
Corso
Analisi esplorativa dei dati in R
4 h
118.1K
I progetti di data analytics sono passaggi fondamentali per chiunque voglia eccellere nel mondo odierno orientato ai dati. Ecco perché sono essenziali:
In sostanza, i progetti di data analytics non solo affinano le competenze tecniche, ma ti preparano anche alle sfide e alle richieste del mondo del lavoro moderno.
Da principiante, concentrati su importazione, pulizia, manipolazione e visualizzazione dei dati.
Nel progetto Exploring the NYC Airbnb Market applicherai competenze di importazione e pulizia per analizzare il mercato Airbnb di New York. Ingerirai e combinerai dati da più formati di file, pulirai stringhe e formatterai date per estrarre informazioni accurate.
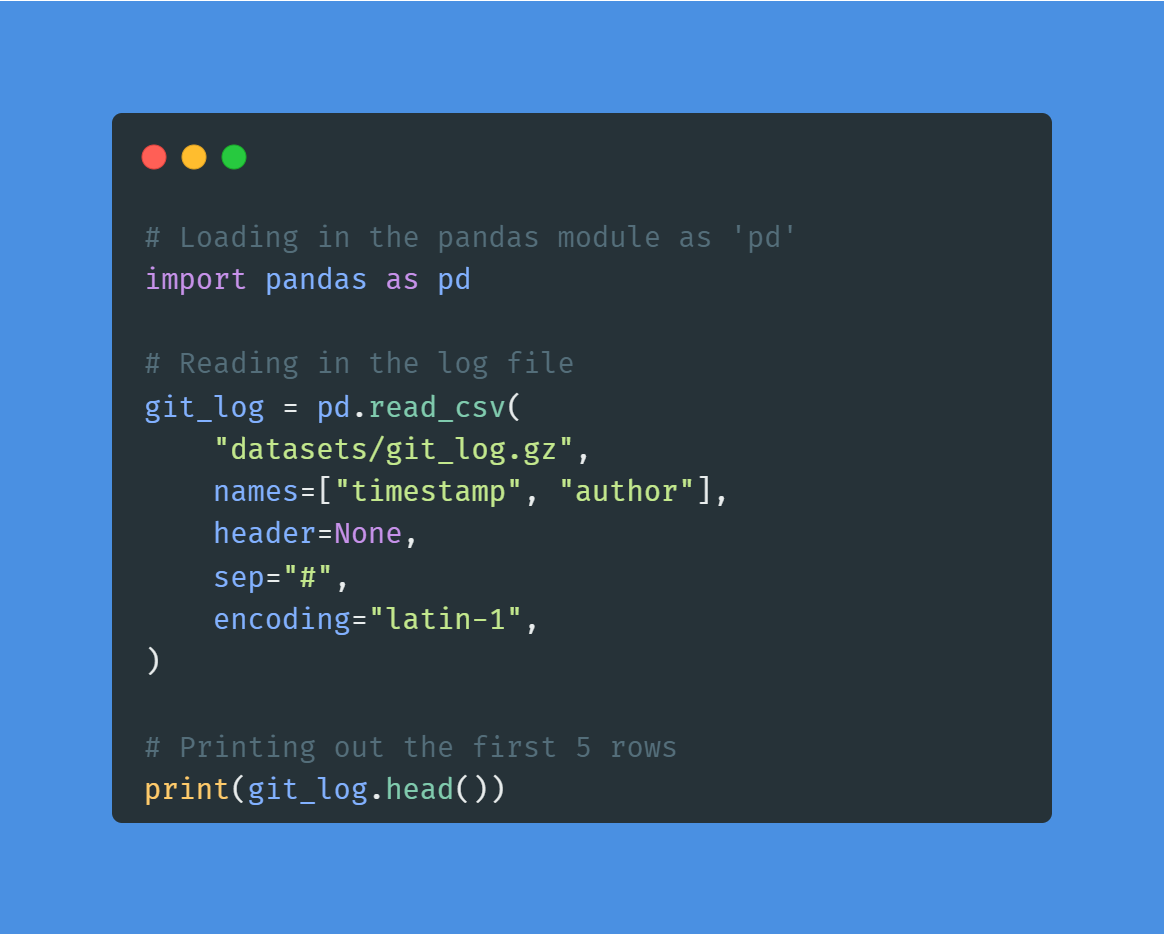
Immagine dell’autore | Codice dal progetto
Il progetto è perfetto per i principianti che vogliono fare esperienza su importazione e pulizia dei dati. Puoi applicare metodi simili a questo dataset di vendita di biglietti online per migliorare ancora nella gestione e nel processamento dei dati.
Approfondisci importazione e pulizia dei dati con questi short course:
Nel progetto Word Frequency in Classic Novels userai requests e BeautifulSoup per fare scraping di un romanzo dal sito Project Gutenberg. Dopo lo scraping e la pulizia del testo, userai tecniche di NLP per trovare le parole più frequenti in Moby Dick. Il progetto introduce al web scraping in Python e al natural language processing.
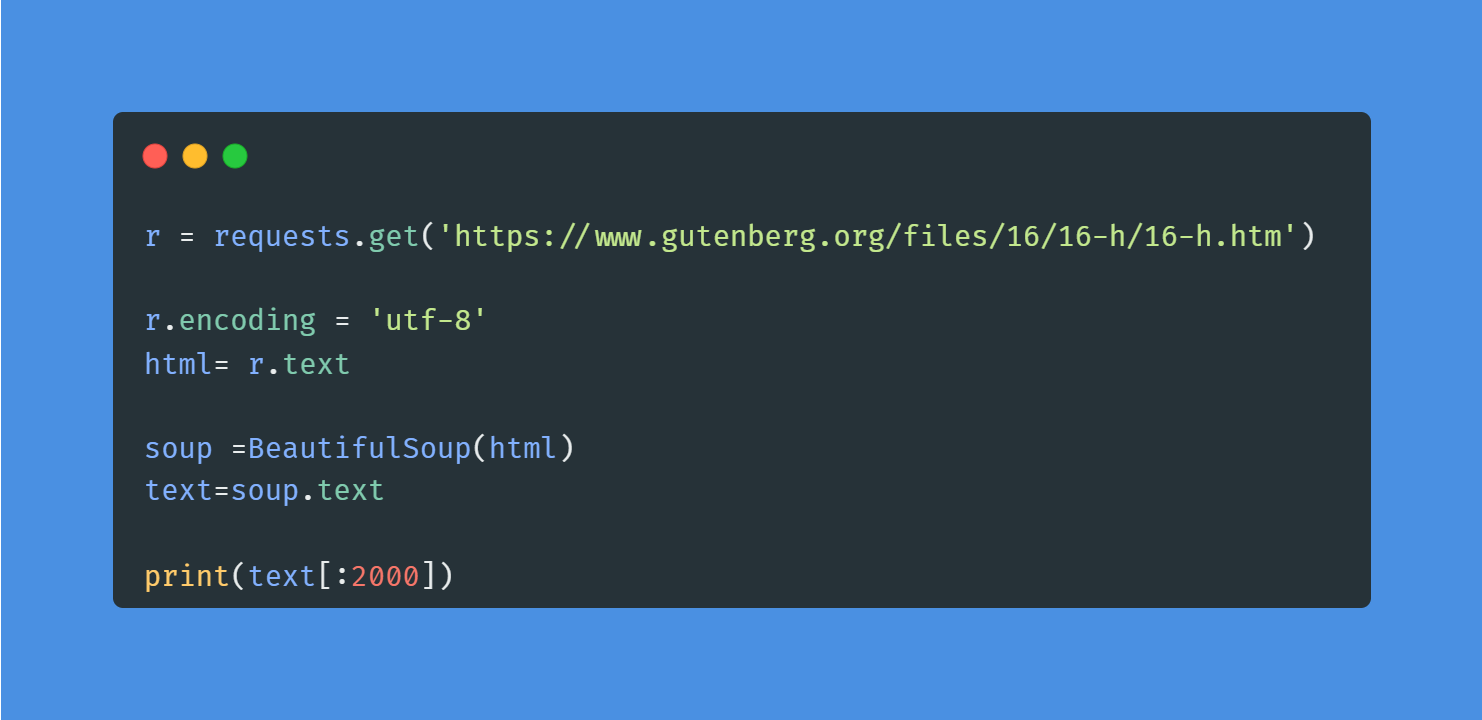
Immagine dell’autore | Codice dal progetto
Per data analyst e data scientist, il web scraping è una competenza essenziale. Puoi seguire il breve corso Web Scraping with Python per capire gli strumenti e i componenti di una pagina web HTML.
