Curso
Introducción a Python
4 h
6.9M

Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoSi quieres aprender más en Python, sigue el curso gratuito Introducción a Python para la Ciencia de Datos de DataCamp.
Todos habéis visto conjuntos de datos. A veces son pequeños, pero a menudo, en ocasiones, tienen un tamaño tremendamente grande. Resulta muy difícil procesar los conjuntos de datos que son muy grandes, al menos lo suficiente como para provocar un cuello de botella en el procesamiento.
Entonces, ¿qué hace que estos conjuntos de datos sean tan grandes? Bueno, son características. Cuanto mayor sea el número de características, mayores serán los conjuntos de datos. Bueno, no siempre. Encontrarás conjuntos de datos en los que el número de características es muy elevado, pero no contienen tantas instancias. Pero ése no es el tema de debate aquí. Así que te preguntarás, con un ordenador básico en la mano, cómo procesar este tipo de conjuntos de datos sin andarte por las ramas.
A menudo, en un conjunto de datos de alta dimensión, quedan algunas características totalmente irrelevantes, insignificantes y sin importancia. Se ha visto que la contribución de este tipo de rasgos suele ser menor al modelado predictivo que la de los rasgos críticos. También pueden tener contribución cero. Estas características causan una serie de problemas que, a su vez, impiden el proceso de modelización predictiva eficaz -
Entonces, ¿cuál es la solución? La solución más económica es la Selección de rasgos.
La selección de características es el proceso de seleccionar las características más significativas de un conjunto de datos dado. En muchos casos, la selección de características también puede mejorar el rendimiento de un modelo de aprendizaje automático.
Suena interesante, ¿verdad?
Obtuviste una introducción informal a la Selección de Características y su importancia en el mundo de la Ciencia de Datos y el Aprendizaje Automático. En este post vas a cubrir:
La selección de características también se conoce como selección de variables o selección de atributos.
Esencialmente, es el proceso de seleccionar lo más importante/relevante. Características de un conjunto de datos.
La importancia de la selección de características se reconoce mejor cuando se trata de un conjunto de datos que contiene un gran número de características. Este tipo de conjunto de datos suele denominarse conjunto de datos de alta dimensión. Ahora bien, con esta alta dimensionalidad, surgen muchos problemas como - esta alta dimensionalidad aumentará significativamente el tiempo de entrenamiento de tu modelo de aprendizaje automático, puede hacer que tu modelo sea muy complicado, lo que a su vez puede conducir a un Sobreajuste.
A menudo, en un conjunto de características de alta dimensión, quedan varias características que son redundantes, lo que significa que estas características no son más que extensiones de las otras características esenciales. Estas características redundantes tampoco contribuyen eficazmente al entrenamiento del modelo. Por tanto, está claro que es necesario extraer las características más importantes y relevantes de un conjunto de datos para obtener el rendimiento de modelado predictivo más eficaz.
"El objetivo de la selección de variables es triple: mejorar el rendimiento de predicción de los predictores, proporcionar predictores más rápidos y rentables, y proporcionar una mejor comprensión del proceso subyacente que generó los datos".
-Introducción a la selección de variables y rasgos
Ahora vamos a entender la diferencia entre reducción de la dimensionalidad y la selección de rasgos.
A veces, la selección de características se confunde con la reducción de la dimensionalidad. Pero son diferentes. La selección de rasgos es diferente de la reducción de la dimensionalidad. Ambos métodos tienden a reducir el número de atributos del conjunto de datos, pero un método de reducción de la dimensionalidad lo hace creando nuevas combinaciones de atributos (lo que a veces se conoce como transformación de características), mientras que los métodos de selección de características incluyen y excluyen atributos presentes en los datos sin modificarlos.
Algunos ejemplos de métodos de reducción de la dimensionalidad son el Análisis de Componentes Principales, la Descomposición de Valores Singulares, el Análisis Discriminante Lineal, etc.
Permíteme que te resuma la importancia de la selección de características:
En la siguiente sección, estudiarás los distintos tipos de métodos generales de selección de rasgos: métodos de filtro, métodos envolventes y métodos incrustados.
La siguiente imagen describe mejor los métodos de selección de rasgos basados en filtros:

Fuente de la imagen: Analítica Vidhya
El método del filtro se basa en la unicidad general de los datos que hay que evaluar y elegir un subconjunto de características, sin incluir ningún algoritmo de minería. El método del filtro utiliza el criterio de evaluación exacta, que incluye la distancia, la información, la dependencia y la coherencia. El método del filtro utiliza los criterios principales de la técnica de clasificación y utiliza el método de ordenación por rango para la selección de variables. La razón para utilizar el método de clasificación es la sencillez, producir características excelentes y relevantes. El método de clasificación filtrará las características irrelevantes antes de iniciar el proceso de clasificación.
