
Program
Veri Bilimcileri için Yardımcı Yapay Zeka Mühendisi
40 sa
MiniMax M2.7, araç kullanımı, çok adımlı kodlama görevleri ve üretkenliğe yönelik akıl yürütme gibi karmaşık ajan iş akışları için tasarlandığından, birçok açık ağırlıklı modelden ayrışır.
En büyük model katmanında değil de orta boy aralıkta yer almasına rağmen, MiniMax M2.7 çok daha pratik bir dağıtım ayak iziyle güçlü kodlama ve akıl yürütme performansı sunacak şekilde konumlandırılmıştır.
Bu rehberde, talep üzerine en ucuz H200 erişimini sunması, hızlı hazırlama sağlaması ve yerel tarzda model sunumu için Linux GPU makinelerini kolayca çalıştırma imkânı vermesi nedeniyle Hyperbolic’i kullanacağım.
Şunları öğreneceksiniz:
Bir Hyperbolic H200 Linux makinesi başlatma
Yerel çıkarım için llama.cpp kurma
MiniMax M2.7’nin Unsloth’a ait UD-IQ4_XS GGUF sürümünü indirme
llama-server’ı OpenAI uyumlu yerel bir API olarak çalıştırma
Yerel modeli ajan odaklı kodlama iş akışları için OpenCode’a bağlama
MiniMax M2.7, MiniMax M2.5 gibi önceki açık modellere göre daha ajan odaklı bir yön sunuyor. Öne çıkmasını sağlayan şey yalnızca kodlama veya akıl yürütme yeteneği değil, aynı zamanda kendi iyileştirme sürecine katılacak şekilde tasarlanmış olmasıdır.
MiniMax’a göre M2.7, kendi evrimine derinlemesine katkı sağlayan ilk modelleridir; karmaşık ajan kılıfları inşa etmeye yardımcı olur, ayrıntılı üretkenlik görevlerini üstlenir ve ajan ekipleri, ileri beceriler ve dinamik araç aramasıyla çalışır.
M2.7 ile büyük bir değişim, öz-evrim iş akışıdır. Geliştirme sırasında model, kendi belleğini güncellemek, pekiştirmeli öğrenme deneyleri için karmaşık beceriler oluşturmak ve bu deneylerin sonuçlarına göre kendi öğrenme sürecini iyileştirmek için kullanıldı.
Tüm bunlar M2.7’yi, standart statik bir modelden ziyade yinelemeli iyileştirme için inşa edilmiş bir sistem gibi hissettiriyor.
Kaynak: MiniMaxAI/MiniMax-M2.7 · Hugging Face
En ilginç bulduğum nokta, MiniMax’in M2.7’yi yalnızca bir başka açık model olarak değil daha fazlası olarak konumlandırması. Bana göre bu, daha gelişmiş sistemlerin kendi geliştirme süreçlerinde daha etkin rol alabildiği, modelleri iyileştirmenin ve eğitmenin daha sürdürülebilir bir yoluna işaret ediyor.
Yalnızca devasa yeni veri kümelerine dayanmak yerine, daha yeni eğitim yöntemlerinin ve öz-iyileştirme döngülerinin model performansını nasıl ileri taşıyabileceğini gösteriyor.
Hyperbolic’e gidin, kaydolun ve kartınızı kullanarak en az 5$ kredi ekleyin. Ardından GPUs sekmesine gidin, Launch Instance’a tıklayın ve H200 SXM5 makinesini seçin.
Bu rehber uzak bir GPU sunucusu kullanıyor, bu yüzden makineyi başlatmadan önce SSH erişiminizin hazır olduğundan emin olmanız gerekir. SSH, kendi terminalinizden Hyperbolic üzerinde çalışan Linux makinesine güvenli bir şekilde bağlanmanızı sağlar.
Zaten SSH kullanıyor ve bir anahtar çifti kuruluysa bir sonraki kısma geçebilirsiniz. Değilse, önce bir anahtar oluşturmanız gerekir.