Nel progetto Exploring NYC Public School Test Result Scores analizzerai le performance SAT standardizzate nelle scuole pubbliche di New York City. Pulirai e riepilogherai le colonne (Matematica, Lettura, Scrittura), confronterai i risultati tra i distretti, classificherai le scuole per punteggi di matematica ed evidenzierai le dieci migliori della città. Lungo il percorso, metterai in pratica mosse fondamentali da analista: correzione dei tipi, gestione dei valori mancanti, calcolo di statistiche di gruppo e trasformazione di dati grezzi a livello scuola in insight chiari e pronti per le decisioni.
Immagine dell’autore | Codice dal progetto
Questo progetto è perfetto per principianti che vogliono creare una EDA realistica in stile business, con ranking, benchmarking e segmentazione geografica. Puoi usare la stessa metodologia su dataset correlati, come "Fattori che alimentano la performance degli studenti" o gli open data del tuo distretto locale, per arricchire il portfolio con analisi comparabili e riproducibili.
Nel progetto Analyzing Motorcycle Part Sales interrogherai un database vendite multi-magazzino per individuare pattern di ricavi nel tempo, per linee di prodotto e per sede. Calcolerai il ricavo netto (considerando sconti/resi dove applicabile), segmenterai per magazzino e data, classificherai le categorie di prodotto top performer e costruirai confronti per mettere in luce crescita vs. calo.
Aspettati tanta SQL pratica: join, troncamento date, aggregazioni condizionali e funzioni finestra per trasformare transazioni grezze in report chiari, pronti per i dirigenti.
Immagine dell’autore | Codice dal progetto
Questo progetto è perfetto per analisti che vogliono esperienza SQL orientata al business, simile al lavoro reale: definizioni KPI, rollup dei ricavi, benchmarking tra magazzini e monitoraggio delle performance nel tempo, da integrare in una dashboard o in un report operativo settimanale.
Nel progetto Exploring the Bitcoin Cryptocurrency Market esplorerai Bitcoin e altri dati sulle criptovalute. Pulirai il dataset scartando le criptovalute senza capitalizzazione di mercato, confronterai Bitcoin con altre valute e preparerai i dati per la visualizzazione.
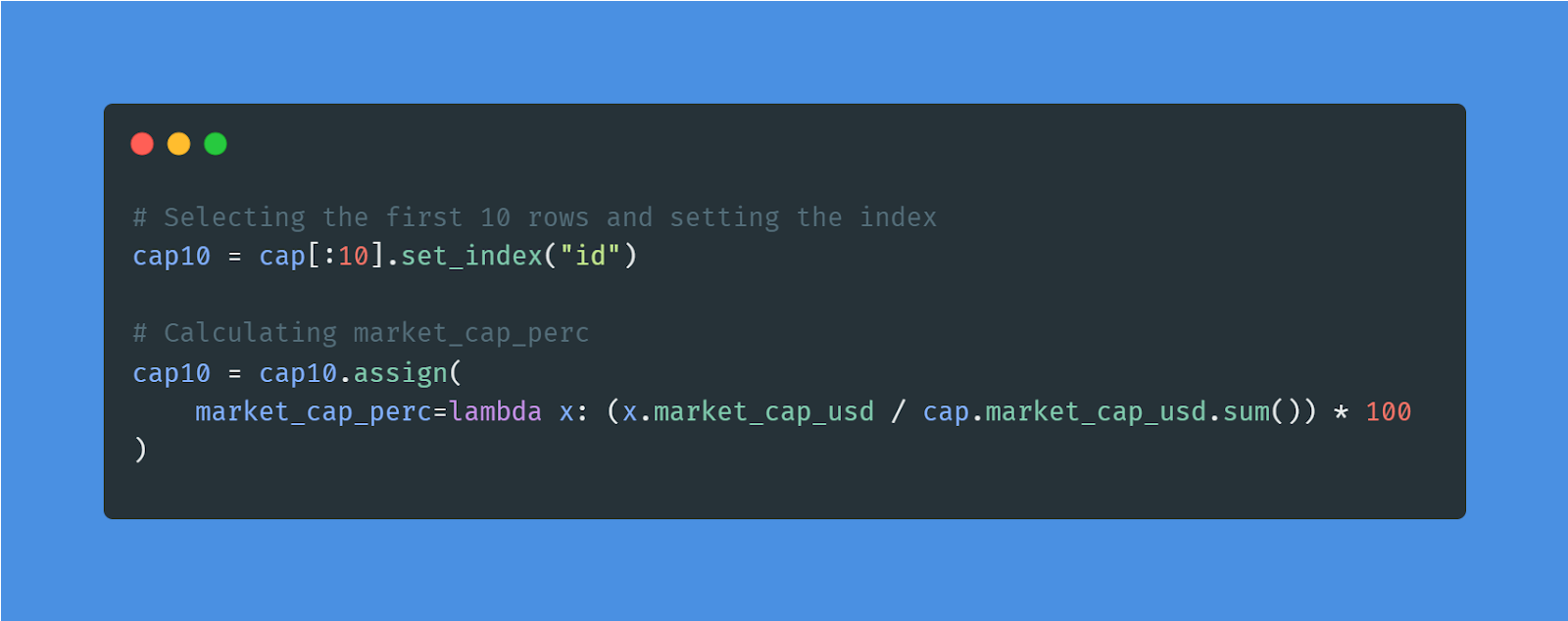 Immagine dell’autore | Codice dal progetto
Immagine dell’autore | Codice dal progetto
Puoi applicare metodi simili ai dati di borsa e imparare a manipolare i dati per l’analisi. Inoltre, puoi imparare trasformazioni, aggregazioni, slicing e indicizzazione seguendo il corso Data Manipulation with pandas.