Los métodos de filtrado se utilizan generalmente como paso previo al tratamiento de los datos. La selección de características es independiente de cualquier algoritmo de aprendizaje automático. Las características se clasifican en función de puntuaciones estadísticas que tienden a determinar la correlación de las características con la variable de resultado. La correlación es un término muy contextual, y varía de un trabajo a otro. Puedes consultar la tabla siguiente para definir los coeficientes de correlación para distintos tipos de datos (en este caso, continuos y categóricos).

Fuente de la imagen: Analítica Vidhya
Algunos ejemplos de algunos métodos de filtrado son prueba de Chi-cuadrado, ganancia de informacióny puntuaciones del coeficiente de correlación.
A continuación, verás los métodos Wrapper.
Al igual que los métodos de filtro, permíteme que te ofrezca el mismo tipo de infográfico que te ayudará a comprender mejor los métodos de envoltura:
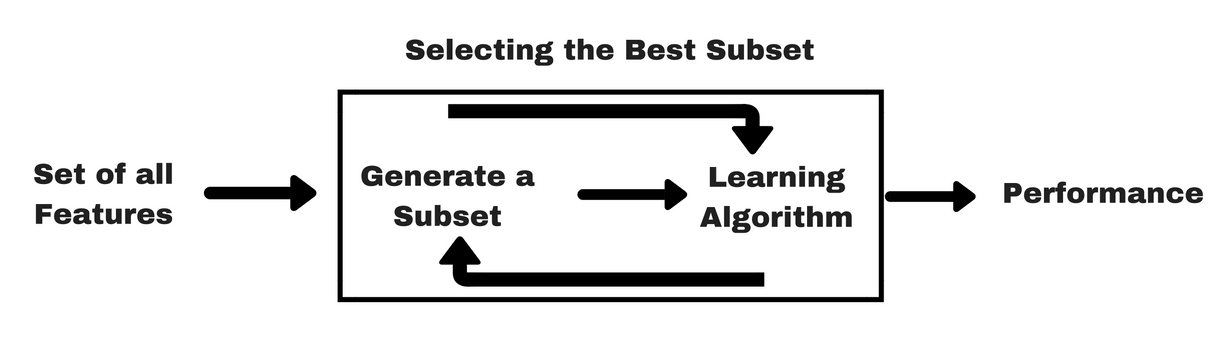
Fuente de la imagen: Analítica Vidhya
Como puedes ver en la imagen anterior, un método envolvente necesita un algoritmo de aprendizaje automático y utiliza su rendimiento como criterio de evaluación. Este método busca una característica que se adapte mejor al algoritmo de aprendizaje automático y pretende mejorar el rendimiento de la minería. Para evaluar las características, se utiliza la precisión predictiva para las tareas de clasificación y se evalúa la bondad del conglomerado mediante la agrupación.
Algunos ejemplos típicos de métodos envolventes son la selección de rasgos hacia delante, la eliminación de rasgos hacia atrás, la eliminación de rasgos recursiva, etc.
¡Suficiente!
Estudiemos ahora los métodos integrados.
Los métodos integrados son iterativos en el sentido de que se ocupan de cada iteración del proceso de entrenamiento del modelo y extraen cuidadosamente las características que más contribuyen al entrenamiento de una iteración concreta. Los métodos de regularización son los métodos integrados más utilizados, que penalizan una característica dado un umbral de coeficiente.
Por eso los métodos de Regularización también se llaman métodos de penalización, que introducen restricciones adicionales en la optimización de un algoritmo de predicción (como un algoritmo de regresión) que sesgan el modelo hacia una menor complejidad (menos coeficientes).
Ejemplos de algoritmos de regularización son el LASSO, la Red Elástica, la Regresión Ridge, etc.
Bueno, a veces puede resultar confuso diferenciar entre métodos filtro y métodos envoltorio en cuanto a sus funcionalidades. Veamos en qué se diferencian.
Hasta ahora has estudiado la importancia de la selección de rasgos, has comprendido su diferencia con la reducción de la dimensionalidad. También cubriste varios tipos de métodos de selección de características. Hasta ahora, ¡todo bien!
Veamos ahora algunas trampas en las que puedes caer al realizar la selección de características:
Puede que ya hayas comprendido el valor de la selección de características en una cadena de aprendizaje automático y el tipo de servicios que proporciona si se integra. Pero es muy importante comprender en qué punto exacto debes integrar la selección de características en tu canal de aprendizaje automático.
En pocas palabras, debes incluir el paso de selección de características antes de alimentar los datos al modelo para el entrenamiento, especialmente cuando utilices métodos de estimación de la precisión como la validación cruzada. Esto garantiza que la selección de características se realice en el pliegue de datos justo antes de entrenar el modelo. Pero si primero realizas la selección de características para preparar tus datos, y luego realizas la selección del modelo y el entrenamiento con las características seleccionadas, entonces sería un error garrafal.
