
Tracks
Kỹ sư AI cấp bậc Associate dành cho các nhà khoa học dữ liệu
40 giờ
MiniMax M2.7 nổi bật so với nhiều mô hình open-weight vì được thiết kế cho các quy trình làm việc agent phức tạp, bao gồm sử dụng công cụ, tác vụ mã hóa nhiều bước và suy luận hướng năng suất.
Dù thuộc nhóm kích thước trung bình chứ không phải hạng mô hình lớn nhất, MiniMax M2.7 được định vị để mang lại hiệu năng mã hóa và suy luận mạnh mẽ với dấu chân triển khai thực tiễn hơn nhiều.
Trong hướng dẫn này, tôi sẽ dùng Hyperbolic vì dịch vụ này cung cấp H200 theo nhu cầu với chi phí rẻ nhất, cấp máy nhanh và cách đơn giản để khởi tạo máy Linux GPU cho kiểu phục vụ mô hình tương tự cục bộ.
Bạn sẽ học cách:
Khởi chạy một máy Linux H200 trên Hyperbolic
Cài đặt llama.cpp để suy luận cục bộ
Tải phiên bản UD-IQ4_XS GGUF của MiniMax M2.7 từ Unsloth
Chạy llama-server như một API cục bộ tương thích OpenAI
Kết nối mô hình cục bộ với OpenCode cho quy trình mã hóa hướng agent
MiniMax M2.7 giới thiệu một định hướng tập trung vào agent hơn so với các mô hình mở trước đó, như MiniMax M2.5. Điểm khiến nó nổi bật không chỉ là khả năng mã hóa hay suy luận, mà còn ở chỗ mô hình được thiết kế để tham gia vào chính quá trình tự cải thiện của mình.
Theo MiniMax, M2.7 là mô hình đầu tiên của họ đóng góp sâu vào sự tiến hóa của chính nó bằng cách giúp xây dựng các bộ khung agent phức tạp, xử lý các tác vụ năng suất công phu và làm việc với đội nhóm agent, kỹ năng nâng cao, cũng như tìm kiếm công cụ động.
Một thay đổi lớn với M2.7 là quy trình tự tiến hóa. Trong giai đoạn phát triển, mô hình được dùng để cập nhật bộ nhớ của chính nó, tạo ra các kỹ năng phức tạp cho các thử nghiệm học tăng cường, và tinh chỉnh quá trình học dựa trên kết quả của những thử nghiệm đó.
Tất cả điều này khiến M2.7 ít giống một mô hình tĩnh tiêu chuẩn và giống một hệ thống được xây dựng để cải tiến lặp lại hơn.
Nguồn: MiniMaxAI/MiniMax-M2.7 · Hugging Face
Điều tôi thấy thú vị nhất là MiniMax định vị M2.7 không chỉ như một mô hình mở nữa. Với tôi, nó hướng tới một cách bền vững hơn để cải thiện và huấn luyện mô hình, nơi các hệ thống tiên tiến có thể đóng vai trò chủ động hơn trong sự phát triển của chính chúng.
Thay vì chỉ dựa vào những tập dữ liệu khổng lồ mới, nó cho thấy các phương pháp huấn luyện mới và vòng lặp tự cải thiện có thể giúp đẩy hiệu năng mô hình đi xa hơn.
Hãy truy cập Hyperbolic, đăng ký, và nạp ít nhất 5 USD bằng thẻ của bạn. Sau đó vào thẻ GPUs, nhấp Launch Instance và chọn máy H200 SXM5.
Hướng dẫn này dùng máy chủ GPU từ xa, nên trước khi khởi động máy, bạn cần đảm bảo quyền truy cập SSH của bạn đã sẵn sàng. SSH cho phép bạn kết nối an toàn từ terminal của mình tới máy Linux đang chạy trên Hyperbolic.
Nếu bạn đã dùng SSH và có cặp khóa, có thể chuyển sang phần tiếp theo. Nếu chưa, bạn cần tạo trước.
Trên máy cục bộ, mở terminal và tạo một khóa SSH nếu bạn chưa có:
ssh-keygenKhi được hỏi, nhấn Enter để lưu ở vị trí mặc định. Bạn cũng có thể thêm mật khẩu bảo vệ nếu muốn tăng bảo mật, nhưng điều này là tùy chọn.