Nel progetto Visualizing the History of Nobel Prize Winners esaminerai oltre un secolo di storia dei Premi Nobel. Con Python analizzerai e visualizzerai i dati per scoprire pattern e potenziali bias nell’assegnazione di onorificenze prestigiose in categorie come fisica, chimica, letteratura e pace.
Applicherai tecniche di manipolazione con pandas e creerai visualizzazioni efficaci con Seaborn per raccontare una storia attraverso i dati. Questo progetto è perfetto per migliorare le abilità di analisi e visualizzazione esplorando uno dei riconoscimenti più famosi al mondo.
Nel progetto Exploring Stock Market Trends with Plotly trasformerai prezzi grezzi di giganti del fast food (es. McDonald’s, Starbucks) in grafici interattivi che evidenziano il momentum del settore e i pattern. Costruirai grafici a candele e a linee, aggiungerai medie mobili e statistiche rolling, confronterai più ticker e annoterai eventi chiave, puntando a uno storytelling visivo che metta in luce volatilità, stagionalità e performance relativa.

Questo è un progetto centrato sulla visualizzazione, perfetto se vuoi una dashboard pulita e pronta per il portfolio che mostri insight di mercato tramite interattività (hover, zoom, range slider) più che con modellazione pesante.
Nel progetto Visualizing COVID-19 visualizzerai i dati COVID-19 usando la libreria R più popolare, ggplot. Analizzerai i casi confermati nel mondo, confronterai la Cina con altri paesi, imparerai ad annotare il grafico e ad aggiungere una scala logaritmica. Il progetto insegna competenze molto richieste per i programmatori R.
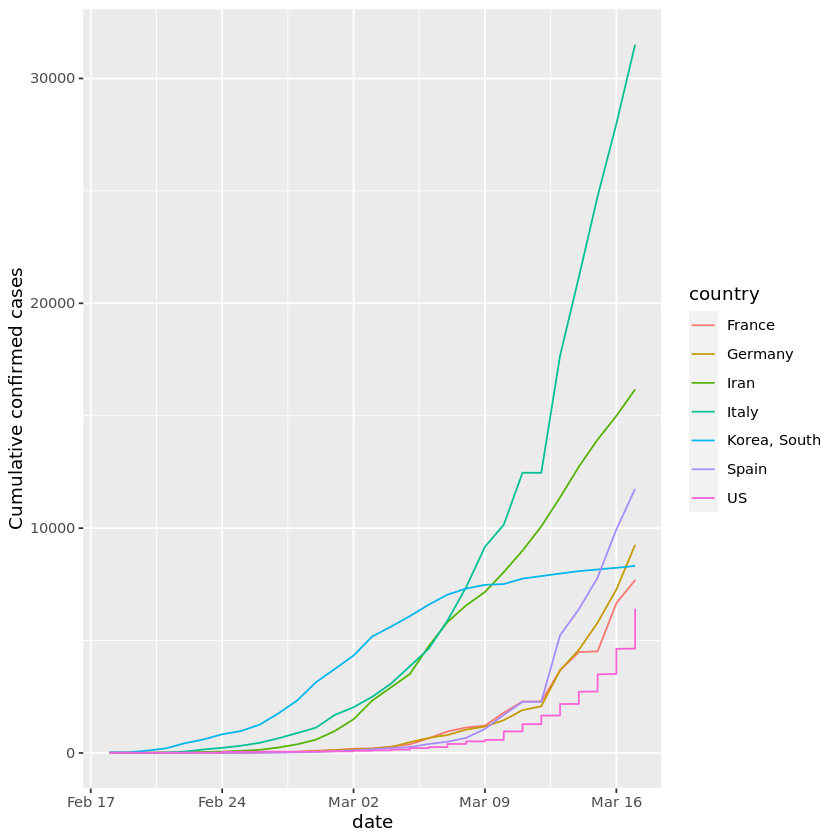
Immagine dal progetto
Puoi applicare i metodi di ggplot ai dati sul morbillo e fare ulteriore esperienza in visualizzazione e analisi. Inoltre, puoi seguire il corso Intermediate Data Visualization with the ggplot2 per imparare le migliori pratiche di data visualization.
Nel progetto Analyzing Super Bowl Viewership and Advertising esplorerai il “dietro le quinte” del Super Bowl—dalle partite e pubblicità agli show dell’intervallo. Con R, manipolerai e visualizzerai i dati per capire come questi elementi interagiscono. Perfetto per sviluppare le tue abilità di analisi con strumenti come ggplot2 e dplyr.
Scrivere codice per visualizzazioni interattive è facile, ma comprendere e interpretare i dati è difficile. Segui il corso Understanding Data Visualization per spiegare la distribuzione nelle visualizzazioni e imparare le migliori tecniche per comunicare dati complessi.
Per affrontare progetti di data analytics più avanzati servono solide basi di matematica, probabilità e statistica. Inoltre, eseguirai analisi esplorativa e analisi predittiva per comprendere a fondo i dati.
Nel progetto Modeling Car Insurance Claim Outcomes userai Python e la regressione logistica per predire i sinistri assicurativi. Lavorando con i dati di On the Road car insurance, identificherai le feature chiave che portano a previsioni più accurate. Questo progetto ti aiuterà ad applicare tecniche di machine learning a problemi reali del settore assicurativo.
Nel progetto Hypothesis Testing with Men's and Women's Soccer Matches analizzerai dati storici sul calcio per testare se le partite internazionali femminili producono più goal di quelle maschili. Con Python affinerai le tue abilità nei test statistici e scoprirai pattern nelle tendenze calcistiche globali.
Se vuoi conoscere le tecniche statistiche più comuni, probabilità, distribuzioni, correlazioni e design sperimentale, segui il corso Introduction to Statistics in Python.
Nel progetto Analyze International Debt Statistics scriverai query SQL per esplorare e analizzare il debito internazionale usando il dataset della Banca Mondiale. SQL è lo strumento più popolare ed essenziale per fare data analytics al volo.
