Supervised Learning with scikit-learn
BeginnerSkill Level
4 h
281.6K learners

Aunque kNN puede utilizarse tanto para la clasificación como para la regresión, este artículo se centrará en la creación de un modelo de clasificación. La clasificación en machine learning es una tarea de aprendizaje supervisado que consiste en prever una etiqueta categórica para un punto de datos de entrada dado. El algoritmo se entrena con un conjunto de datos etiquetados y utiliza las características de entrada para aprender la asignación entre las entradas y las etiquetas de clase correspondientes. Podemos utilizar el modelo entrenado para prever nuevos datos no vistos. También puedes ejecutar el código de este tutorial abriendo este DataCamp Workspace.
El algoritmo kNN puede considerarse un sistema de votación, en el que la etiqueta de clase mayoritaria determina la etiqueta de clase de un nuevo punto de datos entre sus vecinos "k" más próximos (donde k es un número entero) en el espacio de características. Imagina que hay un pequeño pueblo con unos cientos de habitantes, y debes decidir a qué partido político votar. Para ello, puedes acercarte a tus vecinos más próximos y preguntarles a qué partido político apoyan. Si la mayoría de tus "k" vecinos más próximos apoyan al partido A, lo más probable es que tú también votes al partido A. Esto es similar al funcionamiento del algoritmo kNN, en el que la etiqueta de clase mayoritaria determina la etiqueta de clase de un nuevo punto de datos entre sus k vecinos más próximos.
Profundicemos con otro ejemplo. Imagina que tienes datos sobre fruta, concretamente uvas y peras. Tienes una puntuación por lo redonda que es la fruta y por el diámetro. Decides representarla en un gráfico. Si alguien te da una fruta nueva, también podrías representarla en el gráfico, y luego medir la distancia a k (un número) puntos más próximos para decidir qué fruta es. En el ejemplo siguiente, si elegimos medir tres puntos, podemos decir que los tres puntos más próximos son peras, así que estoy seguro al 100 % de que esto es una pera. Si elegimos medir los cuatro puntos más próximos, tres son peras y uno es una uva, por lo que diríamos que estamos seguros en un 75 % de que se trata de una pera. Más adelante en este artículo veremos cómo hallar el mejor valor para k y las distintas formas de medir la distancia.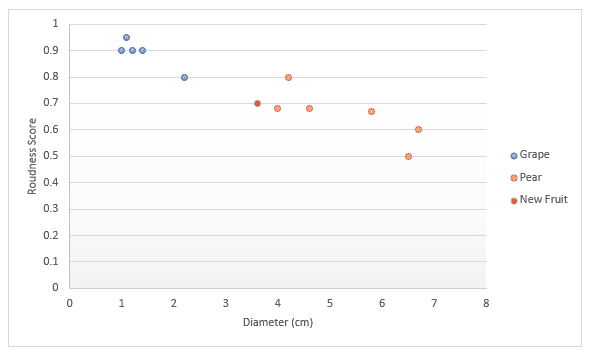
Para ilustrar mejor el algoritmo kNN, trabajemos con un caso práctico que puedes encontrarte al trabajar como científico de datos. Supongamos que eres un científico de datos de un comercio online, y te han encargado que detectes las transacciones fraudulentas. Las únicas características que tienes en esta fase son:
dist_from_home: La distancia entre el domicilio del usuario y el lugar donde se realizó la transacción.purchase_price_ratio: la relación entre el precio del artículo comprado en esta transacción y la mediana del precio de compra de ese usuario.Los datos tienen 39 observaciones que son transacciones individuales. En este tutorial, nos han dado la variable del conjunto de datos df, que tiene este aspecto:
|
0
|
2,1
|
6,4
|
1
|
|
1
|
3,8
|
2,2
|
1
|
|
2
|
15,7
|
4,4
|
1
|
|
3
|
26,7
|
4,6
|
1
|
|
4
|
10,7
|
4,9
|
1
|
Para ajustar y entrenar este modelo, seguiremos la infografía El flujo de trabajo del machine learning.
