
Program
Insinyur AI Asisten untuk Ilmuwan Data
40 Hr
MiniMax M2.7 menonjol dari banyak model open-weight karena dirancang untuk alur kerja agen yang kompleks, termasuk penggunaan alat, tugas pengodean multi-langkah, dan penalaran berorientasi produktivitas.
Meskipun berada di kisaran ukuran menengah, bukan pada tingkat model terbesar, MiniMax M2.7 diposisikan untuk memberikan kinerja pengodean dan penalaran yang kuat dengan jejak penerapan yang jauh lebih praktis.
Dalam panduan ini, saya akan menggunakan Hyperbolic karena menawarkan akses H200 on-demand termurah, penyediaan cepat, dan cara sederhana untuk menyiapkan mesin GPU Linux untuk penyajian model bergaya lokal.
Anda akan mempelajari cara:
Meluncurkan mesin Hyperbolic H200 Linux
Memasang llama.cpp untuk inference lokal
Mengunduh versi UD-IQ4_XS GGUF dari MiniMax M2.7 milik Unsloth
Menjalankan llama-server sebagai API lokal yang kompatibel dengan OpenAI
Menghubungkan model lokal ke OpenCode untuk alur kerja agentic coding
MiniMax M2.7 memperkenalkan arah yang lebih berfokus pada agen dibandingkan model terbuka sebelumnya, seperti MiniMax M2.5. Yang membuatnya menonjol bukan hanya kemampuan pengodean atau penalarannya, tetapi fakta bahwa model ini dirancang untuk mengambil peran dalam proses peningkatannya sendiri.
Menurut MiniMax, M2.7 adalah model pertama mereka yang berkontribusi secara mendalam pada evolusinya sendiri dengan membantu membangun harnes agen yang kompleks, menangani tugas produktivitas yang rumit, serta bekerja dengan tim agen, keterampilan tingkat lanjut, dan penelusuran alat yang dinamis.
Perubahan besar pada M2.7 adalah alur kerja self-evolution. Selama pengembangan, model ini digunakan untuk memperbarui memorinya sendiri, membuat keterampilan kompleks untuk eksperimen reinforcement learning, dan menyempurnakan proses belajarnya berdasarkan hasil eksperimen tersebut.
Semua ini membuat M2.7 terasa kurang seperti model statis standar dan lebih seperti sistem yang dibangun untuk peningkatan iteratif.
Sumber: MiniMaxAI/MiniMax-M2.7 · Hugging Face
Hal yang paling menarik bagi saya adalah MiniMax memosisikan M2.7 sebagai lebih dari sekadar model terbuka lain. Bagi saya, ini mengarah pada cara yang lebih berkelanjutan untuk meningkatkan dan melatih model, di mana sistem canggih dapat berperan lebih aktif dalam pengembangan dirinya sendiri.
Alih-alih hanya bergantung pada himpunan data baru yang masif, ini menunjukkan bagaimana metode pelatihan yang lebih baru dan loop peningkatan mandiri dapat mendorong kinerja model lebih jauh.
Kunjungi Hyperbolic, daftar, dan tambahkan setidaknya $5 kredit menggunakan kartu Anda. Lalu buka tab GPUs, klik Launch Instance, dan pilih mesin H200 SXM5.
Panduan ini menggunakan server GPU jarak jauh, jadi sebelum meluncurkan mesin, Anda perlu memastikan akses SSH Anda siap. SSH memungkinkan Anda terhubung dengan aman dari terminal Anda sendiri ke mesin Linux yang berjalan di Hyperbolic.
Jika Anda sudah menggunakan SSH dan memiliki pasangan kunci yang siap, lanjutkan ke bagian berikutnya. Jika belum, Anda perlu membuatnya terlebih dahulu.
Di mesin lokal Anda, buka terminal dan generasi kunci SSH jika Anda belum memilikinya:
ssh-keygenSaat diminta, tekan Enter untuk menyimpannya di lokasi bawaan. Anda juga dapat menambahkan frasa sandi jika ingin keamanan ekstra, tetapi ini opsional.