Nel progetto individuerai:
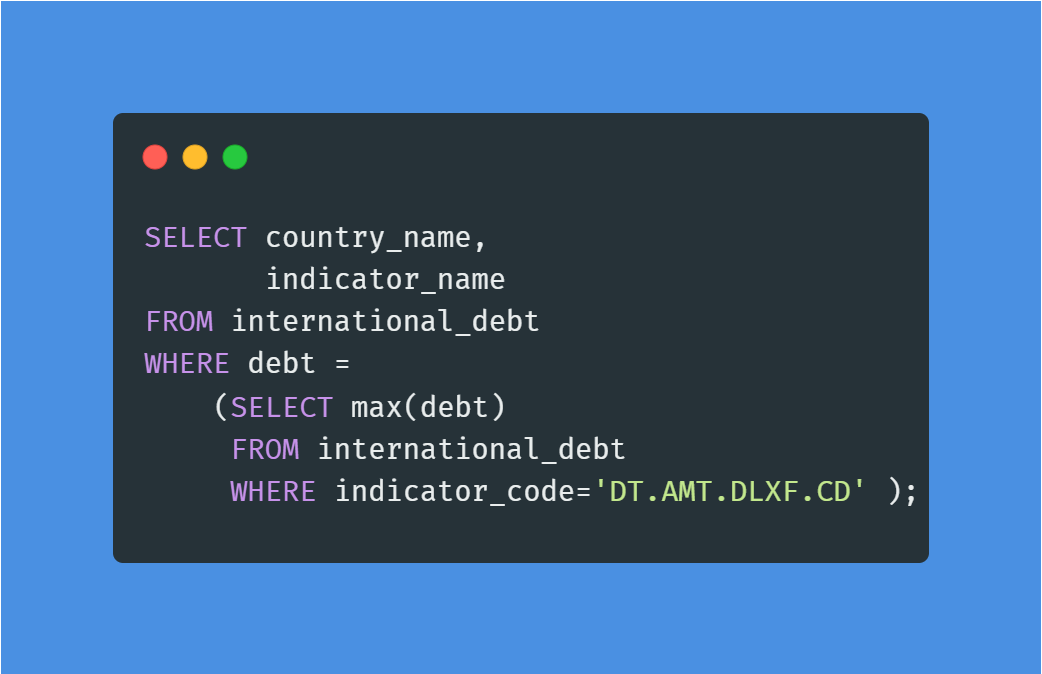
Immagine dell’autore | Codice dal progetto
Ti connetterai al dataset MariaDB World Nations e applicherai query simili per fare ulteriore pratica nella gestione e analisi di database SQL. Inoltre, puoi seguire il corso Exploratory Data Analysis in SQL per tecniche e query avanzate su vari database SQL.
Nel progetto Analyzing Crime in Los Angeles vestirai i panni del data detective per il LAPD, pulendo e segmentando i dati degli incidenti per capire quando e dove è più probabile che si verifichino reati e quali tipologie prevalgono. Segmenterai per fascia oraria, giorno della settimana, quartiere e categoria; calcolerai sintesi delle aree calde e costruirai confronti che si traducono direttamente in insight per l’allocazione delle risorse.
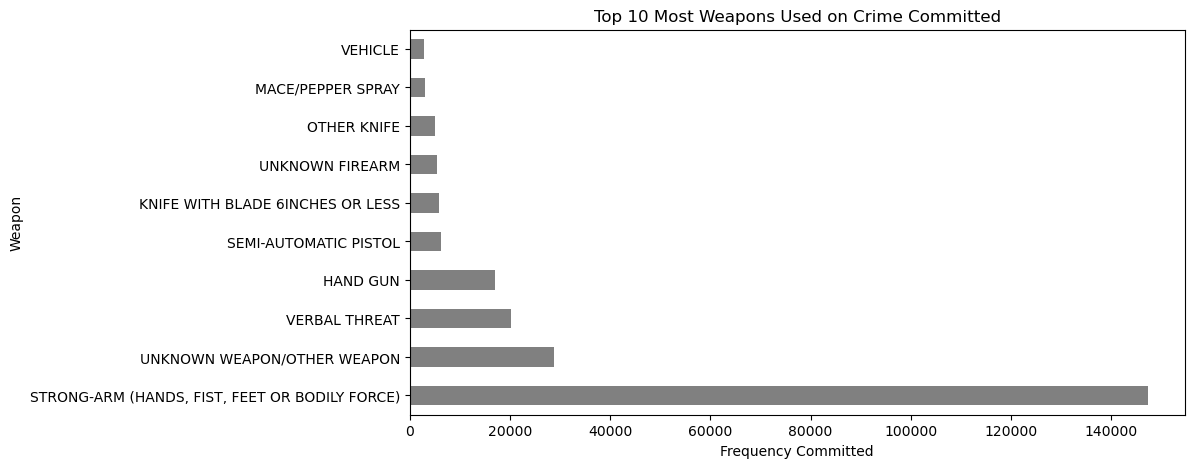
Immagine dal progetto
Metterai in pratica: pulizia dati, raggruppamento e aggregazione, suddivisione temporale, normalizzazione dei tassi (pro capite o per finestra temporale), ranking dei top-N quartieri/reati e creazione di tabelle/grafici interpretabili per le decisioni.
Nel progetto Investigating Netflix Movies and Guest Stars in The Office userai manipolazione e visualizzazione dei dati per risolvere un problema reale di data science. Eseguirai un’analisi esplorativa approfondita e trarrai conclusioni da grafici dettagliati.
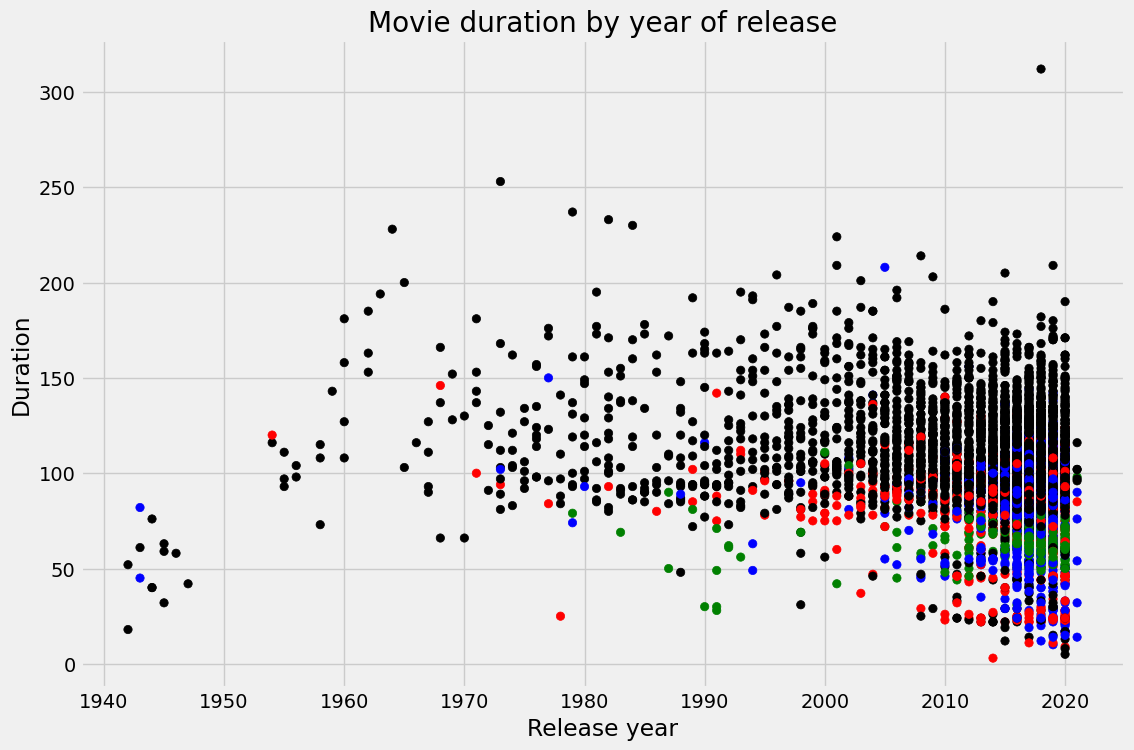
Immagine dal progetto
Puoi lavorare a un progetto da portfolio applicando competenze simili a un nuovo dataset: Netflix Movie Data. Inoltre, puoi seguire Exploratory Data Analysis in Python per imparare di più su pulizia e validazione, relazioni e distribuzioni e analisi multivariata.
