Tracks
Google Workspace 与 Gemini
4小时
以下是两款模型在对实务最重要的维度上的快速对比摘要。
| 功能 | Gemini 3.5 Flash | Claude Opus 4.7 |
|---|---|---|
| 分层定位 | 速度优化(Flash) | 旗舰 |
| SWE-bench Pro | 55.1% | 64.3% |
| Terminal-bench 2.1 | 76.2% | 66.1% |
| MCP Atlas(工具使用) | 83.6% | 77.3% |
| CharXiv Reasoning(多模态) | 84.2% | 82.1% |
| Finance Agent v2 | 57.9% | 51.5% |
| OSWorld(计算机使用) | 78.4% | 78.0% |
| Humanity's Last Exam | 40.2% | 46.9% |
| ARC-AGI-2(抽象推理) | 72.1% | 75.8% |
| 上下文窗口 | 100 万 tokens | 100 万 tokens |
| 视觉分辨率 | 未说明 | 最高 2,576px / 3.75MP |
| Computer Use 支持 | 不支持 | 支持(OSWorld:78.0%) |
| API 输入定价 | $1.50 / 100 万 tokens | $5.00 / 100 万 tokens |
| API 输出定价 | $9.00 / 100 万 tokens | $25.00 / 100 万 tokens |
| 多智能体框架 | Antigravity harness | 任务预算 + 努力度参数 |
这是两款模型差异最明显的维度,尽管尚无全线碾压的赢家。
在通用编码基准 SWE-bench Pro 上,Opus 4.7 得分 64.3%,而 Gemini 3.5 Flash 为 55.1%。这对 Claude 在仓库级工程工作上构成有意义的优势。然而在 Terminal-Bench 2.1 上情况反转,Gemini 3.5 Flash 取得 76.2%,较 Opus 4.7 的 66.1% 领先幅度相当。更偏命令行的工作,Gemini 3.5 Flash 更合适。
| 基准 | Gemini 3.5 Flash | Claude Opus 4.7 | 备注 |
|---|---|---|---|
| SWE-bench Pro | 55.1% | 64.3% | 厂商披露;Opus 4.7 领先约 9 个百分点 |
| Terminal-Bench 2.1 / 2.0 | 76.2%(v2.1) | 69.4%(v2.0) | 版本不同;仅具方向性 |
| MCP Atlas | 83.6% | 77.3% | Gemini 3.5 Flash 在工具编排上领先 |
两款模型都面向长周期智能体任务,但路径不同。Gemini 3.5 Flash 以 Antigravity harness 为核心,能并行部署协作子智能体。谷歌举例为:两名智能体在 6 小时内综述 AlphaZero 论文并编码出可玩的完整游戏。Opus 4.7 则依靠任务预算与新增的 xhigh 努力度来在长时段内保持性能;Anthropic 报告称该模型会咬住难题推进,而非半途而废。
在测量复杂多工具工作流表现的 MCP Atlas 上,Gemini 3.5 Flash 以 83.6% 领先 Opus 4.7 的 77.3%。如果您的智能体系统高度依赖工具编排而非深层代码理解,3.5 Flash 确有优势。
若追求纯粹的软件工程深度,Opus 4.7 更强;若构建以工具为主的智能体流水线、强调吞吐与并行子智能体执行,Gemini 3.5 Flash 竞争力强且成本更低。
除编程能力外,通用推理深度也是 Opus 4.7 相较 Gemini 3.5 Flash 的头号优势。在 Humanity's Last Exam 上(涵盖理学、数学、人文学科的研究生水平问答),Opus 4.7 在无工具条件下得分 46.9%,而 Gemini 3.5 Flash 为 40.2%。在抽象推理上差距收窄:ARC-AGI-2 中 Flash 为 72.1%,Opus 4.7 为 75.8%。
