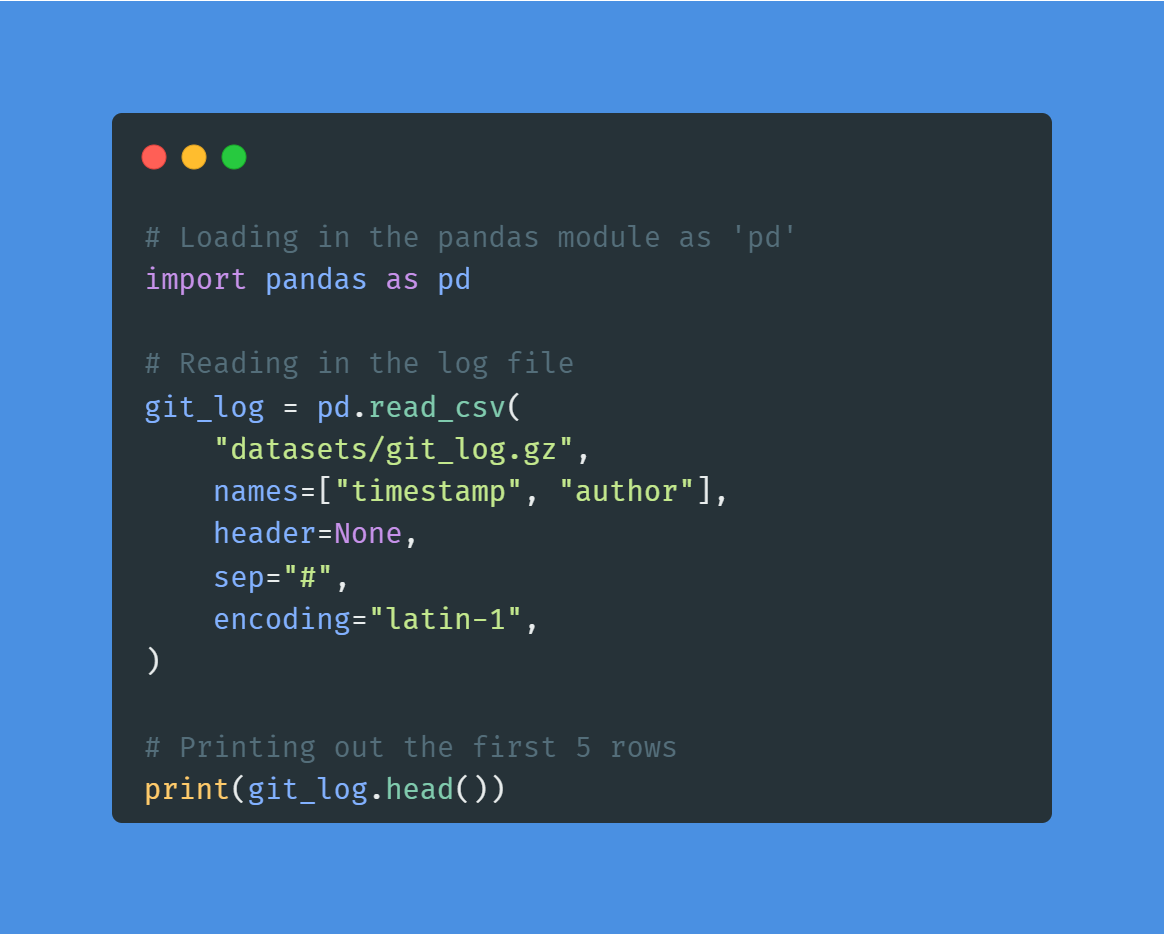
Afbeelding door auteur | Code uit het project
Dit project is perfect voor beginners die ervaring willen opdoen met data importeren en opschonen. Je kunt vergelijkbare methoden toepassen op deze dataset Online Ticket Sales om nog beter te worden in het verwerken van data.
Leer meer over data importeren en opschonen met korte cursussen:
In het project Word Frequency in Classic Novels gebruik je requests en BeautifulSoup om een roman te scrapen van de Project Gutenberg-website. Na het scrapen en opschonen van de tekstdata gebruik je NLP om de meest voorkomende woorden in Moby Dick te vinden. Het project introduceert je in de wereld van Python-webscraping en natural language processing.
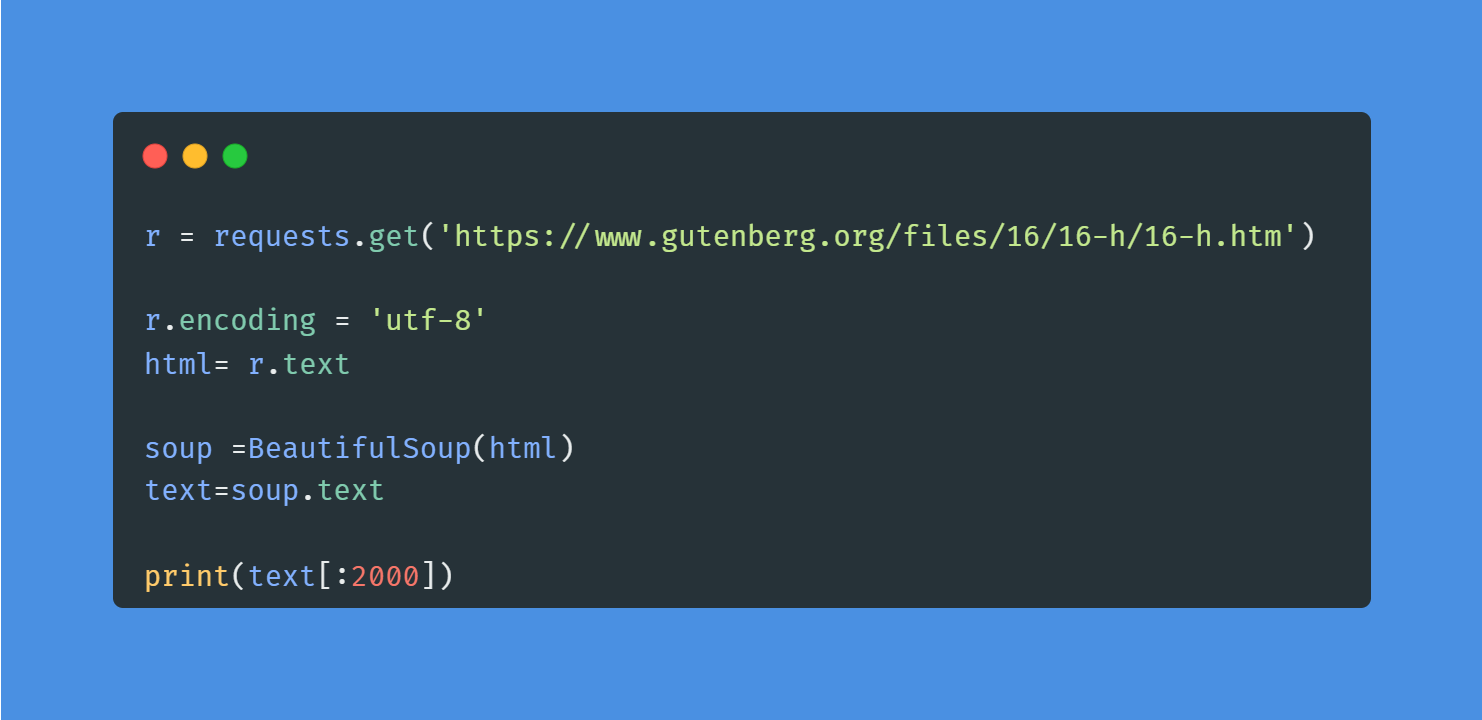
Afbeelding door auteur | Code uit het project
Voor data-analisten en data scientists is webscraping een essentiële skill. Volg de korte cursus Web Scraping with Python om de tools en componenten van een HTML-webpagina te begrijpen.