Yerel makinenizde bir terminal açın ve eğer yoksa bir SSH anahtarı oluşturun:
ssh-keygenİstendiğinde, varsayılan konuma kaydetmek için Enter’a basın. İsterseniz ek güvenlik için bir parola ifadesi de ekleyebilirsiniz, ancak isteğe bağlıdır.
Anahtar oluşturulduktan sonra, kopyalayabilmek için ortak anahtarınızı yazdırın:
cat ~/.ssh/id_rsa.pubSisteminiz Ed25519 biçimini kullanıyorsa, şunu çalıştırın:
cat ~/.ssh/id_ed25519.pubÇıktının tamamını kopyalayın ve Hyperbolic hesabınıza ekleyin. Yalnızca ortak anahtarı yüklediğinizden emin olun. Özel anahtar bilgisayarınızda kalır ve asla paylaşılmamalıdır.
SSH anahtarınız eklendikten sonra Hyperbolic panosuna gidin, GPUs sekmesini açın ve Launch Instance’a tıklayın. Mevcut makineler listesinden bu kurulum için H200 SXM5 örneğini seçin.
Makineyi başlatmadan önce, örneğe açık ve kolay tanınır bir ad verin. Bu, özellikle birden fazla makine başlatırsanız veya bir süre sonra geri dönerseniz onu daha sonra tanımlamayı kolaylaştırır.
Ardından örnek ayarlarını gözden geçirin, SSH anahtarınızın eklendiğini doğrulayın ve makineyi başlatın. Platform, GPU sunucusunu sizin için hazırlamaya başlayacaktır.
Makine tamamen hazır olduğunda panoda etkin olarak görünecektir. Bu noktada, yerel terminalinizden bağlanmak için gereken SSH komutunu da göreceksiniz. Bir sonraki adımda bu komutu kullanacaksınız.
Şimdi yerel terminalinizi açın ve baştan port yönlendirme etkin olacak şekilde SSH komutunu çalıştırın:
ssh -L 8001:127.0.0.1:8001 root@<H200-Instance-IP>Bu, yerel makinenizi uzak Linux sunucusuna bağlar ve ayrıca 8001 portunu iletir; böylece daha sonra llama.cpp sunucusuna tarayıcınızdan http://127.0.0.1:8001 üzerinden erişebilirsiniz.
Sunucuya ilk kez bağlanıyorsanız, SSH sizden parmak izini onaylamanızı isteyecektir. yes yazın ve Enter’a basın.
