Track
Google Workspace with Gemini
4 hr
Here's a quick summary of how the two models compare across the dimensions that matter most for practitioners.
| Feature | Gemini 3.5 Flash | Claude Opus 4.7 |
|---|---|---|
| Tier | Speed-optimized (Flash) | Flagship |
| SWE-bench Pro | 55.1% | 64.3% |
| Terminal-bench 2.1 | 76.2% | 66.1% |
| MCP Atlas (tool use) | 83.6% | 77.3% |
| CharXiv Reasoning (multimodal) | 84.2% | 82.1% |
| Finance Agent v2 | 57.9% | 51.5% |
| OSWorld (computer use) | 78.4% | 78.0% |
| Humanity's Last Exam | 40.2% | 46.9% |
| ARC-AGI-2 (abstract reasoning) | 72.1% | 75.8% |
| Context window | 1M tokens | 1M tokens |
| Vision resolution | Not specified | Up to 2,576px / 3.75MP |
| Computer Use Support | Not supported | Supported (OSWorld: 78.0%) |
| API input pricing | $1.50 / 1M tokens | $5.00 / 1M tokens |
| API output pricing | $9.00 / 1M tokens | $25.00 / 1M tokens |
| Multi-agent framework | Antigravity harness | Task budgets + effort parameter |
This is the dimension where the two models diverge most clearly, although there is no clear winner across the board.
On SWE-bench Pro, the go-to coding benchmark, Opus 4.7 scores 64.3% versus Gemini 3.5 Flash's 55.1%. That's a meaningful gap in favor of repository-level engineering work for Claude. However, the picture turns on its head for Terminal-Bench 2.1, where Gemini 3.5 Flash scores 76.2%, ahead of Opus 4.7's 66.1% by about the same margin. For more terminal-heavy work, Gemini 3.5 Flash is the better choice.
| Benchmark | Gemini 3.5 Flash | Claude Opus 4.7 | Notes |
|---|---|---|---|
| SWE-bench Pro | 55.1% | 64.3% | Opus 4.7 leads by ~9pp |
| Terminal-Bench 2.1 | 76.2% | 66.1% | Gemini 3.5 shines at agentic terminal coding |
| MCP Atlas | 83.6% | 77.3% | Gemini 3.5 Flash leads on tool orchestration |
Both models are designed for long-horizon agentic tasks, but they approach it differently. Gemini 3.5 Flash is built around the Antigravity harness, which deploys collaborative subagents in parallel. Google's own example is synthesizing the AlphaZero paper and coding a fully playable game using two agents over six hours. Opus 4.7 uses task budgets and the new xhigh effort level to sustain performance across long runs, with Anthropic reporting that the model pushes through hard problems rather than stopping partway through.
Gemini 3.5 Flash leads on MCP Atlas at 83.6% versus Opus 4.7's 77.3%, which measures performance across complex multi-tool workflows. If your agentic system relies heavily on tool orchestration rather than deep code understanding, 3.5 Flash has a real edge.
For pure software engineering depth, Opus 4.7 is the stronger choice. For tool-heavy agentic pipelines where throughput and parallel subagent execution matter, Gemini 3.5 Flash is competitive and considerably cheaper.
Besides programming skills, general reasoning depth is the number one area where Opus 4.7 has the edge over Gemini 3.5 Flash. On Humanity's Last Exam, a collection of graduate-level questions across science, mathematics, and humanities, Opus 4.7 scores 46.9% without tools versus Gemini 3.5 Flash's 40.2%. The gap narrows on abstract reasoning: ARC-AGI-2 puts Flash at 72.1% and Opus 4.7 at 75.8%.
The more interesting signal is Finance Agent v2, where Gemini 3.5 Flash scores 57.9% versus Opus 4.7's 51.5%. This was the number that made me rethink the entire comparison. Going in, I assumed Opus 4.7 would lead on anything requiring multi-step reasoning over complex documents, as that's supposed to be the flagship advantage. A Flash-tier model beating it by 6 points on financial workflow automation is not a rounding error.
It suggests Google has specifically optimized 3.5 Flash for the kind of tool-calling, document-grinding pipelines that enterprises actually deploy.
On CharXiv Reasoning, which tests visual reasoning over scientific charts, Gemini 3.5 Flash scores 84.2% versus Opus 4.7's 82.1%. The gap is small, but it's notable that a Flash-tier model leads a flagship in visual reasoning, especially considering visual reasoning is one of Opus 4.7's strengths.
OSWorld, which tests computer interface control, is essentially tied (78.4% vs 78.0%). The important caveat: Gemini 3.5 Flash does not support computer use as a feature, despite the OSWorld score, which is a research evaluation only. That means it measures what the model can do in benchmark conditions, but the Computer Use API tool is simply not (yet?) exposed or shipped for this model version.