In het project Exploring NYC Public School Test Result Scores analyseer je gestandaardiseerde SAT-prestaties op openbare scholen in New York City. Je schoont kolommen op en vat ze samen (Wiskunde, Lezen, Schrijven), vergelijkt uitkomsten per borough, rangschikt scholen op wiskundescores en haalt de top-10 van de stad naar boven. Onderweg oefen je kernvaardigheden van een analist: typen corrigeren, ontbrekende waarden verwerken, groepsstatistieken berekenen en ruwe schooldata omzetten in heldere, besluitklare inzichten.
Afbeelding door auteur | Code uit het project
Dit project is ideaal voor beginners die een realistische, businessachtige EDA (exploratory data analysis) willen maken met ranking, benchmarking en geografische segmentatie. Je kunt dezelfde methodologie toepassen op verwante datasets, zoals "Factors that Fuel Student Performance" of open data van je lokale district, om je portfolio te versterken met vergelijkbare en reproduceerbare analyses.
In het project Analyzing Motorcycle Part Sales bevraag je een salesdatabase met meerdere magazijnen om omzetpatronen te ontdekken in de tijd, per productlijn en per locatie. Je berekent nettoumslag (rekening houdend met kortingen/retouren waar van toepassing), segmenteert per magazijn en datum, rangschikt best presterende productcategorieën en bouwt vergelijkende doorsneden om groei versus krimp te belichten.
Reken op veel praktische SQL: joins, datumtruncatie, conditionele aggregatie en windowfuncties om ruwe transacties om te zetten in heldere, direct bruikbare rapporten.
Afbeelding door auteur | Code uit het project
Dit project is perfect voor analisten die zakelijke SQL-ervaring willen die echt werk weerspiegelt: KPI-definities, omzetrollups, benchmarking van magazijnen en tijdgebaseerde performance-tracking die je zo in een dashboard of wekelijkse operations-update kunt stoppen.
In het project Exploring the Bitcoin Cryptocurrency Market verken je data over Bitcoin en andere cryptovaluta. Je schoont de dataset op door cryptovaluta zonder marktkapitalisatie te verwijderen, vergelijkt Bitcoin met andere munten en bereidt data voor op visualisatie.
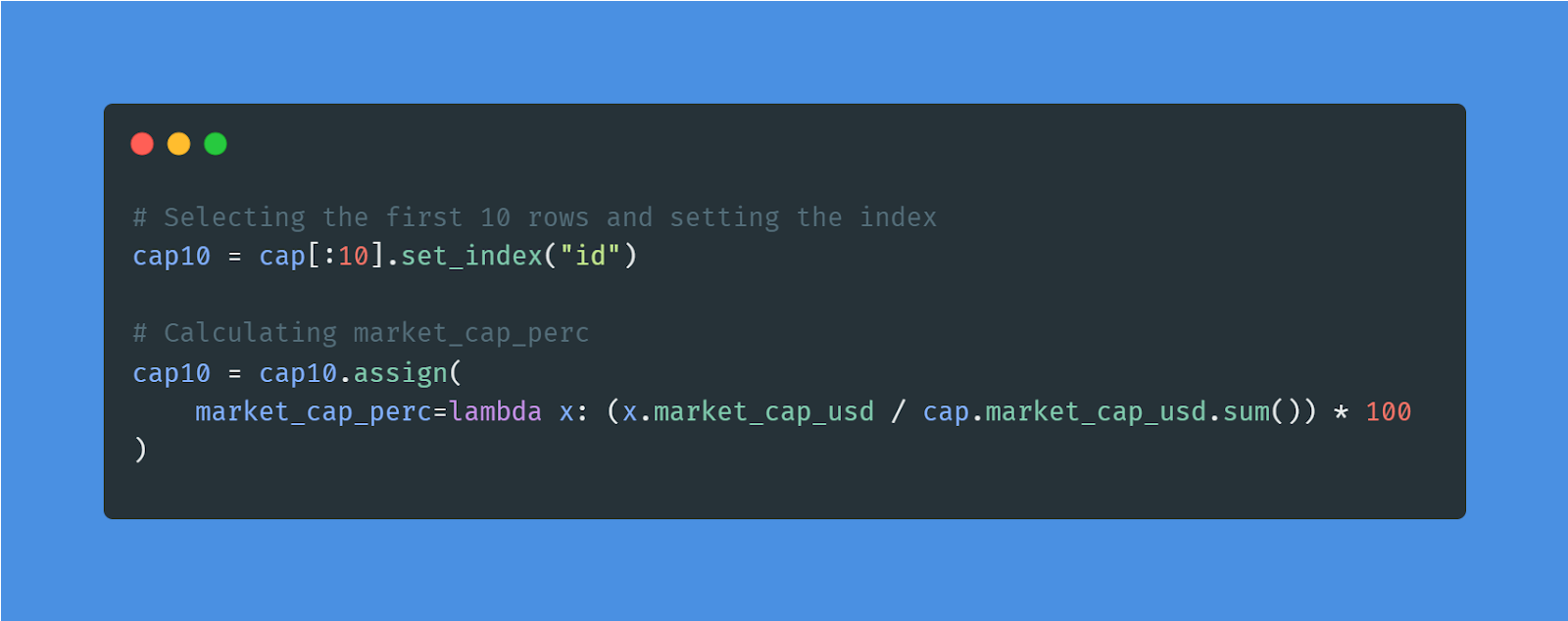 Afbeelding door auteur | Code uit het project
Afbeelding door auteur | Code uit het project
Je kunt vergelijkbare methoden toepassen op beursdata en leren hoe je data manipuleert voor data-analyse. Daarnaast kun je datatransformatie, aggregatie, slicing en indexering leren in de cursus Data Manipulation with pandas.
In het project Visualizing the History of Nobel Prize Winners bekijk je meer dan een eeuw aan Nobelprijs-geschiedenis. Met Python analyseer en visualiseer je data om patronen en mogelijke biases te ontdekken in hoe prestigieuze onderscheidingen worden toegekend in categorieën als natuurkunde, scheikunde, literatuur en vrede.
Je past datamanipulatietechnieken met pandas toe en maakt overtuigende visualisaties met Seaborn om een verhaal met de data te vertellen. Dit project is perfect om je analyse- en visualisatieskills te verbeteren terwijl je een van ’s werelds bekendste onderscheidingen verkent.