Sau khi tạo khóa, hãy in khóa công khai để sao chép:
cat ~/.ssh/id_rsa.pubNếu hệ thống của bạn dùng định dạng Ed25519, hãy chạy:
cat ~/.ssh/id_ed25519.pubSao chép toàn bộ đầu ra và thêm vào tài khoản Hyperbolic của bạn. Hãy chắc chắn bạn chỉ tải lên khóa công khai. Khóa riêng tư nằm trên máy của bạn và không bao giờ được chia sẻ.
Sau khi đã thêm khóa SSH, vào bảng điều khiển Hyperbolic, mở thẻ GPUs và nhấp Launch Instance. Từ danh sách máy sẵn có, chọn H200 SXM5 cho thiết lập này.
Trước khi khởi động máy, hãy đặt cho instance một tên rõ ràng, dễ nhận biết. Điều này giúp bạn dễ dàng xác định sau này, đặc biệt nếu bạn khởi chạy nhiều máy hoặc quay lại sau một thời gian.
Sau đó, xem lại thiết lập instance, xác nhận khóa SSH đã được đính kèm và khởi động máy. Nền tảng sẽ bắt đầu cấp máy chủ GPU cho bạn.
Khi máy sẵn sàng hoàn toàn, nó sẽ hiển thị trạng thái hoạt động trong bảng điều khiển. Lúc đó, bạn cũng sẽ thấy lệnh SSH cần dùng để kết nối từ terminal cục bộ. Bạn sẽ dùng lệnh đó ở bước tiếp theo.
Bây giờ hãy mở terminal cục bộ và chạy lệnh SSH với chuyển tiếp cổng được bật ngay từ đầu:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Lệnh này kết nối máy cục bộ của bạn đến máy chủ Linux từ xa và đồng thời chuyển tiếp cổng 8001, để sau này bạn có thể truy cập máy chủ llama.cpp trong trình duyệt qua http://127.0.0.1:8001.
Nếu đây là lần đầu bạn kết nối đến máy chủ, SSH sẽ yêu cầu xác nhận fingerprint. Gõ yes và nhấn Enter.
Nếu bạn đặt mật khẩu bảo vệ (passphrase) khi tạo khóa SSH, SSH sẽ hỏi mật khẩu trước khi hoàn tất kết nối. Chỉ cần nhập mật khẩu và nhấn Enter. Nên dùng passphrase vì nó thêm một lớp bảo vệ cho khóa riêng của bạn.
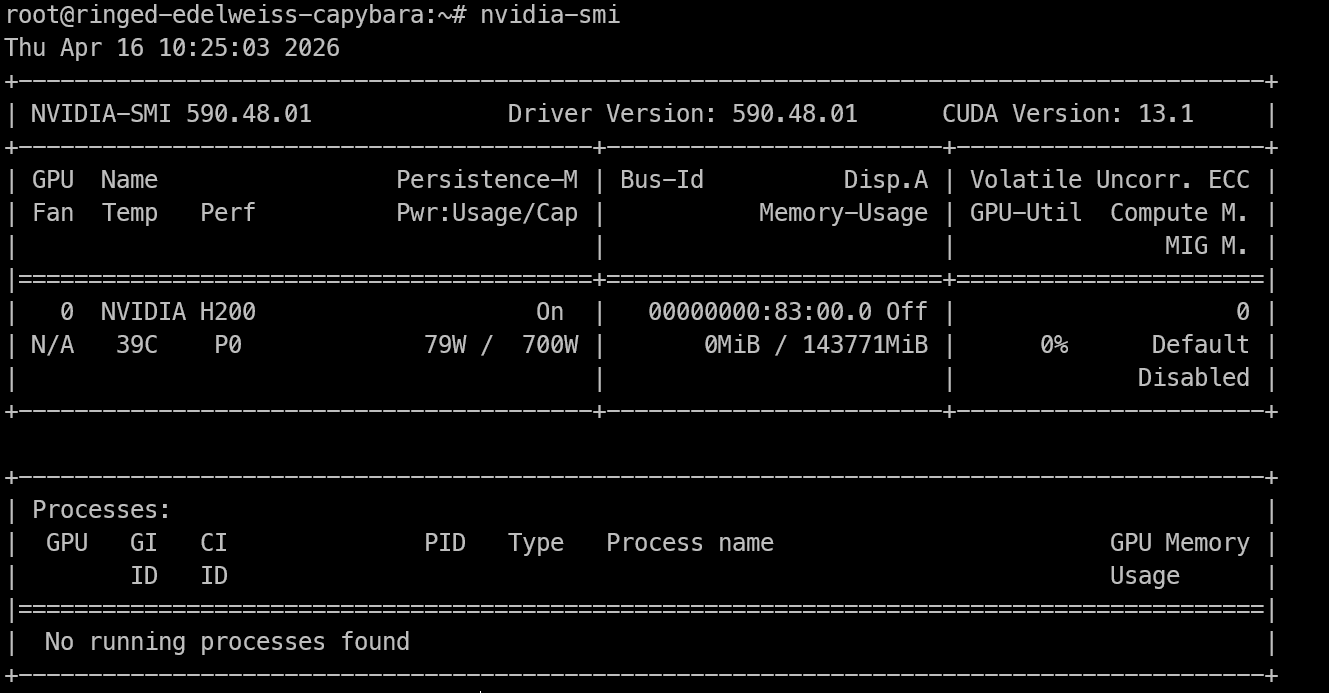
Sau khi có quyền truy cập từ xa vào máy H200, việc đầu tiên là kiểm tra GPU có hiển thị và driver NVIDIA hoạt động đúng không.