Si realizas la selección de características en todos los datos y luego haces una validación cruzada, los datos de prueba de cada pliegue del procedimiento de validación cruzada también se utilizaron para elegir las características, y esto tiende a sesgar el rendimiento de tu modelo de aprendizaje automático.
¡Basta de teorías! Pasemos directamente a la codificación.
Para este caso práctico, utilizarás el conjunto de datos Diabetes de los indios Pima. La descripción del conjunto de datos puede consultarse aquí.
El conjunto de datos corresponde a tareas de clasificación en las que tienes que predecir si una persona tiene diabetes basándote en 8 características.
Hay un total de 768 observaciones en el conjunto de datos. Tu primera tarea es cargar el conjunto de datos para poder continuar. Pero antes vamos a importar las dependencias necesarias que vas a necesitar. Puedes importar los demás a medida que vayas avanzando.
import pandas as pd
import numpy as np
Ahora que se han importado las dependencias, vamos a cargar el conjunto de datos de los indios Pima en un objeto Dataframe con ayuda de la biblioteca Pandas.
data = pd.read_csv("diabetes.csv")
El conjunto de datos se carga correctamente en los datos del objeto Dataframe. Ahora, echemos un vistazo a los datos.
data.head()
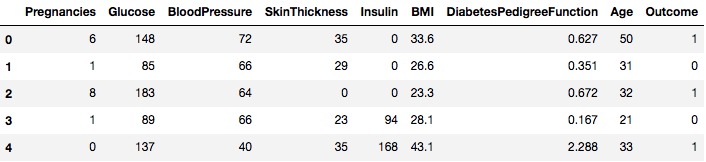
Así que puedes ver 8 características diferentes etiquetadas en los resultados de 1 y 0, donde 1 significa que la observación tiene diabetes, y 0 denota que la observación no tiene diabetes. Se sabe que el conjunto de datos tiene valores perdidos. Concretamente, faltan observaciones para algunas columnas que están marcadas como valor cero. Puedes deducirlo por la definición de esas columnas, y no es práctico tener un valor cero es inválido para esas medidas, por ejemplo, cero para el índice de masa corporal o la tensión arterial es inválido.
Pero para este tutorial, utilizarás directamente la versión preprocesada del conjunto de datos.
# load data
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
dataframe = pd.read_csv(url, names=names)
Ahora has cargado los datos en un objeto DataFrame llamado dataframe.
Convirtamos el objeto DataFrame en una matriz NumPy para conseguir un cálculo más rápido. Además, vamos a segregar los datos en variables distintas para que las características y las etiquetas estén separadas.
array = dataframe.values
X = array[:,0:8]
Y = array[:,8]
¡Maravilloso! Has preparado tus datos.
En primer lugar, aplicarás una Chi-cuadrado para características no negativas con el fin de seleccionar 4 de las mejores características del conjunto de datos. Ya has visto que la prueba Chi-cuadrado pertenece a la clase de métodos de filtrado. Si alguien tiene curiosidad por conocer las interioridades de Chi-Cuadrado, este vídeo hace un trabajo excelente.
La biblioteca scikit-learn proporciona la clase SelectKBest que se puede utilizar con un conjunto de pruebas estadísticas diferentes para seleccionar un número específico de características, en este caso, es Chi-cuadrado.
# Import the necessary libraries first
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
Has importado las bibliotecas para realizar los experimentos. Ahora, veámoslo en acción.
# Feature extraction
test = SelectKBest(score_func=chi2, k=4)
fit = test.fit(X, Y)
# Summarize scores
np.set_printoptions(precision=3)
print(fit.scores_)
features = fit.transform(X)
# Summarize selected features
print(features[0:5,:])
[ 111.52 1411.887 17.605 53.108 2175.565 127.669 5.393 181.304]
[[148. 0. 33.6 50. ]
[ 85. 0. 26.6 31. ]
[183. 0. 23.3 32. ]
[ 89. 94. 28.1 21. ]
[137. 168. 43.1 33. ]]
Puedes ver las puntuaciones de cada atributo y los 4 atributos elegidos (los que tienen las puntuaciones más altas): plas, test, masa y edad. Estas puntuaciones te ayudarán a determinar las mejores características para entrenar tu modelo.
P.S.: La primera fila indica los nombres de las características. Para el preprocesamiento del conjunto de datos, los nombres se han codificado numéricamente.
A continuación, pondrás en práctica Eliminación Recursiva de Características que es un tipo de método envolvente de selección de características.
La Eliminación Recursiva de Características (o RFE) funciona eliminando recursivamente atributos y construyendo un modelo sobre los atributos que quedan.
Utiliza la precisión del modelo para identificar qué atributos (y combinación de atributos) contribuyen más a predecir el atributo objetivo.
