Curso
Trabajo con datos geoespaciales en Python
4 h
17.7K
El aumento de datos es una técnica que consiste en aumentar artificialmente el conjunto de entrenamiento creando copias modificadas de un conjunto de datos utilizando los datos existentes. Incluye realizar pequeños cambios en el conjunto de datos o utilizar el aprendizaje profundo para generar nuevos puntos de datos.
Los datos aumentados se obtienen a partir de los datos originales con algunos cambios menores. En el caso del aumento de imágenes, realizamos transformaciones geométricas y del espacio de color (flipping, cambio de tamaño, recorte, brillo, contraste) para aumentar el tamaño y la diversidad del conjunto de entrenamiento.
Los datos sintéticos se generan artificialmente sin utilizar el conjunto de datos original. A menudo se utilizan redes neuronales profundas (DNN) y redes generativas adversativas (GAN) para generar datos sintéticos.
Nota: Las técnicas de aumento no se limitan a las imágenes. También puedes aumentar audio, vídeo, texto y otros tipos de datos.
En esta sección, aprenderemos sobre técnicas de aumento de datos de audio, datos de texto, datos de imagen y datos avanzados.
Aprende más sobre la transformación y manipulación de imágenes con ejercicios prácticos en nuestro programa de habilidades Procesamiento de imágenes con Python.
El aumento de datos puede aplicarse a todas las aplicaciones de machine learning en las que adquirir datos de calidad es un reto. Además, puede ayudar a mejorar la solidez y el rendimiento de los modelos en todos los campos de estudio.
Adquirir y etiquetar conjuntos de datos de imágenes médicas lleva mucho tiempo y es caro. También es necesario que un experto en la materia valide el conjunto de datos antes de realizar el análisis de datos. Utilizar transformaciones geométricas y de otro tipo puede ayudarte a entrenar modelos de machine learning robustos y exactos.
Por ejemplo, en el caso de la clasificación de la pulmonía, puedes utilizar recorte, zoom, estiramiento y transformación del espacio de color aleatorios para mejorar el rendimiento del modelo. Sin embargo, debes tener cuidado con ciertos aumentos, ya que pueden producir resultados opuestos. Por ejemplo, la rotación y la reflexión a lo largo del eje x aleatorias no son recomendables para el conjunto de datos de imágenes de rayos X.
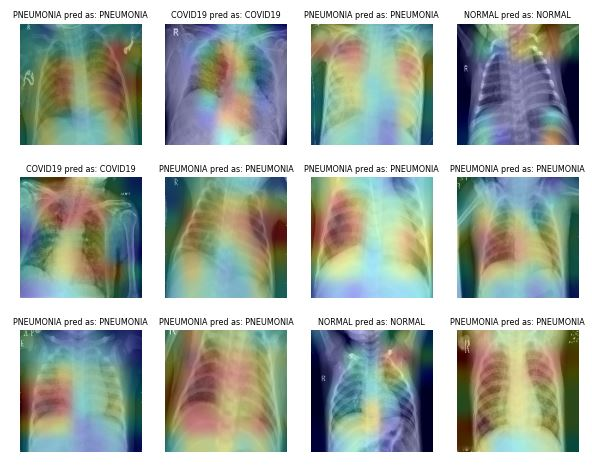
Imagen de ibrahimsobh.github.io | kaggle-COVID19-Classification
Los datos disponibles sobre los vehículos autoconducidos son limitados, y las empresas utilizan entornos simulados para generar datos sintéticos mediante el aprendizaje por refuerzo. Puede ayudarte a entrenar y probar aplicaciones de machine learning en las que la seguridad de los datos es un problema.

Imagen de David Silver | Autonomous Visualization System de Uber ATG
Las posibilidades de los datos aumentados como simulación son infinitas, ya que pueden utilizarse para generar situaciones del mundo real.
El aumento de datos textuales se utiliza generalmente en situaciones con datos de calidad limitada en las que la mejora de la métrica de rendimiento tiene prioridad. Puedes aplicar el aumento de sinónimos, el encaje léxico, el intercambio de caracteres y la inserción y eliminación aleatorias. Estas técnicas también son valiosas para las lenguas con pocos recursos.