Opus 4.7 does support Computer Use, and it's a documented capability with a 78.0% OSWorld-Verified score. If your workflow involves agents that click, type, and navigate applications autonomously, Opus 4.7 is the only option here.
Opus 4.7 also introduced a significant vision upgrade: images up to 2,576 pixels on the long edge, which is more than three times the resolution of prior Claude models. This opens up use cases like reading dense screenshots, extracting data from complex diagrams, and computer-use agents that need pixel-level accuracy. XBOW reported a jump from 54.5% to 98.5% on their visual-acuity benchmark after switching to Opus 4.7, which gives a sense of how much the resolution increase matters in practice.
Gemini 3.5 Flash is available through Google AI Studio, the Gemini API, Android Studio, Gemini Enterprise Agent Platform, Gemini Enterprise, and Google Antigravity. It's also the default model in the Gemini app and AI Mode in Search globally, which means billions of users are already running it. For developers already in the Google Cloud ecosystem, the integration path is straightforward.
Opus 4.7 is available through the Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry, as well as Claude's own web and mobile apps. The model ID is claude-opus-4-7. Anthropic has also launched task budgets in public beta alongside Opus 4.7, giving developers a way to cap token spend across long agentic runs. The new /ultrareview slash command in Claude Code produces a dedicated review session that flags bugs and design issues.
One practical difference: Gemini 3.5 Flash is tightly coupled to the Antigravity harness for multi-agent work, while Opus 4.7's task budgets and effort parameter work across any orchestration setup. If you're building on a framework that isn't Antigravity, Opus 4.7 gives you more flexibility in how you manage long-running agents.
This is where the comparison gets interesting. Gemini 3.5 Flash costs $1.50 per million input tokens and $9.00 per million output tokens. Claude Opus 4.7 costs $5.00 per million input tokens and $25.00 per million output tokens. At those rates, Gemini 3.5 Flash is roughly 3.3x cheaper on input and 2.8x cheaper on output.
There's a catch on the Opus 4.7 side. Anthropic introduced a new tokenizer with Opus 4.7 that uses between 1.0x and 1.35x more tokens for the same input compared to Opus 4.6. English-heavy workloads see roughly 12-18% token inflation in independent tests. The list price didn't change, but the effective cost per prompt did. Anthropic's guidance is to use the effort parameter, task budgets, and explicit brevity instructions to manage this.
For high-volume or latency-sensitive workloads, Gemini 3.5 Flash is the clear choice in terms of cost. For workloads where Opus 4.7's coding depth or Computer Use support is genuinely needed, the price premium is harder to avoid. Anthropic does offer prompt caching (up to 90% savings on cached input tokens) and batch processing (up to 50% savings) as cost controls, which can close the gap for the right workload patterns.
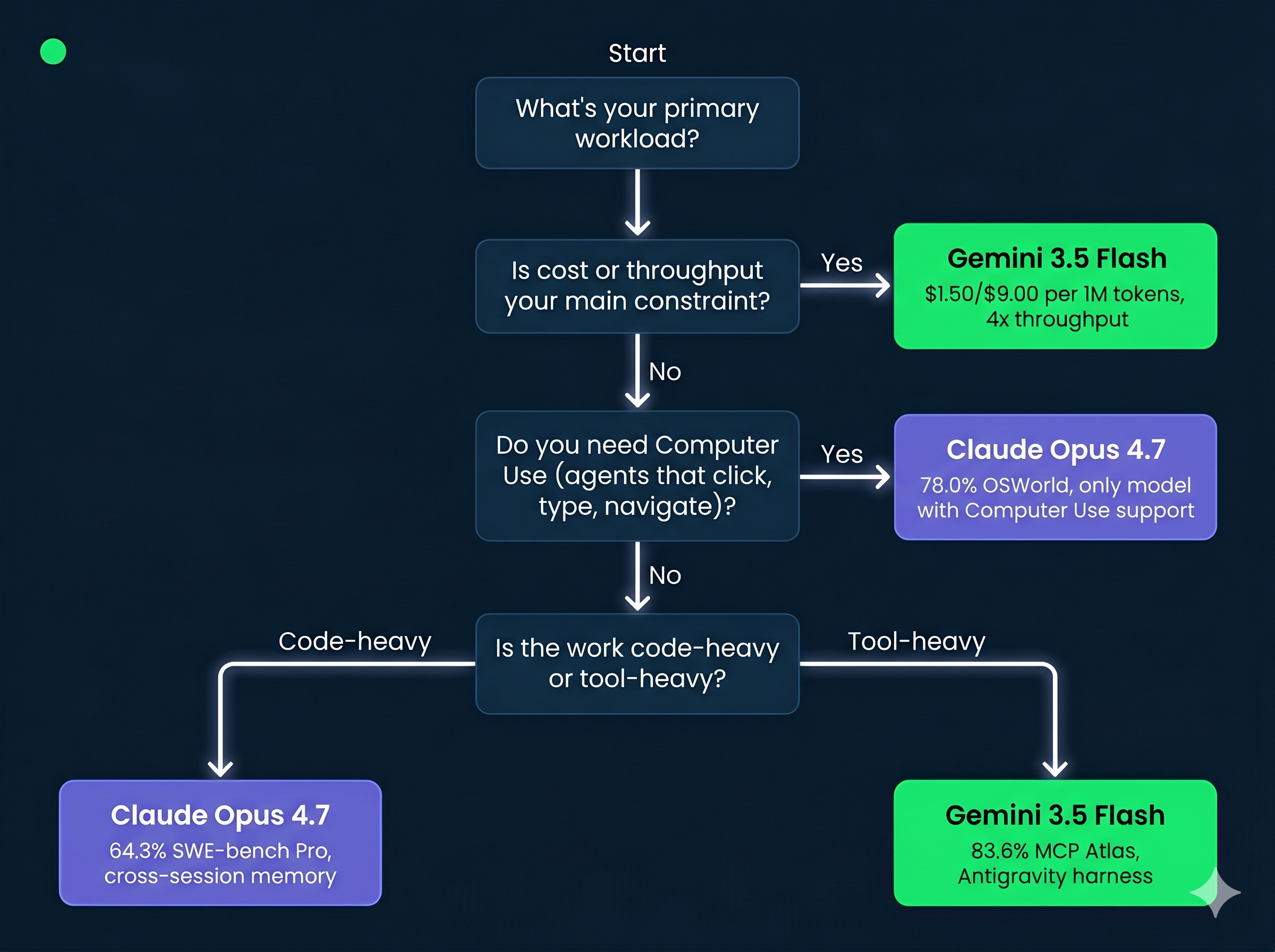
The benchmark data and feature differences point to fairly clear use-case splits. Here's how I'd frame the decision.