Puedes obtener más información sobre la clase RFE en la documentación de scikit-learn.
# Import your necessary dependencies
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
Utilizarás RFE con el clasificador Logistic Regression para seleccionar las 3 características principales. La elección del algoritmo no importa demasiado, siempre que sea hábil y coherente.
# Feature extraction
model = LogisticRegression()
rfe = RFE(model, 3)
fit = rfe.fit(X, Y)
print("Num Features: %s" % (fit.n_features_))
print("Selected Features: %s" % (fit.support_))
print("Feature Ranking: %s" % (fit.ranking_))
Num Features: 3
Selected Features: [ True False False False False True True False]
Feature Ranking: [1 2 3 5 6 1 1 4]
Puedes ver que RFE eligió las 3 características principales como preg, mass, y pedi.
Se marcan como Verdadero en la matriz de apoyo y con un "1" en la matriz de clasificación. Esto, a su vez, indica la fuerza de estos rasgos.
A continuación utilizarás regresión Ridge que es básicamente una técnica de regularización y también una técnica de selección de características.
Este artículo te ofrece una excelente explicación sobre la regresión de Ridge. No dejes de comprobarlo.
# First things first
from sklearn.linear_model import Ridge
A continuación, utilizarás la regresión de Ridge para determinar el coeficienteR2.
Consulta también la documentación oficial de scikit-learn sobre la regresión Ridge.
ridge = Ridge(alpha=1.0)
ridge.fit(X,Y)
Ridge(alpha=1.0, copy_X=True, fit_intercept=True, max_iter=None,
normalize=False, random_state=None, solver='auto', tol=0.001)
Para comprender mejor los resultados de la regresión de Ridge, implementarás una pequeña función auxiliar que te ayudará a imprimir los resultados de forma que puedas interpretarlos fácilmente.
# A helper method for pretty-printing the coefficients
def pretty_print_coefs(coefs, names = None, sort = False):
if names == None:
names = ["X%s" % x for x in range(len(coefs))]
lst = zip(coefs, names)
if sort:
lst = sorted(lst, key = lambda x:-np.abs(x[0]))
return " + ".join("%s * %s" % (round(coef, 3), name)
for coef, name in lst)
A continuación, pasarás los términos de los coeficientes del modelo Ridge a esta pequeña función y verás lo que ocurre.
print ("Ridge model:", pretty_print_coefs(ridge.coef_))
Ridge model: 0.021 * X0 + 0.006 * X1 + -0.002 * X2 + 0.0 * X3 + -0.0 * X4 + 0.013 * X5 + 0.145 * X6 + 0.003 * X7
Puedes ver todos los términos de coeficiente adjuntos a las variables de función. De nuevo te ayudará a elegir las características más esenciales. A continuación se indican algunos puntos que debes tener en cuenta al aplicar la regresión de Ridge:
Bueno, con esto concluye la sección de casos prácticos. Los métodos que implementaste en la sección anterior te ayudarán a comprender las características de un conjunto de datos concreto de forma exhaustiva. Permíteme darte algunos puntos críticos sobre estas técnicas:
En este post, has tratado uno de los temas estadísticos más estudiados e investigados, es decir, la selección de características. También te familiarizaste con sus distintas variantes y las utilizaste para ver qué características de un conjunto de datos son importantes.
Puedes llevar este tutorial más allá fusionando una medida de correlación en el método envoltorio y ver cómo funciona. En el transcurso de la acción, puede que acabes creando tu propio mecanismo de selección de características. Así es como estableces la base de tu pequeña investigación. Los investigadores también utilizan diversos principios de soft computing para realizar la selección. Esto constituye en sí mismo todo un campo de estudio e investigación. Además, deberías probar los algoritmos de selección de características existentes en varios conjuntos de datos y sacar tus propias conclusiones.
Sí, esta pregunta es obvia. Porque hay arquitecturas de redes neuronales (por ejemplo las CNN) que son muy capaces de extraer las características más significativas de los datos, pero eso también tiene una limitación. Utilizar una CNN para un conjunto de datos tabular normal que no tiene propiedades específicas (las propiedades que tiene una imagen típica, como propiedades de transición, bordes, propiedades posicionales, contornos, etc.) no es la decisión más sabia que se puede tomar. Además, cuando tienes datos y recursos limitados, entrenar una CNN con conjuntos de datos tabulares normales puede convertirse en un completo desperdicio. Así que, en situaciones como ésa, los métodos que has estudiado te serán muy útiles.
A continuación encontrarás algunos recursos si quieres profundizar en este tema:
A continuación encontrarás las referencias que se han utilizado para escribir este tutorial.
¡No dejes de publicar tus dudas en la sección de comentarios si tienes alguna!
Cursos de Python
Curso
Curso
Curso