In het project Exploring Stock Market Trends with Plotly zet je ruwe prijsdata van fastfoodgiganten (bijv. McDonald’s, Starbucks) om in interactieve grafieken die sector-momentum en patronen blootleggen. Je bouwt candlestick- en lijngrafieken, voegt voortschrijdende gemiddelden en rolling-statistieken toe, vergelijkt meerdere tickers en annoteert belangrijke gebeurtenissen, met focus op visueel storytelling die volatiliteit, seizoenspatronen en relatieve prestaties uitlicht.

Dit is een visualisatie-first project, perfect als je een strak, portfoliowaardig dashboard wilt dat marktinzicht toont via interactiviteit (hover, zoom, range-sliders) in plaats van zware modellering.
In het project Visualizing COVID-19 visualiseer je COVID-19-data met de populairste R-bibliotheek ggplot. Je analyseert bevestigde gevallen wereldwijd, vergelijkt China met andere landen, leert grafieken annoteren en voegt een logaritmische schaal toe. Het project leert je skills die sterk in trek zijn bij R-programmeurs.
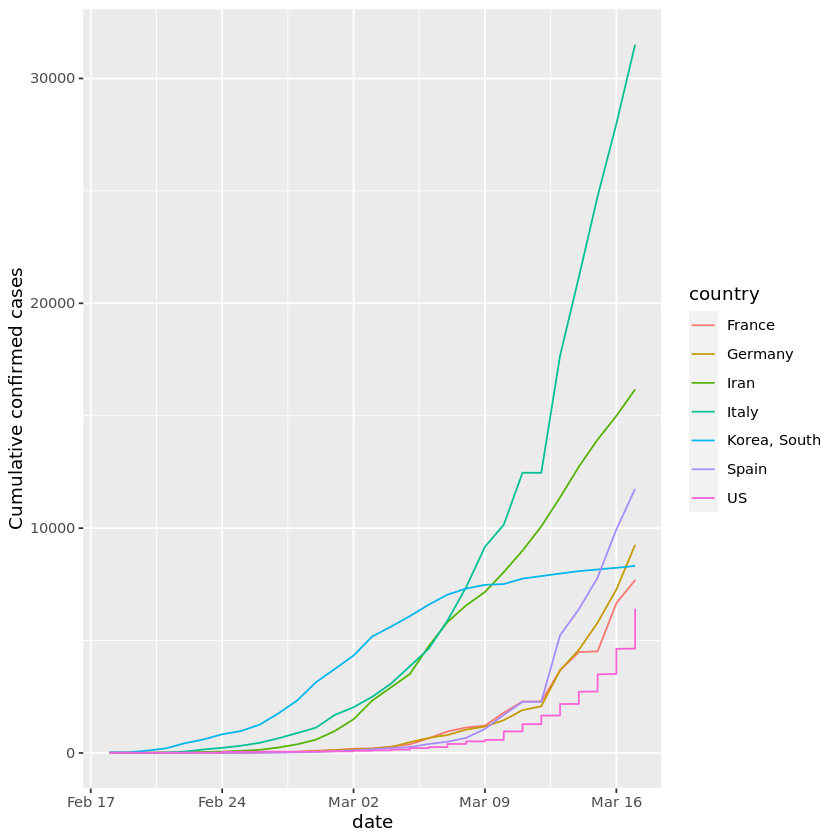
Afbeelding uit het project
Je kunt ggplot-methoden toepassen op mazelendata en meer ervaring opdoen met visualisatie en analyse. Bovendien kun je de cursus Intermediate Data Visualization with the ggplot2 volgen om best practices te leren.
In het Analyzing Super Bowl Viewership and Advertising-project verken je het drama achter de Super Bowl—van de wedstrijden en advertenties tot de halftime shows. Met R manipuleer en visualiseer je data om te ontdekken hoe deze elementen elkaar beïnvloeden. Perfect om je analysekills op te bouwen met tools als ggplot2 en dplyr.
Code gebruiken om interactieve visualisaties weer te geven is makkelijk, maar data begrijpen en interpreteren is lastig. Volg de cursus Understanding Data Visualization om visualisaties en verdelingen te kunnen duiden en de beste technieken te leren om complexe data te communiceren.
Voor meer geavanceerde projecten heb je grip nodig op wiskunde, kansrekening en statistiek. Daarnaast voer je exploratieve data- en voorspellende analyses uit om de data diepgaander te begrijpen.
In het project Modeling Car Insurance Claim Outcomes gebruik je Python en logistische regressie om verzekeringsclaims te voorspellen. Met data van On the Road car insurance identificeer je sleutelkenmerken die tot de meest nauwkeurige voorspellingen leiden. Dit project helpt je ML-technieken toe te passen op echte businessproblemen in de verzekeringssector.
In het project Hypothesis Testing with Men's and Women's Soccer Matches analyseer je historische voetbaldata om te testen of vrouweninterlands meer doelpunten opleveren dan manneninterlands. Met Python scherpk je je statistische testskills aan en ontdek je patronen in wereldwijde voetbaltrends.
Als je de meest gangbare statistische technieken, kansrekening, dataverdelingen, correlatie en experimenteel ontwerp wilt leren, volg dan de cursus Introduction to Statistics in Python.
In het project Analyze International Debt Statistics schrijf je SQL-queries om internationale schulden te verkennen en te analyseren met de dataset van de Wereldbank. SQL is het populairste en essentieelste hulpmiddel voor snelle data-analyse.
In het project ga je het volgende vinden:
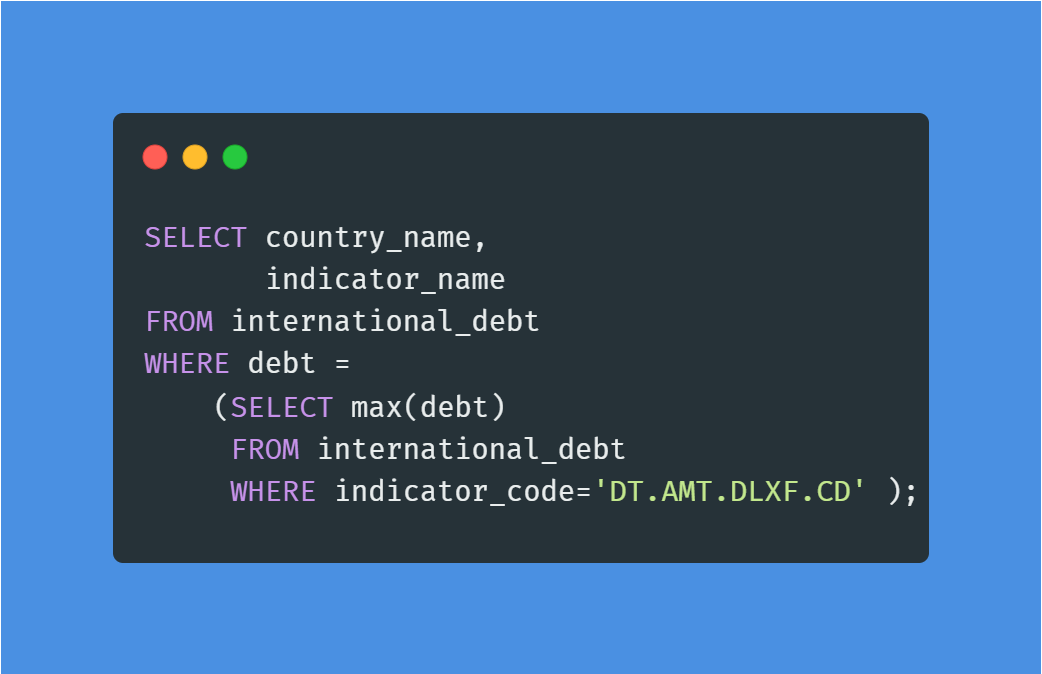
Afbeelding door auteur | Code uit het project
Je koppelt de World Nations-MariaDB-dataset en past vergelijkbare queries toe om extra ervaring op te doen met het beheren en analyseren van SQL-databases. Daarnaast kun je de cursus Exploratory Data Analysis in SQL volgen om technieken en queries voor diverse SQL-databases te verdiepen.