| Use case | Recommended | Why |
|---|---|---|
| High-volume agentic pipelines with cost constraints | Gemini 3.5 Flash | 3x cheaper on output tokens and 4x faster throughput |
| Repository-level software engineering | Claude Opus 4.7 | 64.3% vs 55.1% on SWE-bench Pro; stronger on complex multi-file tasks |
| Multi-tool agentic orchestration | Gemini 3.5 Flash | Leads MCP Atlas at 83.6% vs Opus 4.7's 77.3% |
| Computer use agents (clicking, typing, navigating apps) | Claude Opus 4.7 | Computer Use is supported; Gemini 3.5 Flash does not support it |
| Financial document analysis and workflow automation | Gemini 3.5 Flash | Leads Finance Agent v2 at 57.9% vs 51.5%; Macquarie Bank pilot confirms real-world fit |
| High-resolution image and diagram analysis | Claude Opus 4.7 | Supports images up to 2,576px / 3.75MP; XBOW reported 98.5% on visual-acuity benchmark |
| Google Cloud or Gemini app integration | Gemini 3.5 Flash | Native integration across Google AI Studio, Android Studio, Gemini Enterprise, and Search |
| Long-horizon coding with cross-session memory | Claude Opus 4.7 | File system-based memory persists important notes across multi-session work |
The honest summary is that these two models are not really competing for the same workloads. Gemini 3.5 Flash is a Flash-tier model that happens to beat a previous-generation Pro model on several agentic benchmarks, and it does so at a price point that makes high-volume deployment practical. Claude Opus 4.7 is a flagship model with deeper coding ability, Computer Use support, and better raw reasoning depth. If you're choosing between them, the decision usually comes down to whether you need SWE-bench-level coding performance and Computer Use, or whether you need throughput, cost efficiency, and strong tool orchestration.
What I find most interesting about this comparison is the Finance Agent v2 result. Gemini 3.5 Flash scoring 57.9% versus Opus 4.7's 51.5% on financial workflow automation is not what you'd expect from a speed-optimized model. Combined with the MCP Atlas lead, it suggests Google has specifically tuned 3.5 Flash for the kind of multi-step, tool-calling, document-reasoning workflows that enterprises actually run, not just for raw benchmark performance.
One thing worth watching: Gemini 3.5 Pro is expected to drop next month. If it follows the pattern of the 3.5 Flash launch and outperforms Gemini 3.1 Pro by a meaningful margin, the comparison with Opus 4.7 will look quite different. Pro-tier pricing will likely close the cost gap, but the performance ceiling should rise. For now, Gemini 3.5 Flash is the better choice for cost-sensitive agentic work, and Opus 4.7 is the better choice for deep coding and computer use.
If you want to build practical skills with agentic AI systems and understand how to work with models like these in production, I recommend checking out the AI Agent Fundamentals skill track on DataCamp.
Top Claude and Gemini Courses
Track
Course
Course
blog
Matt Crabtree
8 min
blog
Khalid Abdelaty
11 min
blog
Derrick Mwiti
10 min
blog
Josef Waples
9 min
blog
Tom Farnschläder
11 min
Tutorial
François Aubry