Chạy:
nvidia-smiLệnh này sẽ hiển thị GPU NVIDIA đã cài, phiên bản driver, phiên bản CUDA và bộ nhớ sẵn có. Nếu bạn thấy H200 xuất hiện ở đây, máy đã sẵn sàng cho công việc suy luận.
Bây giờ cài đặt các gói hệ thống cần thiết để biên dịch llama.cpp và chạy mô hình cục bộ.
Chạy:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipCác gói này cung cấp công cụ cần cho các bước còn lại:
build-essential và cmake là bắt buộc để biên dịch llama.cpp
git giúp bạn clone repository
curl và wget hỗ trợ tải tệp
tmux hữu ích nếu bạn muốn giữ các tiến trình chạy dài ngay cả khi đóng terminal.
Khi máy đã sẵn sàng, bước tiếp theo là cài đặt llama.cpp, công cụ chúng ta sẽ dùng để chạy MiniMax M2.7 cục bộ. Điều này cung cấp cả công cụ dòng lệnh để kiểm thử mô hình và máy chủ mà sau đó ta sẽ mở như một API tương thích OpenAI.
Bắt đầu bằng cách clone repository chính thức của llama.cpp vào máy từ xa:
git clone https://github.com/ggml-org/llama.cppLệnh này sẽ tạo thư mục llama.cpp mới trong thư mục hiện tại với toàn bộ mã nguồn cần để build dự án.
Tiếp theo, chạy CMake để cấu hình build. Ở thiết lập này, chúng ta bật CUDA để llama.cpp có thể dùng GPU H200 cho suy luận.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONLệnh này chuẩn bị tệp build trong thư mục llama.cpp/build.
Bây giờ biên dịch các công cụ chúng ta cần:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitLệnh này build ba binary chính:
llama-cli để kiểm thử và chạy mô hình từ terminal
llama-server để phục vụ mô hình qua API cục bộ và giao diện trình duyệt
llama-gguf-split để làm việc với các tệp mô hình GGUF chia nhỏ
Sao chép binary vào thư mục chính
Khi build xong, sao chép các binary đã biên dịch vào thư mục chính của llama.cpp:
cp llama.cpp/build/bin/llama-* llama.cppĐiều này giúp chạy công cụ dễ hơn mà không cần gõ đầy đủ đường dẫn build mỗi lần.
Cuối cùng, chạy các lệnh trợ giúp bên dưới để đảm bảo mọi thứ được cài đặt đúng:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpNếu cả hai lệnh trả về thông tin sử dụng thay vì lỗi, llama.cpp đã được cài thành công và bạn đã sẵn sàng tải mô hình MiniMax M2.7.
Trước khi tải mô hình, hãy cài đặt công cụ tải về của Hugging Face trên máy từ xa:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferLệnh này cài đặt CLI hf cùng với hf-xet, giúp xử lý tải tệp lớn hiệu quả hơn.
Tiếp theo, tạo thư mục cho tệp mô hình và tải phiên bản GGUF UD-IQ4_XS của MiniMax M2.7.