In het project Analyzing Crime in Los Angeles treed je op als datadetective voor de LAPD: je schoont en segmenteert incidentdata om te leren wanneer en waar criminaliteit het meest waarschijnlijk is en welke delicttypen domineren. Je segmenteert op tijdstip, weekdag, buurt en categorie; berekent hotspotsamenvattingen; en bouwt vergelijkingen die direct vertalen naar inzichten voor resource-allocatie.
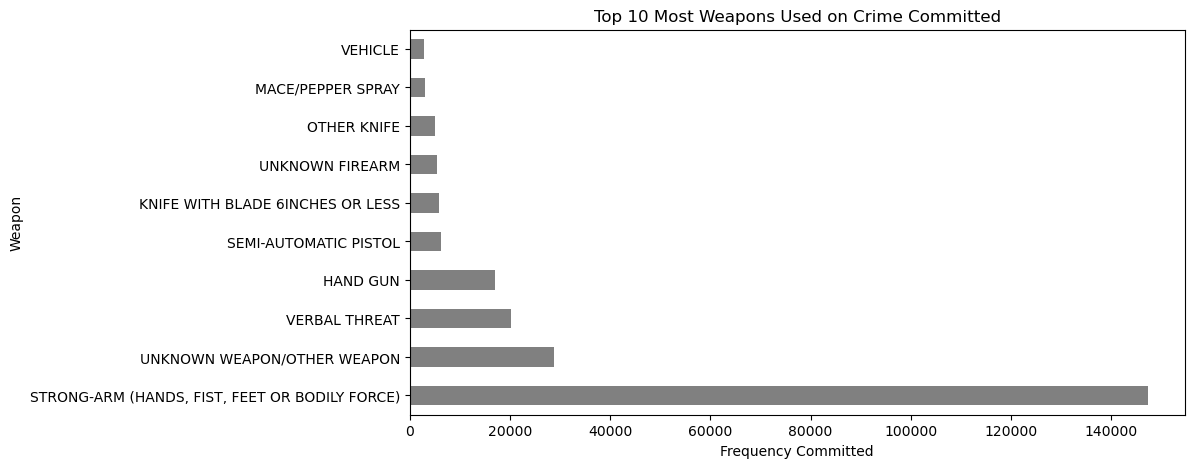
Afbeelding uit het project
Je oefent: data-opschoning, groeperen & aggregeren, tijdgebaseerde buckets, ratenormalisatie (per hoofd of per tijdvenster), top-N-buurten/delicten rangschikken en interpreteerbare tabellen/grafieken bouwen voor besluitvorming.
In het project Investigating Netflix Movies and Guest Stars in The Office gebruik je datamanipulatie en visualisatie om een realistisch datascienceprobleem op te lossen. Je voert diepgaande EDA uit en trekt conclusies uit gedetailleerde grafieken.
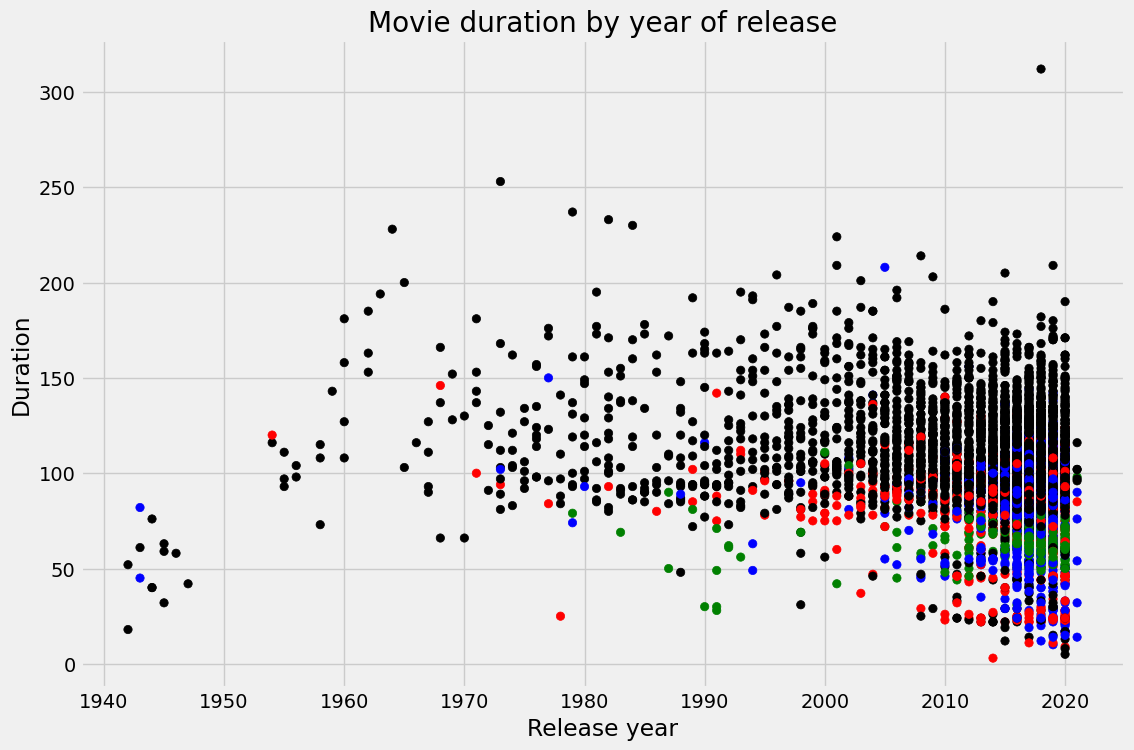
Afbeelding uit het project
Je kunt aan een portfolioproject werken door vergelijkbare skills toe te passen op een nieuwe dataset: Netflix Movie Data. Daarnaast kun je de cursus Exploratory Data Analysis in Python volgen om meer te leren over opschonen en valideren, relaties en verdelingen begrijpen en multivariate relaties verkennen.