更有意思的信号来自 Finance Agent v2,Gemini 3.5 Flash 以 57.9% 领先 Opus 4.7 的 51.5%。这组数据让我重新审视整场对比。起初我以为凡是需要在复杂文档上进行多步推理的任务,Opus 4.7 都应领先——这正是其旗舰优势。一个 Flash 级模型在金融工作流自动化上高出 6 分,并非四舍五入的误差。
这表明谷歌可能针对企业真实部署的那类工具调用、文档处理流水线对 3.5 Flash 进行了专项优化。
在针对科学图表视觉推理的 CharXiv Reasoning 上,Gemini 3.5 Flash 得分 84.2%,Opus 4.7 为 82.1%。差距不大,但值得注意的是,一款 Flash 级模型在视觉推理上领先旗舰,尤其考虑到视觉推理本是 Opus 4.7 的长项。
在测试计算机界面操控的 OSWorld 上,两者基本持平(78.4% vs 78.0%)。但有个重要前提:尽管有 OSWorld 分数(仅研究评测),Gemini 3.5 Flash 并不支持 Computer Use 功能。这意味着 分数衡量的是模型在基准条件下的潜在能力,但该版本并未(尚未?)开放或发布 Computer Use API 工具。
Opus 4.7 则支持 Computer Use,这一能力已被文档化,OSWorld-Verified 得分为 78.0%。如果您的工作流需要智能体自主点击、输入、在应用间导航,只有 Opus 4.7 可选。
Opus 4.7 还带来显著的视觉升级:图像长边最高 2,576 像素,是此前 Claude 模型分辨率的三倍多。这为读取高密度截图、提取复杂图表数据、以及需要像素级精度的计算机使用智能体打开了空间。XBOW 报告在切换到 Opus 4.7 后,其视觉敏锐度基准从 54.5% 跃升至 98.5%,可见分辨率提升在实际中的分量。
Gemini 3.5 Flash 可通过 Google AI Studio、Gemini API、Android Studio、Gemini Enterprise Agent Platform、Gemini Enterprise 与 Google Antigravity 获取。它也是 Gemini 应用与搜索 AI 模式的全球默认模型,意味着数十亿用户已在使用。对于已在 Google Cloud 生态中的开发者,集成路径非常直接。
Opus 4.7 可通过 Anthropic API、Amazon Bedrock、Google Cloud Vertex AI 与 Microsoft Foundry 使用,并在 Claude 的网页与移动端应用中提供。其模型 ID 为 claude-opus-4-7。Anthropic 还在 Opus 4.7 同步推出了任务预算公测,为开发者提供在长周期智能体运行中封顶 token 开销的手段。Claude Code 新增的 /ultrareview 斜杠命令可开启专门的审阅会话,标记缺陷与设计问题。
一个务实差别:Gemini 3.5 Flash 在多智能体工作上与 Antigravity harness 深度耦合,而 Opus 4.7 的任务预算与力度参数可跨任意编排方案使用。如果您构建在非 Antigravity 框架上,Opus 4.7 在管理长时智能体方面更灵活。
这一点颇有看头。Gemini 3.5 Flash 的价格为输入每百万 tokens $1.50、输出每百万 tokens $9.00。Claude Opus 4.7 的价格为输入每百万 tokens $5.00、输出每百万 tokens $25.00。按此计,Gemini 3.5 Flash 在输入上约便宜 3.3 倍,输出上约便宜 2.8 倍。