SSH anahtarınızı oluştururken bir parola ifadesi belirlediyseniz, bağlantı tamamlanmadan önce SSH bunu isteyecektir. Parola ifadenizi yazıp Enter’a basın. Parola ifadesi kullanılması, özel anahtarınıza ek bir koruma katmanı eklediği için önerilir.
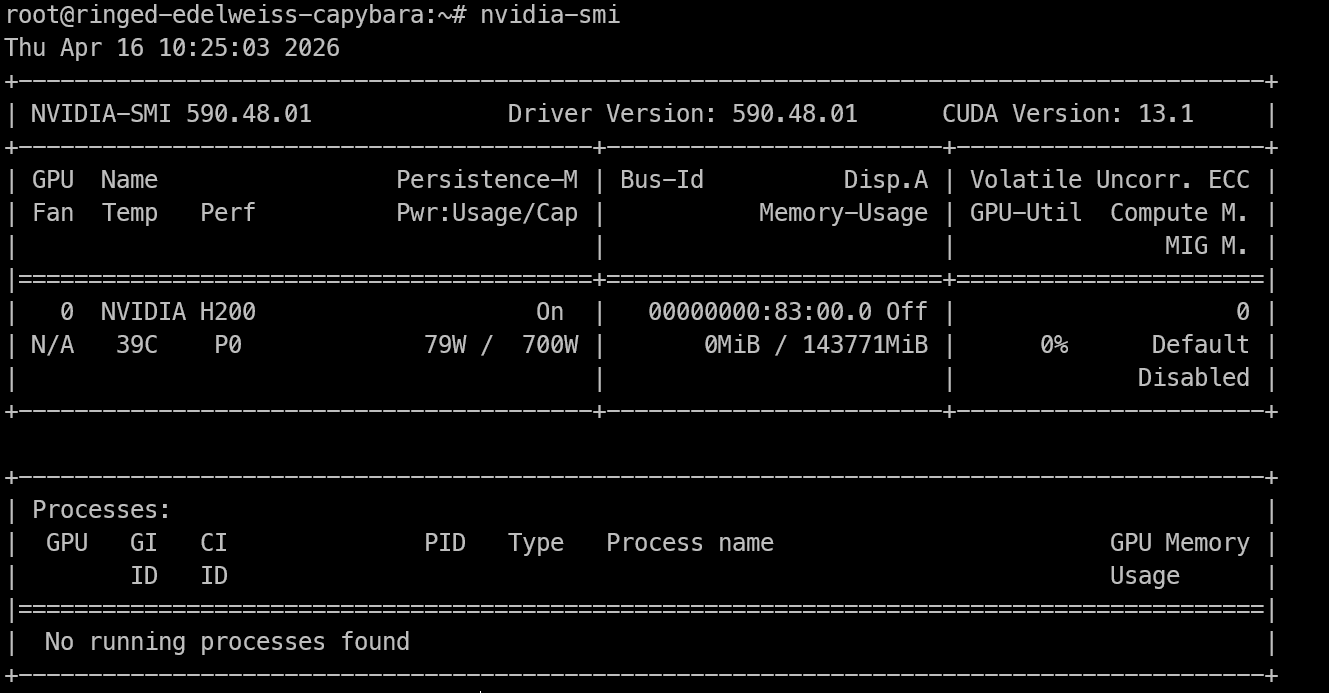
H200 makinesine uzaktan erişim sağladıktan sonra, kontrol etmeniz gereken ilk şey GPU’nun görünür olup olmadığı ve NVIDIA sürücülerinin doğru çalışıp çalışmadığıdır.
Şunu çalıştırın:
nvidia-smiBu komut, yüklü NVIDIA GPU’yu, sürücü sürümünü, CUDA sürümünü ve kullanılabilir belleği gösterir. Burada H200’ü görüyorsanız, makine çıkarım çalışmaları için hazır demektir.
Şimdi llama.cpp’yi derlemek ve modeli yerelde çalıştırmak için gereken sistem paketlerini kurun.
Şunu çalıştırın:
apt-get update
apt-get install -y pciutils build-essential cmake git curl wget libcurl4-openssl-dev tmux python3 python3-pipBu paketler geri kalan kurulum için gereken araçları sağlar.:
build-essential ve cmake, llama.cpp’yi derlemek için gereklidir
git depoyu klonlamanıza imkan verir
curl ve wget dosya indirmeye yardımcı olur
tmux, terminali kapattıktan sonra bile uzun süreli işlemleri aktif tutmak istiyorsanız kullanışlıdır.
Makine hazır olduğuna göre, sıradaki adım llama.cpp’yi kurmaktır; MiniMax M2.7’yi yerelde çalıştırmak için bunu kullanacağız. Bu, modeli test etmek için komut satırı araçlarını ve daha sonra OpenAI uyumlu bir API olarak sunacağımız sunucuyu sağlar.
Önce resmi llama.cpp deposunu uzak makineye klonlayın:
git clone https://github.com/ggml-org/llama.cppBu, bulunduğunuz dizinde projenin derlenmesi için gereken tüm kaynak dosyaları içeren yeni bir llama.cpp klasörü oluşturur.
Sonraki adımda derlemeyi yapılandırmak için CMake’i çalıştırın. Bu kurulumda CUDA etkinleştiriliyor ki llama.cpp çıkarım için H200 GPU’yu kullanabilsin.
cmake llama.cpp -B llama.cpp/build -DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ONBu komut, llama.cpp/build dizini içinde yapı dosyalarını hazırlar.