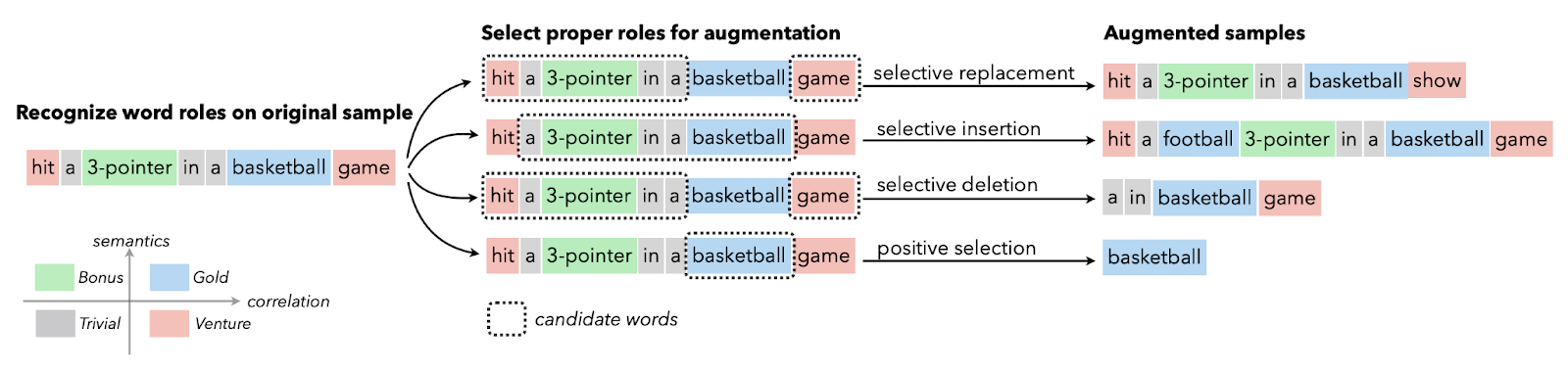
Imagen de Papers With Code | Aumento selectivo del texto con roles de palabras para la clasificación de textos con pocos recursos.
Los investigadores utilizan el aumento de texto para los modelos lingüísticos en casos de reconocimiento, generación de datos secuencia a secuencia y clasificación de textos con muchos errores.
En la clasificación de sonidos y el reconocimiento del habla, el aumento de datos hace maravillas. Mejora el rendimiento del modelo incluso en lenguas con pocos recursos.
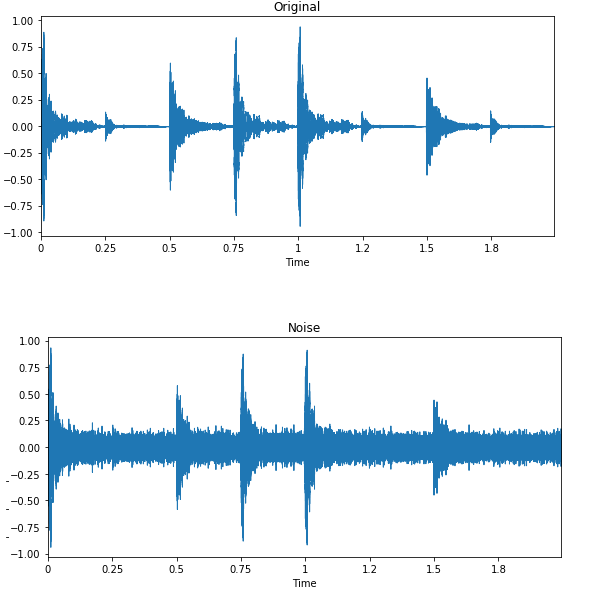
Imagen de Edward Ma | Inyección de ruido
La inyección de ruido, el desplazamiento y el cambio de tono aleatorios pueden ayudarte a producir modelos de voz a texto de última generación. También puedes utilizar GAN para generar sonidos realistas para una aplicación concreta.
En este tutorial, vamos a aprender a aumentar datos de imagen utilizando Keras y Tensorflow. Además, aprenderás a utilizar tus datos aumentados para entrenar un clasificador binario sencillo. El código que se menciona a continuación es la versión modificada del ejemplo oficial de TensorFlow.
Te recomendamos que sigas el tutorial de programación practicando por tu cuenta. El código fuente con los resultados está disponible en DataCamp Workspace.
Utilizaremos TensorFlow y Keras para aumentar los datos y matplotlib para mostrar las imágenes.
%%capture
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from keras import layers
import kerasLa colección Conjunto de datos TensorFlow es enorme. Tienes conjuntos de datos de texto, audio, vídeo, gráficos, series temporales e imágenes. En este tutorial, utilizaremos el conjunto de datos "cats_vs_dogs". El tamaño del conjunto de datos es de 786,68 MiB, y aplicaremos diferentes aumentos de imagen y entrenaremos el clasificador binario.
En el código siguiente, hemos cargado un 80 % de conjunto de entrenamiento, un 10 % de conjunto de validación y un 10 % de conjunto de prueba con etiquetas y metadatos.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)Hay dos clases en el conjunto de datos: "cat" y "dog".
num_classes = metadata.features['label'].num_classes
print(num_classes)2Utilizaremos iteradores para extraer solo cuatro imágenes aleatorias con etiquetas del conjunto de entrenamiento y mostrarlas mediante la función de matplotlib `.imshow()`.
get_label_name = metadata.features['label'].int2str
train_iter = iter(train_ds)
fig = plt.figure(figsize=(7, 8))
for x in range(4):
image, label = next(train_iter)
fig.add_subplot(1, 4, x+1)
plt.imshow(image)
plt.axis('off')
plt.title(get_label_name(label));Como podemos ver, tenemos diferentes imágenes de perros y una imagen de gato.