Setelah kunci dibuat, tampilkan kunci publik Anda agar bisa disalin:
cat ~/.ssh/id_rsa.pubJika sistem Anda menggunakan format Ed25519, jalankan:
cat ~/.ssh/id_ed25519.pubSalin seluruh output dan tambahkan ke akun Hyperbolic Anda. Pastikan Anda hanya mengunggah kunci publik. Kunci privat tetap berada di komputer Anda dan tidak boleh dibagikan.
Setelah kunci SSH ditambahkan, buka dasbor Hyperbolic, buka tab GPUs, dan klik Launch Instance. Dari daftar mesin yang tersedia, pilih instance H200 SXM5 untuk penyiapan ini.
Sebelum menyalakan mesin, beri nama instance yang jelas dan mudah dikenali. Ini akan memudahkan Anda mengidentifikasinya nanti, terutama jika Anda meluncurkan lebih dari satu mesin atau kembali setelah beberapa waktu.
Setelah itu, tinjau pengaturan instance, pastikan kunci SSH Anda terpasang, dan mulai mesin. Platform kemudian akan mulai menyediakan server GPU untuk Anda.
Setelah mesin benar-benar siap, statusnya akan terlihat aktif di dasbor. Pada saat itu, Anda juga akan melihat perintah SSH yang diperlukan untuk terhubung dari terminal lokal Anda. Anda akan menggunakan perintah tersebut pada langkah berikutnya.
Sekarang buka terminal lokal Anda dan jalankan perintah SSH dengan penerusan port yang sudah diaktifkan dari awal:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Ini menghubungkan mesin lokal Anda ke server Linux jarak jauh dan juga meneruskan port 8001, sehingga nanti Anda dapat mengakses server llama.cpp di browser melalui http://127.0.0.1:8001.
Jika ini pertama kalinya Anda terhubung ke server, SSH akan meminta Anda mengonfirmasi fingerprint. Ketik yes lalu tekan Enter.
Jika Anda menetapkan frasa sandi saat membuat kunci SSH, SSH akan memintanya sebelum koneksi selesai. Cukup ketik frasa sandi Anda lalu tekan Enter. Penggunaan frasa sandi direkomendasikan karena menambah lapisan perlindungan ekstra pada kunci privat Anda.
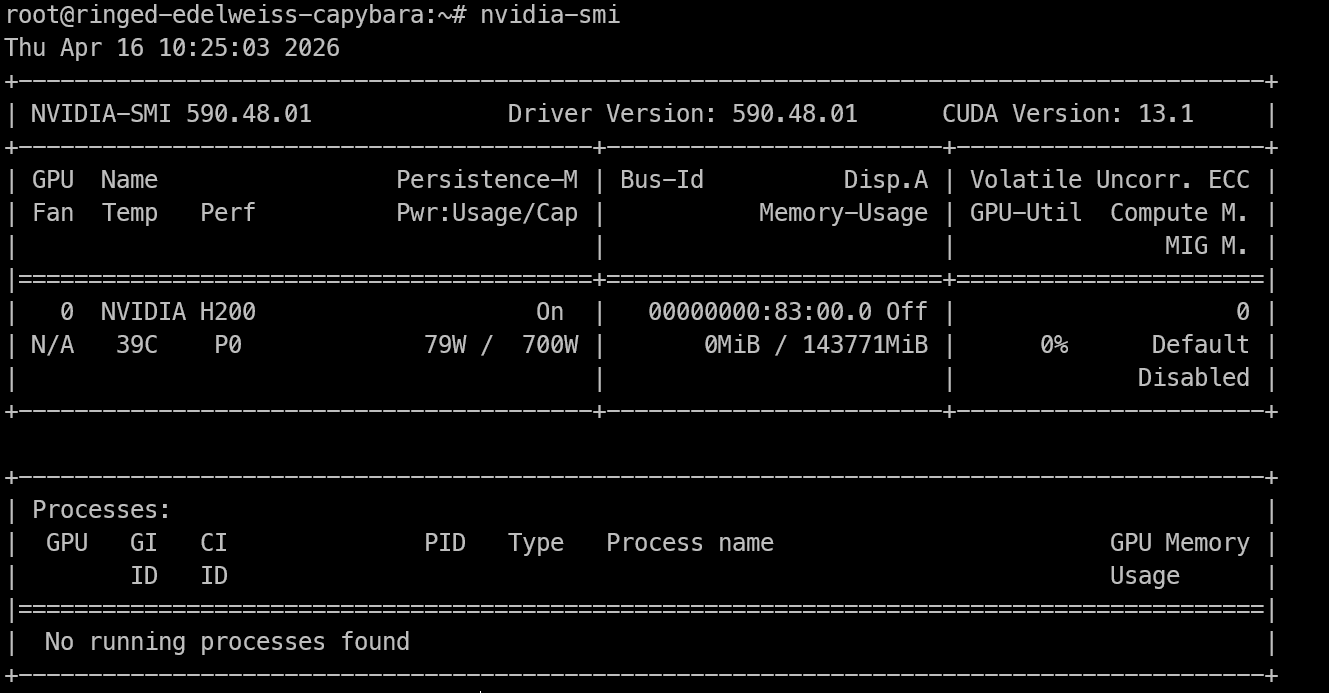
Setelah Anda memiliki akses jarak jauh ke mesin H200, hal pertama yang perlu diperiksa adalah apakah GPU terlihat dan driver NVIDIA berfungsi dengan benar.
Jalankan:
nvidia-smiPerintah ini akan menampilkan GPU NVIDIA yang terpasang, versi driver, versi CUDA, dan memori yang tersedia. Jika Anda dapat melihat H200 tercantum di sini, mesin siap untuk pekerjaan inference.
Sekarang pasang paket sistem yang dibutuhkan untuk membangun llama.cpp dan menjalankan model secara lokal.