Şimdi ihtiyaç duyulan araçları derleyin:
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-server llama-gguf-splitBu işlem üç ana ikili dosyayı oluşturur:
Terminalden modeli test edip çalıştırmak için llama-cli
Modeli yerel bir API ve tarayıcı arayüzü üzerinden sunmak için llama-server
Bölünmüş GGUF model dosyalarıyla çalışmak için llama-gguf-split
İkili dosyaları ana klasöre kopyalayın
Derleme bittikten sonra, derlenmiş ikilileri ana llama.cpp klasörüne kopyalayın:
cp llama.cpp/build/bin/llama-* llama.cppBu sayede her seferinde tam derleme yolunu yazmadan araçları çalıştırmak kolaylaşır.
Son olarak, her şeyin doğru kurulduğundan emin olmak için aşağıdaki yardım komutlarını çalıştırın:
./llama.cpp/llama-cli --help
./llama.cpp/llama-server --helpHer iki komut da hata yerine kullanım bilgisi döndürüyorsa, llama.cpp başarıyla kuruldu ve MiniMax M2.7 modelini indirmeye hazırsınız.
Modeli indirmeden önce, uzak makineye Hugging Face indirme araçlarını yükleyin:
pip -q install -U "huggingface_hub[hf_xet]" hf-xet hf_transferBu, hf CLI’ı ve büyük dosya indirmelerini daha verimli yönetmeye yardımcı olan hf-xet aracını kurar.
Sonraki adımda model dosyaları için bir klasör oluşturun ve MiniMax M2.7’nin UD-IQ4_XS GGUF sürümünü indirin.
Şunu çalıştırın:
mkdir -p /models/minimax-m27
hf download unsloth/MiniMax-M2.7-GGUF \
--local-dir /models/minimax-m27 \
--include "*UD-IQ4_XS*"
Bu, özel bir model dizini oluşturur ve bu rehberde kullanılan 4 bit kuantize sürüm olan yalnızca UD-IQ4_XS dosyalarını indirir.
İndirme büyüktür, yaklaşık 108 GB, bu nedenle örneğinizin ağ hızına bağlı olarak yine de zaman alabilir.
İndirme tamamlandıktan sonra, tüm GGUF parçalarının bulunduğunu doğrulamak için şunu çalıştırın:
find /models/minimax-m27 -name "*.gguf"Şuna benzer şekilde listelenen dört GGUF dosyasını görmelisiniz:
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00003-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00002-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf
/models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00004-of-00004.ggufDört dosyanın hepsi varsa, model doğru şekilde indirildi ve bir sonraki adımda sunucuyu başlatmaya hazırsınız.
Şimdi modeli llama-server ile başlatma zamanı. Bu işlem MiniMax M2.7 GGUF modelini yükleyecek, GPU’da çalıştıracak ve 8001 portunda yerel bir sunucu üzerinden erişime açacaktır.
Model sunucusunu başlatmadan önce bir tmux oturumu başlatın; böylece SSH bağlantınız düşse ya da terminal penceresini kapatsanız bile süreç çalışmayı sürdürür.
Şunu çalıştırın:
tmux new -s minimaxBu, sunucuyu çalıştırmak için kullanacağımız minimax adlı yeni bir tmux oturumu oluşturur.
Şimdi llama.cpp dizinine geçin ve model yolu ile çıkarım ayarlarını vererek sunucuyu çalıştırın:
cd llama.cpp
./llama-server \
--model /models/minimax-m27/UD-IQ4_XS/MiniMax-M2.7-UD-IQ4_XS-00001-of-00004.gguf \
--alias "MiniMax-M2.7" \
--host 0.0.0.0 \
--port 8001 \
--ctx-size 32768 \
--batch-size 2048 \
--ubatch-size 512 \
--threads 16 \
--parallel 1 \
--flash-attn on \
--n-gpu-layers 999 \
--temp 1.0 \
--top-p 0.95 \
--top-k 40Bu, sunucuyu 8001 portunda başlatır ve modeli yükler. Model yüklenirken terminaldeki günlükleri izleyin.