Normalmente utilizamos keras.Sequential() para crear el modelo, pero también podemos utilizarlo para añadir capas de aumento.
En el ejemplo, redimensionamos y reescalamos la imagen utilizando Keras Sequential y capas de aumento de imagen. Primero redimensionaremos la imagen a 180 × 180 y luego la reescalaremos en 1/255. El pequeño tamaño de la imagen nos ayudará a ahorrar tiempo, memoria y computación.
Como podemos ver, hemos pasado correctamente la imagen por la capa de aumento, y el resultado final está redimensionado y reescalado.
IMG_SIZE = 180
resize_and_rescale = keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
result = resize_and_rescale(image)
plt.axis('off')
plt.imshow(result);
1
Apliquemos flip y rotación aleatorios a la misma imagen. Utilizaremos loop, subplot e imshow para mostrar seis imágenes con aumento geométrico aleatorio.
data_augmentation = keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.4),
])
plt.figure(figsize=(8, 7))
for i in range(6):
augmented_image = data_augmentation(image)
ax = plt.subplot(2, 3, i + 1)
plt.imshow(augmented_image.numpy()/255)
plt.axis("off")Nota: Si ves "WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers.", intenta convertir tu imagen a numpy y dividirla entre 255. Te mostrará el resultado claro en lugar de una imagen desvaída.

Además del simple aumento, también puedes aplicar a las imágenes RandomContrast, RandomCrop, HeightCrop, WidthCrop y RandomZoom.
Hay dos formas de aplicar el aumento a las imágenes. El primer método consiste en añadir directamente las capas de aumento al modelo.
model = keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
# Add the model layers
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1,activation='sigmoid')
])Nota: El aumento de datos está inactivo durante la fase de prueba. Solo funcionará para Model.fit, no para Model.evaluate ni Model.predict.
El segundo método consiste en aplicar el aumento de datos a todo el conjunto de entrenamiento mediante Dataset.map.
aug_ds = train_ds.map(lambda x, y: (data_augmentation(x, training=True), y))Crearemos una función de preprocesamiento de datos para procesar los conjuntos de entrenamiento, validación y prueba.
La función hará lo siguiente:
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)Crearemos un modelo sencillo con capas convolucionales y densas. Asegúrate de que la forma de entrada es similar a la forma de la imagen.
model = keras.Sequential([
layers.Conv2D(32, (3, 3), input_shape=(180,180,3), padding='same', activation='relu'),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dense(32, activation='relu'),
layers.Dense(1,activation='softmax')
])Ahora compilaremos el modelo y lo entrenaremos durante una época. El optimizador es Adam, la función de pérdida es Binary Cross Entropy y la métrica es la exactitud.
Como podemos observar, obtuvimos un 51 % de exactitud de validación en la única ejecución. Puedes entrenarlo durante varias épocas y optimizar los hiperparámetros para obtener resultados aún mejores.
La parte de creación y entrenamiento del modelo es solo para darte una idea de cómo puedes aumentar las imágenes y entrenar el modelo.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs=1
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)582/582 [==============================] - 98s 147ms/step - loss: 0.6993 - accuracy: 0.4961 - val_loss: 0.6934 - val_accuracy: 0.5185loss, acc = model.evaluate(test_ds)73/73 [==============================] - 4s 48ms/step - loss: 0.6932 - accuracy: 0.5013Aprende a realizar análisis de imágenes y a crear, entrenar y evaluar redes convolucionales realizando el curso Procesamiento de imágenes con Keras.
En esta sección, aprenderemos a aumentar imágenes utilizando TensorFlow para tener un control más fino del aumento de datos.
Cargaremos de nuevo el conjunto de datos cats_vs_dogs con etiquetas y metadatos.
%%capture
(train_ds, val_ds, test_ds), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)En lugar de la imagen de un gato, utilizaremos la imagen de un perro y aplicaremos diversas técnicas de aumento.
image, label = next(iter(train_ds))
plt.imshow(image)
plt.title(get_label_name(label));
1
Crearemos la función visualize para mostrar la diferencia entre la imagen original y la aumentada.
La función es bastante sencilla. Toma la imagen original y la función de aumento como entrada y muestra la diferencia utilizando matplotlib.
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.axis("off")
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
plt.axis("off")Como podemos ver, hemos aplicado flip a la imagen de izquierda a derecha utilizando la función tf.image. Es mucho más sencillo que keras.Sequential.