Jalankan:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipPaket-paket ini memberikan alat yang dibutuhkan untuk sisa penyiapan:
build-essential dan cmake diperlukan untuk mengompilasi llama.cpp
git memungkinkan Anda mengkloning repositori
curl dan wget membantu mengunduh file
tmux berguna jika Anda ingin menjaga proses yang berjalan lama tetap aktif bahkan setelah menutup terminal.
Sekarang mesin sudah siap, langkah berikutnya adalah memasang llama.cpp, yang akan kita gunakan untuk menjalankan MiniMax M2.7 secara lokal. Ini memberi kita alat baris perintah untuk menguji model dan server yang nanti akan kita buka sebagai API yang kompatibel dengan OpenAI.
Mulai dengan mengkloning repositori resmi llama.cpp ke mesin jarak jauh:
git clone https://github.com/ggml-org/llama.cppIni akan membuat folder llama.cpp baru di direktori saat ini dengan semua berkas sumber yang dibutuhkan untuk membangun proyek.
Selanjutnya, jalankan CMake untuk mengonfigurasi build. Dalam penyiapan ini, kita mengaktifkan CUDA agar llama.cpp bisa menggunakan GPU H200 untuk inference.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONPerintah ini menyiapkan berkas build di dalam direktori llama.cpp/build.
Sekarang kompilasi alat yang kita butuhkan:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitIni membangun tiga biner utama:
llama-cli untuk menguji dan menjalankan model dari terminal
llama-server untuk menyajikan model melalui API lokal dan antarmuka browser
llama-gguf-split untuk bekerja dengan berkas model GGUF terpisah
Salin biner ke folder utama
Setelah build selesai, salin biner yang dikompilasi ke folder utama llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppIni memudahkan menjalankan alat tanpa perlu mengetik path build lengkap setiap kali.
Terakhir, jalankan perintah bantuan di bawah untuk memastikan semuanya terpasang dengan benar:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpJika kedua perintah menampilkan informasi penggunaan alih-alih galat, llama.cpp telah terpasang dengan sukses, dan Anda siap mengunduh model MiniMax M2.7.
Sebelum mengunduh model, pasang alat unduhan Hugging Face pada mesin jarak jauh:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferIni memasang CLI hf bersama hf-xet, yang membantu menangani unduhan berkas besar dengan lebih efisien.
