Las incrustaciones de texto son una herramienta esencial en el campo del procesamiento del lenguaje natural (PLN). Son representaciones numéricas del texto en las que cada palabra o frase se representa como un vector denso de números reales.
La gran ventaja de estas incrustaciones es su capacidad para captar significados semánticos y relaciones entre palabras o frases, lo que permite a las máquinas comprender y procesar el lenguaje humano con eficacia.
Las incrustaciones de texto son cruciales en escenarios como la clasificación de textos, la recuperación de información y la detección de similitudes semánticas.
OpenAI, conocida por sus notables contribuciones al campo de la inteligencia artificial, recomienda actualmente utilizar el modelo Ada V2 para crear incrustaciones de texto. Este modelo se deriva de la serie de modelos GPT y se ha entrenado para captar aún mejor el significado contextual y las asociaciones presentes en el texto.
Si no estás familiarizado con la API de OpenAI o con el paquete openai Python, es recomendable que leas Usando GPT-3.5 y GPT-4 a través de la API de OpenAI en Python antes de continuar. Esta guía le ayudará a configurar las cuentas y a comprender las ventajas del uso de la API.
Este tutorial también incluye el uso del clustering, una técnica de aprendizaje automático utilizada para agrupar instancias similares. Si no está familiarizado con el clustering, en particular con el clustering k-Means, debería considerar la lectura de Introducción al clustering k-Means con scikit-learn en Python.
¿Para qué se pueden utilizar las incrustaciones de texto?
Las incrustaciones de texto pueden aplicarse a múltiples casos de uso, entre ellos:
- Clasificación del texto. Las incrustaciones de texto ayudan a crear modelos precisos para el análisis de sentimientos o las tareas de identificación de temas.
- Recuperación de información. Se pueden utilizar para recuperar información relevante para una consulta específica, de forma similar a lo que podemos encontrar en un motor de búsqueda.
- Detección de similitudes semánticas. Las incrustaciones pueden identificar y cuantificar la similitud semántica entre fragmentos de texto.
- Sistemas de recomendación. Pueden mejorar la calidad de las recomendaciones entendiendo las preferencias del usuario a partir de su interacción con los datos textuales.
- Generación de texto. Las incrustaciones se utilizan para generar textos más coherentes y contextualmente relevantes.
- Traducción automática. Las incrustaciones de texto pueden captar significados semánticos en distintos idiomas, lo que puede mejorar la calidad del proceso de traducción automática.
Puesta en marcha
Para trabajar con incrustaciones de texto se necesitan varios paquetes de Python, que se describen a continuación:
- os: Una biblioteca Python integrada para interactuar con el sistema operativo.
- openai: el cliente Python para interactuar con la API OpenAI.
- scipy.spatial.distance: proporciona funciones para calcular la distancia entre diferentes puntos de datos.
- sklean.cluster.KMeans: se utiliza para calcular la agrupación KMeans.
- umap.UMAP: técnica utilizada para reducir la dimensionalidad de los datos de alta dimensión.
Antes de utilizarlos, asegúrese de instalar openai, scipy, plotly sklearn, y umap con el siguiente comando. El código completo está disponible en este cuaderno de DataLab.
pip install -U openai, scipy, plotly-express, scikit-learn, umap-learnUna vez ejecutado con éxito el comando anterior, se pueden importar todas las bibliotecas de la siguiente manera:
import os
import openai
from scipy.spatial import distance
import plotly.express as px
from sklearn.cluster import KMeans
from umap import UMAPAhora podemos configurar la clave API de OpenAI de la siguiente manera:
openai.api_key = "<YOUR_API_KEY_HERE>"Nota: Tendrá que configurar su propia CLAVE API. La del código fuente no está disponible y era sólo para uso individual.
Patrón de código para llamar a GPT a través de la API
La siguiente función de ayuda se puede utilizar para incrustar una línea de texto utilizando la API OpenAI. En el código, utilizamos la versión 2 de ada para generar las incrustaciones.
def get_embedding(text_to_embed):
# Embed a line of text
response = openai.Embedding.create(
model= "text-embedding-ada-002",
input=[text_to_embed]
)
# Extract the AI output embedding as a list of floats
embedding = response["data"][0]["embedding"]
return embeddingAcerca del conjunto de datos
En esta sección, consideraremos los datos de revisión de instrumentos musicales de Amazon disponibles gratuitamente en Kaggle. Los datos también pueden descargarse de mi cuenta de Github de la siguiente manera:
import pandas as pd
data_URL = "https://raw.githubusercontent.com/keitazoumana/Experimentation-Data/main/Musical_instruments_reviews.csv"
review_df = pd.read_csv(data_URL)
review_df.head()
De todas las columnas, sólo nos interesa la columna reviewText .
review_df = review_df[['reviewText']]
print("Data shape: {}".format(review_df.shape))
display(review_df.head())Data shape: (10261, 1)
Hay muchas reseñas en el conjunto de datos. Para optimizar los costes, sólo utilizaremos 100 filas seleccionadas aleatoriamente.