In het project Predict Future Sales of Fast-Food Menu Items help je een fastfoodketen overbestedingen en spoedbestellingen te verminderen door een verkoopvoorspellingsmodel te bouwen voor topmenu-items. Je kadert het businessprobleem, ontwikkelt kalender-/promotiekenmerken, maakt tijdsbewuste splits, past en vergelijkt regressiemodellen in R en kwantificeert impact met RMSE/MAE—je zet historische POS-data om in nauwkeurigere en kosteneffectieve bestelplannen.
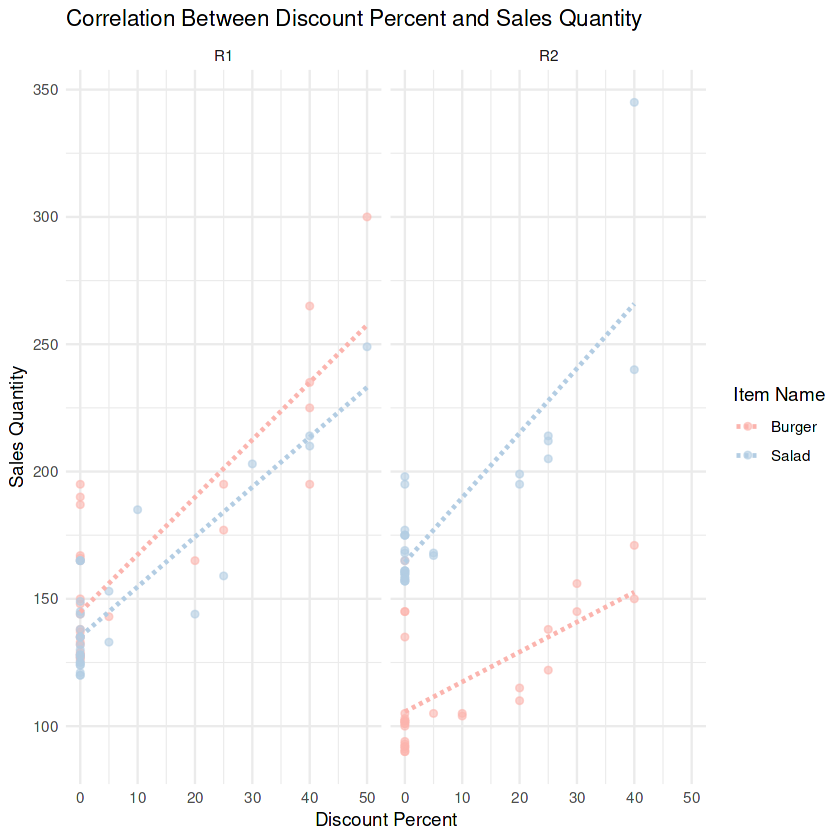
Afbeelding uit project
Je oefent feature engineering (weekdag, feestdagen, promoties), lekvrije train/test-splits, baseline versus getunede modellen, cross-validatie, RMSE/MAE-rapportage, eenvoudige backtesting en het vertalen van modelresultaten naar besteladviezen.
In het project Will This Customer Purchase Your Product? analyseer je winkelgedrag van klanten met statistiek en kansrekening. Met Python ontdek je verschillen tussen nieuwe en terugkerende klanten, zodat marketingteams betrokkenheid op e-commerceplatforms beter begrijpen.
In het project Predicting Credit Card Approvals bouw je het best presterende machinelearningmodel voor het voorspellen van kredietkaartaanvragen.
Eerst begrijp je de data en vul je ontbrekende waarden aan. Daarna bereid je de data voor en train je een logistisch regressiemodel op de trainingsset. Tot slot evalueer je de resultaten en verbeter je de modelprestatie met grid search.
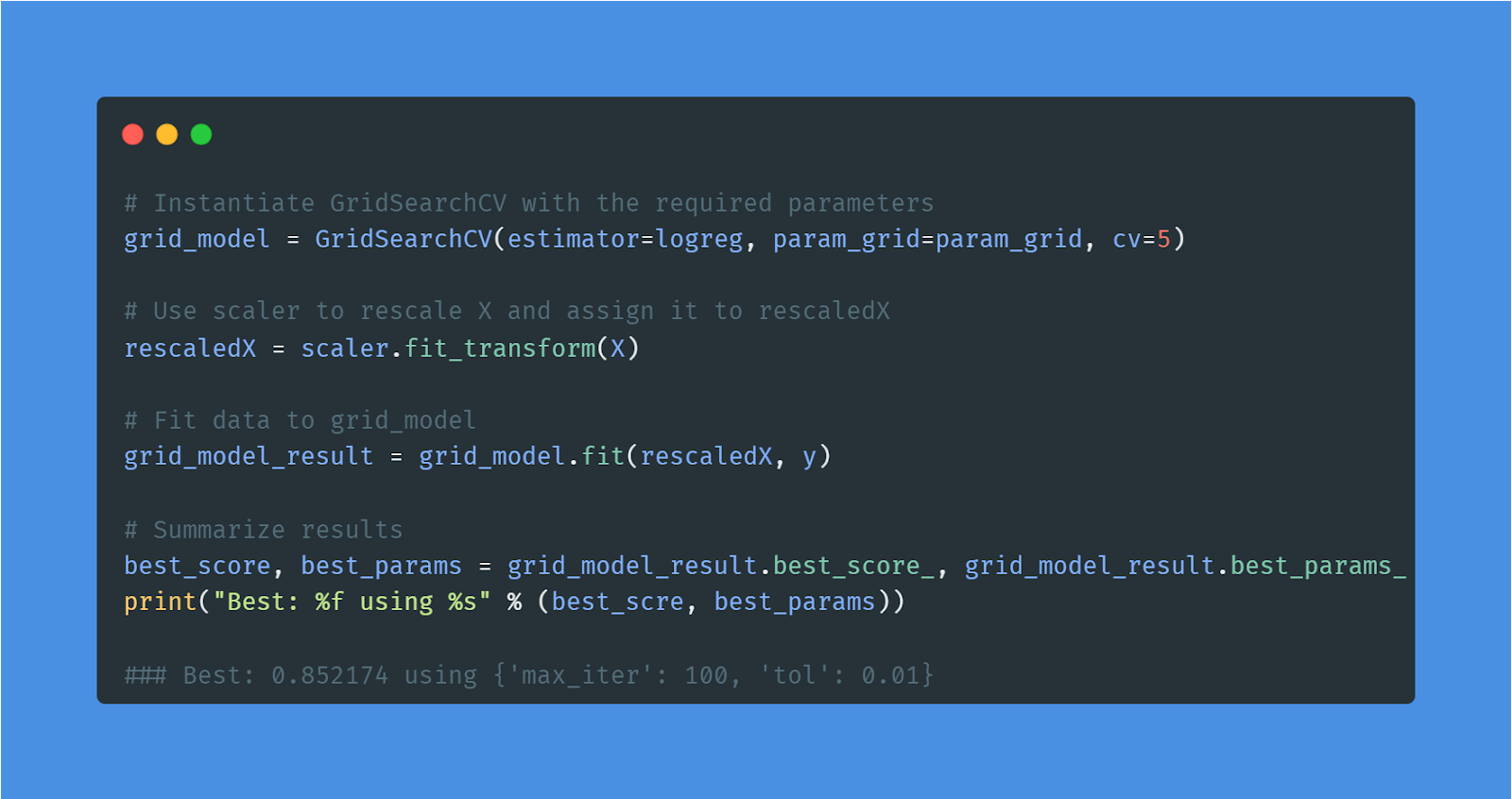
Afbeelding door auteur | Code uit het project
Het toepassen van eenvoudige ML-algoritmen is een essentieel onderdeel van het werk van een data-analist. Je kunt meer ervaring opdoen door vergelijkbare methoden toe te passen op een nieuwe dataset: Bank Marketing.