Selanjutnya, buat folder untuk berkas model dan unduh versi GGUF UD-IQ4_XS dari MiniMax M2.7.
Jalankan:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Ini membuat direktori model khusus dan hanya mengunduh berkas UD-IQ4_XS, yaitu versi kuantisasi 4-bit yang digunakan dalam panduan ini.
Unduhan berukuran besar, sekitar 108 GB, sehingga mungkin memerlukan waktu tergantung kecepatan jaringan instance Anda.
Setelah unduhan selesai, periksa apakah semua shard GGUF sudah ada dengan menjalankan:
find /models/minimax-m27 -name "*.gguf"Anda seharusnya melihat empat berkas GGUF tercantum, kira-kira seperti ini:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufJika keempat berkas ada, model telah diunduh dengan benar, dan Anda siap memulai server pada langkah berikutnya.
Sekarang saatnya memulai model dengan llama-server. Ini akan memuat model GGUF MiniMax M2.7, menjalankannya di GPU, dan membukanya melalui server lokal pada port 8001.
Sebelum meluncurkan server model, mulai sesi tmux agar proses tetap berjalan meski koneksi SSH terputus atau jendela terminal ditutup.
Jalankan:
tmux new -s minimaxIni membuat sesi tmux baru bernama minimax, yang akan kita gunakan untuk menjalankan server.
Sekarang masuk ke direktori llama.cpp dan jalankan server dengan path model dan pengaturan inference:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Ini memulai server pada port 8001 dan memuat model. Saat model dimuat, perhatikan log di terminal.

Jika model berhasil dimuat ke memori GPU, Anda akan melihat pesan yang menunjukkan server sedang mendengarkan pada alamat dan port yang dikonfigurasi.
Setelah model sepenuhnya dimuat, Anda dapat membiarkannya berjalan di dalam tmux dan melepaskan (detach) dari sesi tanpa menghentikannya.
Tekan Ctrl+B, lalu D. Ini akan mengembalikan Anda ke terminal normal sambil menjaga server model tetap aktif di latar belakang.
Jika Anda ingin memeriksa log lagi nanti, sambungkan kembali ke sesi dengan:
tmux attach -t minimaxSetelah server berjalan, buka sesi terminal lain dan jalankan:
curl http://127.0.0.1:8001/v1/modelsAnda akan melihat output seperti ini:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Jika Anda melihat model MiniMax-M2.7 tercantum, server berjalan dengan baik.
Karena Anda sudah memulai SSH dengan penerusan port pada 8001, sekarang Anda dapat membuka WebUI llama.cpp langsung di browser dengan mengunjungi http://127.0.0.1:8001.
Ini memberi Anda akses langsung ke antarmuka model dari browser lokal Anda.
Pada tahap ini, model seharusnya siap digunakan. Anda dapat mengujinya di WebUI atau melalui permintaan API dari terminal untuk memastikan semuanya berfungsi dengan benar.
Dalam penyiapan saya, MiniMax M2.7 merespons sangat cepat, mencapai sekitar 120 token per detik. Sejujurnya ini terasa seperti model lokal tercepat yang pernah saya jalankan sejauh ini pada ukuran ini, terutama mengingat betapa responsifnya bahkan dengan prompt yang lebih panjang dan teknis.
Setelah merespons dengan benar, MiniMax M2.7 sepenuhnya berjalan secara lokal dan siap dihubungkan ke alur kerja pengodean Anda.
Sekarang server llama.cpp lokal sudah berjalan, langkah berikutnya adalah menghubungkannya ke OpenCode. OpenCode adalah agen pengodean berbasis terminal yang mendukung penyedia kustom melalui berkas konfigurasinya. Jika Anda tertarik untuk mengetahui lebih lanjut, baca perbandingan kami tentang OpenCode vs Claude Code.
Untuk model lokal seperti llama.cpp, penyiapan paling bersih adalah mengarahkan OpenCode ke endpoint yang kompatibel dengan OpenAI yang berjalan di http://127.0.0.1:8001/v1.