Ahora, podemos generar las incrustaciones para cada fila del conjunto de datos aplicando la función anterior mediante la expresión lambda:
review_df = review_df.sample(100)
review_df["embedding"] = review_df["reviewText"].astype(str).apply(get_embedding)
# Make the index start from 0
review_df.reset_index(drop=True)
review_df.head(10)
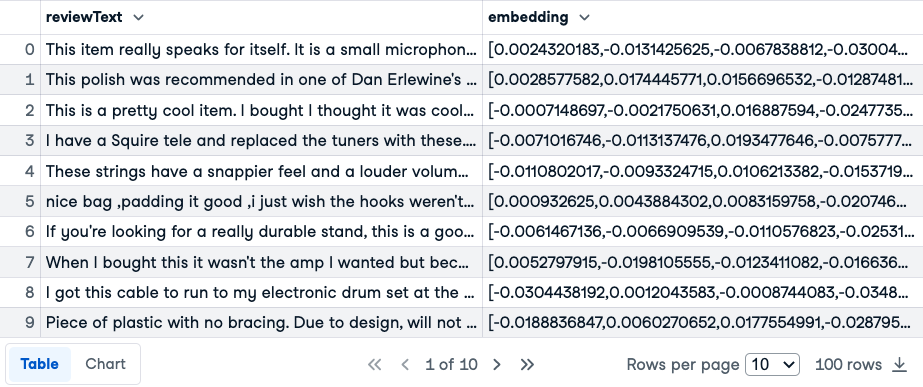
Primeras 10 filas de las reseñas y emdeddings
Comprender la similitud de los textos
Para mostrar el concepto de similitud semántica, consideremos dos reseñas que podrían tener sentimientos similares:
"¡Este producto es fantástico!"
"¡Realmente superó mis expectativas!"
Utilizando pdist() de scipy.spatial.distance, podemos calcular la distancia euclidiana entre sus incrustaciones.
La distancia euclidiana corresponde a la raíz cuadrada de la suma de la diferencia al cuadrado entre las dos incrustaciones, y a continuación se ofrece una ilustración:
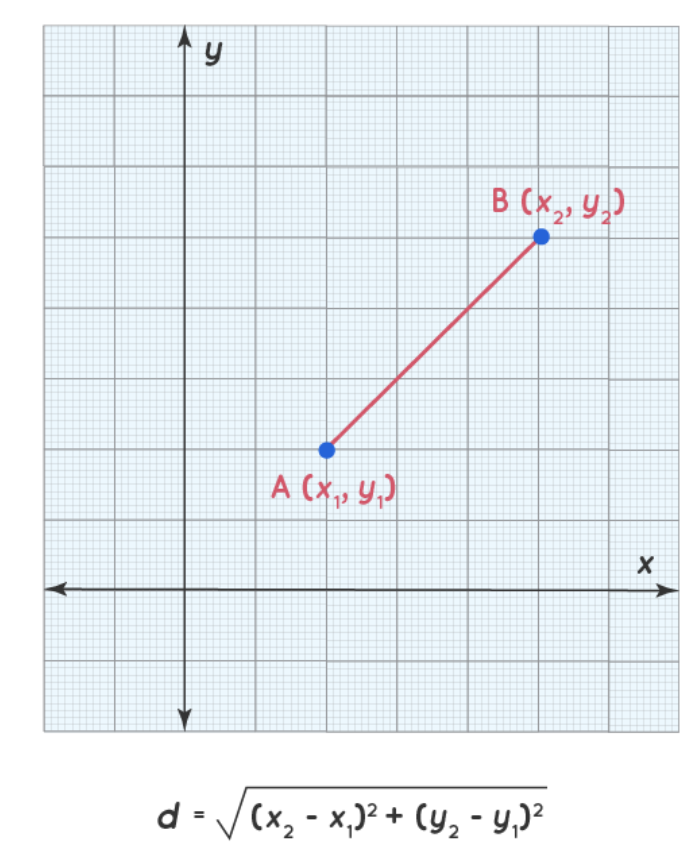
Ilustración de la distancia euclidiana(fuente)
Si estas revisiones son realmente similares, la distancia debería ser relativamente pequeña.
A continuación, considere dos revisiones diferentes:
"¡Este producto es fantástico!"
"No estoy satisfecho con el artículo".
La distancia entre las incrustaciones de estas reseñas será significativamente mayor que la distancia entre las reseñas similares.
Estudio de caso: Utilizar la incrustación de texto para el análisis de conglomerados
Las incrustaciones de texto que hemos generado pueden utilizarse para realizar análisis de conglomerados, de forma que los instrumentos musicales más parecidos entre sí puedan agruparse.
Existen múltiples algoritmos de clustering como K-Means, DBSCAN, clustering jerárquico y Modelos de Mezclas Gaussianas. En este caso concreto, utilizaremos la agrupación KMeans. Sin embargo, nuestra Introducción al Clustering Jerárquico en Py thon proporciona un buen marco para entender los entresijos del clustering jerárquico y su implementación en Python.