Nel progetto Predict Future Sales of Fast-Food Menu Items aiuterai una catena di fast food a ridurre spese e ordini all’ultimo minuto costruendo un modello di previsione vendite per i prodotti principali. Inquadrerai il problema di business, farai feature engineering su calendario/promozioni, creerai split consapevoli del tempo, adatterai e confronterai modelli di regressione in R e quantificherai l’impatto con RMSE/MAE, trasformando lo storico POS in piani d’ordine più accurati ed economici.
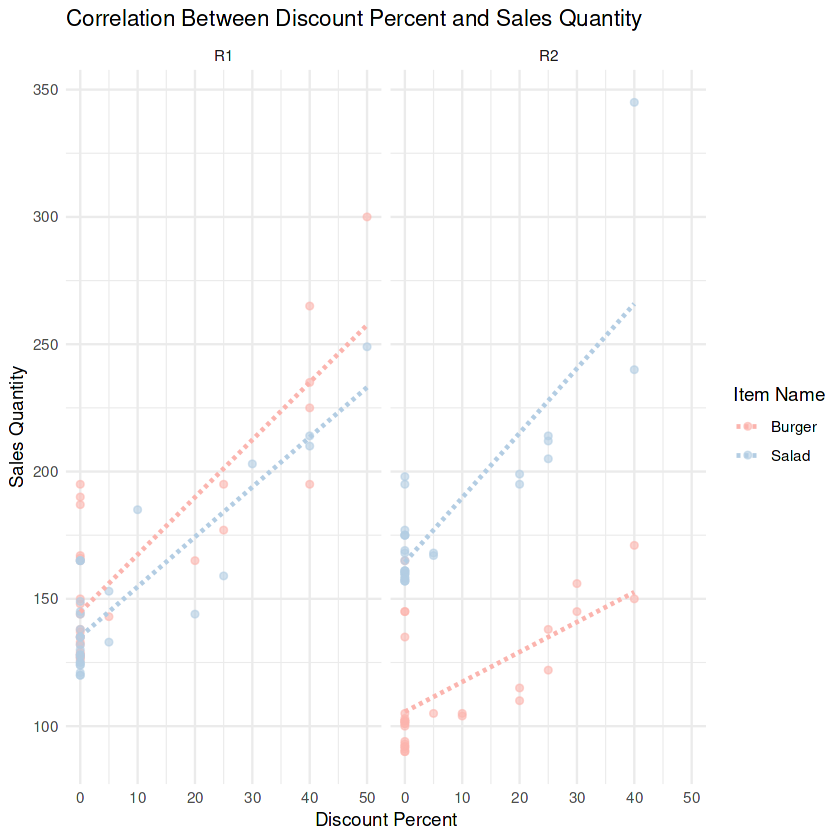
Immagine dal progetto
Metterai in pratica feature engineering (giorno della settimana, festività, promozioni), split train/test senza leakage, modelli baseline vs. ottimizzati, cross-validation, report RMSE/MAE, semplice backtesting e conversione dei risultati in raccomandazioni d’ordine.
Nel progetto Will This Customer Purchase Your Product? analizzerai i comportamenti d’acquisto dei clienti con tecniche di statistica e probabilità. Con Python, scoprirai insight sulle differenze tra clienti nuovi e di ritorno, aiutando i team marketing a comprendere meglio l’engagement sulle piattaforme e-commerce.
Nel progetto Predicting Credit Card Approvals costruirai il modello di machine learning con le migliori performance per predire l’approvazione delle richieste di carta di credito.
Per prima cosa comprenderai i dati e imputerai i valori mancanti. Poi pre-processerai i dati e allenerai un modello di regressione logistica sul training set. Infine, valuterai i risultati e migliorerai le performance usando la ricerca a griglia.