Chạy:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Lệnh này tạo thư mục riêng cho mô hình và chỉ tải các tệp UD-IQ4_XS, là phiên bản lượng tử hóa 4-bit được dùng trong hướng dẫn này.
Tải xuống khá lớn, khoảng 108 GB, nên vẫn có thể tốn thời gian tùy tốc độ mạng của instance.
Sau khi tải xong, kiểm tra tất cả shard GGUF đã có bằng cách chạy:
find /models/minimax-m27 -name "*.gguf"Bạn sẽ thấy bốn tệp GGUF được liệt kê, tương tự như sau:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufNếu cả bốn tệp đều có, mô hình đã được tải đúng và bạn sẵn sàng khởi chạy máy chủ ở bước tiếp theo.
Đến lúc khởi động mô hình với llama-server. Lệnh này sẽ nạp mô hình MiniMax M2.7 GGUF, chạy trên GPU và mở thông qua máy chủ cục bộ ở cổng 8001.
Trước khi chạy máy chủ mô hình, hãy khởi tạo một phiên tmux để tiến trình vẫn chạy ngay cả khi kết nối SSH bị ngắt hoặc bạn đóng cửa sổ terminal.
Chạy:
tmux new -s minimaxLệnh này tạo một phiên tmux mới tên minimax, chúng ta sẽ dùng để chạy máy chủ.
Bây giờ chuyển vào thư mục llama.cpp và chạy máy chủ với đường dẫn mô hình và thiết lập suy luận:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Lệnh này khởi động máy chủ ở cổng 8001 và nạp mô hình. Khi mô hình nạp, theo dõi log trong terminal.

Nếu mô hình nạp thành công vào bộ nhớ GPU, bạn sẽ thấy thông báo cho biết máy chủ đang lắng nghe tại địa chỉ và cổng đã cấu hình.
Khi mô hình đã nạp hoàn tất, bạn có thể để nó chạy trong tmux và tách khỏi phiên mà không dừng tiến trình.
Nhấn Ctrl+B, rồi D. Bạn sẽ quay lại terminal bình thường trong khi máy chủ mô hình vẫn chạy nền.
Nếu muốn xem lại log sau này, gắn lại phiên bằng:
tmux attach -t minimaxSau khi máy chủ khởi chạy, mở một phiên terminal khác và chạy:
curl http://127.0.0.1:8001/v1/modelsBạn sẽ thấy đầu ra như sau:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}Nếu bạn thấy mô hình MiniMax-M2.7 được liệt kê, máy chủ đang chạy đúng.
Vì bạn đã khởi chạy SSH với chuyển tiếp cổng 8001, giờ bạn có thể mở WebUI của llama.cpp trực tiếp trong trình duyệt bằng cách truy cập http://127.0.0.1:8001.
Điều này cho phép bạn truy cập trực tiếp giao diện mô hình từ trình duyệt cục bộ.
Đến thời điểm này, mô hình đã sẵn sàng sử dụng. Bạn có thể thử trong WebUI hoặc qua yêu cầu API từ terminal để đảm bảo mọi thứ hoạt động đúng.
Trong thiết lập của tôi, MiniMax M2.7 phản hồi cực nhanh, đạt khoảng 120 token mỗi giây. Thực sự cảm giác đây là mô hình cục bộ nhanh nhất tôi từng chạy ở kích thước này, đặc biệt khi nó vẫn rất nhạy ngay cả với prompt dài và kỹ thuật hơn.
Khi mô hình phản hồi đúng, MiniMax M2.7 đã chạy hoàn toàn cục bộ và sẵn sàng kết nối vào quy trình mã hóa của bạn.
Giờ khi máy chủ llama.cpp cục bộ đang chạy, bước tiếp theo là kết nối nó với OpenCode. OpenCode là một agent mã hóa chạy trên terminal, hỗ trợ nhà cung cấp tùy chỉnh thông qua tệp cấu hình. Nếu bạn quan tâm tìm hiểu thêm, hãy xem bài so sánh OpenCode và Claude Code.
Với các mô hình cục bộ như llama.cpp, thiết lập sạch nhất là trỏ OpenCode tới endpoint tương thích OpenAI cục bộ đang chạy tại http://127.0.0.1:8001/v1.