Model GPU belleğine başarıyla yüklenirse, sunucunun yapılandırılan adres ve portu dinlediğini gösteren bir ileti göreceksiniz.
Model tamamen yüklendikten sonra, onu tmux içinde çalışır halde bırakabilir ve oturumdan ayrılabilirsiniz; süreç durmaz.
Şunlara basın: Ctrl+B ardından D. Bu, model sunucusunu arka planda aktif tutarken normal terminalinize geri döner.
Günlüklere daha sonra tekrar bakmak isterseniz, şu komutla oturuma yeniden bağlanın:
tmux attach -t minimaxSunucu başladıktan sonra, başka bir terminal oturumu açın ve şunu çalıştırın:
curl http://127.0.0.1:8001/v1/modelsŞuna benzer bir çıktı görmelisiniz:
{"models":[{"name":"MiniMax-M2.7","model":"MiniMax-M2.7","modified_at":"","size":"","digest":"","type":"model","description":"","tags":[""],"capabilities":["completion"],"parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":[""],"parameter_size":"","quantization_level":""}}],"object":"list","data":[{"id":"MiniMax-M2.7","aliases":["MiniMax-M2.7"],"tags":[],"object":"model","created":1776336809,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":200064,"n_ctx_train":196608,"n_embd":3072,"n_params":228689764864,"size":108405492736}}]}MiniMax-M2.7 modelini listede görüyorsanız, sunucu düzgün çalışıyor demektir.
SSH’yi 8001 port yönlendirmesiyle başlattığınız için, şimdi tarayıcınızda http://127.0.0.1:8001 adresine giderek doğrudan llama.cpp WebUI’ı açabilirsiniz.
Bu, modele yerel tarayıcınızdan doğrudan arayüz erişimi sağlar.
Bu noktada model kullanıma hazır olmalıdır. Her şeyin doğru çalıştığından emin olmak için WebUI’da veya terminalden API istekleriyle test edebilirsiniz.
Benim kurulumumda MiniMax M2.7 son derece hızlı yanıt veriyordu; saniyede yaklaşık 120 token’a ulaştı. Açıkçası, özellikle daha uzun ve teknik istemlerde ne kadar çevik davrandığını da düşünürsek, bu boyutta şimdiye kadar yerelde çalıştırdığım en hızlı model gibi hissettirdi.
Doğru yanıt verdikten sonra, MiniMax M2.7 tamamen yerelde çalışıyor ve kodlama iş akışınıza bağlanmaya hazır demektir.
Yerel llama.cpp sunucusu çalıştığına göre, sıradaki adım onu OpenCode’a bağlamaktır. OpenCode, yapılandırma dosyası aracılığıyla özel sağlayıcıları destekleyen, terminal tabanlı bir kodlama ajanıdır. Daha fazlasını merak ediyorsanız, OpenCode ve Claude Code karşılaştırmamıza göz atın.
llama.cpp gibi yerel modeller için en temiz kurulum, OpenCode’u http://127.0.0.1:8001/v1 üzerinde çalışan yerel OpenAI uyumlu uç noktaya yönlendirmektir.
OpenCode’u uzak makineye şu komutla kurun:
curl -fsSL https://opencode.ai/install | bash
Sonra kabuğunuzu yeniden yükleyin ve doğru kurulduğunu doğrulamak için sürümü kontrol edin:
source ~/.bashrc
opencode --version1.4.6Sonraki adımda, OpenCode’a yerel llama.cpp sunucunuzu OpenAI uyumlu bir sağlayıcı olarak kullanmasını söyleyen bir opencode.json dosyası oluşturun.
cat > opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama.cpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama-server (local)",
"options": {
"baseURL": "http://127.0.0.1:8001/v1",
"timeout": 600000,
"chunkTimeout": 120000
},
"models": {
"MiniMax-M2.7": {}
}
}
},
"model": "MiniMax-M2.7"
}
EOFBu yapılandırma, OpenCode’u yerel sunucuya yönlendirir, varsayılan modeli MiniMax-M2.7 olarak ayarlar ve OpenCode’un özel sağlayıcılar için belgelediği OpenAI uyumlu sağlayıcı yaklaşımını kullanır. OpenCode ayrıca uygulama içinde /models komutuyla model seçimini destekler.