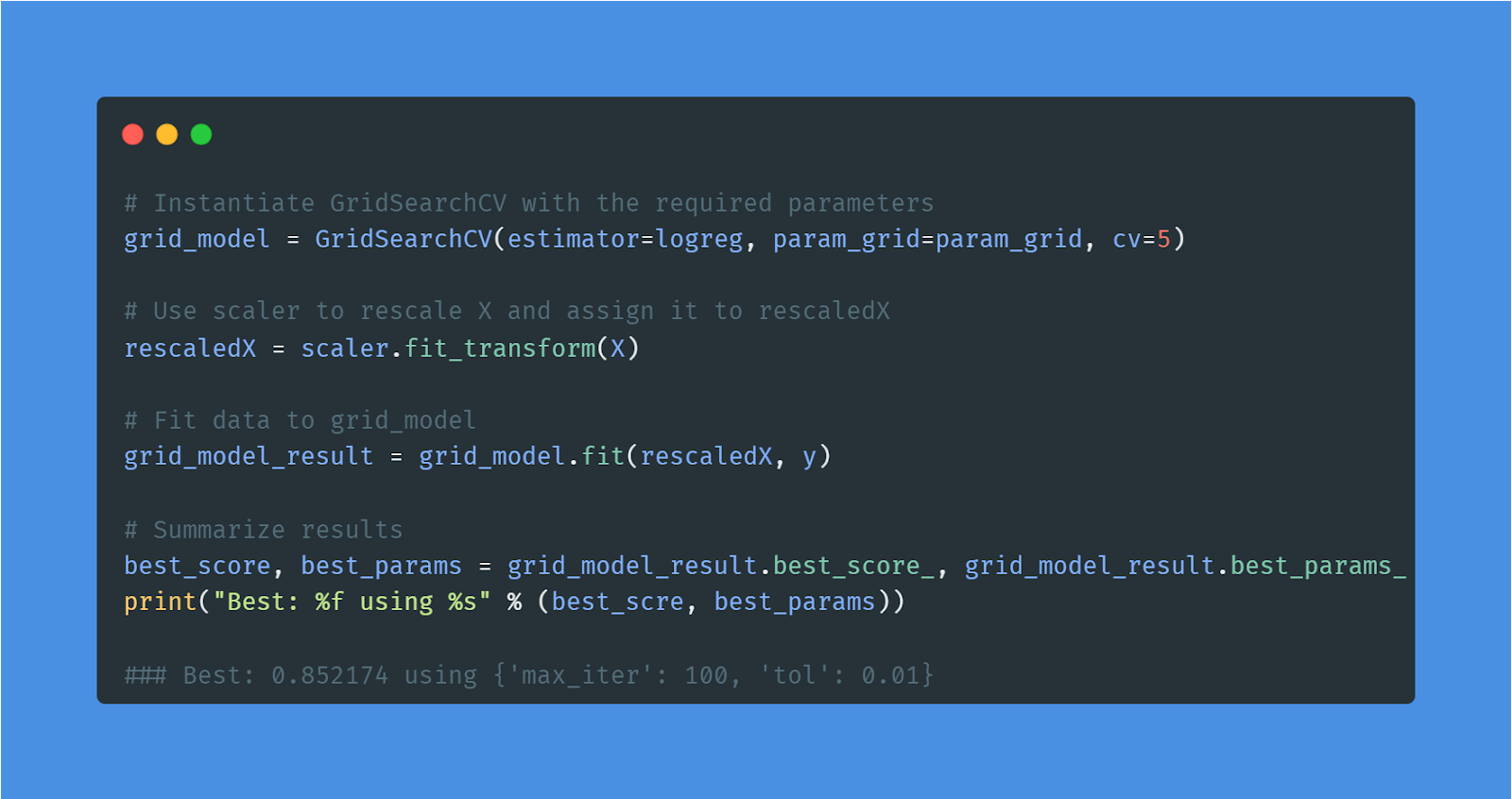
Immagine dell’autore | Codice dal progetto
Applicare semplici algoritmi di machine learning è una parte essenziale del lavoro di un data analyst. Puoi fare ulteriore esperienza applicando metodi simili a un nuovo dataset: Bank Marketing.
Per saperne di più su classificazione, regressione, fine-tuning e pre-processing, segui il breve corso Supervised Learning with the scikit-learn.
I progetti di fine corso sono solitamente basati sulla ricerca e richiedono almeno 2-3 mesi. Lavorerai su un tema specifico cercando di migliorare i risultati con varie tecniche statistiche e probabilistiche.
Nota: cresce il trend dei progetti di machine learning per i progetti di data analytics di fine corso.
Nel progetto Exploring London’s Travel Network interrogherai un data warehouse (Snowflake/Redshift/BigQuery/Databricks) con 12 anni di viaggi TfL (2010–2022) per capire come si muovono i londinesi. Classificherai i mezzi più popolari, individuerai i periodi in cui la funivia è stata insolitamente affollata e riconoscerai rare finestre in cui la metropolitana è stata più tranquilla del normale, trasformando i viaggi grezzi in insight operativi per pianificazione orari e capacità.
Immagine dal progetto
Metterai in pratica raggruppamenti temporali (mese/anno), funzioni finestra e di aggregazione, aggregazioni condizionali per mezzo/linea, individuazione di anomalie (periodi insolitamente affollati o tranquilli), verifica della stagionalità (eventi/festività) e costruzione di tabelle KPI pulite per le operazioni di trasporto.
Nel progetto Reducing Traffic Mortality in the USA troverai una buona strategia per ridurre le morti legate al traffico negli Stati Uniti. Importerai, pulirai, manipolerai e visualizzerai i dati. Inoltre, farai feature engineering e applicherai vari modelli di machine learning (regressione lineare multivariata, clustering KMeans) per arrivare a raccomandazioni a livello statale e comunicare i risultati.
Immagine dal progetto
Se vuoi approfondire l’apprendimento non supervisionato, scopri il corso Cluster Analysis in Python.
Nel progetto Assessing the Effectiveness of Medical Treatments esplorerai l’affascinante caso del Paradosso di Simpson in uno studio sui trattamenti per i calcoli renali. Con R applicherai analisi di regressione per scoprire insight nascosti e capire meglio come gli esiti variano tra gruppi di pazienti.
Nel progetto Building a Demand Forecasting Model prevederai la domanda di prodotti e-commerce con PySpark, rispondendo a domande reali della supply chain come pianificazione scorte e frequenza di riordino. Farai feature engineering temporale (giorno della settimana, stagionalità, festività), creerai split di validazione consapevoli del tempo, allenerai e confronterai baseline di forecasting e modelli ML su larga scala ed eseguirai backtest rolling per quantificare la stabilità, trasformando lo storico ordini in piani di acquisto azionabili.
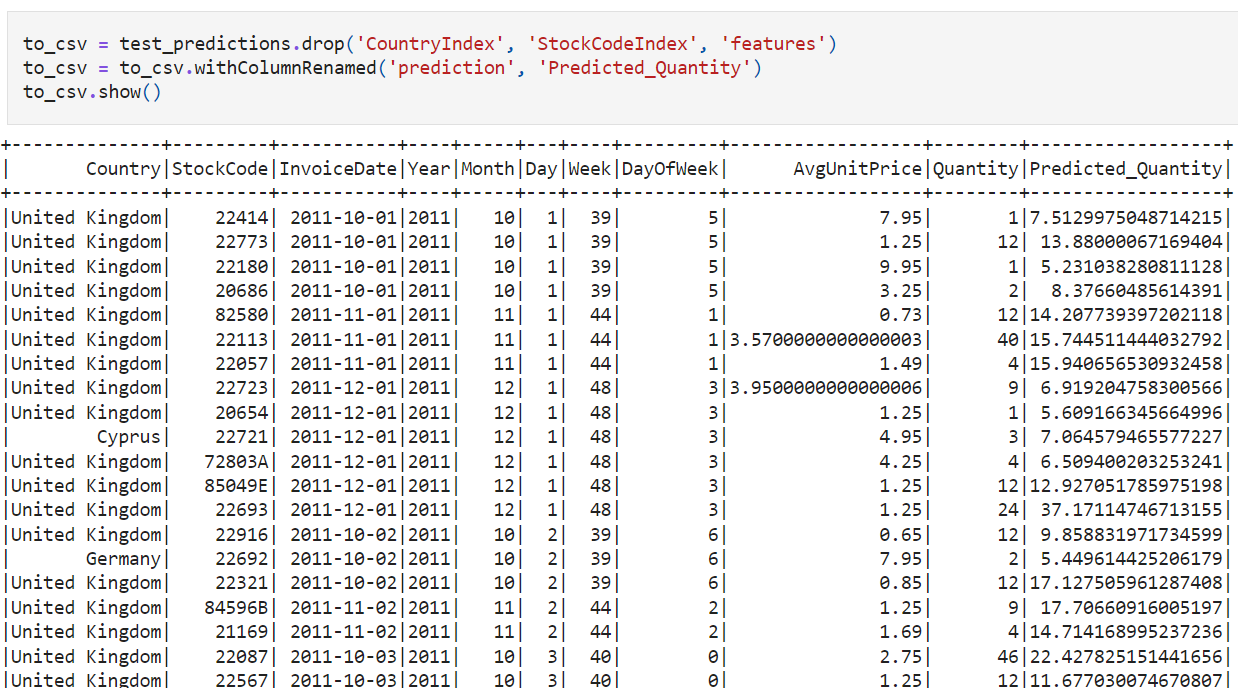
Immagine dal progetto
Metterai in pratica feature engineering su larga scala, join/operazioni finestra in Spark, validazione senza leakage, modelli baseline vs. ottimizzati, analisi degli errori RMSE/MAE, backtest rolling/bloccati e analisi di scenario, incluse promozioni e stagionalità.