Descarga la infografía sobre el flujo de trabajo del machine learning
Sin embargo, como nuestros datos están bastante limpios, no realizaremos todos los pasos. Haremos lo siguiente:
Empecemos visualizando nuestros datos con Matplotlib; podemos representar nuestras dos características en un diagrama de dispersión.
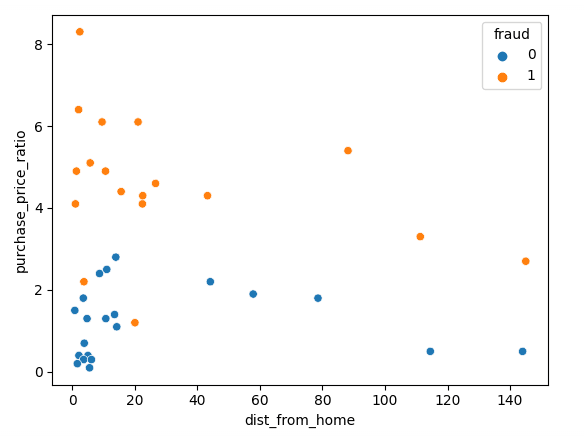
sns.scatterplot(x=df['dist_from_home'],y=df['purchase_price_ratio'], hue=df['fraud'])Como puedes ver, hay una clara diferencia entre estas transacciones, siendo las fraudulentas de un valor mucho mayor que la mediana del pedido de los clientes. Las tendencias en torno a la distancia al domicilio son algo difíciles de interpretar, ya que las transacciones no fraudulentas suelen estar más cerca del domicilio, pero con varios valores atípicos.
Al entrenar cualquier modelo de machine learning, es importante dividir los datos en datos de entrenamiento y datos de prueba. Los datos de entrenamiento se utilizan para ajustar el modelo. El algoritmo utiliza los datos de entrenamiento para aprender la relación entre las características y el objetivo. Trata de encontrar un patrón en los datos de entrenamiento que pueda utilizarse para hacer previsiones sobre nuevos datos no vistos. Los datos de prueba se utilizan para evaluar el rendimiento del modelo. El modelo se prueba con los datos de prueba, que se utilizan para hacer previsiones y comparar estas previsiones con los valores objetivo reales.
Al entrenar un clasificador kNN, es esencial normalizar las características. Esto se debe a que kNN mide la distancia entre puntos. Por defecto se utiliza la distancia euclidiana, que es la raíz cuadrada de la suma de las diferencias al cuadrado entre dos puntos. En nuestro caso, purchase_price_ratio está entre 0 y 8, y dist_from_home es mucho mayor. Si no normalizáramos esto, nuestro cálculo estaría muy influenciado por dist_from_home porque las cifras son mayores.
Debemos normalizar los datos después de dividirlos en conjuntos de entrenamiento y de prueba. Esto se hace para evitar la "fuga de datos", ya que la normalización daría al modelo información adicional sobre el conjunto de prueba si normalizáramos todos los datos a la vez.
El siguiente código divide los datos en divisiones de entrenamiento/prueba y luego los normaliza utilizando el escalado estándar de scikit-learn. Primero invocamos .fit_transform() sobre los datos de entrenamiento, que ajusta nuestro escalado a la media y la desviación típica de los datos de entrenamiento. Luego podemos aplicar esto a los datos de prueba invocando .transform(), que utiliza los valores aprendidos previamente.
# Split the data into features (X) and target (y)
X = df.drop('fraud', axis=1)
y = df['fraud']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Scale the features using StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)Ya estamos preparados para entrenar el modelo. Para ello, utilizaremos un valor fijo de 3 para k, pero tendremos que optimizarlo más adelante. Primero creamos una instancia del modelo kNN y luego ajustamos esto a nuestros datos de entrenamiento. Pasamos tanto las características como la variable objetivo, para que el modelo pueda aprender.