Cài OpenCode trên máy từ xa bằng:
curl -fsSL https://opencode.ai/install | bash
Sau đó nạp lại shell và kiểm tra phiên bản để xác nhận đã cài đúng:
source ~/.bashrc
opencode --version1.4.6Tiếp theo, tạo tệp opencode.json để chỉ định OpenCode dùng máy chủ llama.cpp cục bộ của bạn như một nhà cung cấp tương thích OpenAI.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFCấu hình này trỏ OpenCode tới máy chủ cục bộ, đặt mô hình mặc định là MiniMax-M2.7, và dùng cách tiếp cận nhà cung cấp tương thích OpenAI mà OpenCode tài liệu hóa cho provider tùy chỉnh. OpenCode cũng hỗ trợ chọn mô hình trong ứng dụng với lệnh /models.
Giờ hãy tạo một thư mục dự án đơn giản và khởi chạy OpenCode bên trong:
mkdir ml-app
cd ml-app/
OpencodeKhi OpenCode mở, gõ /models và chọn MiniMax-M2.7 dưới nhà cung cấp cục bộ của bạn.
Khi đã chọn mô hình, hãy đưa ra một prompt mã hóa thực tế. Ví dụ:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.Trên thực tế, đây là lúc thiết lập bắt đầu gây ấn tượng. Mô hình bắt đầu làm việc gần như ngay lập tức, tạo kế hoạch tác vụ và bắt đầu xây dựng các tệp. Trong quá trình thử của tôi, nó phản hồi rất nhạy, phù hợp với tốc độ mà mô hình đã thể hiện khi chạy qua llama.cpp.
Cuối cùng, nó có thể tạo tệp, chạy kiểm thử và hiển thị kết quả.
Sau đó, bạn có thể tiếp tục đẩy xa hơn bằng cách yêu cầu kiểm thử các endpoint API ML, cải thiện cấu trúc ứng dụng hoặc thêm tính năng mới. Vì OpenCode được xây dựng cho quy trình mã hóa dựa trên terminal, đây là thời điểm thiết lập MiniMax cục bộ bắt đầu cho cảm giác như một agent mã hóa thực tiễn chứ không chỉ là mô hình chạy trên máy chủ.
Trong trường hợp của tôi, ứng dụng ML API cục bộ đã hoạt động đúng vào cuối quá trình. Chúng tôi chạy unit test, smoke test và đảm bảo không có lỗi khi chạy cũng như kiểm thử mã. Tổng thể, mất khoảng 2 phút để hoàn tất, cho thấy mô hình này nhanh như thế nào trong quy trình mã hóa cục bộ.
Ban đầu tôi thử với vLLM, nhưng tôi gặp khá nhiều vấn đề, đặc biệt khi cố chạy mô hình AWQ 4-bit. Với kiểu thiết lập này, tôi thấy llama.cpp dễ làm việc hơn nhiều. Cài đặt đơn giản hơn, quy trình mạch lạc hơn và nhanh hơn nhiều để mọi thứ chạy đúng.
Điều tôi cũng thích ở llama.cpp là nó đi kèm WebUI tích hợp, vì vậy bạn có thể kiểm thử mô hình ngay trong giao diện giống ChatGPT trên trình duyệt. Điều đó giúp dễ dàng kiểm tra nhanh prompt, thử phản hồi và đảm bảo mô hình hoạt động trước khi kết nối với thứ như OpenCode.
Đối với việc dùng cục bộ, tôi nghĩ MiniMax M2.7 là một trong những mô hình tốt nhất tôi từng chạy. Nó nhỏ hơn GLM 5.1, chạy nhanh hơn, hiểu code tốt và thể hiện mạnh trong các tác vụ mã hóa hướng agent. Ngay cả phiên bản 4-bit cũng làm rất tốt ở các tác vụ phức tạp hơn, khiến nó cảm giác đủ thực tiễn cho sử dụng thật chứ không chỉ để thử nghiệm.
Tốc độ là phần quan trọng khiến thiết lập này nổi bật. Trường hợp của tôi, MiniMax M2.7 chạy khoảng 120 token mỗi giây với quá trình sinh rất mượt, và thông qua chuyển tiếp cổng SSH, tôi có thể dùng nó từ trình duyệt hoặc API cục bộ như thể đang chạy ngay trên máy của mình. Toàn bộ quy trình vì thế rất nhanh, đơn giản và thực tiễn.
Khóa học Kỹ sư AI
Tracks
Tracks
Courses
blogs
Matt Crabtree
10 phút