Opus 4.7 这边有个“隐性条款”。Anthropic 随 Opus 4.7 引入了新分词器,相比 Opus 4.6,对同一输入会多用 1.0x–1.35x 的 tokens。独立测试显示以英文为主的工作负载大约有 12–18% 的 token 膨胀。标价未变,但单次提示的有效成本上升。Anthropic 的建议是通过力度参数、任务预算与明确的简洁指令来控制。
对于高量级或低延迟敏感的工作负载,Gemini 3.5 Flash 在成本上是明确选择。若任务确需 Opus 4.7 的编码深度或 Computer Use 支持,则难以回避溢价。Anthropic 提供了提示缓存(缓存输入 tokens 节省最高 90%)与批处理(最高节省 50%)等成本控制手段,可在合适的负载模式下缩小差距。
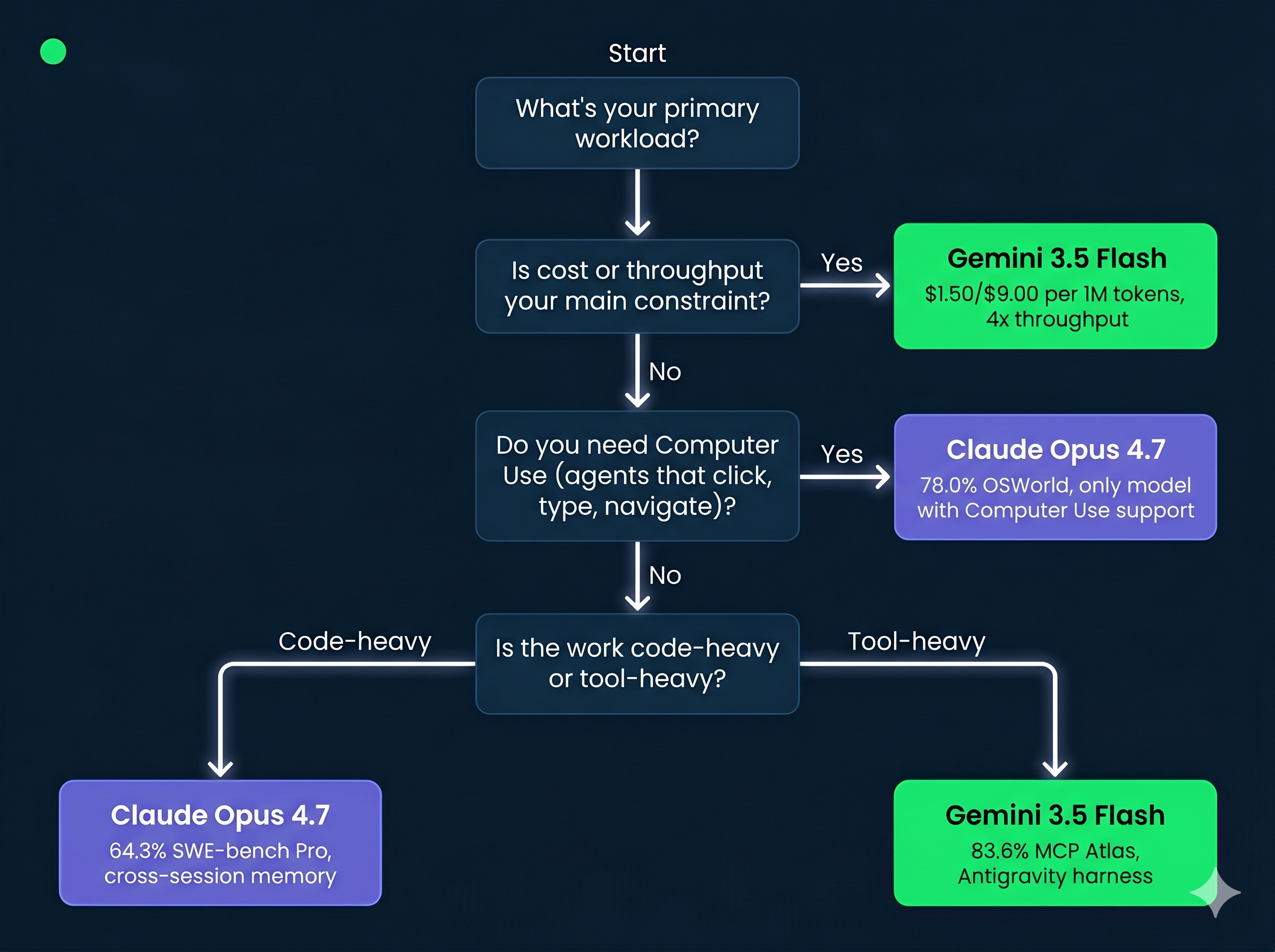
基准数据与功能差异已指向相对清晰的用例划分。我的决策框架如下。
| 用例 | 推荐 | 原因 |
|---|---|---|
| 高吞吐的智能体流水线且存在成本约束 | Gemini 3.5 Flash | 输出 tokens 约便宜 3 倍,且吞吐快 4 倍 |
| 仓库级软件工程 | Claude Opus 4.7 | SWE-bench Pro 64.3% vs 55.1%;在复杂多文件任务上更强 |
| 多工具的智能体编排 | Gemini 3.5 Flash | MCP Atlas 83.6% 领先于 Opus 4.7 的 77.3% |
| 计算机使用型智能体(点击、输入、应用导航) | Claude Opus 4.7 | 支持 Computer Use;Gemini 3.5 Flash 不支持 |
| 金融文档分析与工作流自动化 | Gemini 3.5 Flash | Finance Agent v2 以 57.9% 领先 51.5%;麦格理银行试点验证真实契合度 |
| 高分辨率图像与图表分析 | Claude Opus 4.7 | 支持最高 2,576px / 3.75MP;XBOW 视觉敏锐度基准达 98.5% |
| Google Cloud 或 Gemini 应用集成 | Gemini 3.5 Flash | 原生覆盖 Google AI Studio、Android Studio、Gemini Enterprise 与搜索 |
| 具跨会话记忆的长周期编码 | Claude Opus 4.7 | 基于文件系统的记忆在多会话中保留关键信息 |
实话说,这两款模型并不真正争夺同一类工作负载。Gemini 3.5 Flash 是一款 Flash 级模型,却在若干智能体基准上超越上一代 Pro 模型,且以足以支撑大规模部署的价格点达成。Claude Opus 4.7 则是旗舰,具备更深的编码能力、Computer Use 支持与更强的原始推理深度。若在两者间选择,通常取决于您是否需要 SWE-bench 级别的编码表现与 Computer Use,还是更需要吞吐、成本效率与强工具编排。
本次对比中最令我关注的是 Finance Agent v2 的结果。Gemini 3.5 Flash 在金融工作流自动化上以 57.9% 领先 Opus 4.7 的 51.5%,这并非人们对速度优化模型的直觉预期。叠加 MCP Atlas 的领先,这暗示谷歌对 3.5 Flash 进行了专门调优,面向企业真实运行的多步、工具调用、文档推理工作流,而不仅是追求原始基准分数。
还有一件值得关注的事:Gemini 3.5 Pro 预计下月发布。若它延续 3.5 Flash 的节奏、并在有意义幅度上超越 Gemini 3.1 Pro,那么与 Opus 4.7 的对比将大不相同。Pro 级定价可能缩小成本差距,但性能上限也会抬升。就目前而言,成本敏感的智能体工作更适合 Gemini 3.5 Flash,而深度编码与计算机使用更适合 Opus 4.7。
如果您想系统掌握智能体 AI 的实战技能,了解如何在生产中使用此类模型,建议查看 DataCamp 的 AI Agent Fundamentals 技能路径。
精选 Claude 与 Gemini 课程
Tracks
Courses
Courses