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)¡El modelo ya está entrenado! Podemos hacer previsiones sobre el conjunto de datos de prueba, que podemos utilizar más tarde para puntuar el modelo.
y_pred = knn.predict(X_test)La forma más sencilla de evaluar este modelo es mediante la exactitud. Comprobamos las previsiones comparándolas con los valores reales del conjunto de pruebas y contamos cuántas ha acertado el modelo.
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)Accuracy: 0.875¡Es una puntuación bastante buena! Sin embargo, quizá podamos hacerlo mejor optimizando nuestro valor de k.
Por desgracia, no hay una forma mágica de hallar el mejor valor para k. Tenemos que hacer un bucle con muchos valores diferentes y, luego, utilizar el sentido común.
En el código siguiente, seleccionamos un intervalo de valores para k y creamos una lista vacía para almacenar nuestros resultados. Utilizamos la validación cruzada para hallar las puntuaciones de exactitud, lo que significa que no tenemos que crear una división de entrenamiento y otra de prueba, pero debemos escalar nuestros datos. A continuación, hacemos un bucle sobre los valores y añadimos las puntuaciones a nuestra lista.
Para implementar la validación cruzada, utilizamos cross_val_score de scikit-learn. Pasamos una instancia del modelo kNN, junto con nuestros datos y un número de divisiones que se deben realizar. En el código siguiente, utilizamos cinco divisiones, lo que significa que el modelo divide los datos en cinco grupos del mismo tamaño y utiliza 4 para entrenar y 1 para probar el resultado. Hará un bucle en cada grupo y dará una puntuación de exactitud, de la que hallaremos la media para buscar el mejor modelo.
k_values = [i for i in range (1,31)]
scores = []
scaler = StandardScaler()
X = scaler.fit_transform(X)
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, X, y, cv=5)
scores.append(np.mean(score))Podemos representar los resultados con el siguiente código
sns.lineplot(x = k_values, y = scores, marker = 'o')
plt.xlabel("K Values")
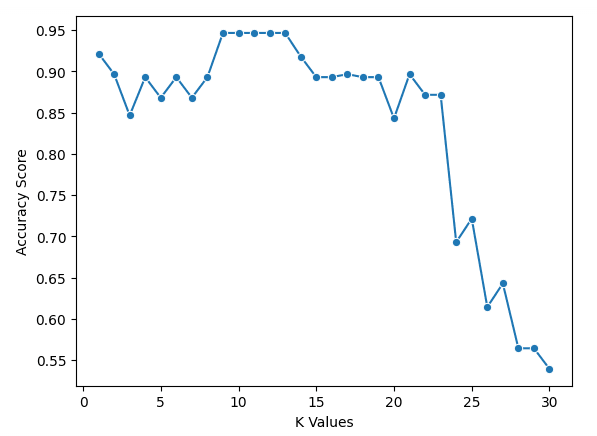
plt.ylabel("Accuracy Score")Podemos ver en nuestro gráfico que k = 9, 10, 11, 12 y 13 tiene una puntuación de exactitud ligeramente inferior al 95 %. Como hay empate para la mejor puntuación, es aconsejable utilizar un valor menor para k. Esto se debe a que, al utilizar valores más altos de k, el modelo utilizará más puntos de datos más alejados del original. Otra opción sería explorar otras métricas de evaluación.
Ahora podemos entrenar nuestro modelo utilizando el mejor valor de k con el código siguiente.
best_index = np.argmax(scores)
best_k = k_values[best_index]
knn = KNeighborsClassifier(n_neighbors=best_k)
knn.fit(X_train, y_train)A continuación, debemos evaluar con exactitud, precisión y recuerdo (ten en cuenta que tus resultados pueden diferir debido a la aleatorización)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)Accuracy: 0.875
Precision: 0.75
Recall: 1.0Tutorial
Kevin Babitz
Tutorial
Abid Ali Awan
Tutorial
Adam Shafi
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Eugenia Anello