Leer meer over classificatie, regressie, finetuning en preprocessing met de korte cursus Supervised Learning with the scikit-learn.
Afstudeerprojecten zijn meestal onderzoeksgedreven en vergen minstens 2–3 maanden om te voltooien. Je werkt aan een specifiek onderwerp en probeert de resultaten te verbeteren met diverse statistische en probabilistische technieken.
Let op: er is een groeiende trend richting machinelearningprojecten voor data-analyticsafstudeerprojecten.
In het project Exploring London’s Travel Network bevraag je een warehouse (Snowflake/Redshift/BigQuery/Databricks) met 12 jaar aan TfL-reizen (2010–2022) om te begrijpen hoe Londenaren zich verplaatsen. Je rangschikt de populairste vervoerswijzen, prikt periodes waarin de kabelbaan ongewoon druk was en identificeert zeldzame momenten waarop de metro rustiger was dan normaal—je zet ruwe reizen om in operationele inzichten voor dienstregeling en capaciteitsplanning.
Afbeelding uit het project
Je oefent time bucketing (maand/jaar), window- en aggregatiefuncties, conditionele aggregatie per modus/lijn, anomalieën spotten (ongewoon druk of rustig), seizoensinvloeden checken (events/feestdagen) en nette KPI-tabellen bouwen voor vervoeroperations.
Voor het project Reducing Traffic Mortality in the USA bedenk je een goede strategie om verkeersdoden in de VS te verminderen. Je importeert, schoont, manipuleert en visualiseert de data. Daarnaast voer je feature engineering uit en pas je diverse ML-modellen toe (multivariate lineaire regressie, KMeans-clustering) om per staat te adviseren en de resultaten te communiceren.
Afbeelding uit het project
Wil je meer leren over unsupervised learning? Bekijk de cursus Cluster Analysis in Python.
In het project Assessing the Effectiveness of Medical Treatments verken je de fascinerende casus van de paradox van Simpson in een studie naar niersteenbehandelingen. Met R pas je regressianalyse toe om verborgen inzichten bloot te leggen en beter te begrijpen hoe uitkomsten per patiëntgroep verschillen.
In het project Building a Demand Forecasting Model voorspel je de vraag naar e-commerceproducten met PySpark en beantwoord je echte supplychainvragen zoals voorraadplanning en aanvulfrequentie. Je ontwikkelt temporele features (weekdag, seizoenspatronen, feestdagen), maakt tijdsbewuste validatiesplits, traint en vergelijkt forecasting-benchmarks met ML-modellen op schaal en voert rolling backtests uit om stabiliteit te kwantificeren—je zet bestelgeschiedenis om in actiegerichte inkoopplannen.
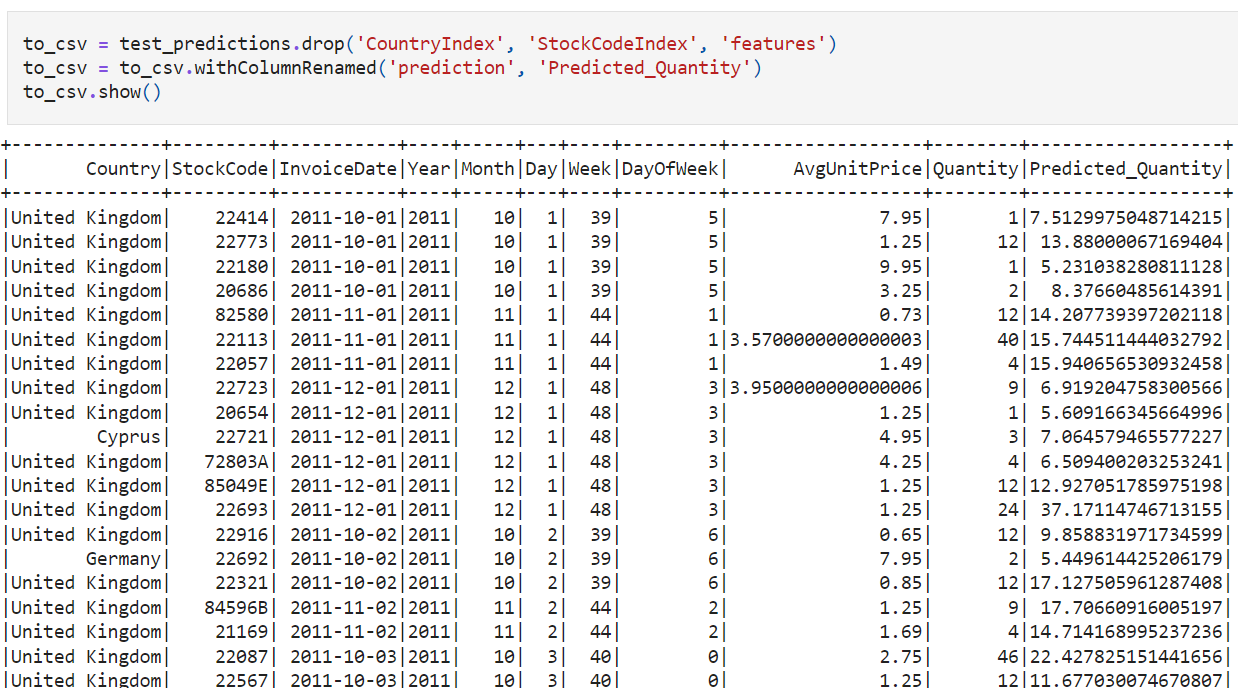
Afbeelding uit het project
Je oefent grootschalige feature engineering, Spark-joins/windowoperaties, lekvrije validatie, baseline versus getunede modellen, RMSE/MAE-foutenanalyse, rolling/blocked backtests en scenarioanalyse, inclusief promoties en seizoensinvloeden.
In het project Social Networks: A Twitter Network Analysis analyseer je volgersdata met pandas en NetworkX om influencers, bruggen en communitystructuren te ontdekken. Je bouwt herbruikbare functies voor het laden/opschonen van edge-lijsten, construeert grafen, berekent centraliteitsmaten (degree, betweenness, eigenvector), detecteert communities, inspecteert ego-nets en visualiseert netwerktopologie—je zet ruwe connecties om in heldere, actiegerichte inzichten.
Je oefent grafconstructie uit volgersdata, data-opschoning met Pandas, centraliteit en communitydetectie, invloedrijke accounts rangschikken, ego-netverkenning en leesbare netwerkvisualisaties met duidelijke takeaways maken.