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
1
Vamos a convertir la imagen a escala de grises utilizando `tf.image.rgb_to_grayscale`.
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
1
También puedes ajustar la saturación en un factor de 3.
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
1
Ajusta el brillo proporcionando un factor de brillo.
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
1
Recorta la imagen desde el centro utilizando una fracción central de 0,5.
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
1
Haz rotar la imagen 90 grados utilizando la función `tf.image.rot90`.
rotated = tf.image.rot90(image)
visualize(image, rotated)
1
Igual que las capas Keras, tf.image también tiene funciones de aumento aleatorio. En el ejemplo siguiente, aplicaremos el brillo aleatorio a la imagen y mostraremos varios resultados.
Como podemos ver, la primera imagen es un poco más oscura, y las dos siguientes son más brillantes.
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)


Igual que keras, podemos aplicar una función de aumento de datos a todo el conjunto de datos mediante Dataset.map.
def augment(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
image = tf.image.random_crop(image, size=[IMG_SIZE, IMG_SIZE, 3])
image = tf.image.random_brightness(image, max_delta=0.5)
return image, label
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)Keras ImageDataGenerator es aún más sencillo. Su funcionamiento es óptimo cuando cargas datos desde un directorio local o CSV.
En el ejemplo, descargaremos y cargaremos un pequeño conjunto de datos CIFAR10 de la biblioteca de conjuntos de datos por defecto de Keras.
Después, aplicaremos el aumento utilizando `keras.preprocessing.image.ImageDataGenerator`. La función hará rotar las imágenes, cambiará su altura y su anchura y les aplicará flip horizontal aleatoriament.
Por último, ajustaremos ImageDataGenerator al conjunto de datos de entrenamiento y mostraremos seis imágenes con aumento aleatorio.
Nota: El tamaño de la imagen es 32 × 32, por lo que tenemos una pantalla de baja resolución.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
datagen = keras.preprocessing.image.ImageDataGenerator(rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.2)
datagen.fit(x_train)
for X_batch, y_batch in datagen.flow(x_train,y_train, batch_size=6):
for i in range(0, 6):
plt.subplot(2,3,i+1)
plt.imshow(X_batch[i]/255)
plt.axis('off')
break
En esta sección, conoceremos otras herramientas de código abierto que puedes utilizar para aplicar diversas técnicas de aumento de datos y mejorar el rendimiento del modelo.
La transformación de imágenes está disponible en el módulo torchvision.transforms. De forma similar a Keras, puedes añadir capas de transformación en torch.nn.Sequential o aplicar una función de aumento por separado en el conjunto de datos.
Augmentor es un paquete Python para el aumento de imágenes y la generación de imágenes artificiales. Puedes ejecutar Perspective Skewing, Elastic Distortions, Rotating, Shearing, Cropping y Mirroring. Augmentor también incluye funciones básicas de preprocesamiento de imágenes.
Albumentations es una herramienta Python rápida y flexible para el aumento de imágenes. Se utiliza ampliamente en competiciones de machine learning, en el sector y en la investigación para mejorar el rendimiento de las redes neuronales convolucionales profundas.
Imgaug es una herramienta de código abierto para el aumento de imágenes. Admite una gran variedad de técnicas de aumento, como ruido gaussiano, contraste, nitidez, recorte, affine y flip. Tiene una interfaz estocástica sencilla pero potente, e incluye puntos clave, cuadros delimitadores, mapas de calor y mapas de segmentación.
OpenCV es una biblioteca masiva de código abierto para visión artificial, machine learning y procesamiento de imágenes. Se utiliza generalmente en la creación de aplicaciones en tiempo real. Puedes utilizar OpenCV para aumentar imágenes y vídeos sin problemas.
Las funciones de aumento de imagen proporcionadas por Tensorflow y Keras son prácticas. Solo tienes que añadir una capa de aumento, tf.image o ImageDataGenerator para realizar el aumento. Aparte de los marcos de aprendizaje profundo, puedes utilizar herramientas independientes como Augmentor, Albumentations, OpenCV e Imgaug para realizar el aumento de datos.
En este tutorial, hemos aprendido las ventajas, limitaciones, aplicaciones y técnicas del aumento de datos. Además, hemos aprendido a aplicar el aumento de imágenes en el conjunto de datos cats vs. dog utilizando Keras y Tensorflow. Si estás interesado en aprender más sobre el procesamiento de imágenes, consulta el programa de habilidades Procesamiento de imágenes con Python. Te enseñará los fundamentos de la transformación y manipulación de imágenes, el análisis de imágenes médicas y el procesamiento avanzado de imágenes con Keras.
Principales cursos
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
Tutorial
Moez Ali
Tutorial
Bekhruz Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Joanne Xiong