Nel progetto Social Networks: A Twitter Network Analysis analizzerai i dati dei follower con pandas e NetworkX per scoprire influencer, ponti e strutture di comunità. Costruirai funzioni riutilizzabili per caricare/pulire edge list, costruirai grafi, calcolerai metriche di centralità (grado, betweenness, autovettore), rileverai comunità, ispezionerai ego-net e visualizzerai la topologia della rete, trasformando connessioni grezze in insight chiari e azionabili.
Metterai in pratica costruzione del grafo da dati di follower, pulizia dati con pandas, centralità e rilevamento comunità, ranking degli account influenti, esplorazione delle ego-net e creazione di visualizzazioni della rete leggibili con takeaway chiari.
Il progetto World Population Analysis è un ottimo esempio di analisi esplorativa approfondita. Esplorerai varie colonne, visualizzerai i paesi meno e più popolati, e analizzerai densità di popolazione e tasso di crescita. Inoltre, mostrerai la distribuzione del ranking dei paesi e la mappa delle correlazioni.
Immagine dal progetto
Impara modi semplici per creare visualizzazioni in Python completando il corso Intermediate Data Visualization with Seaborn.
Il progetto Data Science and MLOps Landscape in Industry è una miniera d’oro per manipolazione dati, visualizzazioni e analisi esplorative e geospaziali. Imparerai a usare efficacemente box plot, doughnut chart, bar chart, heatmap, grafici categoriali paralleli, bubble chart, funnel chart, radar chart, icicle chart e mappe. Inoltre, imparerai a interpretare vari tipi di grafici.
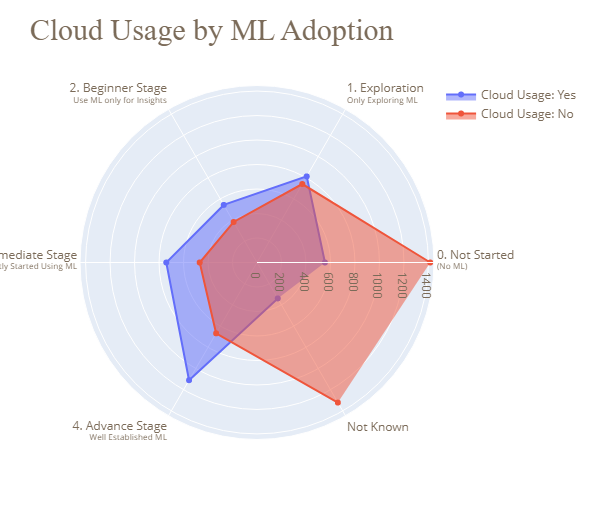
Immagine dal progetto
Segui il corso Introduction to Data Visualization with Plotly in Python per scoprire funzionalità avanzate di Plotly e personalizzazione.
Nel 2026, gli analisti più richiesti uniscono analitica tradizionale e strumenti di AI. Le aziende vogliono professionisti capaci di lavorare con dati non strutturati, costruire pipeline in tempo reale e spiegare gli insight in modo semplice. Questi due progetti rispondono direttamente a questa esigenza.
Nel progetto Sentiment Analysis Complete Project, userai Python e NLP per preprocessare migliaia di testi non strutturati da un dataset reale, eseguire tokenizzazione e rimozione delle stop word, quindi applicare modelli di machine learning per classificazione e scoring del sentiment. Questo workflow end-to-end trasforma testo disordinato in previsioni positivo/negativo con metriche di accuratezza, valutazione del modello e visualizzazioni.
Mostra competenze pratiche in preprocessing e classificazione del testo, ideale per portfolio di data analyst focalizzati su customer insight o ruoli di social media monitoring.
Approfondisci le tue competenze NLP con il corso Introduction to Natural Language Processing in Python.
Nel progetto Store Sales Time-Series Forecasting affronterai una competizione Kaggle reale usando dati di una catena di supermercati ecuadoriana su 50+ negozi e 30 famiglie di prodotti. Applica la libreria Prophet di Facebook per prevedere le vendite tenendo conto di prezzi del petrolio, festività, promozioni e stagionalità multi-serie
Il progetto copre feature engineering, cross-validation ed ensemble che combinano Prophet e LightGBM per un’accuratezza di livello produttivo.
I progetti end-to-end sono ottimi per il curriculum e per comprendere il ciclo di vita di un progetto di data analytics.
In generale, ti troverai a:
Nel progetto Analyzing Unicorn Companies userai SQL per esplorare le aziende “unicorno” valutate oltre 1 miliardo di dollari. Analizzerai quali settori hanno le valutazioni più alte e identificherai trend emergenti, come la crescita annuale delle nuove unicorn tra il 2019 e il 2021.
Nel progetto Monitoring a Financial Fraud Detection Model vestirai i panni del data scientist post-deployment per una grande banca del Regno Unito. Con Python monitorerai le performance di un modello antifrode e indagherai perché potrebbe non funzionare come previsto, garantendo la sicurezza dei fondi dei clienti.
Nel progetto Time Series Analysis and Forecasting approfondirai l’analisi dei trend, applicherai il modello ARIMA per le previsioni, confronterai i risultati e visualizzerai gli esiti per comprendere le vendite sia di arredamento sia di forniture per ufficio.
I progetti di analisi e forecasting di serie temporali sono molto richiesti nel settore finanziario e ti aiuteranno a ottenere un lavoro ben retribuito. L’unica cosa che devi fare è interpretare i vari trend e prevedere i numeri con accuratezza.