Het project World Population Analysis is het beste voorbeeld van diepgaande exploratieve analyse. Je verkent verschillende kolommen, visualiseert de minst en meest bevolkte landen en onderzoekt bevolkingsdichtheid en groeipercentage. Daarnaast toon je de landenrangverdeling en een correlatiekaart.
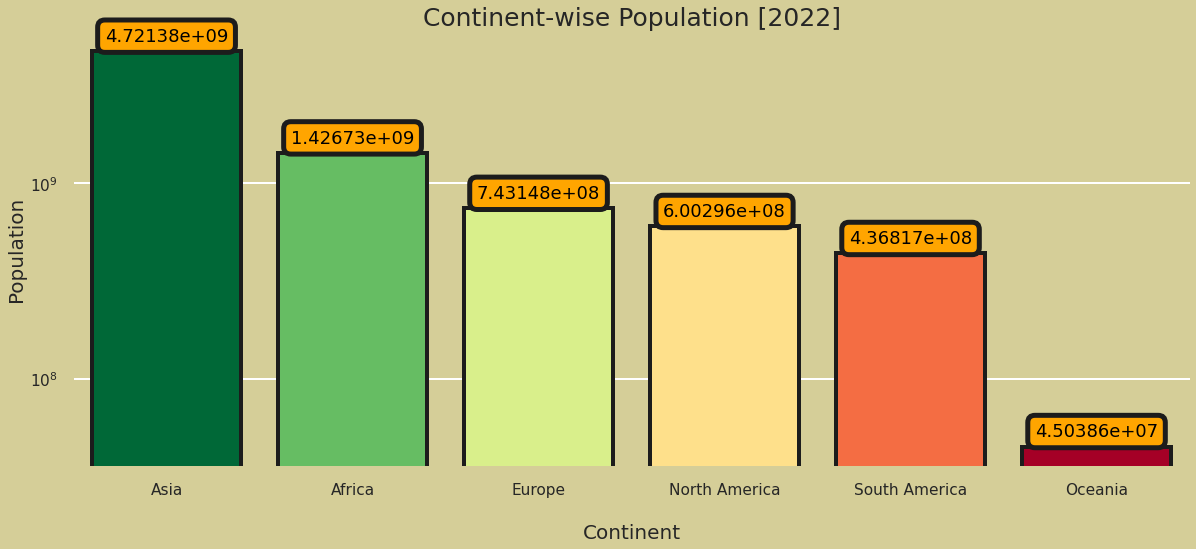
Afbeelding uit het project
Leer eenvoudige manieren om datavisualisaties in Python te maken met de cursus Intermediate Data Visualization with Seaborn.
Het project Data Science and MLOps Landscape in Industry is een heilige graal voor alle datamanipulatie, visualisaties en exploratieve en geospatiale analyse. Je leert effectief gebruikmaken van boxplots, donutdiagrammen, staafdiagrammen, heatmaps, parallelle categorische grafieken, bubbeldiagrammen, trechters, radardiagrammen, icicle-diagrammen en kaarten. Daarnaast leer je verschillende grafiektypes interpreteren.
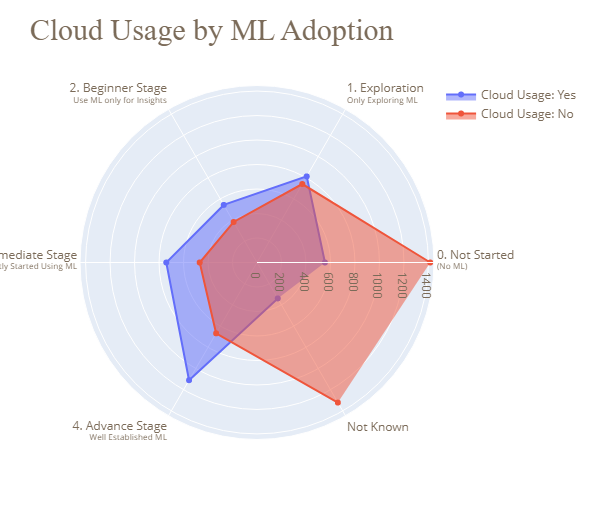
Afbeelding uit het project
Volg de cursus Introduction to Data Visualization with Plotly in Python om geavanceerde Plotly-features en -aanpassingen te leren.
In 2026 combineren de meest gewilde analisten traditionele analytics met AI-tools. Bedrijven willen professionals die met ongestructureerde data kunnen werken, realtime pipelines kunnen bouwen en inzichten in gewone taal kunnen uitleggen. Deze twee projecten spelen daar rechtstreeks op in.
In het project Sentiment Analysis Complete Project gebruik je Python en NLP om duizenden ongestructureerde tekstsamples uit een echte dataset voor te bewerken, tokenization en stopwoordverwijdering uit te voeren en vervolgens ML-modellen toe te passen voor sentimentclassificatie en -scoring. Deze end-to-end workflow zet rommelige tekstdata om in heldere positief/negatief-voorspellingen met nauwkeurigheidsstatistieken, modelevaluatie en visualisaties.
Het toont praktische skills in tekstvoorbewerking en -classificatie en is ideaal voor data-analistportfolio’s gericht op klantinzichten of socialmediamonitoring.
Verdiep je NLP-skills met de cursus Introduction to Natural Language Processing in Python.
In het project Store Sales Time-Series Forecasting pak je een echte Kaggle-competitie aan met data van een Ecuadoraanse supermarktketen over 50+ winkels en 30 productfamilies. Pas Facebooks Prophet-bibliotheek toe om verkoop te voorspellen, rekening houdend met olieprijzen, feestdagen, promoties en multiseriële seizoensinvloeden
Het project behandelt feature engineering, cross-validatie en ensemblemodellen die Prophet en LightGBM combineren voor nauwkeurigheid op productieniveau.
End-to-endprojecten zijn uitstekend voor je cv en je begrip van de levenscyclus van een data-analyticsproject.
In het algemeen ga je:
In het project Analyzing Unicorn Companies gebruik je SQL om unicorn-bedrijven met een waarde van meer dan $1 miljard te verkennen. Je analyseert welke sectoren de hoogste waarderingen hebben en identificeert opkomende trends, zoals de jaarlijkse groei van nieuwe unicorns tussen 2019 en 2021.
In het project Monitoring a Financial Fraud Detection Model neem je de rol aan van post-deployment data scientist voor een grote Britse bank. Met Python monitor je de performance van een fraudedetectiemodel en onderzoek je waarom het mogelijk niet werkt zoals verwacht, om de financiën van klanten te beschermen.
In het project Time Series Analysis and Forecasting duik je diep in trendanalyse, pas je het ARIMA-model toe voor forecasting, vergelijk je de resultaten en visualiseer je deze om de verkoop van zowel meubels als kantoormaterialen te begrijpen.
Tijdreeksanalyse- en forecastprojecten zijn zeer in trek in de financiële sector en helpen je aan een goedbetaalde baan. Het enige wat je moet doen, is verschillende trends interpreteren en de cijfers nauwkeurig voorspellen.