Agrupar los datos de texto
El uso del clustering K-means requiere predefinir el número de clusters a utilizar, y estableceremos ese número a 3 con el parámetro n_clusters de la siguiente manera:
kmeans = KMeans(n_clusters=3)
kmeans.fit(review_df["embedding"].tolist())Reducir las dimensiones de los datos de texto incrustados
Los humanos sólo somos capaces de visualizar hasta tres dimensiones. En esta sección se utilizará el UMAP, una herramienta relativamente rápida y escalable para realizar la reducción de dimensionalidad.
En primer lugar, definimos una instancia de la clase UMAP y aplicamos la función fit_transform a las incrustaciones, lo que genera una representación bidimensional de la incrustación de las revisiones que puede representarse gráficamente.
reducer = UMAP()
embeddings_2d = reducer.fit_transform(review_df["embedding"].tolist())Visualizar las agrupaciones
Por último, crea un gráfico de dispersión de las incrustaciones bidimensionales. Las coordenadas x e y se toman respectivamente de embeddings_2d[: , 0] y embeddings_2d[: , 1]
Las agrupaciones serán visualmente distintas:
fig = px.scatter(x=embeddings_2d[:, 0], y=embeddings_2d[:, 1], color=kmeans.labels_)
fig.show()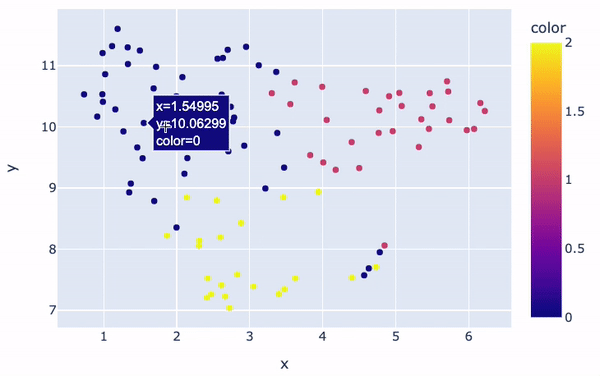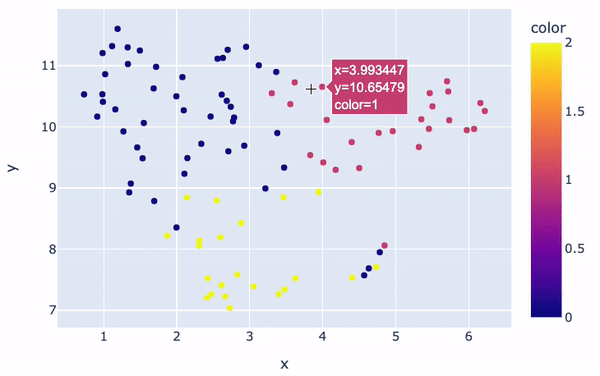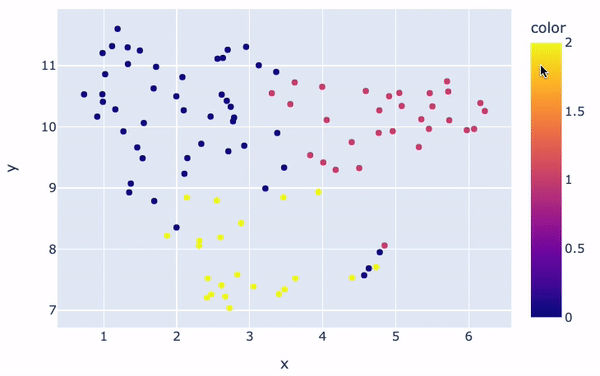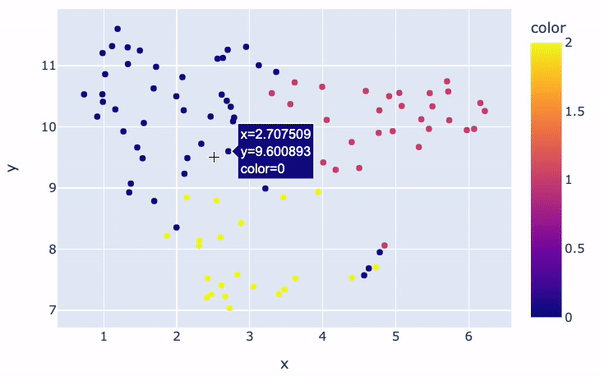
Visualización de clusters
En general, hay tres grupos principales con colores diferentes. El color de cada reseña en la figura viene determinado por la etiqueta/número de clúster que le asigna el modelo K-Means. Además, la posición de cada punto ofrece una representación visual de la similitud entre una determinada revisión y las demás.
Pase al siguiente nivel
Para profundizar en el conocimiento de las incrustaciones de texto y la API OpenAI, considere el siguiente material de DataCamp: Ajuste fino de GPT-3 mediante la API de OpenAIy Python y La API de OpenAI en Python Cheat Sheet. Le ayuda a liberar todo el potencial de GPT-3 a través del ajuste fino y también ilustra cómo utilizar la API de OpenAI y Python para mejorar este modelo de red neuronal avanzada para su caso de uso específico.