Şimdi basit bir proje klasörü oluşturun ve içinde OpenCode’u başlatın:
mkdir ml-app
cd ml-app/
OpencodeOpenCode açıldığında, /models yazın ve yerel sağlayıcınız altında MiniMax-M2.7’yi seçin.
Model seçildikten sonra, ona gerçek bir kodlama istemi verin. Örneğin:
Build a simple machine learning API app with FastAPI using just two files: one app.py file for the API and model loading/prediction logic, and one test_app.py file for basic endpoint tests.Uygulamada, kurulum bu noktada etkileyici hissettirmeye başlıyor. Model neredeyse anında çalışmaya başlıyor, bir görev planı oluşturuyor ve dosyaları oluşturmaya koyuluyor. Testlerimde, llama.cpp üzerinden zaten ne kadar hızlı çalıştığıyla uyumlu bir biçimde oldukça çevik hissettirdi.
Sonunda dosyaları oluşturmayı, testleri çalıştırmayı ve sonuçları göstermeyi başardı.
Bundan sonra, ondan ML API uç noktalarını test etmesini, uygulama yapısını iyileştirmesini veya yeni özellikler eklemesini isteyerek daha ileri gidebilirsiniz. OpenCode terminal tabanlı kodlama iş akışları için tasarlandığından, yerel MiniMax kurulumunun yalnızca bir sunucuda çalışan bir modelden ziyade pratik bir kodlama ajanı gibi hissettirmeye başladığı nokta burasıdır.
Benim durumumda, yerel ML API uygulaması çalışmanın sonunda doğru şekilde çalışıyordu. Birim testleri yaptık, duman testi yaptık ve kodu çalıştırırken ve test ederken hata olmadığından emin olduk. Genel olarak her şeyin tamamlanması yaklaşık 2 dakika sürdü; bu da bu modelin yerel bir kodlama iş akışında ne kadar hızlı hissettirdiğini gösteriyor.
Başlangıçta vLLM ile başladım, ancak özellikle 4 bit AWQ bir modeli çalıştırmaya çalışırken epey sorunla karşılaştım. Bu tür bir kurulum için llama.cpp’yi çok daha kullanışlı buldum. Kurulum daha basit geldi, iş akışı daha yalındı ve her şeyi düzgün şekilde çalışır hale getirmek çok daha hızlıydı.
llama.cpp’de hoşuma giden bir diğer nokta, yerleşik bir WebUI ile gelmesi; böylece modeli tarayıcınızdan ChatGPT benzeri bir arayüzde hemen test edebiliyorsunuz. Bu, istemleri hızlıca kontrol etmeyi, yanıtları test etmeyi ve OpenCode gibi bir şeye bağlamadan önce modelin çalıştığından emin olmayı çok daha kolaylaştırıyor.
Yerel kullanım için MiniMax M2.7 şimdiye kadar çalıştırdığım en iyi modellerden biri. GLM 5.1’den daha küçük, daha hızlı hissettiriyor, kodu iyi anlıyor ve ajan odaklı kodlama görevlerinde güçlü performans gösteriyor. 4 bit sürüm bile daha karmaşık görevlerde çok iyi iş çıkardı; bu da onu yalnızca denemelik değil gerçek kullanım için pratik hissettirdi.
Bu kurulumu öne çıkaran unsurların büyük kısmı hız. Benim durumumda MiniMax M2.7 yaklaşık saniyede 120 token ile çok akıcı üretim sağlıyordu ve SSH port yönlendirmesi sayesinde, sanki kendi makinemde çalışıyormuş gibi yerel tarayıcımdan veya API üzerinden kullanabildim. Bu da tüm iş akışını hızlı, basit ve çok pratik hissettirdi.
Yapay Zekâ Mühendisliği Kursları
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