Pasang OpenCode pada mesin jarak jauh dengan:
curl -fsSL https://opencode.ai/install | bash
Lalu muat ulang shell Anda, dan periksa versinya untuk memastikan pemasangan berhasil:
source ~/.bashrc
opencode --version1.4.6Selanjutnya, buat berkas opencode.json yang memberi tahu OpenCode untuk menggunakan server llama.cpp lokal Anda sebagai penyedia yang kompatibel dengan OpenAI.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFKonfigurasi ini mengarahkan OpenCode ke server lokal, menetapkan model bawaan ke MiniMax-M2.7, dan menggunakan pendekatan penyedia kompatibel OpenAI yang juga didokumentasikan OpenCode untuk penyedia kustom. OpenCode juga mendukung pemilihan model di dalam aplikasi dengan perintah /models.
Sekarang, buat folder proyek sederhana dan jalankan OpenCode di dalamnya:
mkdir ml-app
cd ml-app/
OpencodeSetelah OpenCode terbuka, ketik /models dan pilih MiniMax-M2.7 di bawah penyedia lokal Anda.
Setelah model dipilih, berikan prompt pengodean yang nyata. Misalnya:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.Dalam praktiknya, di sinilah penyiapan mulai terasa mengesankan. Model mulai bekerja hampir seketika, membuat rencana tugas, dan mulai membangun berkas-berkasnya. Dalam pengujian saya, model terasa sangat responsif, sejalan dengan seberapa cepat model sudah berjalan melalui llama.cpp.
Pada akhirnya, model mampu membuat berkas, menjalankan pengujian, dan menampilkan hasilnya.
Setelah itu, Anda dapat mendorongnya lebih jauh dengan memintanya menguji endpoint API ML, memperbaiki struktur aplikasi, atau menambahkan fitur baru. Karena OpenCode dibuat untuk alur kerja pengodean berbasis terminal, pada titik ini penyiapan MiniMax lokal mulai terasa seperti agen pengodean yang praktis, bukan sekadar model yang berjalan di server.
Dalam kasus saya, aplikasi API ML lokal berfungsi dengan benar pada akhir proses. Kami menjalankan unit test, melakukan smoke testing, dan memastikan tidak ada galat saat menjalankan dan menguji kode. Secara keseluruhan, butuh sekitar 2 menit untuk menyelesaikan semuanya, yang menunjukkan betapa cepatnya model ini terasa dalam alur kerja pengodean lokal.
Awalnya saya mulai dengan vLLM, tetapi saya menemui cukup banyak masalah, terutama saat mencoba menjalankan model AWQ 4-bit. Untuk penyiapan seperti ini, saya mendapati llama.cpp jauh lebih mudah digunakan. Pemasangannya terasa lebih sederhana, alur kerjanya lebih lugas, dan jauh lebih cepat untuk membuat semuanya berjalan dengan benar.
Hal lain yang saya suka dari llama.cpp adalah hadirnya WebUI bawaan, sehingga Anda bisa langsung menguji model dalam antarmuka mirip ChatGPT dari browser. Ini membuatnya jauh lebih mudah untuk memeriksa prompt secara cepat, menguji respons, dan memastikan model berfungsi sebelum menghubungkannya ke sesuatu seperti OpenCode.
Untuk penggunaan lokal, saya rasa MiniMax M2.7 adalah salah satu model terbaik yang pernah saya jalankan sejauh ini. Model ini lebih kecil dari GLM 5.1, terasa lebih cepat, memahami kode dengan baik, dan berkinerja kuat dalam tugas agentic coding. Bahkan versi 4-bit pun bekerja sangat baik pada tugas yang lebih kompleks, sehingga terasa praktis untuk penggunaan nyata dan bukan sekadar untuk eksperimen.
Kecepatan adalah bagian besar mengapa penyiapan ini menonjol. Dalam kasus saya, MiniMax M2.7 berjalan sekitar 120 token per detik dengan generasi yang sangat mulus, dan melalui penerusan port SSH, saya bisa menggunakannya dari browser atau API lokal seolah berjalan di mesin saya sendiri. Itu membuat keseluruhan alur kerja terasa cepat, sederhana, dan sangat praktis.
Kursus Rekayasa AI
Program
Program
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