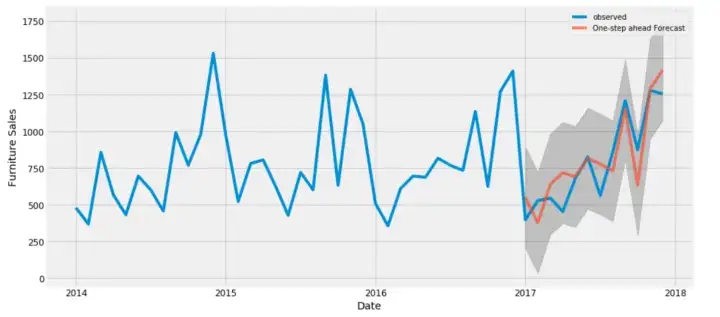
Afbeelding uit het project
Als je moeite hebt met analyseren en voorspellen, rond dan de cursus ARIMA Models in Python af om te leren over ARMA-modellen, de toekomst fitten, de beste modellen selecteren en seizoensgebonden ARIMA-modellen trainen.
Het doel van het project Build a multi-objective recommender system is om e-commercekliks, winkelwagen- toevoegingen en bestellingen te voorspellen. Kort gezegd bouw je een multi-objective aanbevelingssysteem op basis van eerdere gebeurtenissen in een gebruikerssessie.
Na afronding van het project beheers je:
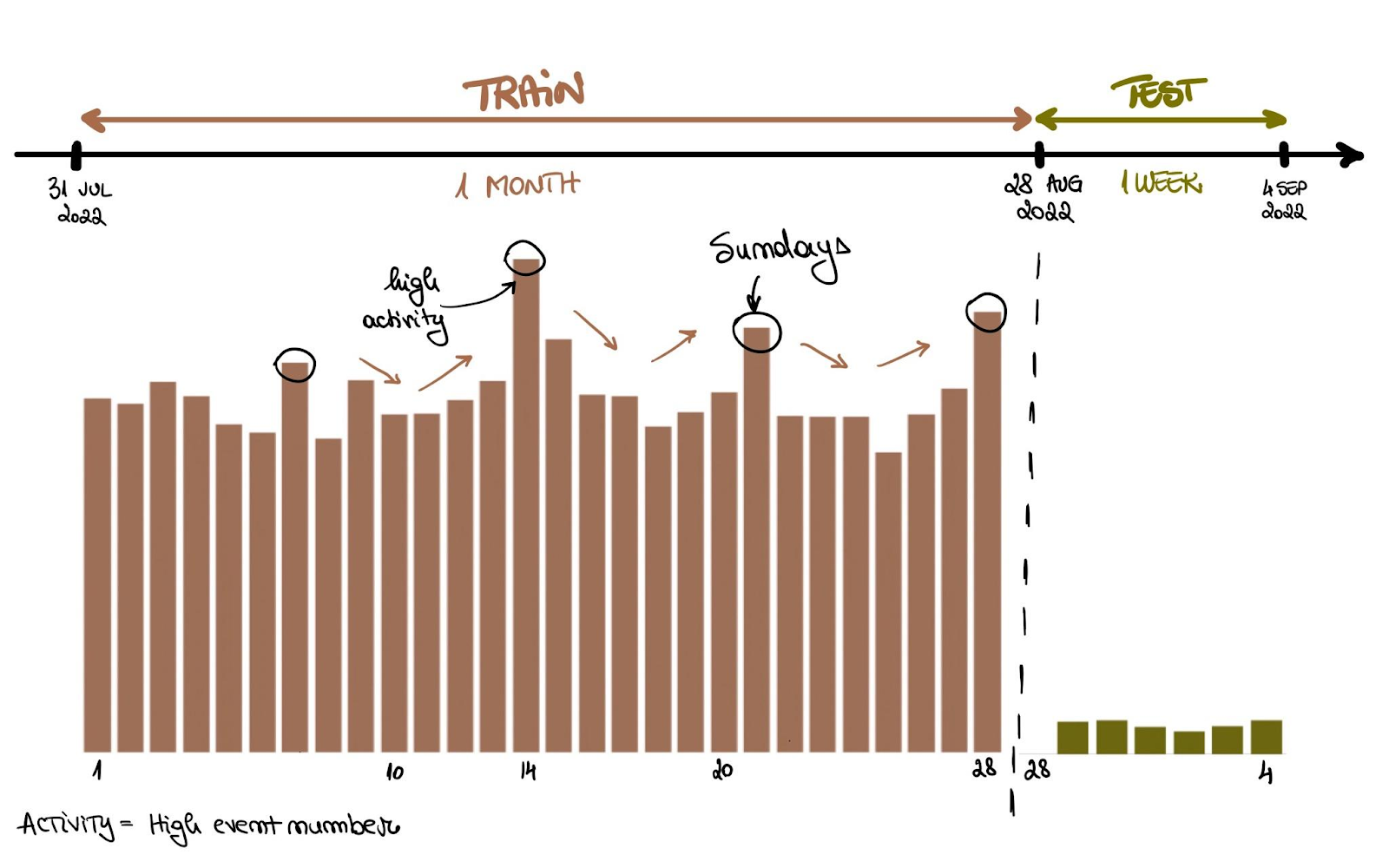
Afbeelding uit het project
Een project afronden is maar de helft van het werk—het effectief presenteren aan werkgevers is net zo belangrijk. Zo maak je van je projecten vindbare portfolio-assets:
Hoewel individuele projecten essentieel zijn voor persoonlijke vaardigheidsontwikkeling, moeten organisaties er ook voor zorgen dat hun teams goed uitgerust zijn voor de complexiteit van data-analyse. DataCamp for Business biedt op maat gemaakte oplossingen waarmee bedrijven hun medewerkers kunnen upskillen in data science, analytics en machine learning. Met toegang tot een enorme bibliotheek met interactieve cursussen, aangepaste leerpaden en realistische projecten kunnen teams hun skills in data-inname en -opschoning, manipulatie, visualisatie en voorspellende analyse ontwikkelen—alle kerngebieden die in deze blog zijn uitgelicht.
Of je nu een startup bent of een grote onderneming, DataCamp for Business biedt de tools om te upskillen, reskillen en een datagedreven cultuur te creëren om concurrerend te blijven. Je kunt vandaag nog een demo aanvragen om meer te weten te komen.
Na het leren van essentiële skills moet je een sterk portfolio opbouwen om je kennis te laten zien. Daarnaast leer je nieuwe tools, features en concepten die nuttig zijn voor je professionele leven.
In dit artikel hebben we beginnerprojecten, geavanceerde projecten, afstudeerprojecten en end-to-end data-analyticsprojecten bekeken. Bovendien hebben we projecten behandeld over data-inname en -opschoning, kansrekening en statistiek, datamanipulatie en -visualisatie, en exploratieve data- en voorspellende analyse.
Wat is de volgende stap? Na minimaal 12 projecten, probeer gecertificeerd te worden als Professional Data Analyst. Dat vergroot je kans om aangenomen te worden. Bekijk ook onze posts over hoe je data-analist wordt en hoe je een cv als data-analist bouwt voor meer carrièretips.
Cursus
Cursus
blog
Adel Nehme
15 min