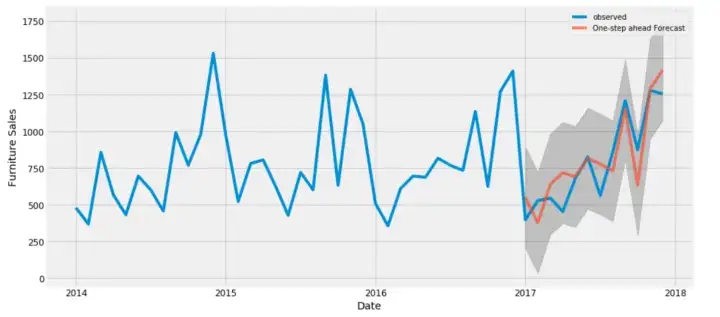
Immagine dal progetto
Se fai fatica con analisi e forecasting, prova a completare il corso ARIMA Models in Python per conoscere i modelli ARMA, il fitting sul futuro, la selezione dei modelli migliori e l’addestramento di ARIMA stagionali.
L’obiettivo del progetto Build a multi-objective recommender system è prevedere click, aggiunte al carrello e ordini in e-commerce. In breve, creerai un recommender system multi-obiettivo basato sugli eventi precedenti in una sessione utente.
Al termine del progetto, avrai padroneggiato:
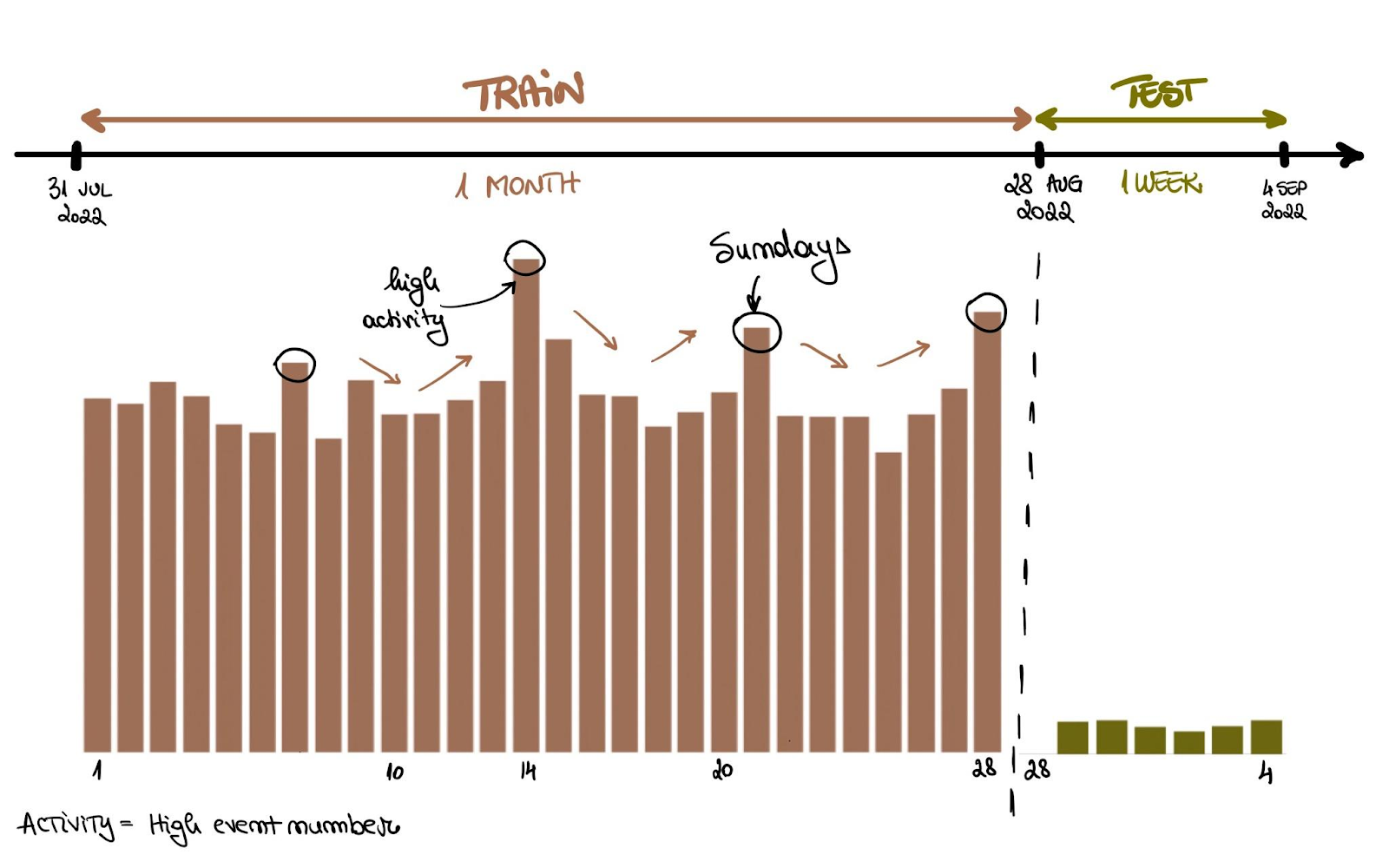
Immagine dal progetto
Completare un progetto è solo metà del lavoro—presentarlo in modo efficace ai datori di lavoro è altrettanto importante. Ecco come trasformare i tuoi progetti in asset di portfolio facilmente scopribili:
Se i progetti individuali sono essenziali per la crescita personale, le organizzazioni devono anche assicurarsi che i team siano pronti a gestire la complessità della data analytics. DataCamp for Business offre soluzioni su misura per aiutare le aziende a fare upskilling dei dipendenti in data science, analytics e machine learning. Con accesso a un’ampia libreria di corsi interattivi, percorsi personalizzati e progetti reali, i team possono avanzare nelle competenze di ingestion, pulizia, manipolazione, visualizzazione e analisi predittiva—tutte aree chiave evidenziate in questo blog.
Che tu sia una startup o una grande impresa, DataCamp for Business fornisce gli strumenti per fare upskilling, reskilling e creare una cultura data-driven per restare competitivo nel mercato di oggi. Puoi anche richiedere una demo oggi stesso per saperne di più.
Dopo aver imparato le competenze essenziali, devi costruire un solido portfolio per mostrare ciò che sai fare. Inoltre, continuerai a imparare nuovi strumenti, funzionalità e concetti utili per la tua vita professionale.
In questo post abbiamo visto progetti per principianti, avanzati, per studenti dell’ultimo anno e progetti end-to-end di data analytics. Abbiamo inoltre coperto progetti su ingestion e pulizia dei dati, probabilità e statistica, manipolazione e visualizzazione, e analisi esplorativa e predittiva.
E adesso? Dopo aver completato almeno 12 progetti, prova a certificarti come Professional Data Analyst. Aumenterà le tue possibilità di essere assunto. Puoi anche consultare i nostri post su come diventare data analyst e come costruire un curriculum da data analyst per altri consigli di carriera.
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

